java基础学习笔记
大纲
| Java |
初始JavaSE |
java异常机制 |
|
| java基础语法 |
字符串和可变字符串 |
||
| 程序流控制 |
包装类揭秘 |
||
| Java |
函数和数组 |
java日期类 |
|
| 面向对象思想 |
集合的体系分析和使用 |
||
| 类的继承 |
java文件处理 |
||
| 接口和多态 |
IO流详细分析 |
||
| 内部类和Object根类 |
多线程 |
||
| eclipse开发工具的使用 |
网络 |
||
| HTML |
request和response |
||
| CSS |
session和cookie |
||
| XML |
jsp |
||
| JavaWeb |
JDBC |
EL表达式和JSTL标签 |
|
| Tomcat |
EMS |
||
| http协议 |
filter和listener |
||
| servlet |
upload和dawnload |
||
| JavaScript |
Struts2 |
||
| Java |
Ajax和Json及正则表达式 |
spring |
|
| MySQL |
hibernate |
||
| Jquery |
springmvc |
||
| java反射和注解开发 |
mybatis |
一.
1.什么是类?什么是对象?
2.如何创建类?如何创建对象?
3.引用类型之间画等号
4.null和NullpointerException
二.
1.方法的重载
2.构造方法
3.this
4.引用类型数组
三.
1.内存管理:堆 ,栈 方法区
2.继承
3.super
4.向上造型/向下造型(强制转换)
四.
1.什么是方法的重写及重写的意义
2.重写与重载的意义
3.package和import
4.访问控制修饰符
5.static
6.final
7.static final的常量
五.
1.抽象方法
2.抽象类
3.接口及接口之间的关系,接口与类之间的关系
六.
1.多态:意义 ,向上造型, 强制转换,判断instanceof
2.内部类:成员内部类,匿名内部类
常用英文缩写
1.HTML(Hyper Text Markup Language)超文本标记语言的
2. css指的是层叠演示表(cascading style sheets)
3. XML( Extensible Markup Language)可扩展性标记语言
4.HTTP协议(HyperText Transfer Protocol)超文本传输协议
1. 什么是类和对象?
类和对象
1) .现实世界是由很多很多对象组成的,基于对象抽出了类
2) .对象是真实存在的单个个体类:类别/类型,代表一类个体
3) .类中可以包含:
3.1)所有对象所共有的属性/特征——变量
3.2)所有对象所共有的行为——方法
4).一个类可以包含多个对象,结构相同,数据不同
5)类是对象的模板,对象是类的具体实例。
**缺陷一:缺乏对数据的封装
**缺陷二:数据和方法处于分离状态
面向过程编程:一堆方法,调来调去 (OOP)面向对象编程:以对象为核心,围绕着对象做操作
面向接口编程:在面向对象的基础之上,抽接口,复用性好,可维护性好,可扩展性好,移植性好.........
人类通过探讨对象的属性和观察对象的行为 来了解对象
2.JVM内存结构——栈(stack)
栈
栈用于存放程序运行过程当中所有的局部变量,一个运行的Java程序从开始到结束会有多次方法的调用。JVM会为每一个方法的调用在栈中分配一个对应的空间,这个空间称为该方法的栈帧,一个栈帧对应一个正在调用中的方法,栈帧中存储了该方法的参数,局部变量等数据。当某一个方法调用完成后,其对应的栈帧将被清除。
方法的重载:
方法名相同,参数列表不同叫方法的重载。
方法重载不能根据方法的返回值的不同来区分,因为返回值不属于方法签名的一部分。
类Day2
1.引用类型变量
1.引用类型变量用于存放对象的地址,可以给引用类型赋值为null,表示不指向任何对象,当某个引用类型变量为null
时,无法对对象实施访问(因为他没有指向任何对象).此时,如果,通过引用访问成员变量或调用方法,会产生NullPointerExceptiion异常.
2.this 的用法:
在方法中可以通过this 关键字表示"调用该方法的那个对象"
public void down(int dy){
This.y+=dy;
}
这样的写法更加明确,print方法功能可以描述为打印出调用该方法的那个对象的x和y的值,在没有奇异的情况下可以省略this
This:
this:只能用在方法中在方法中访问成员变量前都有一个默认的this.
1.this指的是当前对象,谁调用指得谁
2.用法:
**this.成员变量----访问成员变量
**this.方法()---访问方法
**this()-----调用构造方法
构造方法:
在Java语言中可以通过构造方法的实现对对象成员变量的初始化,构造方法是在勒种定义的方法,但不同于其他的方法,构造方法的定义有如下两点规则:
1.构造方法的名称必须与类同名
2.构造方法没有返回值,但也不能写void.
默认的构造方法:
任何一个编译的类都必须含有构造方法,如果源程序中没有定义,编译器在编译时将为其添加一个无参的空的构造方法(称之为"默认的构造方法")
当定义了构造方法后,编译器将不再添加默认的构造方法.
虚拟机 (Java virtual Machine)
JVM中类的装载是由classLoader 和他的子类来实现. (装载器)
Java ClassLoader 是由一个重要的Java运行时组件,它负责在运行时查找和装入类文件的类.
构造方法也叫构造器,在构造器中,通过this.可以调用其他的构造器,而且this必须放在方法的第一行
默认构造器
默认构造器,如果再类中没有带参数的构造器,默认构造器是隐式存在的,如过类中定义有参数的构造器,那么默认构造器就被覆盖了,如果使用默认构造器,只需把它显示的定义出来即可
内存Day03
复习
1.同一个文件中可以包含多个类
2.public修饰的类只能有一个
3.public修饰的类只能与文件名相同
4.方法的签名:方法名+参数列表
5.什么时候可以省略this:
*任何一个类都必须含有构造方法
*如果程序中没有定义,编译器将为其添加一个我默认的无参的构造方法
*当定义了构造方法后Java编译器jiang
*构造方法可以重载
1.内存管理:
Java程序,运的时候,特别卡,然后买了内存条,但是任然是卡,问你这是什么原因
编译好的java程序需要在JVM中.(.class文件)
2.JVM分为哪几部
堆中专门储存所有new出来的对象
成员变量储存在堆内存中,并且默认值为0.其生命周期在new对象是存在堆中
3.垃圾
*垃圾:没有任何引用所指向的对象
回收过程是透明的,就是说GC并不是一见到垃圾马上回收若想快一些课可以调用system.gc();来及时调用
4.内存泄漏
*内存泄漏:计算机的不归之路,不死就学习活到老学到老
不再使用的对象还没有被及时的回收(特别严重的泄漏会导致程序崩溃)
为了防止内存泄漏要采取的办法:
当对象不再使用时应及时将引用设置为null;
C++必须自己回收垃圾,而java中有自己的垃圾回收机制.
5.栈
栈;什么是栈;
栈是用来存储什么的?
用于存储程序运行时在方法中声明的所有局部变量—即正在调用的方法的所有局部变量
调用方法时:在栈中为该方法分配对应的栈帧,栈帧中包含所有的局部变量(包括参数),当方法调用结束时,栈帧消失,局部变量一并消失,
局部变量的生命周期:
调用方法时存在栈中,方法调用结束时与栈帧一并消失,每一个调用的方法都有一块栈帧.
方法区:
用来存储方法的区域
方法区;用来存放方法的区域
1.方法区用于存放类的信息,java程序运行时首先会通过类加载器,载入文件的字节码信息,经过解析后将其装入方法区(类的各种信息包括方法)都放在方法区存储.
如:
Cell c=new Cell();
Cell类首先被装载到JVM的方法区中.其中包括类的基本信息和方法定义等.
2.方法区专门用于存储.class字节码文件
继承关系
田广才继承祁玉良的所有蚂蚁花呗
狗:金毛 哈士奇 萨摩耶 泰迪
Extends 关键字,可以实现类的继承
被继承的类叫做父类/超类/superclass
继承的类叫做子类/(subclass),子类可以继承父类的成员变量及成员方法,同时也可以定义自己的成员变量好和方法
Java语言不支持多重继承 即一个类之能继承一个父类,但一个父类可以有多个子类,
Public Crile extends Shape{
Int r;
Public void setR(int r){
This.r=r;
}
}
描述类的时候,我们如果发现几个类有重复的属性和方法,我们就可以采用继承的方式来设计
class子类 extends 父类{
子类的属性;
子类的方法;
}
继承的特点:
1:子类会把父类所有的属性和方法继承下来直接使用
2:子类除了继承父类的属性和方法外还可以有自己特有的属性和方法
3:父类更通用,子类更具体
4:子类之能获得父类中的非private的属性,如果想要继承就得提供公共的set和get 方法,私有的方法是无法继承下来的.
5: Class A extends B extends
Java 中之能做单继承 如:
class A extends B{
}
6:java中支持多级继承
class A extends B{
}
class C extends A {
}
继承的好处是提高代码的复用性,减少重复代码
继承分为父类和子类
父类中放所有子类共有的属性和方法
子类中放子类所特有的属性和方法.
子类继承父类后,子类有:子类+父类的所有属性和方法,然而,子类可以访问父类 但是父类不可以访问子类
*继承具有传递性:
class A {
int a =1;
}
class B extends A {
int b=2;
}
class C extends B{
int c=3
}
修饰词作用域
| 修饰词 /作用域 |
当前类 |
同胞类 |
子孙类 |
其他类 |
| Public |
可访问 |
可访问 |
可访问 |
可访问 |
| Protected |
可访问 |
可访问 |
可访问 |
不可访问 |
| Default |
可访问 |
可访问 |
不可访问 |
不可访问 |
| Private |
可访问 |
不可访问 |
不可访问 |
不可访问 |
复习:day03
一.
- 方法的签名:方法名+参数列表
- 方法的重载overload:
- 发生在同一个类中,方法名相同,参数列表不同
- 编译器在编译时会根据方法的签名自动绑定方法
- 构造方法:给成员变量赋初值,与类同名,没有返回值类型,创建对象 时被自动调用.若不谢则默认一个无参构造,写了就不在默认提供,构造方法可以重载.
- This:方法中,那个对象调用方法,指的就是哪个对象.
- This.成员变量----访问成员变量(实参)
This.方法名------调用方法
This()------------调用构造方法
- Null:空,没有指向任何对象
若引用该变量值为null,则该引用不能再进行任何操作,若操作,则发生NullPointerException空指针异常
- 引用类型画等号:指向同一个对象,相互影响
基本类型画等号:赋值,不影响
数组是引用类型
二. 继承
(1).代码复用,减少代码重复
(2)通过extends 关键字来继承
(3).超类/父类:所有派生类/子类所共有的属性和行为(方法)
(4).派生类/子类:派生类所特有的属性和行为(方法)
(5)派生类继承超类后:派生类就具有了超类+派生类的所有属性和方法
(6).继承具有传递性:
(7):java规定,在构造派生类之前必须先构造超类.
Super:
Super指代当前对象的父类对象
Super的用法:
Super.成员变量名---访问父类的成员变量
Super.方法名---调用父类的构造方法
Super.()----调用父类的构造方法
Java规定:构造子类之前必须先构造父类
(如何保证此规定呢?)
在子类的构造中若没有调用父类的构造方法则默认super()空,来调用父类的无参构造方法,若自己调了,则不再默认提供
*super()调用父类构造,必须 位于子类构造的第一句.
三.重写的定义:
1.发生在父子类中,方法名相同,参数列表相同,方法体不同
- 重写的方法被调用时要看对象的类型
- 子类构造方法中,必须通过super关键字调用父类的构造方法,这样可以妥善的初始化继承自父类的成员变量
- 如果子类的构造方法中没有调用父类的构造方法,Java编译器会自动的加入对父类无参构造方法的调用(如果该父类没有无参的构造方法,会有编译错误)
四.重写与重载的区别(面试官经常 问)
重写:发生在父子类中,方法名相同,参数列表相同,方法体不同(遵循运行期绑定)
重载:发生在同一个类中,方法名相同,参数列表不同,方法体不同.(遵循编译器绑定,根据引用的类型绑定方法)
总结:向上造型的时候,如果父子类中没有发生重写,则调用的是父类中的方法,如果发生了重写则调的是子类中的方法
方法的重写(override):重新写,覆盖
(1).发生在父子类中,方法名称相同,参数列表相同,方法体不同
(2).重写方法被调用时看对象的类型
(3).重写遵循”两同两小一大”原则:
a.两同:方法名称相同 参数列表相同
b.两小:派生类方法的返回值类型小于或等于超类方法的1.void时,必须相等
2.基本类型时,必须相等
3.引用类型时,小于或等于
c.一大:派生类方法返回值类型小于或等于超类的
重载
遵循所谓”编译期绑定”.即在编译时根据参数变量的类型判断应该调用哪个方法.因为变量obj的类型为super
因此:Goo的g(super)方法被调用
重写
遵循所谓”运行期绑定”即在运行时根据引用变量指向的实际对象类型调用方法,obj实际指向的是子类的对象
因此子类重写后的f()方法被调用
鸡汤
Wining is not about being the first one ac
胜利不是第一个跨越的人。终点线或得分最多的目标,但它是关于你能做到最好的
复习
向上造型:
(1).超类型的引用指向派生类的对象
(2).能点出来什么,看引用的类型
方法的重写;
(1).发生在父子类中,方法名相同,参数列表相同,方法体不同
(2).重写方法被调用时,看对象的类型
重写与重载的区别:
重写:发生在父子类中,方法名相同,参数列表相同,方法体不同,遵循运行期绑定
重载 :发生在同一类中,方法名相同,参数列表不同,方法体不同,编译期绑定,看引用的类型
包
Package语句—包
包命名
1.包的作用避免类的命名冲突
2.同一包装类名不能重复
3.建议包名的所有字母都小写
4.项目非常大的时候建议:域名反写www.baidu .com反写为com.baidu+项目名称+模块名称+类名
类的完全限定名:包名.类名(全称)
import 语句
访问一个类时,需要使用该类的全称,但这样的书写方式过于繁琐:
所以可以通过import语句的全称进行声明;
Import的语法为:import类的全局限定名(即包名+类名)
通过import语句声明了类的全称后,该文件就可以直接使用类名来访问了
import的作用
1.声明类/引入类
2.同包中的类可以直接访问,不同包中的类想访问需要先import声明类再访问类(建议使用此方法)
3.使用类的全称太繁琐 (不建议使用)
封装的意义:
对外提供可调用的,稳定的功能
封装容易变化的,具体的实现细节,外界不可访问,这样的意义在于:
--降低代码出错的可能性,便于维护
--但内部的实现细节改变时,只要保证对外的功能定义不变 ,其他模块就不会因此而受到牵连
Final关键字修饰变量,以为不可改变,final可以修饰成员变量,也可以修饰局部变量,当final修饰成员变量时,
初始化
1.声明同时初始化
2.构造函数中初始化
Final关键字
Final关键字修饰局部变量,在使用之前初始化即可
Final修饰类:
Final关键字修饰类不可以被继承,使一个类不能被继承的意义在于:可以保护类不被继承修改,可以控制滥用继承对系统造成的危害,在JDK中的一些基础类库被定义为final的,例如:String,Math,Integer,Double等等,自己定义的类可以声明为final的
常量:
Static final修饰的成员变量称为常量,必须同时初始化,并且不可改变,常量建议所有字母大写.
在实际运用中应用率较广,因为static final常量实在编译期被替换的,这样可以节约不必要的空间开支.
总结:final:最终的,不可改变的----单独应用率极低
修饰变量:变量不可被改变
修饰方法:方法不可被重写
修饰类:类不可被继承
Static final:常量,应用率相对较高
必须声明同时初始化
通过类名点来访问,且不可被改变
建议:常量名所有字母都大写,多个单词用”_”分隔
编译器在编译时将常量自动替换为具体的值,效率高
何时用:有一个数永远不变,并且多次使用
关键字 final可以修饰一个类 一个方法 一个变量 各起什么作用?
Static 关键字:
成员变量:
成员变量包含实例变量和静态变量
1.实例变量:
1).属于对象的,存在堆中
2).有几个对象就有几个实例变量
3).比粗通过对象点来访问.
2.静态变量:
1).由static修饰,凡是static修饰的都是属于类的,存在方法区中
2)既然是在方法区中
3)因其属于类 所以此常常用类名点来访问
4)何时用:所有对象的数据都一样时使用
3.静态方法:
1)由static修饰//静态变量叫类属性
用类名点就可以调
2)属于类的,存在方法区中
3)通过类名点来访问
4)静态方法中没有隐式this传递
没有this就意味着没有对象
而实例成员必须通过对象点来访问,所以静态方法中不能直接访问实例成员和main方法并列的方法都要加static
在实际的应用中实例变量用的多,实例方法用的多
何时用静态方法?
方法的操作仅与参数相关,而与对象无关时使用
之前学过哪些静态方法呢?
例如:
- int[] a1=Arrays.copyOf(a,6);
- Double a=Math.random();
- Double b=Math.sqrt(25);//开方*
抽象类&抽象方法:
由abstract 修饰的方法为抽象方法,抽象方法即只有方法的定义,没有方法的实现.用一个分号结尾,
方法的五要素:
1 修饰词 2 返回值类型 3 方法名 4 参数列表 5 方法体
Public static void main (String [] args){
System.out.println();
}
而抽象方法,在方法的5要素中少了一个要素(缺少方法体),所以也可以将抽象方法理解为不完整的方法.
若将抽象方法包含在类中,则该类也为抽象的,可以理解为 该类也不完整,抽象类由abstract关键字声明.
抽象类
抽象类:是不能实例化对象的,而一个类不能实例化是没有意义的,所以,需要定义类来继承抽象类,而如果一个类继承了抽象类,则其必须重写其抽象方法(变不完整为完整),除非该类也声明为抽象类.
实例化
实例化:在内存在开出了空间 就叫实例化.一个对象在内存中开辟了空间.
抽象类的意义在于:
1.为其子类提供一个公共的类型(父类引用指向子类对象)
2.封装子类中的重复内容(成员变量和方法)
3.定义有抽象方法,子类虽然有不同的实现,但该方法的定义是一致的.(子类需要实现此抽象方法)
总结:
1抽象方法:由abstract修饰,只有方法的定义,没有方法体
2抽象类:由abstract修饰,可以包含抽象方法,也可以包含普通方法
3包含抽象方法的类,必须是抽象类
4类中没有抽象方法也可以将类声明为抽象类
5抽象类不能被实例化,
6抽象类一般需要被继承:
1子类也可以声明抽象类(不建议使用,没大的意义)
2子类重写抽象类中的所有抽象方法---首选
抽象类的意义
1.封装了子类的公用的成员,为子类提供一个公共类型
2.定义抽象方法,由 子类来做不同的实现,但是方法名是一样的.
3抽象类的抽象方法不能和private,final,static共存
接口:(接口)
什么是接口:
当一个抽象类,如果抽象类中的所有方法都是抽象的,那么我们就可以吧它定义为一个接口,接口是对行为/方法的抽象 ,类是对属性和行为的抽象.
Interface 接口名{
方法的定义;
……
}
接口中的方法的定义不需要abstract来修饰.默认就是抽象的.
1.接口不可以实例化的,需要有类来实现
接口进而实现接口的语法,例子如下:
Class 类名 implements 接口1,接口2,…..
2.接口中的方法也不能和private static and final共存
3.在接口中可以定义属性,可以通过接口的实现类的实例来访问,还可以通过接口名来访问(推荐大家使用),接口中的属性不能修改,我们接口中的属性默认都是final static 的,通常在接口中来定义属性把它作为常量,常量的名字规范是单词大写,而且多个单词之间用下划线来分隔,比如FILE_PATH
4.接口可以继承接口(单继承)
5.接口可以看成特殊的抽象类,即值包含抽象方法和常量的抽象类,可以通过interface关键字来定义接口
抽象类是:封装公用的成员
接口的应用
使用接口的好处
1.接口定义的是一种标准,可以使我们的代码分层开发,分模块开发.
2.降低代码的耦合度(关联性),提高代码的课扩展性和可维护性.
3.接口改进了单继承的局限.
接口和抽象类的区别
1.接口的所有方法都是抽象的,抽象类里面的方法是可以抽象也可以不抽象的
2.接口和抽象类都不能实例化,接口需要类来实现后实例化实现类,抽象类需要类来继承后实例化子类
3.抽象类只能单继承,接口可以多继承接口,接口还可以多实现
4.接口中的属性是static final类型的
复习
什么是抽象 类
由abstract修饰的抽象方法.抽象方法只有方法的定义,没有方法体的实现,用一个分号结尾.
抽象方法与普通方法区别
抽象方法缺少了一个要素(方法体),
抽象类 :由abstract修饰,可以包含抽象方法,也可以包含普通方法.
包含抽象方法的类,必须是抽象类 类中没有抽象方法,也可以将类 声明为抽象类
抽象类不能被实例化,Shape=new Shape();//编译错误
抽象类一般也需要被继承
(1).子类也声明为抽象类
(2)子类重写抽象类中 的所有抽象方法---首选
抽象类的意义
1).封装子类共用的成员
为子类提供一个公共的类型
2).定义抽象方法,由子类来做不同的实现,但方法名是一样的
Abstract类和interface有什么区别:
含有abstract修饰符的class类即为抽象类,abstract类不能抽检实例对象—含有abstract方法的类必须定义为abstract class 抽象类中的方法不必是抽象的.抽象类中定义抽象方法必须在具体子类中实现.所有,不能有抽象构造方法或抽象静态方法,如果子类没有实现父类的所有抽象方法,那么子类也必须定义为abstract类型
接口(interface)也可以说成是抽象类的一种特例,接口中的所有方法,都必须是抽象的,接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public static final
语法区别
1.抽象类可有构造方法,接口中不能有构造方法.
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须是抽象的,不能有非抽象的普通方法
4.抽象类中的抽象方法的访问类型可以是public和(默认类型)虽然eclipse 不报错,但应该也不行,但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型
5.抽象类中可以包含静态方法,接口中不能包含静态方法
6.抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以是任意,但接口中定义的变量只能是public static final 类型,并且默认即为public static final 类型
类 和接口
一个类可以实现多个接口,但是只能继承一个抽象类
两着在应用上的区别:
接口更多的是在系统构架设计方法发挥作用,主要用于定义模块之间的通信契约,而抽象类在代码实现方面发挥作用,可以实现代码的重用,例如,模板方法设计模式是抽象类的一个典型应用,假设某个项目的所有servlet类都要用相同的方式进行权限判断,记录访问日志和处理异常,那么久可以定义一个抽象类让所有的servle都继承这个抽象类,在抽象类的service方法中完成权限判断,记录访问日志和处理异常代码,在各个子类中只是完成各自的业务逻辑代码,实例代码如下:
Public abstract class BaseServlet extends HttpServlet{
Public final void service(HttpServletRequest request,HttpServleRespones response)throwsIOException ServletException{
记录访问日志
进行权限判断
IF(具有权限){
doService(resquest,response);
}catch(Exception)
}记录异常信息
}
}
Protected abstract void dService(HttpServletResquest resquest,HttpServletResponse response)throwsIOException,ServletException;
//注意访问权限定义成protected,显得即专业又严谨,因为它是专门给子类用的
}
Public class MyServlet extends BaseServlet{
Protected void doService(HttpServletRequest request,HttpServletResponse response)throwsIOExceptinServletException{
本 Servlet只处理的具体业务逻辑代码
}
}
例题
1.父类方法中间的某段代码不确定,留给子类干,就用模板方法设计模式.
备注:这道题的思路是先从总体解释抽象类和接口的基本概念,然后再比较两者的语法细节,最后再说两者的应用区别.比较语法细节区别的条理是:先从一个类中的构造方法,普通成员变量和方法(包括抽象方法),静态变量和方法,继承特性等6个方面逐一去比较回答,接着从第三者继承的角度回答,特别是最后用了一个个典型的例子来展示自己深厚的技术功底.
1. 是否可以从一个static方法内部发出对非static方法的调用?
答:不可以,因为非static方法是要与对象关联在一起的,必须要创建一个对象后,才可以在该对象上进行方法调用,也就是说,当一个static方法被调用时,可能还没有创建任何实例对象,如果从一个static方法中发出对非static方法的调用那个非static方法是关联到哪个对象上的?在逻辑上无法成立,所以,一个static方法内部无法发出对非static 方法的调用
静态变量和实例变量有什么区别?
1).语法定义上的区别:静态变量要加static关键字,而实例变量前则不加
2).程序运行时的区别:实例变量属于某个对象的属性 必须创建实例对象,其中的实例变量才会被分配空间.才能使用这个实例变量,静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以使用了,总之,实例变量必须创建对象后才可以通过这个对象来使用,静态变量则可以直接使用类名点来引用.
接口:
接口不能包含构造方法,因为接口中都是常量和抽象方法,而构造方法是给成员变量赋初值的,所以接口中不能包含构造方法.
为什么要做成抽象方法?
因为每个角色的行为是不一样的,所以没有办法写方法体,此时就需要做成抽象方法,而抽象方法所在的类就是抽象类
人生总是那样痛苦吗?还是只有小时候会这样?
总是如此!
Is life always this hard ,or it just when you are a kid?
Always like this!
使用接口和 类
1.若符合既是也是原则,使用接口实现
2.若方法是部分子类的共有行为---则定义成接口.
3.如方法是所有子类的共有行为---则抽象 为一个类
4.接口就是一个标准 ,一个规范.
5.接口中只能包含常量和抽象方法
6.接口不能被实例化
接口 引用 =new 实现类();//向上造型
1.类实现接口,必须将所有抽象方法都实现
2.类可以实现多个接口用逗号分隔
3.如果类又继承父类,又实现接口,需先继承 后实现
4.接口与接口之间可以继承,可以单继承 也可以多继承
多态:
多种形态.例如:美女;有人认为脸蛋漂亮是美女,有人认为胸大是美女,有人认为气质好是美女,有人认为温柔是美女,有人认为班花是美女,有人认为性格开朗是美女.
水的 形态:三态.
多态的意义:
1.同一类型的引用指向不同的对象有不同的实现—行为多态.
重写方法被调用时看对象的类型
对象的多态:同一对象被造型为不同的类型时,有不同的功能
向上造型:
父类型的引用指向子类的对象就是向上造型
能造型成类型的有:
他的父类型,他实现的接口.
能点出来什么看对象的类型
向上造型后,能点出来的东西小于等于父类
如果后期我想点一堆东西出来怎么办?
强制转换
那就将向上造型变为向下造型,就是强制转换
Aoo o1=new Boo();向上造型
所以在强制转换中 为了避免出现ClassCastException需要通过instanceof关键字判断某个引用指向的对象是否为为指定的类型
可以通过强制转换将父类型变量转换为子类型变量 前提是该变量指向的对象是该子类类型
也可通过强制转换将变量转换 为某种接口类型,前提是该变量指向的对象确实实现接口.
Instanceof返回的是Boolean结果,如果强制转换成功就是true
内部类:
1.成员内部类:不太常用
1.类 中套类,外面的叫外部类,里面的叫内部类
如:class Father{//外部类
Class son{//内部类
}
}
2.内部类通常只服务于外部类,对外不具备可见性
3.内部类通常是在外部类中创建的
2.匿名内部类:比较常用的
那么什么时候需要定义匿名内部类呢?
如果在一段程序中需要创建一个类的对象(通常这个接口需要实现某个接口或继承某个类)而且对象创建后,这个类的价值就不存在了,此时这个类可以不必命名,称之为匿名内部类
1.如果想创建一个类的对象,并且对象只被创建一次,此时该类不必命名,称为匿名内部类.
什么是内部类:
没有名字的类,这种累需要在接口上实现
位置:
把一个类定义到另一个类中,那么内部的类就是内部类
注意:内部类不能直接创建类
创建语法:
外部类.
内部类.变量名=new外部类对象.new内部类对象.
2.通过示例说明:访问外部类的数据,该数据必须是final的.
Object
Object 是所有类得根类 ,所有类都是直接或的去继承object类.
类object是类层次结构的根类,每个类都使用object作为超类,所有对象包括数组都实现这个类的方法
“==”和equals方法的区别?
“==”操作符专门用来比较两个变量的值是否相等,也就是比较变量所对应的内存中所存储的数值是否相同,要比较两个基本类型的数据或两个引用变量是否相等,只能用==操作符
如果一个变量指向的数据是对象类型的,那么,这时候涉及了两块内存,对象本身占用课一块内存(堆内存),例如Object obj=new object;变量obj是一个内存(栈内存),new object()是另一个内存(堆内存),此时 变量obj所对应的内存中存储的数值就是对象占用的那块内存的首地址,对于指对象类型的变量,如果要比较两个变量是否指向同一个对象,既要看这两个变量所对应的内存中的数值是否相等,这时候就需要用==操作符进行比较.
Equals方法
Equals方法是用于比较两个独立对象的内容是否相同 ,就好比区别比较两个人的长相是否相同,它比较的两个对象是独立的.例如:对于下面的代码
String a=new String(“foo”);
String b=new String(“foo”);
两条new语句创建了两个对象.然后用a,b这两个变量分别指向其中的一个对象,着是两个不同的对象,他们的首地址是不同的 ,即a和b中存储的数值是不相同的,所以,表达式a==b将返回false,而这两个对象中的内容是 相同的,所以,表达式a,equals(b)将返回true.
在实际开发中,我们经常要比较传递进来的字符串内容是否相等,例如:String input =…input.equlas(“quit”),许多人稍不注意就使用”==”进行比较了,这是错误的,记住,字符串 的比较基本上都是使用equals()方法.
如果一个类没有自己定义equal方法,那么它将继承object类的equals方法,Object类的equals方法的实现 代码如下:
Boolean equal(Object obj){
Return this ==obj;
}
这说明,如果一个类没有自己定义equals方法,她默认的equals方法(从object类继承的)就是使用”==”操作符,也是在比较两个变量指向的对象是否是同一对象,这时候使用equals和使用”==”会得到同样的结果,如果比较的是两个独立的对象则返回false.如果你编写的类希望能够比较该类创建的两个实例对象的内容是否相同那么你必须覆盖(重写)equals方法,由你自己写代码来决定在什么情况即可认为两个对象的内容是否相同.
int a=2;
int b=5;
面向对象
面向对象的三大特征:
1.封装:
1.类:封装的是对象的属性和行为
2.方法:封装的是具体的逻辑实现/逻辑功能
3.访问控制修饰符:封装的是访问的权限
2.继承
1.作用:避免代码的重复,有利于代码的复用
2.父类:父类中存放子类共有的属性和行为
子类:存放子类所特有的属性和行为
3.子继承父后:子具有:父+子
4.单一继承,传递性,多接口实现.
3.多态:
1.意义:行为的多态,对象的多态
2.向上造型,强制类型转换,instanceof
3.多态的表现形式:重写+重载.及重写与重载的区别及相同之处.
调试
调试:Debug虫子 漏洞
Debug的目的就是找到错误的出处
Debug需要记住的几个键
F5:逐步调试进到方法中
F6逐步过程调试,不会进到方法中
F7:跳出当前方法
F8:跳到下一个断点,若没有断点了 就直接结束程序
Eclipse
一.大纲视窗:
该视窗中显示当前代码视图源文件中定义的类或者接口,以及定义的所有成员
当代码过长时,查找代码中的某一个类或者成员,在该视窗中是最方便的.
在代码中出现对此 的名称要统一更改也可以在视窗中完成.同时其他代码如果使用了该变量也可一并改变
二.异常
如果被调用的方法发生了运行时异常,那么如果被调用的方法不去处理(不try…catch)jvm默认就会把这个运行时的异常抛到上一层,上一层函数可以对这个异常进行处理,如果上一层函数依然没法处理,那就不处理,就会接着往上抛,总有一层方法会处理
Try…final:
Try…final:final内部的代码不管是否发生异常一定会执行,finally内部的代码不管是否发生异常都会执行,finally主要是来做一些资源的释放
Try…catch…finally
注意:finally可以在return后面执行
编译期的异常:
我们必须要处理或者抛出,否则无法编译通过,继承与exception的所有异常,除了RuntimeException以外都是编译器异常
运行时异常:
运行时异常可以通过,它是发生在程序的运行阶段,在运行的阶段如果发生了运行时的异常,如果我们当前方法不处理就会自动抛出,我们可以手动通过代码类捕捉处理 ,建议向上抛出
自定义异常:
在实际的项目开发中,我们需要跟业务相关的异常,而这样的异常javaAPI中
如:在电商系统 中,在提交订单的时候如果出现了库存不足,我们要抛出自定义的异常,自定义的异常只需要继承javaAPI中的异常类即可,通常情况下我们会自定义运行时异常,所以我们自定义异常就去继续RuntimeException.
1.Exception,非运行时异常,在项目运行钱必须处理掉.一般由程序员try catch掉
2.RunTimeException,运行时异常,在项目运行之后出错则直接终止运行,异常由jvm虚拟机处理
处理异常:
在我们写程序的时候难免会出现小错误,java中的异常机制是为了提高我们程序的健壮性和容错性而存在的
异常体系:
Throwable:Throwable类是java语言中所有错误或异常的超类
什么是Error:
Error是Throwable的子类,它是程序出现了严重的问题,这种问题程序解决不了,
如:因为内存溢出或没有可用的的内存提供给垃圾回收器时,java虚拟机无法分配一个对象,这时抛出该异常
异常总结;
编译期的异常
我们必须处理,如果不处理就会编译失败.
两种解决方法:1,抛出异常,2.try….catch
运行期异常:
编译的时候没有异常,但是程序运行过程中产生的异常就是运行时异常,这种异常我们需要通过程序来容错提高代码的健壮性.
Try{
有可能发生运行时异常的代码
}catch(异常对象){
}finally{
释放资源
}
异常的处理方法:
1.try…catch
2.try…finally
3.try…catch…catch
4.try…catch…catch…finally
printStackTrace()//输出异常的详细信息
\
String字符串
定义:String类代表字符串,java程序中的所有字符中字面值(如”abc”)都作为此类的实例实现,字符串是常量:他们的值在创建后就不能更改
在java中 .存储每一个字符均使用2个字节来保存,使用的是Unicode编码,并且任何一个字符(无论是英文还是汉子)每个字符的长度都是1,所以字符串的长度就是该字符串所有的字符个数.
API:
JDK中包含大量的API类库,所谓(API_Application programing Interface)应用程序编程接口:就是一些已经写好的,可供直接调用的功能(在Java语言中,这些功能以类的形式封装).
JDK API
JDK API包含的类库功能强大,经常使用的有:字符串操作,集合操作.文件操作,输入输出操作,网络操作,多线程操作等等.
JDK包含的API中存储一个字符均用2个字节保存,用Unicode编码(定长编码1个字符长度为1)
为了便于维护和使用,JDK类库按照包结构划分,不同功能的类划分在不同的包中.
经常使用的包:
Java.long java 程序的基础类.如:字符串,多线程等(只有此包特殊)
包中的类使用的频率相对高,不需要import可直接使用.
Java.util 常用的工具类,如集合,随机数产生器,日历,时钟等
Java.Io 文件操作.输入/输出 操作
Java.net 网络操作
Java.math 数学运算相关操作
Java.security 安全相关操作
Java.sql 数据库
Java.text 处理文字,日期,数字,信息的格式等
字符串:
字符串常量池(String常量池)是最底层的final
类是不能被继承以及改变
java字符串有一个优化措施,就是在堆内存中开辟了一段空间用来储存曾经创建的字符串对象(字面量形式创建才会储存)以便重用他们 这样可以减少因大量内容相同的字符串对象的创建,降低内存开销
对于重复出现的字符串直接量,JVM会首先在常量池中查找,如果存在即返回该对象
字面量:
字面量是指有字母,数字,下划线,$等构成的字符串或数值,他只能作为右值出现,
所谓右值:等号右边的值
如:int a = 0; a为左值 123为右值.
StringBuffer概述:
StringBuffer :字符缓冲区
StringBuffer和String 区别:
String 一旦被创建后,值不能被改变,如果参与了操作,引用发生了变化不是在原有的字符串上操作,而是产生了一个新的字符串
System系统类 Day04
系统类中的arrarcopy()
包装类:
包装类的功能就是把基本数据类型转换成类,就是把一个数包装成对象,当对象用
基本数据类型: 包装类
byte Byte
sort Short
int Integer
long Long
boolean Boolean
char Character
float Float
double Double
1.包装类是不可变类,在构造了包装类对象后,不允许更改包装在其中的值.
2.包装类是final的,不能定义他们的子类.
包装类的由来:
包装类由于基本类型没有面向对象的特性,在实际开发中不能直接参与面向对象的开发环节,为此Java为这个基本,类型提供了对应的包装类,其中6数字类型都继承Number,而char,bolean 的包装了继承自己的object
自动拆装箱:
在JDK1.5的时候推出了一个新的特性,自动拆装箱
自动拆装箱是编译器认可的特性,而非jvm认可,当编译器在编译源代码时发现了基本类型与对应的包装之间互相赋值使用时会自动补充代码完成他们之间的转换工作.
拆箱和装箱
装箱:把int型转换成Integer--->new Integer(int i)
拆箱:把Integer转换成int-->intvalue()对象方法
装箱和拆箱是不需要我们主动调用的
Integer 数据类型的默认值是:null
int 类型的默认值是:0
所以做项目时建议用Integer类型的
集合
集合
需求:把一个班级的学生储存起来,使用数组.
数组的特性:数组的长度是固定的,无法满足动态数组的添加.
集合的特性:长度可变,只能储存对象类型(由于有包装类的存在,集合可以储存任何类型)
collection
在实际开发中,需要将使用的对象存储于特定的数据结构的容器中所以JDK提供了一种这样的容器-----(集合 collection)
collection是一个接口,里面定义了相关的操作方法,其有两个子接口分别是List和set接口,集合也叫容器,用于储存对象.我们根据不同的需求和不同的数据结构来对集合做了不同的抽象
List
List:可重复集,元素是否重复,取决于元素的equals()比较结果
Set
Set:不可重复集,该集合中是不能将相同的元素存入集合两次,同list
集合中存储的都是引用类型元素,并且集合只保存每个对象的引用,而并非将元素对象本身存入集合
集合中封装的方法:
add 和 contains
add()
--boolean add(E e)添加成功则返回true,
否则false
contains()
--boolean contains(object o):该方法用于
判断给定的元素是否被包含在集合中若包含则返回true,否则返回false,这里需要注意的是集合在判断元素是否被包含是根据equals()方法的比较结果,通常重写equals保证contains()的合理结果
addAll
addAll(Collectionc)
将指定collection中的所有元素都添加到此collection中(可选操作)
boolean remove(E e)
boolean remove(E e)从集合中删除给定的
元素,用equals比较结果
clear()清除
removeAll(colleciton c)
Iterator(迭代器)
collection提供了统一的遍历集合的方式:迭代器方法为Iterator inerator()方法获取
一个可以遍历当前集合的迭代器.
Java.util.Interator接口
迭代器接口规定了用于遍历集合的方法.
不同的集合都实现了一个迭代器的实现类,用于遍历自身.我们无需记住每种迭代器实现类的名字,只需要将其看作Iterator遍历集合即可.
迭代器遍历集合的通用模式:遵循:问,取,删.
其中删除元素,不是遍历集合的主要操作.
获取用于遍历集合的迭代器:
Iterator it = c.inerator();
Iterator it = c.inerator();
while(it.hasNext()){//boolean hanNext()
判断集合是否还有下个元素可以遍历
String str =
system.out.println|(str);
system.out.println|(str);
if("#"equals(str)){//在使用迭代器遍历的过程中不能通过集合的方法增珊元素
it.remove();
}
system.out.println(c);
List的储存方法
1.add(E e)向列表尾部添加指定的元素
*(可选操作)
2.add(int index, E element)在列表的
指定位置插入指定元素(可选操作).
3.addAll(collectionc)
添加指定collection中的所有元素到此列表的结尾,顺序是指定collection的迭代器返回这些元素的顺序(可选操作)
4.addAll(int index,collectionc)将指定collection中的所有元
素都插入到列表
string 9月18号
String s1=new String(“abc”);
String s2=”abc”
有什么区别 ?
前者创建了两个对象 后者创建了一个对象
变量s1是一个内存
New String();是另外一个内存
new String();是另外一个内存
//1.创建了一个学生类的对象
//2.调用了无参构造方法
Student s=newStudent();
StringBuilder
java.long.StringBuilder
由于String的设计不利于频繁的修改内容,所以java专门提供了一个用于修改字符串内容的类:StringBuilder
StringBuilder提供了一个可变的字符数组,所以字符串内容的修改都是在这个数组中进行,而不会每次修改都创建一个新对象.
String,StringBuffer和StringBuilder的区别:
简述:String,Stringbuffer和StringBuilder
String的长度是不可改变的;StringBuffer的长度是可变的.如果对字符串的内容进行操作,特别是内容要修改的,则只使用StringBuffer如果最后需要String,那么使用StringBuffer的toString()方法转换成String类型数据,StringBuffer是线程安全的.
而从JDK1.5开始,为StringBuffer类补充了一个单线程使用的等价类即StringBuilder.
而StringBuilder类是非线程安全的,因为它支持所有相同操作,但由于它不执行同步,所以速度更快.
泛型
泛型:就是提前指定要操作的数据类型
在集合中使用的语法:
list<数据类型>变量名=new ArrayList<数据类型>();
自定义一个泛型:
语法:class/interface类名/接口名
}
T只是泛型的一个标准,使用什么字符都可以,但是都要大写,不要使用特殊字符.建议用T,E也凑合.
泛型的作用:
是约束集合当中的元素类型的,泛型是JDK1.5之后推出的一个新特性;
泛型有称为参数化类型,在实例化某个类时,指定泛型的具体类型.泛型是编译器认可的,原型是object指定泛型可以使编译器帮助检测类型匹配以及做自动造型,最常在集合中使用,用来约束元素类型.
注:不指定泛型则默认为原型object.
HashSet类
HashSet类实现了Set接口,由哈希表(实际上是一个HashMap实例)支持,它不保证set的迭代顺序:特别是它不保证该顺序恒久不变.此类允许使用null元素HashSet的唯一性:
在HashSet做添加的时候会逐个来判断当前集合中的对象和要添加的对象的比较通过以下的条件判断两个对象是否相等.
e.hash==hash&&((k=e.key)==key||key.equals(k))
hash值必须相等比并且两个对象的地址值相等或者equals返回true
Set里的元素是不能重复的,那么用什么方法来区分重复与否呢?
ArrayList和linkedList:
list接口是Collection的子接口,用于定义线性表数据结构,可以将list理解为存放对象的数组,只不过其元素个数可以动态的增加或减少
List接口的两个常见实现类为ArrayList个LinkedList分别用动态数组和链表的方式实现了List接口.
可以认为ArrayList和linkedList的方法在逻辑上完全一样,只是在性能上有一定的差别.ArrayList更适合于随机访问而LinkedList更适合于插入和删除.在性能要求不是特别苛刻的情形下可以忽略这个差别
如: 吉利和法拉利的区别
ArrayList内部本身就是数组,添加元素需要扩容,但扩容这件事不用你干,所以ArrayList查的快,但是增删麻烦.
工具类Arrays;
toArray(方法)
collection提供了集合可转换为数组 的方法:toArray()
输出是集合可直接点数组Arrays.toString(数组)
collections的sort()方法要求集合必须是可比较的
这就意味着元素必须实现Comparable接口并重写比较方法compareTo(
抽象方法
抽象方法int compareTo(T t);
而所有子类都需要重写该方法来定义对象间的比较规则,该方法要求返回一个整数,这个整数不关心具体的值,而关心取值范围.
Collection
Collection的sort方法仅能对list集合进行排序(有序)是对集合元素的自然排序,那么两个元素对象之间就一定要有大小之分,在使用collection的sort排序的集合元素都必须是comparable接口的实现类.该接口表示其子类是可比较的.
Map
Map就是键值对的集合的接口的抽象
使用的时候通过key的值来获得对应的value值,将键映射到值的对象.一个映射不能包含重复的键,每个键最多只能映射一个值,键只允许有一个空值,值可以有多个空值
注:Map集合和之前学过的collection接口无关
Map是接口又称为查找表,用于存储key-value映射对,key可以看成是value的索引,作为key的对象,在集合中不可重复.Map接口中有多种实现类,其中常用的有内部Hash表,实现的HashMap和内部排序为二叉树实现的TreeMap
map put(K k,V v)
* 将给定的key-value对存入Map
* 由于Map不允许存放重复的key,所以
* 若使用Map已有的key存放一个新的value时则是替换
* 该key原来对应的value值,那么put()方法返回的
* 就是被替换的这个value值,若key不存在则put方法返回
* null
map的特点:
1.成对出现的
2.数据的键是唯一的
3.一个键只能对应值
4.值可以重复
5.键允许有一个为空,值可以多个是空
Map集合和collection集合的区别?
答:1.Map集合是键值对的集合,Collection是单一出现的数据的集合.
1.Map的键是唯一的,而Collection的子接口Lis人集合中的元素是可以重复的set是唯一的
2.map是夫妻对,collection是单身狗.
list和map的区别
一个是储存单列数组的集合,另一个是存储键和值这样的双列数据的集合.List中储存的数据是有序的,并且允许重复:map中存储的数据是没有顺序的,其键是不能重复的,他的值是可以复制的;
List,Map和Set三个接口,存取元素是,各有什么特点?
这样的题属于随意发挥题:一是要真正明白这些内容,而是要有交钱的总结和表达能了
首先,list与set具有相似性,都是单列元素的集合,所以他们有一个共同的父接口,叫Collection.Set里面不允许有重复的元素,所谓重复,即不能有有两个相等的对象,即假设set中有一个A对象,现在我要在set中在存入B,但是B与A的equals相等,则B 对象存储不进去,所以,Set集合的add方法有一个boolean的返回值,当集合中没有某个元素,此时add方法可以成功加入该元素是,则返回true,当集合中有事,add方法无法加入该元素,返回false, Set取元素时.此时,没法说取第几个,只能以Iterator接口取得所有元素在逐一遍历各个元素.
List表示有先后顺序的集合,逐一,不是那种按年龄大小,,价格之类的排序,当我们多次调用add(Object e)方法时,每次加入的对象就像火车站买票有排队顺序一样,先来后到但也可插队.即调用add(int index obj e)方法,就可以指定当前对象集合中的存放位置.一个对象可以被反复储存到list中,每调用一次add方法,这个对象就被插入进集合中一次,其实.并不是把这个对象本身储存到集合中,而是在集合中使用了一个索引变量指向这个对象,当这个对象被add多次是,即相当于集合有多个索引指向了这个对象
list除了可以以Iterator接口取得所有元素,在逐一遍历各个元素外,还可以调用get(index)来明确说明取第几个.
Map与list和set不同,他是双列集合 ,其中有put方法,定衣如下:
put(obj key, obj value_每次储存是,要储存一堆key/value不能储存重复的key,这个重复的规则也是按equals比较像等.
取则可以根据key获得相应的value,即get(Object key)返回值为key所对应的value.另外,也可以获得所有的key的集合,还可以获得所有的value的集合,还可以获得key 和value组合的MapEntry的对象的集合
list一特定次序来持有元素,可有重复元素,set无法有重复元素,内部排序,Map保存key-value值,value可多值.
HashSet按照hashCode值的某种运算方式进行存储,而不是直接按hashCode值的大小进行存储,例如”abc”->78,”defà62”,”xyz”à65在HashSet中的存储顺序不是62,65,78.
Map的实质就是一个数组,为什么查询速度比数组快呢?(当今世界上查询速度最快的算法)..
1).根据key来查找value,key相当于身份证号,用put()方法,存元素的时候要经过前台的散列算法,调用key的hashCode方法,根据计算key-value对儿存入.
Map之所以查询速度快就是根据key直接算出value的位置,而不需要遍历.所以其不受数据量的影响.
散列算法
散列算法是有瑕疵的,key的hashCode觉得key-value键值对在数组中的位置,如果有两个key的hashCode值一样,且不是原来的key,就需要在bucket种的某一个格子中放两个key-value元素,entry有两个属性:
1.一个entry表示一组键值对
2.entry是一个地址 ,地址记录的是他的下一个entry是谁,所以说entry也是一个链表.所以在Map中有两个值的hashCode值一样,但是这两个key不是同一个key的时候了,他就会形成链表.
弊端是根据key提取value的时候,就会出现遍历链表的操作,所以速度会慢,因此要避免Map中出现链表
其中是否形成链表,key起着关键作用,key的HashCode觉得key在数组中的什么位置,map根据key来判断是不是重复的key要根据equals()方法
首先:2个key的HashCode值一样,表示2个key在数组的同一个格子里,如果equals比较是false,说明是两个key.所以就会形成两个链表,因为key是泛型指定,所以什么类型都可以放.
而在java中,所有的类都有hashCode方法,Object提供的hashCode和equals()都不用重写.
HashCode特点
HashCode是Map的实现类,其特点如下:
1.HashMap是map的实现类
2.允许有多个null值和一个null键
3.HashMap中的元素没有顺序,(跟添加的顺序无关)
4.HashMap不是线程安全的
HashMap是Map的一个常用的子类的实现,其实是用散列算法实现的.
HashMap内部维护着一个散列数组(就是一个存放元素的数组),美其名曰散列桶,而当人们向HashMap中存入一组键值对时,HashMap首先获得key这个对象的HashCode()方法的返回值,然后使用该值进行一个散列算法,得出一个数字,这个数字就是这组键值对要存入散列数组中的下标位置.
根据下标位置,HashMap还会查看散列数组当前位置是否包含该元素,(这里要注意的是散列数组中每个元素并非是直接储存键值对的,而是存入了一个链表,这个链表中的每个节点才是真实保存这组键值对的)
检查是否包含该元素时要根据当前要存入的key在当前散列数组对应的位置中的链表里是否已经包含了这个key,若不包含则将这组键值对存入链表,否则就替换value
那么在获取元素时,HashMap同样先根据key的hashCode值进行散列算法,找到他所在散列数组中的位置,然后遍历该位置的俩表,找到该key所对应的value之后返回
看到这里可能有个疑问,聊表中应该只能存入一个元素,那么HashMap是如何将Key-value存入链表的某个节点的呢?实际山,HashMap会将每组键值对封装为一个Entry的实例,然后将该试了存入链表.
什么是链表节点?
size()跟capacity()
size()就是map中键值对的个数
capacity是容量,就是数组的长度
loadfacto加载因子size/capacity=loadfactor
加载因子的默认值是3/4=0.75
意味着向bucket(桶中)map中存的键值对个数永远不能超过数组长度的3/4
例如:默认长度是16,里面就能放12个键值对,如果超过这个比值就会出现数组扩容(自动进行).
为什么只占3/4呢?
根本原因 还是尽可能的避免出现链表,如果默认的16个格都放满,就会导致可选的房间少,而散列算法是不会变的,唯一可变的值hashCode值,但hashCode值不是算法的唯一参数.那么计算出来的数字如果不能控制在一个范围内,就有可能超出数组的长度,12=3x4 12=2x6.不可控制后面的数字.
一旦超出数组的长度就会发生数组下标越界,所以你算完的值一定在其 下标允许的范围内,意味着数组的length也是散列算法的一个参数,所以hashCode值不变.size的长度小,就会导致算出来的位置可选的就比较少,所以就容易出现2个键值对在一个格子中,
例如默认的是16个格子,4x4=16 2x8=16 hashCode值不一样,要想保证算出来的值都不一样,每个格一个元素这是做不到的.
散列算法=hashCode()x(数组长度length)
map内部数组扩容,所有元素都有rehash,纳秒级响应.
map
map的接口哈希表和链表实现,具有可预知的迭代顺序,此实现与HashMap的不同之处在于,LinkHashMap维护者一个双向链表,此链表定义了迭代顺序,该迭代顺序通常就是元素的存放顺序,需要注意的是,如果在Map中重新存入已有的key,,那么key的位置不会发生变化,只是将value替换
文件操作
java.io.File
java.io.File用于表示文件(目录),也就是说程序员可以通过File类再程序中操作硬盘上的文件和目录.
File
File类只用于表示文件(目录)的信息(名称,大小),等,换句话说只能访问或目录的相关属性,不能对文件的内容进行访问.
1.可以访问一个文件或目录的属性信息
2.操作一个文件或目录(创建,删除)
3.访问一个m目录的子项
但是不能使用File访问文件数据
生而为人 我很抱歉
被嫌弃的松子的一生
是嘲讽吧,当你觉得人生快要完了的时候 它还在继续 当你觉得人生要重新开始的时候,它却完了.
File day09
File
File file =new File(“d:/xxx/xxx/x.txt”);
不建议写绝对路径的原因是绝对路径都是操作系统规定的,一旦使用就证明你的底层系统有一个严重的耦合关系.如果按照以上写法就会一次编程到处调错,在Linux中不认识:d
所以java为了避免跟底层系统相关的差异性,他就把目录分隔符”/”用了一个常量去表示File.separator,在Linux系统中是”/”在Windows系统中是”\”.
递归:
什么是递归?
递归就是反复调用方法自身,递归一定有跳出条件.
IO流
java标准io
IO流根据方法分为:
1. 输入流:外界到我们编写的程序中的方向,所有输入流是用于从外界获取数据的流,简称读操作
2. 输出流:将数据从我们编写的程序发送到外界的方向的写操作.
IO流根据流来区分分为:
1. 节点流:节点流称为低级流是实际连接程序与数据源的”管道”,负责传输数据,而读写操作一定是建立在节点流上进行的.
2. 处理流:处理流又称为高级流,用于处理其他流,不能独立存在(没有意义),使用高级流处理其他流的目的是通过高级流带来的功能简化我们对数据读写时的某些复杂处理.
文件流
FileInputStream,FileOutputStream
它们是一对低级流,作用是对文件读写数据
文件流符合java标准的IO操作
IO流在java中从数据角度来分类为:
1. 字符流:文本,我们能读懂的都可以 认为是字符流 如文章
2. 字节流:二进制数据,这种数据一般用文本打开 ,我们读不懂,比如:图片翁不军军军军,MP3文件等等.
字符流的超类:
Reader:子类FileReader,BufferedReader
字符输出流的超类:
Writer:子类FileWriter,BufferedWriter
缓冲字符流;
缓冲字符流由于内部有缓冲区,所以读写的效率高,并且字符流的特点是可以按行读写字符串
流 day0927
需求:定义学生类(学号,姓名,年龄,性别,成绩,)将学生名单输出到”学生名单.txt中”
输出换行:
把 文本写入到文件总\n代表换行
然而不同的环境下换行的方式是不一样的
windows:\r\n
Linux:\n
Mac:\r
newline():可以换行,高效缓冲区的输出流的扩展方法:
字节流的概述
字节输入流:InputStream:常用子类:FileInputStream
字节输出流:OutputStream:常用子类:FileOUtStream
缓冲流:
BOS-BufferedOutputStream基本工作原理
在向硬件设备做写出操作是,增大写出次数,无疑会降低写出效率,为此我们可以使用缓冲输出流来一次性批量写出若干数据,减少写出次数来提高写出效率
BufferedOutputStream
BufferedOutputStream缓冲输出流内部维护这一个缓冲区,每当我们向该流写出数据是,都会先将数据存入缓冲区,当缓冲区已满是,缓冲流会将数据一次性全部写出.
BIS-BufferedInputStream
在读取数据时,若以字节为单位读取数据,会导致读取次数过于频繁从而大大降低读取效率,为此我们可以通过提高一次读取的字节数量减少读取次数来提高读取效率.
BufferedInputStream
BufferedInputStream是缓冲字节输入流,其内部维护着一个缓冲区(字节数组)使用该流在读取一个字节时,该流会尽可能多的一次性读取若干个字节并存入缓冲区,然后逐一的将字节返回,直到缓冲区中的数据全部被读完毕,会再次读取若干个字节从而反复这样就减少了读取的次数,从而提高了读取效率.
BIS是一个处理流,该流为我们提供了缓冲功能
对象流:
对象流是一组高级流,作用是通过这组流可以方便的读写java中的任何对象
对象输出流
对象输出流:用于写出对象,用于底层读写都是 字节读写,所以无论怎么样的数据都要转换为字节才能看出,对象输出流可以自行将给定的对象转换为一组字节然后写出,省去了我们将对象按照结构转化为字节的麻烦.
对象序列化的概念:
对象是存在于内存中的,有时候我们需要将对象保存到硬盘上,又有时候我们需要将对象传输到另一台计算机上等等这样的操作,这时我们需要将对象转换为一个字节序列,而这个过程就成为对象的序列化.相反,我们有这样的一个字节序列,需要将其转换为对应的对象,这个过程就称为对象的反序列化.
字符流:
java根据读写数据的单位划分了:字节流,字符流
InputStream,OutputStream是所有字节输入流与字节输出流的父类
常用实现类:
FileInputStream,
BufferedInputStream等
缓冲字符流:
缓冲字符流由于内部有缓冲区,读写字符的效率高,并且字符流特点是按行读写字符串.
PrintWriter也是缓冲字符输出流,它内部总是链接BufferWriter除此之外PW还提供了自动刷新功能,所以更常用.
字节流与字符流的区别:
要把一片二进制数据逐一输出到某个设备中,或者从某个设备中逐一读取一片二进制数据,不管输入输出设备是什么,我们要用统一的方式来完成这些操作,用一种抽象的方式进行
InputStreamReader完成byte流解析为char流,按照编码解析.
OutputStreamWriter:提供char流到byte流,按照编码处理.
ISR读取和OSW写入:实例:
InputStream is =new FileInputStream(“gbk.txt”);
InputStreamReader in =new InputStreamReader(is);
OutputStreamWriter ow=new OutputStreamWriter(new FileOutputStream(filename))
int c;
while((c=in.read())!=-1){
ow.write(c);
ow.fluse();
}
int c ;
while ((c=in.read(chars,0,chars.length))!=-1)}
String s=new String(char,0,c);
system.out.pringln(s);
ow.write(char,0,c);
ow.flush();
}
BR 和BW
字符流的过滤器是字符 读写的功能扩展,极大的方便了文本的读写操作.
BufferedReader br=new BufferdeReader(new InputStreamReader (new FileInputStream(Srcfiname))):
BufferedWriter bw=new BufferedWrite(new OutputStreamWriter(new FileOutputStream(tatgetfile)));
String str=null;
while((sstr=br.readLine())!=null){//不识别换行
bw.write(str);
bw.newLine();//换行
bw.flush();
}
FR和FW
FileReader fr=new FileReader(filename)
FileWriter fw=new FileWriter(“d:\\fw.txt”)
int c;
while((c=fr.read())!=-1){
fw.write(c);
fw.flush();
}
PrintWriter
PrintWriter(File file):使用指定文件创建不具有自动行刷新的心PrintWriter.
PrintWriter(OutputStream out):根据现有的OutputStream创建不带自动行刷新的新PrintWriter.
PrintWriter(OutputStream out,Boolean autoFlush):通过现有的OutputStream创建新的PrintWriter.
PrintWriter(String filename):创建具有指定文件名称且不带自动行刷新的新PrintWriter.
PrintWriter(Writer out ):创建不带自动行刷新的新PrintWriter.
PrintWriter(Writer out,Boolean autoFlush):创建新PrintWriter.
例如:
PrintWriter pw =new PrintWriter(“d:\\pw.txt”);
pw.flush();
BufferedReader br =new BufferedReader (new InputStreamReader(System.in));
while (true){
String str=br.readLine();//从控制台读取一行读到end结束
System.out.println(str);
if(“end”.equals(str))
break;
}
OIS和OOS:
将object转换为byte序列,就是序列化,反之叫反序列化,为了在byte流中存储对象,使用writeObject()/readObject()进行序列化和反序列化.
Serializable接口:
Serializable
Serializable是序列化接口,对象必须实现序列化接口,才能进行序列化,否则出现不能序列化的异常!
Transient
Transient是java语言的关键字,用来表示一个域不是该对象序列化的一部分,序列化也叫串行话.
当一个对象被序列化的时候,transient型变量的值不包括在序列化的表示中,然而非transient型的变量是被包括进去的.
注:Transient修饰的属性可以通过其他手段进行序列化,可以参考ArrayList源码,ArrayList中底层数组是用transient修饰但进行了序列化.
OOS----ObjectOutputStream writerObject(Object):序列化对象
OIS---
final
final用于声明属性,方法,和类分别表示属性不可变,方法不可重写,类不可被继承.
内部类要访问局部变量,局部变量必须定义成final类型.
finally
finally是异常处理语句结构的一部分,表示总是执行.
finalize是object定义的一个方法,所以所有的类都具有该方法,该方法是GC在释放一个实例的时候调用的,这意味着该方法调用完毕这个对象就会被释放了.
finally块只能定义在异常捕获机制中且一般放在最后,即try后面或者最后一个catch之后.
finally块可以保证其中的代码一定执行,无论try语句块中的代码是否抛出异常,多以通常会将无关乎程序出错而都要执行的代码应当放在finally中比如:流的关闭操作.
InputStream:
1. FileInputStream
2. ByteArrayIbputStream
3. FilterInputStream
4. ObjectInputStream
5. StringBufferInputStream
6. PipedInputStream
7. SequenceInputStream
8. StringBufferInputStream
OutputStream:
1. FileOutputStream
2. ByteArrayOutStream
3. FileOutStream
4. ObjectOutputStream
5. PipedOutputStream
FileInputStream(构造器,异常,close)
1. FileInputStream(File file)通过打开一个到实际文件的连接来创建一个FileInputStream,该文件通过文件系统中的File对象file指定.
2. FileInputStream(String name)通过打开一个到实际文件的连接来创建一个FileInputStream该文件通过文件系统中的路径名name指定.
3. IOException当发生某种I/O异常时,抛出此异常,此类为异常的通用类,它是由失败的或中断的I/O操作生成的.
4. close(方法)关闭此输入流并释放与该流有关联的所有系统资源.
FileInputStream(read)
int read():读取一个byte无符号填充到int第八位,-1是EOF(end of file)
int read(byte[] b):从此输入流中将最多b.length个字符的数据读人一个字节数组中,返回读取的字节的个数.
int read(byte[]b,int off ,int len):从此输入流中最多len个字节的数据读入一个字节数组中
实例如下:
File file =new File();
InputStream is =new FileInputStream(file)://打开文件
int b;
while((b=is.read())!=-1){
system.out.pring(Integer.to String(b)+””);
}
is.close();
FileOutputStream(构造)
FileOutputStream(File file):创建一个向指定File对象表示的文件中写入数据的文件输出流.
FileOutputStream(File file ,Boolean append):创建一个向指定File对象表示的文件中写入数据的文件输出流.
FileOutputStream( String name):创建一个向具有指定名称的文件中写入数据的输出流.
FileOutputStream(String name,Boolean append):创建一个向具有指定name的文件中写入数据的输出文件流
FileOutputStream(WriteO):
void write(byte[] b):b.length个字节从指定字节数组写入此文件输出流中.
void write(byte[] b,int off ,int len):将指定字节数组中从偏移量off开始的len个字节写入到此文件输出流.
void write(int b):将指定字节写入此文件输出流.
节点流和过滤流:
FileInputStream和FileOutputStream,节点流,用于从文件中读取或往文件中写入字节流.如果在构造方法FileOutputStream时,文件已经存在,则覆盖这个文件.
BufferedInputStream和BufferedOutputStream,过滤流,需要使用已经存在的节点流来构造,提供带缓冲的读写,提高了读写的效率.
DataInputStream和DataOutputStream,过滤流,需要使用已存在的节点流来构造,提供了读写java中的基本数据类型的功能.
PipedInputStream和PipedOutputStream管道流.用于线程间的通信,一个线程的pipedInputStream对象从另一个线程的PipedOutputStream对象读取输入,要是管道流有用,必须同时构造管道输入流和管道输出流.
BIS基本原理:
BufferedInputStream是一个带有缓冲区的输入流,通常使用它可以提高我们的读取效率.
1. 每次调用read()方法的时候,它首先尝试从缓冲区里读取数据
2. 若读取失败,(缓冲区无可读取数据)则选择从物理数据源(比如文件)读取数据(这里后悔尝试可能读取多的字节放入到缓冲区中).最后在将缓冲区的内容不部分过全部返回给用户,由于缓冲区里读取数据远远比直从物理数据源(比如文件)读取速度快,所以BufferedInputStream的效率很高.
Bos基本原理:
BufferedOutputStream为IO操作提供了缓冲区,写入操作时,加上缓冲流这种流模式是为了提高IO输出的性能.例如我们想从应用程序吧数据放入文件,想到与将一缸水倒入另一个缸中:
1. 仅适用Fos的writer( )方法,相当于一滴水一滴水的”转移”
2. 使用Bos的Writerxxx( )方法更方便,相当于从DOS一瓢一瓢放入桶( BOS)中,再从桶(BOS)中倒入另一个缸,性能提高了.
BUfferInputStream是一个带有缓冲区
的输入流,通常使用它可以提高我们的读取效率.
1.每次调用read()方法的时候,它首先
从缓冲区里读取数据
2.若读取失败,(缓冲区吴可读数据)
3.则选择从物理数据源(譬如文件)读取
数据(这里会尝试尽可能读取多的字节放入缓冲区中.)
4.最后再将缓冲区的内容部分或全部防
回给用户,由于从缓冲区里读取数据远比直接从物流数据源(譬如文件)读取速度快,所以BufferedInputStream的效率很高
字符流:
ISR和OSW概述:
1. 字符的处理,一次处理一个字符(Unicode)
2. 字符的底层仍然是基本的字节流
3. 字符流的基本实现:
InputStreamReader完成byte流解析为char流,按照编码解析.
OutputStreamWriter:提供char流到byte流,按照编码处理.
ISR读取和OSW写入:实例:
InputStream is =new FileInputStream(“gbk.txt”);
InputStreamReader in =new InputStreamReader(is);
OutputStreamWriter ow=new OutputStreamWriter(new FileOutputStream(filename))
int c;
while((c=in.read())!=-1){
ow.write(c);
ow.fluse();
}
int c ;
while ((c=in.read(chars,0,chars.length))!=-1)}
String s=new String(char,0,c);
system.out.pringln(s);
ow.write(char,0,c);
ow.flush();
}
BR 和BW
字符流的过滤器是字符 读写的功能扩展,极大的方便了文本的读写操作.
BufferedReader br=new BufferdeReader(new InputStreamReader (new FileInputStream(Srcfiname))):
BufferedWriter bw=new BufferedWrite(new OutputStreamWriter(new FileOutputStream(tatgetfile)));
String str=null;
while((sstr=br.readLine())!=null){//不识别换行
bw.write(str);
bw.newLine();//换行
bw.flush();
}
InputStreamReader完成byte流解析为char流,按照编码解析.
OutputStreamWriter:提供char流到byte流,按照编码处理.
ISR读取和OSW写入:实例:
InputStream is =new FileInputStream(“gbk.txt”);
InputStreamReader in =new InputStreamReader(is);
OutputStreamWriter ow=new OutputStreamWriter(new FileOutputStream(filename))
int c;
while((c=in.read())!=-1){
ow.write(c);
ow.fluse();
}
int c ;
while ((c=in.read(chars,0,chars.length))!=-1)}
String s=new String(char,0,c);
system.out.pringln(s);
ow.write(char,0,c);
ow.flush();
}
BR 和BW
字符流的过滤器是字符 读写的功能扩展,极大的方便了文本的读写操作.
BufferedReader br=new BufferdeReader(new InputStreamReader (new FileInputStream(Srcfiname))):
BufferedWriter bw=new BufferedWrite(new OutputStreamWriter(new FileOutputStream(tatgetfile)));
String str=null;
while((sstr=br.readLine())!=null){//不识别换行
bw.write(str);
bw.newLine();//换行
bw.flush();
}
FR和FW
FileReader fr=new FileReader(filename)
FileWriter fw=new FileWriter(“d:\\fw.txt”)
int c;
while((c=fr.read())!=-1){
fw.write(c);
fw.flush();
}
PrintWriter
PrintWriter(File file):
PrintWriter(File file):使用指定文件创建不具有自动行刷新的心PrintWriter.
PrintWriter(OutputStream out):
PrintWriter(OutputStream out):根据现有的OutputStream创建不带自动行刷新的新PrintWriter.
PrintWriter(OutputStreamout,Boolean autoFlush):
PrintWriter(OutputStreamout,Boolean autoFlush):通过现有的OutputStream创建新的PrintWriter.
PrintWriter(String filename):
PrintWriter(String filename):创建具有指定文件名称且不带自动行刷新的新PrintWriter.
PrintWriter(Writer out ):
PrintWriter(Writer out ):创建不带自动行刷新的新PrintWriter.
PrintWriter(Writer out ):
PrintWriter(Writer out )::创建新PrintWriter.
例如:
PrintWriter pw =new PrintWriter(“d:\\pw.txt”);
pw.flush();
BufferedReader br =new BufferedReader (new InputStreamReader(System.in));
while (true){
String str=br.readLine();//从控制台读取一行读到end结束
System.out.println(str);
if(“end”.equals(str))
break;
}
OIS和OOS:
将object转换为byte序列,就是序列化,反之叫反序列化,为了在byte流中存储对象,使用writeObject()/readObject()进行序列化和反序列化.
Serializable接口:
Serializable是序列化接口,对象必须实现序列化接口,才能进行序列化,否则出现不能序列化的异常!
Transient
Transient是java语言的关键字,用来表示一个域不是该对象序列化的一部分,序列化也叫串行话.
当一个对象被序列化的时候,transient型变量的值不包括在序列化的表示中,然而非transient型的变量是被包括进去的.
注:Transient修饰的属性可以通过其他手段进行序列化,可以参考ArrayList源码,ArrayList中底层数组是用transient修饰但进行了序列化.
OOS----ObjectOutputStream writerObject(Object):序列化对象
OIS----ObjectInputStream readObject():对象的反序列化.
线程:
java语言的优势之一就是线程处理较为简单.
一般操作系统都支持同时运行多个任务,一个任务通常就是一个程序,每个运行中的程序被称为一个进程,当一个程序运行时,内部可能包含多个顺序执行流,每个顺序执行流就是一个线程.
程序
程序:指令+数据的byte序列,如:qq.exe
进程:正在运行的程序,是程序动态的执行过程(运行于内存中)
线程:在进程内部,并发运行的过程(java中的方法可以看做线程)
并发:进程是并发运行的,os将时间划分为很多的时间片段(时间片)然后CPU将这些片段尽可能的均匀的分配给正在运行的程序,微观上进程是走走停停,宏观上是都在运行,这种运行的现象叫并发,但是不是绝对意义上的”同时发生”.
InputStreamReader完成byte流解析为char流,按照编码解析.
OutputStreamWriter:提供char流到byte流,按照编码处理.
线程的实现:
创建新执行线程有两种方式:
Thred类代表线程类型
任何线程对象都是Threan(子类)的实例
Thred类是线程的模板(封装了复杂的线
程开启等操作,也封装了操作系统的差异性)
只要重写run()方法即可实现具体线程
方式一:
继承Thread并重写run()方法,并在run方法中添加线程要执行的任务代码
注意:启用线程要调用线程的start()方法,而不是直接调用run()方法.当strat()调用后线程纳入线程调度,一旦线程获取CPU时间片段后,该线程会自动调用run()方法.
此方式的不足之处:
1.由于Java是单继承的不能继承其他类
2.定义线程的同时,run()方法中定义
了线程要执行的任务,这就导致了线程与任务有一个必然的耦合关系,不利于线程的重用.
方式二:
实现Runnable接口单独定义线程任务使用内部创建线程,使用该方式可以简化编译代码的复杂度当一个线程需要一个实例使我们通常使用此方式创建
在互联网项目中存在大量的并发的案例,如卖火车票,银行取款,电商网站
如果不加约束就会出现并发安全问题.
针对线程的安全性问题,我们需要使用同步(就是要加锁,共享资源只能一个人访问)锁.
同步锁
语法:
synchronized(锁对象){
操作共享资源的代码
}
同步代码加在设么地方?
1.当代码被多个功线程访问的时候
2.代码中有共享的数据
3.共享数据被多条语句操作.
Synchronized Demo 1
Synchronized同步代码块的锁对象可以使任意类对象(线程的实现方式是使用继承于Thread),这个对象必须是线程类共享(静态的)
Synchronized是可以加载方法上,如果是静态的方法Synchronized的锁对象就是类的类 对象,如果不是静态的,Synchd如果加在对象方法上,那么它锁的是this
Sync2
多线程并发安全问题(执行混乱)
当多个线程并发访问同一个资源时,由于线程切换实际的不确定,会导致操作顺序违背代码设计的执行流程而出现混乱,严重时可能导致系统瘫痪.
Sync3
当一个方法被Synchronized修饰后 ,该方法成为”同步方法”即多个线程不能同时在方法内部 执行,同步监视器对象就是该方法所属对象,即方法内部看到的this
语法:
Synchronized(同步监视对象){
需要同步运行的代码片段
}
- StringBuffer是同步的synchronized append();
- StringBuffer不是同步的append();
- Vector和Hashtable是同步的
- ArrayList和HashMap不是同步的
- Collection.synchronizedList()
- Collection.synchronizedMap()
- ArrayList list=new ArrayList();
List syncList =collection.synchronizedList(list);
notify()he wait()
notify()he wait()只有使用锁的对象才能调用
yield()方法:
暂停当前正在执行的线程对象,并执行其他线程
----该方法用于使当前线程主动让出此次此次CPU时间片段,回到Runnable状态,等待分配时间片.
boolean isDaemon()
boolean isDaemon():测试线程是否为守护线程,如果返回的是true就是守护线程.
int getPriority()返回线程的优先级.
--long getId()返回该线程的标识符
--String getName()返回该线程的名称
--int getPriority()返回该线程的优先级
--Thread.state getState();互殴线程的状态
--boolean isDaemon():测试线程是否为守护线程
--boolean isInterrupted();测试线程是否已中断
synchronized
使用synchronized将现有集合转换为一个线程安全的集合.
ArrayList为什么不是线程安全的?
一个ArrayList,在添加一个元素的时候,它可能会有两步来完成:
1.在[Items[size]]的位置存放此元素
2.增大size的值,size++;
在单线程运行的情况下,如果size=0,添加一个元素,此元素在位置0而size=1;而如果是在多线程情况下,比如有两个线程,此线程A先将元素放在位置0.但是此时CPU调度的时间到,使线程A暂停.
线程B得到运行机会,线程B也向此ArrayList添加元素 因为此时,size仍然等于0(注意:假设的是添加一个元素是要两个步骤而线程A仅仅完成了步骤1),所以线程B也将元素放在位置0,然后线程A和线程B都继续运行,都增加size值.
现在我们来看看ArrayList的情况,元素实际上只有一个,存放在位置0,而size却等于2,这就是”线程不安全”了.
练习:
从桌子上取豆子,桌子上有20个豆子,用两条线程模拟,当豆子数为0时,线程结束,(模拟”抢”所出现的并发安全问题)
所谓同步执行:多个线程必须排队执行
所谓异步执行:多个程序可以同步执行
ISR读取和OSW写入:
实例:
InputStream is =new FileInputStream(“gbk.txt”);
InputStreamReader in =new InputStreamReader(is);
OutputStreamWriter ow=new OutputStreamWriter(new FileOutputStream(filename))
int c;
while((c=in.read())!=-1){
ow.write(c);
ow.fluse();
}
int c ;
while ((c=in.read(chars,0,chars.length))!=-1)}
String s=new String(char,0,c);
system.out.pringln(s);
ow.write(char,0,c);
ow.flush();
}
BR 和BW
字符流的过滤器是字符 读写的功能扩展,极大的方便了文本的读写操作.
BufferedReader br=new BufferdeReader(new InputStreamReader (new FileInputStream(Srcfiname))):
BufferedWriter bw=new BufferedWrite(new OutputStreamWriter(new FileOutputStream(tatgetfile)));
String str=null;
while((sstr=br.readLine())!=null){//不识别换行
bw.write(str);
bw.newLine();//换行
bw.flush();
}
FR和FW
FileReader fr=new FileReader(filename)
FileWriter fw=new FileWriter(“d:\\fw.txt”)
int c;
while((c=fr.read())!=-1){
fw.write(c);
fw.flush();
}
PrintWriter
PrintWriter(File file):使用指定文件创建不具有自动行刷新的心PrintWriter.
PrintWriter(OutputStream out):根据现有的OutputStream创建不带自动行刷新的新PrintWriter.
PrintWriter(OutputStream out,Boolean autoFlush):通过现有的OutputStream创建新的PrintWriter.
PrintWriter(String filename):创建具有指定文件名称且不带自动行刷新的新PrintWriter.
PrintWriter(Writer out ):创建不带自动行刷新的新PrintWriter.
PrintWriter(Writer out,Boolean autoFlush):创建新PrintWriter.
例如:
PrintWriter pw =new PrintWriter(“d:\\pw.txt”);
pw.flush();
BufferedReader br =new BufferedReader (new InputStreamReader(System.in));
while (true){
String str=br.readLine();//从控制台读取一行读到end结束
System.out.println(str);
if(“end”.equals(str))
break;
}
递归:
递归就是方法调用方法自身,递归一定有跳出条件
IO流
Java标io
Io流根据方向分为:
输入流:外界到我们编写的程序中的方向,所有输入流是用于从外界获取数据的流,简称读操作.
输出流:将数据从我们编写的程序发送到外界的方向写操作.
Io流根据流来区分:
节点流:节点流又称低级流,是实际连接程序与数据源的"管道",负责传输数据
读写操作,一定是建立在节点流上进行.
处理流:处理流又称高级流,用于处理其他流,不能独立存在(没有意义)
使用高级流处理其他流的目的是通过高级流到来的功能简化我们对数据
文件流
FileInputStream,FileOutputStream
他们是一对低级流,作用是对文件读写数据文件流符合Java标准的IO操作
IO流在Java中从数据的角度分类为:
1.字符流:文本,我们能读懂的都可以认为是字符流,比如:文章,Java文件等.
2.字节流:二进制数据,这种数据一般应文本打开,我们看不懂--比如:图片文件,MP3文件,等等.
字符输入流的超类: Reader:子类FileReader,bufferedReader
字符输出流的超类:
Writer:子类FileWriter,BufferedWriter
缓冲字符流:
缓冲字符流由于内部有缓冲区,所以读写的效率高并且字符流的特点是可以按行读写字符串
BufferedWriter;BufferedReader
缓冲字符流由于内部有缓冲区,读写字符的效率高
PrintWriter也是缓冲字符输出流,它内部总是链接BufferWriter除此之外PW还提供了自动行刷新功能
PrintWriter形式2:
PrintWriter提供了常规的构造方法,允许传入一个字节流或字符流
异常处理:
重点面试题:
1.Throwable,Error和Exception
Java异常结构中定义有Throwable类,Exception和Error是其派生类的两个子类,其中Exception表示由于网络故障,文件损坏,设备错误,用户输入非法等情况导致的异常而Error表示Java运行时环境出现的错误,例如:jvm内存资源耗尽
try {
需要处理的异常代码
} catch (XXXXXException e) {
当try中代码出错后再这里捕获并处理
}
2.什么是Java序列化,如何实现Java序列化?或者解释Serialzable接口的作用.
答:我们有时候将一个Java对象变成字节流的形式传出去或者从一个字节流中恢复成一个Java对象,例如:要将Java对象存储到硬盘或者传送到网络上的其他计算机这个过程我们可以自己写代码去把一个Java对象变成某个格式的字节流在传输,但是,JRE本身就提供了这种支持,我们可以调用OutPUtStream的writeObject方法来做,如果要让java帮我们做,要被传输的对象必须实现serializable接口这样,javac编译时就会进行特殊处理,编译的类才可以被writeObject方法操作这就是所谓的序列化。需要被序列化的类必须实现Serializable接口,该接口是一个mini接口,其中没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的。
例如:在web开发中,如果对象被保存在了session中,tomcat在重启时要把
Session对象序列化到硬盘中,这个对象就必须实现Serializable接口。
如果对象要经过分布式系统进行网络传输或通过rmi等远程调用,这就需要
在网络上传输对象,被传输的对象就必须实现Serializable接口。
FOS(构造)
FileOutputStream(File file):创建一
个指定File对象表示的文件中写入数据的文件输出流.
FileOutputStream(File file,boolean
append):创建一个向指定File对象表示的文件中写入数据的输出流.
FileOutputStream(String name):
创建一个向指定名称的文件中写入数据
的输出流.
FileOutputStream(String name,boole
an append):创建一个向具有指定name的文
件中写入数据的输出文件流
void write(byte[] b,int off.int len):
将指定字节数组从偏移量off开始的len个字节写入此文件输出流
void write(int b):将指定字节写入此
文件输出流
FOS(Write):
void write(byte[]b):将b.length个字
从指定字节数组写入此文件
计算机网络:
是指将地理位置不同的具有独立功能的多态计算机一级外部设备.
通过通信线路连接起来,在网络操作系统,网络管理软件以及通信协议的管理下,实现资源共享和信息传递的计算机系统.
网络通信的三要素:
IP地址;
端口号;
传输协议
HTTP协议
HTTP协议:超文本传输协议.是浏览器与服务器之间传输数据的协议,底层的协议为TCP协议.
HTTP则为应用层协议,负责定义传输数据的格式.
HTTP协议分为两个版本:1.0和1.1两个版本,现在常用的为1.1版本.
协议规定:客户端与服务端通讯方式为一次请求一次响应.
服务端不会主动发送内容给客户端,
客户端发起请求,服务端接受到请求后向客户端发起响应,采取一问一答的方式
JDBC(Java Database Connection)
JDBC是Java应用程序访问数据的里程碑式解决方案,Java研发者希望用相同的方式访问不同的数据库,以实现与具体数据库无关的Java操作界面.
JDBC订一客一套标准接口,即访问数据库的通用API,不同的数据库厂商根据各自数据库的特点去实现这些接口.
JDBC核心API-Connection
class.forName(“oracle.jdbc.OracleDriver”)
装载Driver类,Driver通过static块实现在DriverManager中的”自动注册”
Connection conn=DriverManager.getConnection(“jdbc:oracle:thin:@192.168.1.17”)
根据url连接参数找到与之匹配的Driver对象,调用其方法获取连接.
JDBC核心API-Statement:
创建Statement
Statement stmt =conn.createStatement();
执行指定的sql语句,可能返回多个结果
Boolean flag=stmt.execute(sql);
执行指定的sql语句,该语句返回单个的ResultSet
ResultSet rs =stmt.executeQuery(sql);
执行指定的sql语句,该语句可以是insert,update,delete
ResultSet rs=stmt.executeUpdate(sql);
关闭释放资源
stmt.close();

JDBC访问数据库的工作过程:
- 加载驱动,建立连接
- 创建语句对象
- 执行SQL语句
- 处理结果集
- 关闭连接
Driver接口及驱动类加载
要是有JDBC接口,需要先将对应数据库的实现部分(驱动)加载进来.
驱动类加载方式:(Oracle)
class.forName(“oracle.jdbc.driver.OracleDriver”);
意思是:装载驱动类,驱动类通过static块实现在DriverManager中的”自动注册”
Connection接口:
Connection接口
Connection接口负责应用程序对数据库的连接,在加载驱动之后,使用url,username,password三个参数,创建到具体数据库的连接.
Class.forName(“Oracle.jdbc.OracleDriver”);
//根据url连接参数,找到与之匹配的Driver对象,调用其方法获取连接
Connection conn=DiverManager.getConnection(“jdbc.oracle.thin:@192.168.1.17::1521:lz”.”openlab”,”open123”);
需要注意的是Connection只是接口,真正的实现是由数据库厂商提供的驱动包完成的.
Statement接口
Statement接口用来除了发送到数据库的SQL语句对象,通过Connection对象创建,主要有三个常用方法:
Statement stmt=conn.createStatement();
//1.execute方法,如果执行的sql是查询语句且有结果集则返回true,如果是非查询语句:
boolean flag =stmt.execute(sql);
//2.执行查询语句返回结果集
ResultSet rs =stmt.executeQuery(sql);
//3.执行DML语句返,返回影响的记录数
int flag=stmt.executeUpdate(sql);
ResultSet接口
执行查询SQL语句后返回的结果集,由ResultSet接口接收.
常用的处理方式:遍历/判断是否有结果(登录).
String sql=”select*from emp”;
ResultSet rs =stmt.executeQuery(sql);
while(re.next()){
System.out.println(rs.getInt(“empno”)+”,”+rs.getString(“ename”))
}
查询的结果存放在ResultSet对象的一系列中,指针的最初位置在行首,使用next()方法来在行间移动,getXXX方法来取得字段的内容
“selet ID,ACCOUNT_ID,HOST,USER_NAME,LOGIN_PASSWD”;
while(rs.next()){
System.out.println(rs.getInt(“ID”)+”,”+rs.geetInt(“ACCOUNT_ID”));
}
遍历结果集
Oracle是著名的Oracle公司的数据库产品.
Oracle是世界上第一个商品化的关系型数据库管理系统
Oracle采用标准的SQL(Structured Query Language结构化查询语言)支持多种数据类型,提供面向对象的数据支持,具有第四代语言开发工具支持Unix ,Windows,os/2等多中平台Linux.
目前最新的数据库版本是Oracle 18c.
SQL Server数据库概述:
Miscrosoft SQL Server是微软的产品,运行在WindowsNT服务器上
Misrosoft SQL Server的最初版本使用于中小企业,但是应用范围不断扩展,已经触及到大型跨国企业的数据库管理.
MySQL数据库
MySQL是开方源码的小型关系型数据库管理系统,广泛应用在小型网站中,总体拥有成本低,规模较Oracle和DB2要小,2008年1月16日被sum公司收购.2009年4月sum又被Oracle收购,所以sum属于Oracle公司
十里洋城成就一生功业潮起潮落里里外外都体面你陪了我多少年穿林打叶过程轰轰烈烈花开花落一路上起起跌跌春夏秋冬泯和灭幕还未谢好不容易又一年渴望的你竟还没有出现假如成功就在目前 为何还有不敢实践的诺言一辈子忠肝义胆薄云天撑起那风起云涌的局面过尽千帆沧海桑田你是唯一可叫我永远怀念锦上添花不如一蓑烟雨满堂盛宴还不如一碗细面井水一瓢也香甜有谁一任平生可以不拖不欠慢慢长夜想起那谁的人面想到疲倦的人间不再少年好不容易又一年渴望的你竟还没有出现假如成功就在目前为何还有不敢时间的诺言一辈子忠肝义胆薄云天撑起那风起云涌的就没场景了似水流年你是我心坎里唯一的思念
东临碣石,以观沧海。水何澹澹,山岛竦峙。树木丛生,百草丰茂。秋风萧瑟,洪波涌起。 日月之行,若出其中;星汉灿烂,若出其里。 幸甚至哉,歌以咏志。
JavaScript
JavaScript---js
它是嵌入HTML中在浏览器中的脚本语言,具有与java和C语言类似的语法。一种网页编程技术,用来向HTML添加交互行为,直接嵌入HTML页面,由浏览器 解释执行代码,不进行预编译ECMA(欧洲计算机联盟协会)由ECMA组织维护JavaScript标准,由浏览器内置的JavaScript引擎执行代码,JavaScript是一种解释执行语言,事先不编译,逐行执行,是基于对象的 语言:
内置大量的对象
Js的使用
Js有一个事件机制,鼠标光标点击按钮
两种引用方式:
1.内嵌式:
在HTML文档中通过可以引入.

2.外联式:
引用jsp文件

事件:
用户在作出操作的时候执行Js代码,也就是JS被调用的时机.
如:单击.双击,鼠标悬停
| 类别 |
事件 |
事件说明 |
| 表单事件 |
onblur |
当前元素失去焦点时发生此事件 |
| onchange |
当前元素失去焦点并且元素内容发生改变时触发此事件 |
|
| onfocus |
当某个元素获得焦点时触发此事件 |
|
| onreset |
当表单被重置时触发此事件 |
|
| onsubmit |
当表单被提交时触发此事件 |
|
| 页面事件 |
onload |
当页面加载完时触发此事件 |
常用对象
1.Window对象
window对象表示整个浏览器窗口,处于对象层次顶端,可用于获取浏览器窗口的大小,位置,或设置定时器等.在使用使,JavaScript允许省略window对象的名称.
| 属性/方法 |
说明 |
| document.history.locatio.navigator.screen |
返回相应对象的引用,例如document属性返回document对象的引用 |
| parent,self,top |
分别返回父窗口,当前窗口和最顶层窗口的对象引用 |
| innerWidth ,innerHeight |
分别返回窗口文档显示区域的宽度和高度 |
| outerWidth ,outerHeight |
分别返回窗口的外部宽度和高度 |
| open( ) ,close( ) |
打开或关闭浏览器窗口 |
| alert( ),confirm( ),prompt( ) |
分别表示弹出警告框,确认框,用户输入框 |
| setTimeout(),clearTimeout( ) |
设置或清除普通定时器. |
2.Date对象
Date对象是一个有关日期的对象,它具有动态属性,必须使用new关键字创建一个实例.语法如下:
var Mydate=new Date( );

3.String对象
string对象是JavaScript提供的字符串处理对象,创建对象实例后才能使用,提供对字符串处理的属性和方法

方法
方法指的是 面向对象的语言
函数
函数指的是 面向过程的语言
Js之前是面向过程的语言,演变为现在的面向对象.
js
1.访问修饰符,js中的函数(方法)都是公有的,所以不需要写访问修饰符
2.js函数不需要声明返回值类型,默认有返回值(方法自带返回值)
3.js中函数都是公有的不需要修饰符
4.js中的函数不需要声明返回值类型
5.js不分单引号和双引号
6.引入外部的js是文件调用式.在单独的js文件内写js
7.需要引入到网页上才能使用.标签必须是双标签哪怕没有内容
8.该标签不能引入js又写js(其实可以写特殊的js)
9.使用
不能既应用有写js代码
js的数据类型
1.定义 变量,部分数据类型直接定义成var
2.js的数据类型不分int double 等
3.js所有的小数,整数都定义成number(64位)
举个例子

类型
String类型
1.直接量就是首位加上单引号或者双引号
2.js没有字符类型,就是一个长度的String
3.特殊字符需要转译
Boolean类型
参与运算的时候直接转换
true--à1;
false-à0;
js引擎对boolean的解释规则;
1.真: 非空字符串,非0的数字,非空对象
2.假: 数字0.空字符集,null,undefined,NaN(nonumber)
变量的数据是有类型的,变量是没有类型的,统一用 var关键字声明.
数据类型的隐式转换
JavaScript是属于松散类型的程序语言
--变量在声明时不需要指定数据类型
--变量所引用的数据有类名.
**不同类型数据在计算过程中会自动进行转换
数字+字符串:数字转换为字符串
数字+布尔值:true转换为1.false转换为0.
字符串+布尔值:布尔值转换为字符串true或false
布尔值+布尔值:布尔值转换为数值1或0.
js并不严谨,所以说是一种弱类型的语言
当一个数字里面存着字符串与另外一个任何一个东西做加法的时候,”+”就变成了字符串连接,如:s1+”100”就是串,当除”+”以外的其他符号的时候”s1=100”就成了纯数字.
例如:
var s1=”100”;
var b= true;
cosole.lot(s1-b);//99
console.log(s1+b);//100true
数据类型的转换
--typeof
--查询当前类型,返回String/number/boolean/object/function/undefined
例如:typeof(“test”+3),返回”String ”
isNaN(is not a number)
--判断被检测表达式经过转换后是不是一个数
--如果被检测表达式不是数,则返回true,否则返回false
获取值
如何获取网页上某一个元素的值或者某一个元素内部写入的数据呢?
”text”value=”button”>
要分元素来看元素中有value属性,
对于有value属性的元素要获取文本框对象的值value属性就拿到了该元素的值
对于没有value属性的元素,使用Inner.HTML取值,如元素 中没有value属性,就用span.innerHTML来取值或赋值.
而标签中有value属性则通过input.value取值或赋值.
获取元素对象
如何获取页面上的每一个标签且把所获得的标签当做对象使用?
如何获取网页上一个元素的对象呢?
span=document.getElementById(“s_id”);/这是无value属性获取对象的方法.
var input=document.getElementById(“t-id”)这是有value属性获取对象的方法.
如:
123
span.innerHTML=123//span内部的123
var str=span.innerHTML;

数学运算符
1.+-*/跟java一样
2.”/”结果可以是小数,java中5/2结果是2,Js中5/2结果是2.5
3.num++ ++num
关系运算符
“==”< > <= >= != !==等等
“===”意味着数据类型和值都一样

调错
1.看错误信息---挑认识的看
2.打桩:
--观察程序的执行流程
--看每一步变量的值师傅正确
3.排除法
4,看debug 在网页中按F12
debug的用法点击sourcesà点击demoà点击行号à点击按钮就会一行一行往下走.
js可以使用任意数据当做条件
if(a!=null&&a!=0&&a!=””&&a!=undefined&&a!=NaN{java中是这么写的
if(a){ js里写起来简单
}
js中的条件表达式:
Java中的条件表达式必须返回布尔值
js中的表达式可以是任意表达式,即可返回任何类型值


js中常用API
什么是js中常用API
对象就是JavaScript中常用的重要API
JavaScript包好多种对象:
--内置对象:API String类,日期类
--外部对象:
1.Windows对象:浏览器里面的对象
2.dom对象: 等标签,通过document.getElementById获取 --自定义对象: 后期会对标签进行增删改查. 我们学习dom对象的目的:最终就是为了能实现动态网页的添加或者删除标签 属性和方法 访问对象属性对象.属性 访问对象方法:对象.方法名(); --String对象 --Number对象 --Boolean对象 --Array对象 --Math对象 --Date对象 --Function对象等. 1.创建String对象 var str=”你好js”; var str=new String(‘hello world’); str.toLowerCase(); str.toUpperCase(); 3.获取指定的字符串 str.charAt(index);à一个长度的字符串 str.charCode(index) à返回指定位置字符的unicode编码,相当于java中的charAT 4.查询指定字符串 var str =”abcdef” str.indexOf(“c”) str.lastIndexOf(“c”) 5.获取子字符串 str.substring(start[end]); var str=”abcafcdef”; str.substring(2,4); 6.替换子字符串 str.replace(finder,tester) finder:要被替换的字符串 tester:替换成的字符串 var str =”abcdfcdef”; var str2=str.replace(“af”,”zzz”); console.log(str2); 7.字符串分隔à返回值是一个数组 var str=”一,二,三,四,五,六,日”; var strArray=str.split(“,”); num.toFixed(num) 把num转换成字符串,并且保留小数点后一定的位数 var num=23.56789 alert(num.toFixed(2));//23.57àString 根据你要取舍的小数位数四舍五入或者补零 ##boolean对象 ##Array数组对象 var a1=new Array(); var a2=new Array(7); var a3=new Array(100,”a”,true); var a4=[100,200,300]; --获取数组元素的个数:length属性 数组长度是不变的 --访问数组元素 a1[0]=1;//a1的长度由0变为1 console.log(a3[1]); 注意:js中数组对象都是object类型 (1).创建数组时就已知数据 var a1=[“张珊”,19,’男’] (2).如果创建数组的时候不知道存什么,就创建一个空数组 var a2=new Array() a2[0]”=”list”; a2.push(“20”);//追加数据 (3).数组倒转 var arr=[5,7,1,6,3,12]; arr.reverse();//数组反转 (4).数组排序 var arr=[5,8,1,6,3,12,32,15]; arr.sort();//叫字符串排序 表单验证: 在实际开发中,经常需要对字符数据进行一些复杂的匹配,查找替换等操作,通过”正则表达式”,可以方便的实现字符串的复杂操作. 正则表达式是一串特定字符,组成一个”规定字符串”这个规则字符串是描述文本规则的工具,正则表达式就是记录文本规则的代码. 例如: 正则表达式:[a-z] 表示a~z的任意一个字符 ; 正则表达式:”[a-z]”表示由一个或多个a-z字符组成的 字符串 正则表达式[abc]:表示a,b,c中的任意一个字符 正则表达式[^abc]:表示除了a,b,c的任意字符 正则表达式[a-zA-Z0-9]:表示a-z,A-Z,0-9,中的任意一个字符 [a-z&&[^bc]]:a~z中除了b和c以外的任意一个字符 --^代表字符串开始 --$代表字符串结束 如:匹配用户名规则--从头到尾连续8~10个单词字符 \w{8,10} ^\w{8,10}$第二种写法 “abcd1234_abcd”第一种 写法可以通过,第二种不行 js中没有class function本身就是js内置对象 直接把function的对象名,当做参数传递 给另外一个方法就可以了. js中有括号的方法意味着执行. function aa(){ alert(11111111); } var bb=aa;//如果aa后面加括号以为着方法执行了 Math.sin(x),Math,cos(x),Math.tan(x)等 计算函数: Math.sqrt(x),Math,log(x),Math.exp(x);等 数值比较函数: Math.abs(x);Math.max(x,y….);Math.random() Math.round(x)等 --arguments参数列表 --js中没有重载 --调用函数时,只要函数名一样,无论传入多少个参数,调用的都是同一个函数. --所有的参数传递给argument的数组对象 function aa(){ alert(argument。length); alert(arguments【0】); } 传入数字,计算总和,模拟方法重载的效果 function sum(a,b){ var s=0; if(arguments.length>0){ for (var i=0;i s+=arguments[i]; } } retrun s; } console.log(sum(1,2,3)); console.log(sum(4,5,6,7,8,9)); 由以上案例得出结论: --js中没有重载 --在js中调用函数的过程,只检测函数名,不检测参数列表 --如果出现多个同名函数存在,最后一个有效 1.使用new创建function对象 var add=new Function(“x”,”y”,”return(x+y);”); var result=add(2,3); alert(result); 2.匿名函数 var add=function(x,y);{ retrun x+y; } add(2,3); --匿名函数就是不给方法起名字 --这个方法在别的地方不再被调用了,就可以使用匿名函数 var arr={5,12,8,1,3,32,15}; arr.sort(function(a,b){ retrun b-a; }); 一个function对象在创建的时候,可以给参数也可以不给参数,但是在调用的时候无论传入多个参数,调用的都是同一个函数,当方法X()中传入了x,y两个参数,x,y会自动存入到arguments数组对象中, 怎么使用arguments对象? arguments数组对象是内置的,只要创建方法,无论是否有参数,就有arguments数组对象存在 比如说: function method(){ alert(22); } method(10,20);依然执行不报错 parseInt/parseFloat isNaN eval --全局函数可以用于所有的javascript对象 --不需要对象调用 1.eval eval(str) var str=”alert(1111)”; --eval函数,是一个全局函数,用于计算表示的字符串 --执行字符串中的js代码 //执行表达式 var str=”2+3”; alert(eval(str)); //执行js代码 var str=”function aa(){ alert(111); } aa();”; eval(str); --eval通常执行服务器动态传递过来的js代码块 1.外部对象就是浏览器提供的API 2.这些对象是w3c规定,由浏览器开发者开发的 3.这些对象分为两部分,BOM和DOM 4.我们可以使用js访问操作这些对象 BOM--browser object model --可移动的窗口,更改状态栏文本 --执行不与页面内容直接联系的操作(不操作标签) DOM--Document Object Model --定义了访问和操作HTML文档的标准方法(标签) --应用程序通过对DOM树的操作,来实现对HTML文档数据的操作(增删改查) 1.Windows浏览器窗口 --所有的js的全局对象,全局函数,全局变量都会自动成为Windows对象的成员 2.window中的常用数据 --var document =window.document BOM 的document对象是通过window.document属性得到的 --window.history --window.location --window.screen --window.navigator 1.弹出框 --alert(); --confirm(“睡醒了吗?”) --prompt(“需不需要去洗把脸”) 输入框 2.定时器 用于网页动态时钟,倒计时,跑马灯,轮播图,无缝滚动,周期定时器 --周期定时器 以一定的时间间隔,执行代码,循环往复 --setInterval(exp,time) --exp:需要反复执行的代码,一般为匿名反方法 time:时间周期,毫秒 --返回已启动的定时器对象(ID) --clearInterval(ID):停止计时器
eval函数时一个全局函数,用于计算表达式的字符串,执行字符串中的js代码,浏览器中有js 代码,js代码中有个eval,eval()方法要执行一个字符串,字符串中包含着其他的js代码,js代码哪来的? 是从服务器动态传过来的,要使str在浏览器中执行就是用eval. 注意事项:使用eval会因浏览器版本不同而产生一些错误,为了避免这种错误,使用语法为eval(“+(“+str+”)”); navigator(浏览器信息对象) 包括:浏览器的版本,浏览器公司名称 浏览器的内核是什么,使用什么样的操作系统等. 电子时钟案例演示 包含当前页面相关的url信息,作用是获取和改变当前浏览器的网址, -href属性:当前窗口正在浏览的网页网址. --reload():方法,重写载入当前网址,并刷新. 代码实现如下: function(){ var b=confirm(“你确定要离开当前网页吗?); if(b){ //设置当前页面的url location.href=”http://www.baidu.com”; } } location.reload(); 包含有关客户端显示屏幕的信息 --常用于获取屏幕分辨率色彩,宽高,可用宽高. --height width属性. --availWidth availHeight ;(合适的宽高) screen.height screen.width screen.availWidth screen.availHeight 包含用户在浏览器窗口访问过的url --length属性:history.length --back( )方法history.back( ) --forward( )history.forward() --go( 通过下标去哪个页面都行).等等方法 包含浏览器相关信息 --获取和操作浏览器和操作系统的信息 --userAgent属性,检查当前浏览器的 版本 navigator.userAgent方法就可以调出来 通常使用BOM对象操作可移动的窗口,alert就属于BOM对象的方法.还可以通过状态栏更改文本,执行不与页面内容直接联系的操作.(意味着不操作标签). 在BOM中最大的对象是window,级别最高,表示浏览器窗口(指的是浏览器向你展示的全部).window是所有js的全局对象,全局函数,全局变量的总领导. window中存在的属性可以直接获取对象.(location对象,screen对象,history对象,document对象,navigator对象). 才是BOM对象的属性. BOM中的document是window的一个属性,结果是获得document对象,转换成代码即为: var document=window.document; BOM 中的document对象是通过window.document数得到的,其中window可省略. 页面的元素都被加载完,window.onload时间才会被激发 中的元素都被加载完. window.onload是window对象的一个事件 --在页面加载完成之后调用某个方法函数. --window.οnlοad=匿名函数,动态绑定;通过此事件就可以将
”p1”οnclick=”fn();”>
} 1.浏览器获取html文件有一个解析过程,即解析成DOM对象 2.为了以后可以对网页内容进行增删改查操作,只需要操作DOM对象即可. 3.因为这套对象具有树状结构,所以人们形象的称为DOM树. 4.树结构中的每级对象称之为节点(是根节点) 学习DOM就是学习它的结构以及节点上的API 1.查找节点 2.读取节点信息 3.修改节点 4.可以增加新节点 5.删除节点 --obj.nodeName --obj.nodeType 数字: “1”代表元素节点 “2”代表属性节点 “3”代表文本节点 “8”代表注释节点 “9”代表文档节点 以上内容什么时候用呢? nodeName和nodeType属性在写js框架的时候会频繁使用. 1.内容:双标签之间的文本叫内容,所有的双标签都拥有自己的内容 2.读写内容的方式: --innerHTML是HTML形式的内容,可以改变HTML的结构 --innerText读写的是纯文本格式与结构无关. --读写节点的值value form表单的节点或元素都有value --表单空间中的数据叫值value --input,select,textarea有value 例如: ”value=”按钮”id=”btn1”> var btn1=document.getElementById(“btn1”);//按钮 1.通过方法来读取节点的属性. --obj.getAttribute(属性名)class id src --obj,setAattribute(属性名,属性值) 2.通过方法来移出属性 --obj.removeAttribute(属性名) 3.直接通过属性名,读写属性 document.getElementByTagName(); //根据标签名获得一个对象的数组 document.getElementByTagName(img);整个这篇网页的所有img对象都会获得,并且存 到一个数组中. nodeName: 元素节点和属性节点:标签或属性名称 文本节点:永远都是#text innerHTML:设置或者获取位于对象起始和结束标签内的HTML obj.getAttribute( )方法:根据属性名获取属性的值 obj.setAttribute(属性名,属性值) obj.removeAttribute(属性名) 查找并修改节点: ”h1”>h1 text ”text1”type=”text”> var a=document.getELement(“text”); tex1.value=”text data”; tex1.style.color=”gray”; var b=document.getElementById --如果需要操作HTML元素,比如首先找到该元素 差尊节点有如下几种方式: --通过id查询 --通过层次查询 --通过标签名称查询 --通过name属性查询 document.getElement(); 如果id值错误,则返回null parentNode --遵循文档的上下层次结构查找单个父节点. childNodes ”gz”>广州
var ul=document.getElementByTagName(“ul”)[0]; --getElementByTagName() --根据指定的标签名称返回所有的元素 --忽略文档的结构 --查找整个HTML文档中的所有元素 --如果标签名称错误,则返回长度为0的节点列表 返回一个节点列表(数组) --使用节点列表的length属性获取个数 [index]:定位具体的元素. 鼠标悬停事件:οnmοuseοver=”停止轮播”; 鼠标离开事件:οnmοuseοut=”开始轮播”; 事件: 指DHTML对象在状态改变,操作鼠标或者键盘时触发的动作. --鼠标事件 --键盘事件 --状态改变事件 --事件触发后会产生一个event对象 --任何事件触发后,将会产生一个event对象 --event对象记录事件发生时的鼠标位置,键盘按键状态和触发对象信息等, --获得event对象 --使用event对象获得相关信息,如单击位置,触发对象等. --常用属性:clientX/clientY等 获得event对象 --IE等浏览器:直接使用event关键字 获得事件源 --IE等浏览器:event.srcElement //IE浏览器 function func(){ alert(event.clientX+”:”+event.clientY); alert(event.srcElement.nodeName);//Div } js的兼容都是源于event对象,按下的每一个键都会把信息保存在event对象中.event对象会调出一个属性,告诉你按的是哪个按键. this的用法: 事件处理机制: 事件冒泡:--传递 如何取消冒泡传递呢? 用event.stopPropagation方法 以前只支持Firefox,Chrome,现在新版本IE也支持了,IE8.0以及8.0以下版本不支持 --MOZ是火狐内核 --ms是IE内核 --webkit是谷歌和苹果内核 --任何事件触发之后,都会生成一个event对象,event对象是自己生成的. event对象在生成的时候,由于浏览器版本不同,内核不同,导致获取方式不同 --event对象记录事件在触发的那一刻,鼠标位置.键盘的按键状态,及触发对象(事件源)等信息 1.html代码中直接使用event对象 ”button”value=”HTML-IE-CH-FF”οnclick=”alert(event.clientX+”:”+event)”> //虽然同样,但是这种代码没有意义 在开发中,要求HTML代码和js代码完全分离,解耦合. event对象中保存着很多属性和方法 --event.clientX/event.clientY --event.cancelBubble=true --event.stopPropagation(); event保存着事件源,这里还有兼容性问题
$(“p”)à[p,p,p…fn].css( ) $(“p”)[i]àpàinnerHTML 什么是jQuery --jQuery是一个优秀的JavaScript框架,一个轻量级的js库. --它封装了js,css,DOM提供了一致的简洁的API --兼容css3,及各种浏览器 --使用户更方便的处理HTML,Events,实现动画效果,冰倩方便的为网站提供Ajax交互. 使用户的HTML页面保持代码和HTML内容分离 注:jQuery2.x开始不再支持Tnternet Explorer6,7,8 $(“p”)(双引号里的p代表选择器) jQuery对象与DOM对象的关系 jQuery对象本质上是一个DOM对象数组,它在该数组上扩展了一些操作数组中元素的方法 --可直接操作这个数组: --obj.length:获取数组长度 --obj.get(index):获取数组中的某一个DOM对象 --obj.[index]:等价于obj.get(index) jQuery延用了css选择器的写法 $(“p”)需要加双引号 1.标签选择器$(“div”) 2.类选择器$(“.class”) 3.id选择器$(“#id,.class,div”) 1.子选择器$(“selector1>selector2”) 2.后代选择器$(“selector1 selector2”) 3.弟弟选择器$(“selector1+selector2”) 4.弟弟们选择器$(“selector1~selector2”) 1.基本过滤器 --$(“li:first”)第一个元素 --$(“li:last”)最后一个元素 --$(“li:eq(n)”)第n个元素 $(“li:not(selector)”)把selector排除在外 2.不常用: --$(“li:even”)挑选下标偶数 --$(“li:odd”)挑选下标奇数 --(“li:gt(n)”)下标大于n的元素 --(“li:lt(n)”)下标小于n的元素 3.内容过滤器 --contains(str)匹配所有包含str文本的元素 --empty匹配所有不包含子元素和文本的空元素 4.可见性过滤器 --hidden匹配display:none的元素,type为hidden的input元素 --visible匹配所有课件的元素 5.属性过滤器 $(“li[attribute]”)匹配具有attribute属性的元素 $(“input[value=’你好’]”)匹配属性等于str的元素 $(“input[value!=’你好’]”)匹属性不等于str的元素 6.状态过滤器 --enable匹配可用的元素 --disabled匹配不可以的元素$(“input.disabled”); 常用的两种 1.checked匹配选中的状态 2.selected匹配选中状态的option 1.text匹配文本框 2.password匹配密码框 3.button匹配按钮 4.radio匹配单选 5.checkbox匹配多选 6.submit匹配提交按钮 7.reset匹配重置按钮 8.file匹配文件框 9.hidden匹配隐藏框$(“input:hidden”) ----标准写法 $(“input:text”) ----省略写法 $(“text”) 注意: hidden必须按照标准写法$(“input:hidden”) 1.读写节点的内容innerHTML innerText的区别. --用jQuery方法读写节点的内容 var str=obj.html( ) //jQuery方法写节点的内容 obj.html(“ 123 --var str=obj.text( ); obj.text(“123”); --读写单标签中的内容 var str=obj.val( )/obj.val(“123”) 4.读取节点属性 var str=obj.attr(“属性名”)//读取节点属性 obj.attr(“属性名”.”属性值”);//写节点 2.增删节点 var p=document.creatElement(“p”); p.innerHTML=”str”; 节点 var obj=$(“”大家好,学习好痛苦啊! parent.append(obj)作为最后一个子节点追加 parent.prepend(obj)作为第一个子节点插入 brother.afert(obj)作为下一个兄弟节点添加 brother.before(obj)作为上一个兄弟节点添加 obj.remove();obj就被删除了 obj.remove(selector);满足条件的被删除 obj.empty();清空节点 操作dom就是操作dom --obj.addclasss(“样式类名”) --obj.removeClass(“样式类名”) --obj.hasClass(“样式类名”):判断是否有 某个样式 --obj.toggleClass(“样式类名”) --obj.css(“displace”,”none”);设置样式 var str =obj .css(“display”);读取样式 --选择器$(“p:first”) --类型装换$(dom) --创建新节点$(“”) --obj.html(“…”).attr(“src”,”01.png”); --obj.addClass(“…”).removeClass( ); --obj.parent( );/obj.parent( ).addClass://父子关系 --obj .next( );//兄弟节点 --obj.html( ); --obj.text( ); --obj.val( ); obj.css(“color”); 就是在debug中的控制台中打印,看对象的结构.如果是jQuery对象,就是连写的. --obj.parent( ):父节点 --obj.children( )/obj.children(selector)/obj.children([selector]);子节点/除选中以外的子节点/除自己以外的 其它子节点 --obj.next( );下一个兄弟节点 --obj.prev( );上一个兄弟节点. --obj.siblings([selector]);除了自己以外所有的兄弟节点 --obj.find([selector]);找到obj.内部符合条件的节点. --$obj.bind(事件类型,事件处理方法/函数) --$obj.bind(‘click’,fn); --简写形式:$obj.click(fn);//绑定事件和方法 注意:$obj.click()则代表触发了click事件. obj.click(function( ){ });绑定匿名方法 总结: 对数据的存储需求一直存在,保存数据的方式,经历了手工管理,文件管理等阶段.直至数据库管理阶段. 文件存储方式保存数据的弊端: 1.缺乏对数据的整体管理,数据不便修改: 2.不利数据分析和共享. 3.数据量急剧增长,大量数据不可能长期保存在文件中 因此数据库应用而生.是人们存放数据,访问数据,操作数据的存储仓库. 数据库 数据库(DataBase简称DB)是按照数据结构来组织,存储和数据库管理的仓库. 数据库管理系统 数据库管理系统(DataBaseManagementSystem):管理数据库的软件. 数据库建立了数据之间的联系,使用结构化的方式和处理数据,能够统一,集中及独立的管理数据,使数据的存取独立于使用数据的程序,实现了数据共享. 数据库称为数据的知识库,并对这些数据的存储,访问,安全,数据一致性,并发操作及备份恢复负责. 数据在数据库中的存储的基本单位是表(table). 学号 姓名 年龄 最高学历 毕业院校 班级 101 田广才 18 博士后 烟台大学 1 102 刘德华 45 本科 香港大学 2 103 赵云镇 34 大专 野鸡大学 3 104 张学友 52 高中 母鸡大学 4 105 孙中山 45 大专 中山大学 5 106 单田芳 63 本科 口技大学 6 107 张国荣 23 小学 国荣大学 7 关系是一个数学概念,描述两个元素的关联或对应关系,所以关系型数据库,即是使用关系模型吧数据组织到数据表中,现实世界可以用数据来描述. --Oracle(oracle甲骨文公司) --DB2(IBM) --SQL Server(MS) --MySQL(Oracle) 在关系型数据库中,数据库存放于二维数据表中(Table)中. 一个关系型数据库有多个数据表组成,数据表是关系型数据库的基本存储结构,由行和列组成,行(row)也就是横排数据,也经常被称作记录(record),列(column)也就是纵列数据,也被称作为字段.(Field),表和表之间是存在关联关系的. 主流关系型数据库: Oracle是当今著名的Oracle(甲骨文)公司的数据库产品,它是世界上第一个商品化的关系型数据库管理系统,也是第一个推出和数据库结合的第四代语言开发工具的数据库产品. Oracle采用标准的SQL结果化查询语言,支持多种数据类型,提供面向对象的数据支持,具有第四代语言开发工具,支持Unix,Windows,os/2等多种平台,Oracle公司的软件产品数据库包括Oracle服务产品,Oracle开发工具和Oracle应用软件,其中最著名的就是Oracle数据库,目前最新的版本是Oracle18c. DB2是IBM的关系型数据库管理系统,DB2具有很多不同的版本,可以运行在从掌上产品到大型机不同的终端机器上,DB2 university Database Personal Edition和DB2 University Database Workgroup Edition分别是为os/2和windows系统的单用户和多用户提供的数据库管理系统. DB2在高端数据库的主要竞争对手是Oracle. Sybase是美国Sybase公司研发的一种关系型数据库,是较早采用c/s技术的数据库厂商,是一种典型的unix或Windows NT平台上客户机/服务器环境下的大小数据库系统.sybase通常与Sybase SQL anywhere用于客户机/服务器环境,前者为服务器数据库,后者为客户机数据库,采用该公司研发的PowerBuilder为开发工具,在国内大中型系统中有广泛的应用. Sybase主要有三个版本,一是Unix操作系统下运行的版本,而是Novell Netware环境下运行的版本,三是Windows NT环境下运行的版本.对Unix操作系统目前广泛应用的为Sybase 10及Sybase 11 for Sco Unix. SQL server数据库概述: Microsoft SQL server是运行在Windows NT服务器上,支持c/s结构的数据库管理系统,采用标准SQL语言,微软公司对它进行了部分扩充而成为事务SQL(transaction-SQL) SQL server最早是微软为了要和IBM竞争时,与Sybase合作所产生的,其最早的发展者是Sybase,和Sybase数据库完全兼容,在与Sybase终止合作关系后,微软自主开发出SQL Server 6.0版本,往后的SQL Server 即均有微软自主开发,最新版本是SQL Server2017. Microsoft SQL Server是运行在Windows NT服务器上,支持c\s结果的数据库管理系统,它采用标准SQL语言,微软公司对它进行了部分扩充而成为事务SQL(Transact-SQL). Microsoft SQL Server几个初始版本使用与中小企业的数据库管理,但是后来它的应用范围有所扩展,已经触及大型,跨国企业的数据库管理. MySQL是一个开放源代码的小型数据库管理系统.开发者为瑞典MySQL AB公司.目前MySQL被广泛地应用在Internet上的中小型网站中. 与其它的大型数据库例如: Oracle,IBM DB2等相比,MySQL自有它的不足之处,如规模小,功能有限等,但对于一般个人使用和中小企业来说,MySQL提供的功能已经绰绰有余了,而且由于MySQL是开放源代码的软件,因此可以大大降低总体拥有成本,许多中小型网站为了降低网站总体拥有成本,而选择了MySQL作为网站数据库. 2008年1月16日,sun收购了MySQL,2009年4月,sun被Oracle公司收购,目前最新的版本是8.0。 SQL(Structrued Query Language)是结构化查询语言的缩写.SQL是在关系型数据库操作,检索及维护所使用的标准语言,可以用来查询数据,操纵数据,定义数据,控制数据,所有的数据库都使用相同或者相似的一计. --数据定义语言:(DDL):Data Defintion Language --数据操纵语言:(DML):Data Manipulation Language --事务控制语言:(TCL):Transaction Control Language --数据查询语言:(DQL):Data Query Language --数据控制语言:(DCL):Data Control Language 执行SQL语句时,用户只需要知道其逻辑含义,而不需要知道SQL语句的具体执行步骤. 用于建立,修改,删除数据库对象,包括创建语句(Create),修改语句(Alter)删除语句(Drop),比如使用create,table创建表,使用alter table修改表,使用drop table删除表等动作,这类语句不需要事务的参与,自动提交. 用于改变数据库,包括Insert ,Update, Delete三条语句,其中,Insert语句用于将数据插入到数据库中,Update语句用于更新数据库中已存在的数据,Delete 用于删除数据库中已存在的数据,DML语言和事务是相关的.执行完DML操作后必须经过事务控制语句提交后才真正的将改变应用到数据库中. 用来维护数据一致性的语句,包括提交(commit)回滚(rollback),保存点(savepoint). 三条语句:其中commit用来确认已经进行的数据库改变,pollback语句用来取消已经进行的数据库改变,当执行DML操作后(也就是上面说的增加,修改,删除等动作),可以用啦commit语句来确认这种改变,或者使用rollback取消这种改变,savepoint语句用来设置保存点,使当前的事务可以回退到指定的保存点,便于取消部分改变. 用来查询所需要的数据,使用最广泛,语法灵活复杂, 用于执行权限的授予和收回操作,创建用户等,包括授予(grant)语句,收回(revoke)语句,crate user语句,其中grant用于给用户或角色授予权限,revoke用于收回用户或角色已有的权限,DCL语句也不需要事务的参与,是自动提交的. 1.登录 运行cmd进入命令行 sqlplus 用户名/密码[as sysdba] 2.查看当前连接的数据库的用户 show user; 3.用户的切换: --切换为超级管理员 conn用户名/密码as sysdba; --切换为普通用户 conn用户名/密码 4.查看用户下的表: select*from tab; 5.查看表中的内容: select*from表名; --一管理员身份查询表中的内容 select*from Scott.emp; 6.查看表的结构 desc emp; desc 表名; Number(9)最大长度为9的数值类型 varchar2(10)最大长度为10的字符串, varchar2用于储存可变长度的字符串 varchar2一般情况下把所有的字符都看成是占两字节处理, varchar只对汉子和全角等字符当做;两字节处理,数字,英文 等字符都是一个字节. varchar 2吧空串””等同于null处理,而varchar任然按照空串处理 建议在Oracle中使用varchar2 例如:Number(7,2)--数值类型整数位占5位,小数占2位,一共占7位. Date:时间类型. 解锁账户 雇员表 No 字段 类型 描述 1 EMPNO NUMBER(4) 表示雇员编号,唯一的 2 ENAME VARCHAR2(10) 表示雇员姓名 3 JOB VARCHAR2(9) 表示工作单位 4 MGR NUMBER(4) 雇员的领导编号 5 HIREDATE DATE 表示雇佣日期 6 SAL NUMBER(7,2) 表示月薪,工资 7 COMM NUMBER(7,2) 表示奖金,佣金 8 DEPTNO NUMBER(2) 部门标号 简称SQL结构化查询语言,是一种数据库查询和程序设计语言,用于存取数据和查询,更新和管理关系型数据库:同时也是数据库脚本文件的扩展名,结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作,它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统,可以使用相同的结构化查询语言作为数据输入与管理的接口,结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能. select empno 部门编号,ename 部门名称 from emp; 创建 create table insert into student(id,name)values(1,’名字’); insert all into hero values(1,'诸葛亮','法师',18888) into hero values(2,'孙悟空','打野',18888) into hero values(3,'小乔','法师',18888) into hero values(4,'黄忠','法师',18888) into hero values(5,'刘备','法师',18888) select 1 from dual; 插入 单行插入 多行插入 insert all into hero values(1,'诸葛亮','法师',18888) into hero values(2,'孙悟空','打野',18888) into hero values(3,'小乔','法师',18888) into hero values(4,'黄忠','法师',18888) into hero values(5,'刘备','法师',18888) select 1 from dual; insert into 表名 values( 内容 ) 查找 修改 update hero set money =2888 where money=1888; 删除 delete from hero where money=28888; 全删 全部删除(包括表头) drop table tablename; 表名查询数据表的结构 创建一个hero1表 插入id int ,name varchar2(10), salary double,dept varchar2(10),joinDate date, 创建 create table hero1 (id int, name varchar2(10),salary double,dept varchar2(10),joinDate date); 插入 insert all into hero1 values(1,'诸葛亮',1000,'法师部门',’2017-12-12’) into hero1 values(2,'庞统',3000,'法师部门',’2017-12-12’) into hero1 values(3,'孙悟空',100,'刺客部门',’2017-12-12’) into hero1 values(4,'达摩',1000,'法师部门',’2017-12-12’) into hero1 values(5,'泷谷源治',1000,'法师部门',’2017-12-12’) select 1 from dual; 修改hero3里诸葛亮的工资为200000 1.重命名 rename 原来的名字 to 新表名 2.在现有表中增加列 alter table tablename ADD (column datatype [DEFAULT EXPR][,column datatype….]) 删除列: ALTER Table tablename DROP(列名/字段名) 删除字段需要从每行中删掉该字段占据的长度和数据并释放在数据库中占据的空间,如果表记录较大,删除字段可能需要比较长的时间. 创建一个employee表 create table employee(id number(4),name varchar2(20),gender char(5)default ‘M’,birth DATE,salary number(6,2),job varchar2(30),deptno number(2)); Oracle中的日期数据比较特殊,如果插入的列有日期字段,要考虑日期格式,Oracle默认的日期格式是”DD-MON-RR”,或者按照默认格式插入数据,或者自定义日期格式.用TO_DATE函数转换为日期类型的数据. update语句用来更新表中的记录,语法如下: update 表名 set 字段名=value where condition; 其中where子句是可选的,但是如果没有where字句可选的,但是如果没有where字句,则全表的数据会被更新,务必小心. 用来删除表中的记录,语法如下: delete[from]表名[where condition]; 和update语句蕾西,where字句是可选的,但是如果没有where字句,则全表的数据都会被删除 Delete from employee where job is null;(把职位是空职位的删除掉) char 和 varchar2 类型都是用来表示字符串数据类型,用来在表中存放字符串信息,比如姓名,职业,地址等. char存放定长长度字符,如果数据存不满指定长度,则补齐空格. varchar2存放变长度字符,实际数据有多长就占用多少. 如保存字符串”helloworld”,共10个英文字母: --char(100):10个字母,补齐90个空格.实际占用了100个字节. --varchar2(100):10个字母,实际占用10个字节. char类型浪费空间,换取查询时间的缩短.varchar2节省空间,查询时间变长,字符串按照自然顺序排序 字符串在数据库中存储的默认单位是字节,也可显示为指定字符.如: --char(10),等价于char(10BYTE) --如果指定单位为字符:char(10 cahr),20个字节 --varchar2(10),等价于varchar2(10 byte) --指定单位字符:varchar2(10 char),20个字节; 每个英文字符占用一个字节,每个中文字符按照编码不同,占用2-4个字节; --zhs16gbk:2个字节 --utf-8:2-4个字节 long类型可以认为是varchar2的加长版,用来存储变长字符串,最多达2GB的字符串数据,但是long类型有诸多限制,所以不建议使用: --每一个表只能有一个long类型列: --不能作为主键: --不能建立索引: --不能出现在查询条件中等. clob用来存储定长或变长,字符串,最多达4GB的字符,Oracle建议开发中. 使用clob替代long类型,比如如下方式定义数据表: 例子: create table student(id number(4),name char (20), detail clob); concat和”||” concat是字符串链接函数; 语法是: concat(char1,char2)用于返回两个字符串连接的结果,两个参数char1 ,char2 是要连接的两个字符串. concat只能有两个参数,所以如果连接3个字符串时,需要两个concat函数,比如链接emp表中的name列和salary列,中间用”:”隔开. select concat(concat(name,’:’),sal)from employee 在链接两个以上操作符时并不是很方便,concat的等价操作是连接操作符"||". 当多个字符串连接时,用||符号更直观,下述SQLQ语句实现相同的效果。 SELECT ename ||':'|| sal FROM employee; 在连接时如果任何一个参数是Null,相当于连接了一个空格。 LENGTH(char)用于返回参数字符串的长度,如果字符类型是VARCHAR2,返回的实际 长度,如果字符类型时CHAR,长度还包括后补的空格。例如: SELECT ename,LENGTH(name)FROM employee; 将列出字符串的长度: 这个三个函数全部是英文的大小写转换函数,用来转换字符的大小写: ——UPPER(char)用于将字符转换为大写形式 ——LOWER(char)用于将字符转换为小写形式 ——INITCAP(char)用于将字符串中每个单词的首字符大写,其他字符小写,单词之间用 空格和非字母字符分隔 如果这三个函数的输入参数是NULL值,仍然返回NULL值,例如: SELECT UPPER('hello world'),LOWER('HELLO WORLD'),INITCAP('hello world') FROM DUAL; 将列出的参数"hello world"的大写,小写和首字符大写的形式,一般用来查询数据表中不确定 大小写的情况,如下图所示: 这三个TRIM函数的作用是截取子字符串,语法形式及解释: ——TRIM(c2 FROM c1)表示从c1的前后截去c2 ——LTRIM(c1[,c2])表示从c1的左边(Left)截去c2 ——RTRIM(c1[,c2])表示从c1的右边(Right)截去c2 在后两个函数中,如果没有参数c2,就去除空格 例如: SELECT TRIM('e' FROM 'elite') AS t1, LTRIM('elite','e') AS t2, RTRIM('elite','e') AS t3 FROM DUAL; LPAD、RPAD: PAD意即补丁,LPAD和RPAD两个函数都叫做位补丁,LPAD表示 LEFT PAD,在左边打补丁 。RPAD表示RIGHT PAD,在右边打补丁,语法如下: ——LPAD(char1,n,char2)左补位函数 ——RPAD(char1,n,char2)右补位函数 参数的含义:在字符串参数char1的左端或右端用char2补足到n位,其中参数char2可 重复多次。例如在EMP表中使用左补位,将sal用$补齐6位 select lpad (‘name’,7,’$’)from employee; 表示在一个字符串中截取子串,语法是: substr(char,[m[,n]]); 用于返回char中从m位开始取n个字符的子串,字符串的首位计数从1开始, 参数含义如下: --如果m=0,则从首字符开始,如果m取负数,则从尾部开始 --如果没有设置n,或者n的长度超过了char 的长度,则取到字符串末尾为止. 用来返回在一个字符串中子串的位置,语法是: instr(char 1,char2[,n[,m]]) 参数的含义: --返回子串char2在源字符串char1中的位置 --从n的位置开始 搜索,没有指定n,从第一个字符串开始搜索 --m用于指定子串的第m次出现的次数,如果不指定取值1 --如果在char1中没有找到子串char2,返回0 查询所有表 number(p)表示整数 数据表中的数值类型用number表示,完整语法是: number(precision,scale) 精度 比例 可以用来表示整数和浮点数,如果没有设置参数s,则默认取值0,即number(p)用来表示整数,p表示竹子的总位数,取值为1-38.一般用来在表中存放如编码,年龄,次数等用整数记录的数据,例如建表时指定学生编码是4位数字: 如果指定了s但是没有指定p,则默认p为 38. 例如: 列名 number (* ,s) number(p ,s)经常用来做表中存放金额,成绩,等有小数位的数据,例如创建学生表,指定成绩整数位最多为3位,小数位最多2位: 例如: create table student(id number(4),name char(20),score number(5,2)); 内部实现是number,可以将其理解为number的别名,目的是多种数据库及编程语言兼容 --number(p,s):完全映射至number(p,s)类型 --decimal(p,s)或dec(p,s): 完全映射至number(p,s) --integer或int: 完全映射至number(38)类型 数值函数指参数是数值类型的函数,常用的有round,trunc,mod,ceil 和floor.其中round用来四舍五入,语法如下: round round(n[,m])用于将,参数n按照m的数字要求四舍五入.其中: --参数中的n可以是任何数字,指要被处理的数字 --m必须是整数 --m取正数则四舍五入到小数点狗第m为 --m取0值则四舍五入到整数位 --m取负数,则四舍五入到小数点钱m为 --m缺省,默认值是0 正整数 trunc trunc(n[,m])的功能是截取,其中n和m的定义和round (n[m])相同,不同的是功能上按照截取的方式处理数字n.例 mod mod(m,n)是取模函数,返回m除以n后的余数,如果n为0则直接返回m.例如: 1.薪水值按1000取余数 2.select ename,sal,mod(sal,1000)from employee; ceil,floor ceil(n),floor(n)这两个函数顾名思义,一个是天花板,就是取大于或等于n的最小整数值,一个是地板,就是取小于或等于n的最大正整数.比如数字n=4.5那么它的ceil是5.0 它的floor是4.0.在SQL语句中的例子如下: select ceil (45.678)from dual; select floor (45.678)from dual; DATE和timestamp是Oracle中最常用的日期类型,date用来保存日期和时间,表示范围是从公元前4712年1月1日至公元9999年12月31日 date类型在数据库中的实际存储固定为7个字节,格式分别为: --第1字节: 世纪+100 --第2字节: 年 --第3字节: 月 --第4字节: 天 --第5字节: 小时+1 --第6字节: 分+1 --第7 字节: 秒+1 表示时间戳,与date的区别是不仅可以保存日期和时间,还能保存小数秒,可指定为0-9,默认6为,最高精度可以到ns(纳秒)级别. 数据库内部用7或者11个字节存储,精度为0时,用7字节存储,与date的功能相同,精度大于0时则用11字节存储,格式为: --第1字节~~第7字节与date相同 --第8-11字节:纳秒,采用4个字节存储,内部运算类型为整型. 例如下图: 其中sysdate是日期关键字 系统时间的格式转换 select to_char(sysdate,’yyyy-mm-dd day hh24:mi:ss)from dual; 在建表时,可以将系统时间sysdate作为某一列的默认值,当插入新的记录,将会取消当时的系统时间,作为数据的一列保存起来,例如学生表: 用日期类建表的例子: YY 2位数字的年份 YYYY 4位数字的年份 MM 2位数字的月份 MON 简写的月份 MONTH 全拼的月份 DD 2位数的天 DY 周几的简写 DAY 周几的全拼 HH24 24小时制的小时 HH12 12小时制的小时 MI 显示分钟 SS 显示秒 查询入职日期 last_day: last_day(date):返回日期date所在 月的最后一天,一般是在按照自然月计算某些业务逻辑,或者按照月末周期性活动时很有用处.例如: select last_day(sysdate)from dual;查询当月的最后一天 例题:查询09年2月的最后一天代码如下: select last_day(’28-2月-09’)from dual; add_months(date,i):返回日期date加上i个月后的日期值.其中: --参数i可以是任何数字,大部分时候去正整数 --如果i是小数,将会被截取成整数后在参与运算 --如果i是负数,则获得的是减去i个月后的日期值 例如: 计算职员入职20周年纪念日 select ename,add_months(hiredate,20*12)"20周年"from emp; months_between(date,date2):计算date1和date2两个日期值之间间隔了多少个月,实际运算时date1-date2,如果date2事件比date1晚,会得到负值.除非两个日期间隔是整数月,否则会得到带小数位的结果,比如运算2009年9月1日到2009年10月10日之间会间隔多少个月,会得到1.29个月,例如计算职员入职多少个月:代码如下图 select ename,months_between(sysdate,hiredate)hiredate from emp; next_day(date,char):返回date日期数据的下一个周几,周几是由参数char来决定的,在中文环境下,直接使用”星期三”这种形式,英文环境下,需要使用”Wednesday”这种英文的周几,为避免麻烦,可以直接用数字1-7表示周日-周六. 需要注意的是next_day不要按字面意思理解为明天,查询下个周三是几号: 实例代码如下: select next_day(sysdate,4)next_wedn from dual; 其中代表的是周三 差上下周几 比较函数least和Greatest语法 两个函数都可以有多个参数值,但参数类型必须一致,返回结果是参数列表中最大或最小的值,在比较之前,在参数列表最终第二个以后的参数会被隐含的转换为第一个参数的数据类型,所以如果可以转换,则继续比较,如果不能转换将会报错. select least(sysdate,’10-10月-08年’)from dual; extract直译为抽取/提取: extract(data From datetime):从参数datetime中提取参数 date指定的数据,比如提取年,月. 例如取出当前日期的年: select extract(year from sysdate)current_year from dual; 取出指定时间的小时: select extract(hour from timestamp '2008-10-10 10:10:10')from dual; null时数据库里的重要概念,即空值,当表中的某些字段值,数据未知或者暂时不存在,取值null java中的简单数据类型是不能取值null的,在数据库中,任何数据类型均可取值为null. 在数据表中插入记录时,如果要插入null值,可以用显式指定null值方式或者不插入某个字段值,即隐式表示null值,例如表student中: 在条件查询中,因为null不等于任何值,所以不能用”列名=null”这种形式查询,必须采用”列名 is null ”来判断,或者用is not null来查询非空数据. 把表中数据更新为null值,把数据表的某个字段更新为null值,和更新为其他数据的语法是相同的, 非空约束 非空就是(not null)约束是约束条件的一种,用于确保数据表中的某个字段值不为空.因为在默认情况在,任何数据类型的列都允许有空值,但系统的业务逻辑可能会要求某些列不能去空值,这时需要在建表时指定该列不允许为空.一旦某个字段被设置了非空约束条件,这个字段中必须存在有效值,即: 当执行插入数据的操作时,必须提供这个列的数据,当执行更新操作时,不能给这个列的值设置为null. nvl(expr1,expr2):将null转变为非null值,如果expr1为null,则取值expr2,expr2是非空值. 其中expr1和expr2可以是任何数据类型,但两个参数的数据类型必须是一致的.就算员工收入,如果comm列为空值的话,最终计算结果将是空,不符合逻辑,所以先将取值null值的comm列转换为0,再相加. select ename,sal,comm,sal+nvl(comm,0)salary from emp; nvl2(expr1,expr2,expr3):和nvl函数功能类似,都是将null转变为非空值,nvl2用来判断expr1是否为null,返回expr2,如果是null,返回expr3. select ename,sal,comm,nvl2(comm,sal+comm,sal)salary from emp; 其中:select用于指定要查询的列,from指定要从哪个表中查询,如果要查询所有列,可以在select后面使用*,如果只查询特定的列,可以直接在select后指定列名,列名之间都用逗号隔开,查询dept表中的所有记录: select*fromdept: 在SQL语句中可以通过使用列的别名改变标题的显示样式,或者表示结果的含义,使用语法是列的别名跟在列名后,中间可以加或不加一个as关键字,例如: select empno as id ,ename “name”,sal*12 “annual salary”from emp; 别名可以直接写,不必用双引号引起来,但是如果希望别名区分大小写字符,或者别名中包含字符或空格,则必须用双引号引起来. 在select语句中,可以在where子句中使用比较操作符限制查询结果,是可选的.当查询条件中和数字比较,可以使用单引号,也可以不用,当和字符及日期类型的数据比较,,则必须用单引号引起,例如查询部门10下的员工信息: select*from emp where deptno=10; 如果只查询表的部分列,需要在select后指定列名, 例如: select empno,ename,sal,job from emp; 查询条件: 使用>,<,>=,<=,=,!= 在where子句中查询条件,可以使用比较运算符来做查询, 比如:查询表中工资低于2000的职员信息 select*from emp where sal<2000; 查询志愿表中不属于部门10的员工信息: select*from emp where deptno!=10; 查询职员表中在1983年1月1日以后入职的职员 信息 select ename,sal,hiredate from emp where hiredate>to_date('1983-1-1','yyyy-mm-dd'); 在SQL操作中,如果希望返回的结果必须满足多个条件,应该使用and逻辑,操作符连接这些条件,如果希望返回的结果满足多个条件之一即可,应该使用or逻辑操作符连接这些条件. 例如: 查询薪水大于1000且职位是clerk的职员信息 select ename,job,sal from emp where job='CLERK' and sal>1000; 当用户在执行查询时,不能完全确定某些信息的查询条件,或者只知道信息的一部分,可以借助like来实现模糊查询,like需要借助两个通配符: --%: 表示0到多个字符 --_ :表示单个字符: 这个两个通配符可以配合使用,构造灵活的匹配条件. 例如:查询职员姓名中第二个字是’A ‘的员工信息: select ename,job from emp where ename like’A%’; 在where子句中可以用比较操作符in(list)来取出符合列表中的数据.其中的参数list表示值列表,当列或表达式匹配于列表中的任何一个值时,条件为true,该条记录则被 显示出来. in页可以理解为一个范围比较操作符,只不过这个范围是一个指定的值列表. not in(list)取出不符合此列表中的数据记录, 例如查询职位是manager或者clerk的员工: select ename,job from emp where job in('MANAGER','CLERK'); 查询不是部门10或者20 的员工: 方法一 select ename,deptno from emp where deptno!=10 and deptno!=20; 方法二 select ename,job from emp where deptno not in (10,20); between…and…操作符用来查询符合某个值域范围条件的数据,最常见的是使用在数字类型的数据范围上,但对字符类型和日期类型数据也同样使用. 例如:查询薪水在1500-3000之间的职员信息: select ename,sal from emp where sal between 1500 and 3000; 空值null是一个特殊的值,比较的时候不能使用”=”号,必须使用is null,否则不能得到正确结果, 例如查询哪些职员的奖金数据为null; select ename,comm from emp where comm is null; 在比较运算符中,可以出现all和any,表示”全部”和”任一”,但是all和any不能单独使用,需要配合单行比较操作符>,>=,<,<=等一起使用.其中: >any:大于最小 >all:大于最大 例如:查询薪水比职位是”SALESMAN”的人高的员工信息,比任意一个salesman高 都行: select empno,ename,job,sal,deptno from emp where sal>any (select sal from emp where job='SALESMAN'); 当查询需要对选中的字段进行进一步计算,可以在数字列上使用算术运算表达式,(+,-,*./).表达式符合四则运算的优先级,如果要改变优先级,可以使用括号. 算数运算主要是针对数字类型的数据,对日期类型的数据可以做加减操作,表示在日期值上加或减一个天数. 查询条年间使用字符串函数upper,将条件中的字符串变大写后参与比较: select ename,sal,job from emp where ename=upper(‘cose’) 查询年薪大于10万的员工记录: select ename,sal from emp where sal*12>50000; 数据表中有可能存储相同的行,当执行查询操作时,默认情况下会显示所有的行,不管查询结果是否有重复的数据.当重复数据没有实际意义,经常会需要去掉重复值,使用distinct实现. 例如:查询员工的部门编码,包含所有的重复值: select deptno from emp; select distinct deptno,job from emp; 查询员工的部门编号去掉重复值: select distinct deptno from emp; distinct后面可以组合查询,下面查询每个部门的职位,去掉重复值,注意是的平台no和job联合起来不重复: select select deptno,job from emp; 对查询出的数据按照一定的规则进行排序操作,使用order by子句. 注意:order by必须出现在select中的最后一个子句. 岁职员表按薪水排序: select ename ,sal from emp order by sal; 排序时默认 按照升序排列,即由小到大,asc用来指定升序 排序,desc用来指定降序排序,因为null值视作最大,则升序排列时,排在最前,如果不写asc或desc,默认是asc,升序排列. 例如:按部门编号为10的员工的经理升序排序: select empno,ename,mgr from emp where deptno=10 order by mgr; select empno,ename,mgr from emp where deptno=10 order by mgr; 按照员工的薪水倒叙排序: select ename ,sal from emp order by sal desc; 当以多个列作为排序标准时,首先按照第一列进行排序,如果是第一列数据相同,在以第二列排序,以此类推,多列排序时,不管正序列还是倒序,每个列需要单独设置排序方式. 对表中的职员排序,先按照部门编码的正序排序,再按照薪水降序排列: select ename ,deptno,sal from emp order by deptno asc,sal desc; 查询时 需要做一些数据统计,比如:查询职员表中各个部门 职员的平均薪水,各部门的员工人数,当需要统计的数据 并不能只管列出,而是需要根据现有的数据计算得到的结果,这种功能可 使用聚合函数来实现. 即:将表的全部数据划分为几组数据,每组数据统计出一个结果.因为是多行数据参与运算返回一个结果,也称作分组函数,多行函数,集合函数,用到的关键字有: --group by 按什么分组: --having 进一步限制分组结果 在SQL语句中,增加having子句的原因是,where关键字无法与聚合函数一起使用,where条件用于过滤行,而having语句用于过滤分组数据. 聚合函数不能写在where后面,因为执行where的时候,聚合函数还没有执行. --having要和聚合函数结合使用,虽然也可以写普通字段的条件,但是普通字段的条件推荐写在where后面. sum( ):sum函数时返回值列的总数 avg( ):avg函数返回数值列的平均值,null不包括在计算中. count( ):count(column_name)函数返回指定列的值数目 max( ):max函数返回一列中的最大值,null值不包括在内. min( ):min函数返回一列中的最小值,nullhi不包括在内. 查询emp表中平均 薪水在1000到5000之间的部门编号有哪些? 用来取得列或表达式的最大,最小值,可以用来统计任何数据类型,包括数字,字符和日期.例如获取机构下的最高薪水和最低薪水,参数是数字: --计算最早和最晚的入职时间,参数是日期: avg和sum: avg和sum函数用来统计或表达式的平均值,这两个函数只能操作数字类型,并忽略null值 , 例如:获得emp表中全部志愿的平均函数和薪水总和: select avg(sal)avg_sal,sum(sal) sum_sal From emp; count函数用来计算表中的记录条数,同样忽略null值,例如获取职员表中一共有多少职员记录: select count(*)total_num from emp; 别名count(里面写表头)total_num 查询emp表中有多少人是有职位的(忽略没有职位的员工记录): select count(job) total_job from emp; select count(job) from emp; 注:数据库中的对象包括,表,视图,序列,索引. 用来对分组后的结果进一步限制,比如按部门分组后,得到每个部门的最高薪水,可以继续限制输出结果,必须跟在group by后面,不能单独存在. 例如:查询每个部门的最高薪水,只有最高薪水大于4000的记录才被输出显示: select deptno,max(sal) max_sal from emp group by deptno having max(sal)>4000; select deptno,max(sal) max_sal from emp group by deptno having max(sal)>4000; 当一条查询语句中包含所有的子句,执行顺序以下列子句次序: 1:from 子句: 执行顺序为从后往前,从右至左,数据量较少的 表尽量放在后面. from dual:伪表,当查询的内容不和任何表中的数据有关系时可以使用伪表,伪表只能查出一条语句记录. 比如: select upper(‘hello world’)from dual; 2.where子句 执行顺序为自上而下,从左到右,将能过滤掉最大数量记录的条件写在where子句的最右 3.group by: 执行顺序从左往右分组,做好在group by前使用where将不需要的记录在group by之前过滤掉. 4.having 子句: 消耗资源,尽量避免使用,having会在检索出所有记录之后才对结果集进行过滤,需要排序等操作. 5.select子句: 少用*号,尽量取字段名称.Oracle在解析的过程中,通过查询数据字典将*号依次转换成所有的列名,所以就消耗时间. 6.order by子句: 执行顺序为从左到右排序,消耗资源. 实际应用中所需要的数据,经常会需要查询两个或两个以上的表.这种查询两个或两个以上的数据表或试图的查询叫做连接查询,连接查询通常建立在相互关系的父子表之间.语法如下: select table1 column,table2.column from table1,table2 where table1 column1=table2.column2; select AVG(sal),deptno from emp where AVG (sal)>2000 group by deptno; 此处不允许where的原因是where的过滤时机不对. 查询员工名字及其所在部门(sales)的名字. 方式一: select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno and d.dname='SALES'; 方式二: select table1.column,table2.column from table1 join table2 on (table1.column1 table2.column2); select e.ename,d.dname from emp e join dept d on e.deptno=d.deptno where d.dname='SALES'; 内连接: 查询需要满足的条件:使不满足连接条件的记录是不会在关联查询中查询出来的. 外连接: 外连接除了会将满足连接条件的记录查询出来之外,还会将 不满足连接条件的记录也查询出来,外连接分为 左外连接和右外连接. 左外连接:以join左侧为驱动表(所有数据都会被查询出来)那么当该表中的某条记录不满足连接条件时,来自右侧表中的字段全部填null: 左外连接用left outer join关键字进行查询: 驱动表:主要显示数据的表 select e.ename,d.dname from emp e left outer join dept d on e.deptno=d.deptno; 右外连接:把left 转换为right: 笛卡尔积指进行关联操作的每个表的每一行都和其他表的每一行做组合,假设两个表的记录条数分别是x和y,笛卡尔积将返回x*y条记录,当两个表关联查询时,不写连接条件,的到的结果即是笛卡尔积. 不写连接条件,笛卡尔积显示结果14*4=56 内连接:内连接返回两个关联表中所有满足连接条件的记录. 外连接:在有些情况下需要返回那些 不满足连接条件的记录,需要使用外连接,即不仅返回满足连接条件的记录,还将返回不满足连接条件的记录,比如吧没有职员部门和没有部门的职员查出来. 语法如下: select table1.column,table2.column from table1[left|right|full]join table2 on table1.column1=table2.column2; 左外连接 右外连接 select e.name ,d.dname from emp e right outer join dept d on e. 全连接是指除了返回凉的表中满足连接条件的记录,还会返回不满足条件的所有其他行,即是左外连接和右外连接查询结果的总和. 例如: select e.ename ,d.dname from emp e full outer join dept d on e.deptnp=d.deptno; select e.ename ,d.dname from emp e full outer join dept d on e.deptno=d.deptno; 自连接: 自连接是一种特殊的连接查询,数据的来源是一个表,即关联关系来自于单表中的多个列,表中的列参照同一个表中的其他列的情况称作自参照表. 自连接是通过将表名别名虚拟成两个表的方式实现,可以是等值或不等值连接. 例如查询每个志愿的经理名字以及他们的职员编码: select worker.empno w_empno,worker.ename w_ename,manger.empno m_empno,man from emp worker join emp manager on worker .mgr=manger.empno; using子句:直接管理操作(了解) 查询部门编号为30的职员的所有信息: select*from emp join dept using(deptno)where deptno=30; on子句,自己编写连接条件: select*from emp t join dept d on t.deptno=d.deptno; 查询部门编号相等的元的信息 select *from emp join dept on emp.deptno=dept.deptno; select*from emp cross join dept; 1.按部门分组,查询部门名称和部门的员工数量 2.查询出部门平均工资大于2000的部门 3.查询出部门人数大于5的部门 子查询在where子句中 在select查询中,在where查询条件中的限制条件不是一个确定的值,而是来自于另外一个查询的结果.为了给查询提供数据而首先执行的查询语句叫做自查询. 子查询:嵌入在其它SQL语句中的select语句,大部分时候出现在where子句中.子查询嵌入的语句称作主查询或父查询.主查询可以是select语句,也可以是其它类型的语句比如DML或DDL语句. 根据返回结果的不同,子查询可分为单行子查询,多行子查询及多列子查询. 例如:查找和Scott同职位的员工: selecte.ename,e.job from emp e where e.job=(select job from emp where ename=’scott’); 例如:查找薪水比整个机构平均薪水高的员工: select e.ename,e.sal,from emp e where e.sal>(select avg(sal)from emp); 三行显示 例如:查询出比7654工资高的雇员: 在一个查询的内部还包括另一个查询,则此查询称为子查询. SQL的任何位置都可以加入子查询. 所有的子查询都必须在’(括号)’括号中编写 子查询包括3类 1.单行子查询 2.多行子查询 3.多列子查询 例如:查询出比雇员7654的工资高,同时从事和7788的工作一样的员工. select*from emp t1 where t1.sal>(select t.sal from emp t where t.empno =7654)and t1.job =(select t2.job from emp t2 where t2.empno=7788); from : 从哪张表 where : 普通字段的过滤 group by : 分组 having : 聚合字段的过滤 order by : 排序 select : 筛除 1.要求查询每个部门的最低工资和最低工资的雇员和部门名称 select d.dname,a.minsal,e.ename from dept d,(select deptno,min(sal) minsal from emp group by deptno) a,emp e where d.deptno=a.deptno and e.sal=a.minsal; 2.查询出每个部门最低工资的员工? select*from emp e where e.sal in (select min(sal) from emp group by depeno); 3.查询出所有员工的部门有哪些?(使用distinct关键字) select*from dept d where d.deptno in (select distinct deptno from emp); 4.查询拿最低工资的员工的信息 5.工资多于平均工资的员工的信息 6.最后入职的员工的信息 1.limit begin,size/count 2.limit 子句写在order by 子句之后 3.begin是本页数据的起始行,从0开始 4.size是本页数据要显示的总行数 例如:每页显示5条数据,查询第 三页数据: select 字段名1 from 表名 order by 字段名 1 limit 10,5 ; 自关联查询:(特殊的一对一关联) 如果一张表中保存的数据存在层级关系如:员工和上级领导,分类和上级分类,部门和直属部门 注意事项:查询数据时把一张表当成两张表用. 一对多关联 在数据多的表中添加一个关联关系字段 如用户与地址,类目与商品都是一堆多关联关系 通常一方称之为主表,多方称之为从表.(用户是主表,部门是从表) 设计方案:从表中添加一个字段,保存主表的主键. 一对一关联 两个表通过id关联 比如emp 和dept 一个对一个 多对多关联 必须使用中间表保存两张表之间的关系 什么是权限管理:每个用户都有不同的权限,通过用户角色模块和用户角色关系表,角色模块关系表用来保存每个用户所对应的模块信息. 1.视图也被称作是虚表,即虚拟的表,是一组数据的逻辑表示 2.数据库中存在多种对象,表和视图都是数据库中的对象(表,索引,视图,序列)(表和视图不能重名) 3.视图对应一条select语句,结果集被赋予一个名字,即视图名字 4.视图本身并不包含任何数据,它只包含映射到基表的一个查询语句,当基表数据发生变化,视图数据也跟着发生变化.(基表:基础的本来的那一张表) 5.视图的好处是可以重用子查询,而视图并不是一张表,他就是一个对象 6.创建视图是需要有权限的,需要由dba授权 7.创建视图的语句时create view 8.用户必须有create view系统权限才能创建视图. 9.如果没有权限会提示权限不足. 10.管理员可以通过dcl语句授予用户创建视图的权限.语法是grant create view to 用户名: 11.使用视图的目的:简化SQL语句的复杂度,重用子查询,限制数据访问. 查找视图 select*from 视图名: 密码sys 123456 Scott qqqqqq 创建视图的SQL语句: create or replace view v_emp_10 as select empno id,ename name,sal salary,deptno from emp where deptno=10; 修改视图 格式 : create or replace view 原视图名 as 新的子查询; create or replace view v_emp_10 as (select*from emp where deptno=10 and sal<3000); 视图分为简单视图和复杂视图 简单视图 在创建视图的子查询中不包含:关联查询, 去重 ,函数 ,分组 的视图称为简单视图. 复杂视图 和简单视图相反.对视图进行dml操作,只针对简单视图可以使用,因为复杂查询通常情况只是为了浏览数据用的.不需要也不能进行增删改查的操作. 视图的字段遵循原表字段的约束 如果往视图中插入一条数据,其在视图中不显示,但是在源表中显示的数据称之为数据污染,不建议这样操作. 数据污染只有insert命令才会出现数据污染,因update和delete命令只能操作视图中有的数据. 如何避免数据污染 with check option 短语表示,通过视图所做的修改必须在视图的可见范围内: create view v_emp_10 as select*from emp where deptno=10 with check option; 1.重用子查询,提高开发效率 2.限制数据的访问 drop view 表名; 在工作中一般只进行dql,不使用dml 显示部门的平均工资,最高工资,最低工资,工资总和,部门员工人数 create view v_emp_deptinfo as select deptno,avg(sal) a,max(sal)x,min(sal)n, sum(sals),count(*)c from emp group by deptno; 复杂视图指在子查询中包含了表达式,单行函数或分组函数的视图,此时必须为子查询中的表达式或函数定义别名. 复杂视图不允许dml操作(增删改查),会报错. 视图虽然是存放在数据字典中的独立对象,但是视图仅仅是基于表的一个查询定义,所以对视图的删除不会导致基表数据的丢失,不会影响基表数据. 序列(sequence)是一种用来生成唯一数字值的数据库对象.序列的值由Oracle程序按递增或递减的顺序自动生成,通常用来自动产生表的主键值,是一种高效率获得唯一键值的途径. 序列是独立的数据库对象,序列并不依附于表.通常情况下,一个序列为一个表提供主键,但一个序列也可以为多个表提供主键值. 创建序列: create sequence[schema.] sequence_name[start with i][increment bu j] [maxvalue m | nomaxvalue ] [minvalue n | nomnvalue] [cycle|nocycle][cache p | nocache] 其中 --sequence_name是序列名,将创建在schema方案下 --序列的第一个序列值是i,步进是j . 如果j是正数,表示递增,如果是负数,表示递减 序列可生成的最大值是m,最小值是n.如果没有设置任何可选参数值,序列的第一个值是1,步进是1. cycle表示在递增至最大值或递减至最小值之后是否继续生产序列号,默认是nocycle cache用来指定先预去p个数在缓存中,以提高序列值的生产效率,默认值是20. 删除序列: DROP SEQUENCE sequence_name; --用来加快查询的技术,其中最重要的是索引(index),通常索引能够快速提高查询速度. --如果不使用索引,MySQL必须从第一条记录开始,然后读完整个表直到找出相关的行.表越大,话费的时间越多. 索引可以用来改善性能,有时索引可能降低性能,如果数据库没有索引就相当于字典没有目录. B_tree索引:最常见的索引类型,大部分引擎大都支持B树索引. hash索引:只有mempry引擎支持,使用场景简单. R-Tree索引(空间索引):空间索引是myisam的一种特殊索引类型,主要用于地理空间数据类型. FULL-TEXT(全文索引);全文索引也是myisam的一种特殊索引类型,主要用于全文索引,innodb从MySQL5.6版本提供对全文索引的支持. 索引是独立于表的对象,可以存放在与表不同的表空间( TABLESPACE)中.索引记录中存有索引关键字和指向表数据的指针( 地址)对索引进行io操作要比对表进行操作要少很多.索引一旦被建立就将被Oracle系统 自动维护,查询语句中不用指定使用哪个索引,是一种提高查询效率的机制. CREATE INDEX索引名 on 表名( 列名1,列名2,列名….); unique索引:表示唯一的,不允许重复的索引.如果该字段信息保证不会重复例如身份证号用作索引是可设置为unique; 如何创建unique索引 create unique index 索引名 on 表名 (列的列表); 复合索引: 复合索引可以叫多列索引,是基于多个列的所有,如果经常在order by子句中使用job 和salary,作为排序依据,可以建立复合索引. create index idx_emp_job_sal on emp(job,dal); 如果经常在索引列上执行dml操作,需要定期重建所有,提高索引空间利用率,语法如下: alter index 索引名 rebuild; 当一个表上有不合理的索引,会导致操作性能下降,删除索引的语法: Drop index 索引名; 1.约束的作用: 约束的全称是约束条件,也称作完整的约束条件,约束是在数据表执行的一些数据校验规则,当执行dml操作时,数据必须符合这些规则,如果不符合则无法执行.约束条件可以保证表中数据的完整性,保证数据间的商业逻辑. 2.约束的类型 约束条件包括: --非空约束(not null),简称nn --唯一性约束(unique),简称uk --主键约束(primary key),简称pk --外键约束(foreign key),简称fk --检查约束(check),简称ck 3.非空约束 --建表时添加非空约束 非空约束用于确保字段值不为空,默认情况下,任何列都允许有空值,但业务逻辑可能会要求某些列不能取空值,当某个字段被设置了非空约束条件,这个字段中必须存在有效值,即: --当执行insert操作时,必须提供这个列的 数据 --当执行update操作时,不能给这个列的值设置为null 在建表时添加非空约束 例如: create table 表名 ( eid number (4),name varchar2(20)not null,salary number(7,2),hiredate dateconstraint 字段名 not null); 其中constraint为约束的意思 取消非空约束 如果业务要求取消某列的非空约束,可以采用重建表或修改表的方式: alter table 表名 modify (eid number (4)); 什么是唯一性约束? 唯一性(unique)约束条件用于保证字段或者字段的组合不出现重复值.当给表的某个类定义了唯一约束,该列的值不允许重复,但允许是null值. 唯一约束条件可以在建表时建立,也可以在建表以后再建立. 添加唯一性约束 create table 表名( eid number(4) unique , name varchar2(20) , email varchar2(200), salary number(7,2), hiredate date, constraint 字段名 unique(email) ); 在建表之后如何添加唯一约束条件: alter table 表名 add constraint 字段名 unique(name); 主键的意义 主键(primary key )约束条件从功能上看相当于非空(not null)且唯一(unique)的组合.主键字段可以是单字段或者多字段组合,即:在主键约束下的单子段或 多字段组合上不允许有空值,也不允许有重复值. 主键可以用来在表中唯一的确定一行数据,一个表上只允许创建一个主键,而其他的约束条件则没有明确限制. 主键选取的原则 --主键应是对系统无意义的数据 --永远也不要更新主键,让主键除了唯一标识之外,再无其他用途 --主键不应包含动态变化的数据,如时间戳 --主键应自生成,不要认为干预,以免使它带有除了唯一标识一行以外的意义. --主键尽量建立在单列上. 添加主键约束 在建表时添加主键约束条件: create table 表名 ( eid number(4) primary key, name varchar2(20), email varchar(200), salary number(7,2), hiredate date ); 在建表后添加主键约束: alter table 表名 add constraint 字段名 primary key (eid); 1.外键约束的意义 外键约束条件定义在两个表的字段或一个表的两个字段上,用于保证相关两个字段的关系,比如emp表的deptno列参照dept表的deptno列,则dept称作主表或父表,emp表称作从表或子表. 2.添加外键约束 先建表,在建表以后建立外键约束条件: create table 表名( eid number(4), name varchar2(20), salary number(7,2), deptno number(4) ); 3.修改外键约束 alter table 表名 add constraint 字段名 froeign key(deptbo) reference dept (deptno); 检查约束条件用来强制在字段上的每个值都要满足check中定义的条件.当定义了check约束的列新增或修改数据时,数据必须符合check约束中定义的条件. 事务是一组原子性的SQL查询,或者说是一个独立的工作单位,在事务内的语句要么全部执行成功,要么全部执行失败. 转账: updater user set money=money+500 where id=2; update user set money=money-500 where id=1; 事物的acid性质: 1.原子性:最小的单元,不可分割 2.一致性:保证SQL执行的一致性,要么都成功,要么都失败 3.隔离性:多个事务并发时,不能相互影响. 4.持久性:commit提交后,数据保存到数据库中. Java database connectivity:java访问数据库的解决方案,希望用相同的方式访问不同的数据库,以实现与具体数据库无关的java操作界面. jdbc定义了一套标准接口即访问数据库通用的API,不同的是不同的数据库厂商根据各自数据库的特点去实现折现接口. java代码通过jdbc实现与数据库的交互. 为什么要使用jdbc? 因为java语言需要连接各种数据库例如(Oracle,MySQL,db2等)为了避免java程序员每一种数据库都学一套相关的API,java语言中提出了一个jdbc接口,让各个数据库遵循这个接口去屑各自的驱动.这样程序员只需要学会掌握jdbc接口方法的调用就能够完成对各种数据库的操作. www.maven.aliyun.com下载jar包 1.加载驱动,建立连接 2.创建SQL语句对象 3.执行SQL语句 4.处理结果集 5.关闭连接 负责应用程序对数据库的连接,在加载驱动之后,使用url,username,password三个参数,创建到具体数据库的连接. 代码如下: 需要注意的是: connection只是接口,真正 的实现是由数据库厂商提供的数据包完成 Statement接口用来处理发送到数据库的SQL语句对象,通过Connection对象创建 主要方法有三个: Statement state=conn.createStatement( ); //1.execute( )方法,如果执行的sql语句是查询语句,且有结果集则返回true //如果没有结果集则返回false,说明创建成功. //如果创建失败则抛出异常. boolean flag =state.execute(sql) //执行查询语句返回结果集 ResultSet rs=state.executeQuery(sql) //执行dml语句,返回影响的记录数 int flag=state.executeupdate(sql); 由以上可知: Statement(语句)对象: --conn.getStatement( )方法创建对象 --用于执行SQL语句 --execute(ddl)执行任何SQL,常用来执行DDL,DCL --executeUpdate(dml)执行dml语句,如:insert update delete --executeQuery(dql)执行dql语句:如:select --execute(ddl):如果没有异常则表示成功 --executeUpdate(dml)返回数字,表示更新”行”数量,抛出异常则失败 --executeQuery(dql)返回ResultSet(结果集)对象,代表2维查询结果,使用for遍历处理,如果查询失败抛出异常! 最后关闭数据连接 ResultSet rs =state.excuteQuery (sql); 这里rs.next( )方法由游标的概念 查询结果存放在TesultSet 对象的一系列中,指针的最初位置在行首,使用next( )方法用来在行间移动,getXXX( )方法用来获取字段的内容. 从ResultSet中获取数据的两种方式: 1.rs.getInt(“字段名称”); 2.rs.getInt(index);//index表示字段的位置 index值从1开始 定义好db.properties之后,需要在java程序中找到它,此时需要使用从类路径加载的方式: String path=” D:\workspace1\JDBC\src\main\resources\db.properties”; //获得当前类的路径加载属性文件 properties.load(DBUtility.class.getClassLoader().getResourceAsStream(path)); 在工具类中定义公共的关闭连接的方法,所有访问数据库的应用,共享此方法.当完成功能,关闭连接. public static void closeConnection(Connection conn){ if(conn!=null){ try{ conn.close( ); }catch(SQLExcetption e){ e.printStackTrace( ); } } } ./src/main/resources/db.properties; 为什么要使用连接池 数据库连接的简历及关闭资源消耗巨大,传统数据库访问方式:一次数据库访问对应一个物理连接,每次操作数据库都要打开关闭物理连接,系统性能严重受损. 解决受训的方案是:创建数据库连接池(Connection pool). 系统初运行时,主动简历足够的连接,组成一个池,每次应用程序请求数据库连接时,无需重新打开连接,而是从池中取出已有的连接,使用完后,不再关闭,而是归还. 为什么要使用数据库连接池(续集) 连接池中连接的释放与使用原则 --应用启动时,创建初始化数目的连接的 --当申请时无连接可用或者达到指定的最小连接数,按增量参数值创建的连接 --为确保连接池中最小的连接数的策略: 1.动态检查:定时检查连接池,一旦发现数量小于最小连接数,则补充相应的新连接保证连接池正常运转. 2.静态检查:空闲连接不足时,系统才检测是否达到最小连接数,按需分配,用时归还,超时归还. 连接池也只是JDBC定义的接口,具体事项有数据库厂商完成. DBCP(dataBaseCOnnectionPoll):数据库连接池,是Apache的一个javaL连接池开源项目,同时也是Tomcat使用的连接池组件,相当于是一个Apache开发的针对连接池接口的一个实现方案. 连接池是创建和管理连接的缓冲池技术,将连接准备好被任何需要他们的应用使用. 创建一个值日表: id number(4) name varchar(20) password number(10) money number(50) email varchar(50) 优点: 1.相比较Statement代码结构整齐,可读性更高. 2.带有预编译 效果,SQL语句只编译一次,然后只需要修改不同的参数即可,所以执行效率要高于Statement( 效果不是太明显) 什么是Servlet? sun公司制定的一种用来扩展web服务器功能的组件规范. 需要把html文件写好,包括图片,视频,需要事先准备好,放到web服务器上面,然后通过浏览器访问. 需要经过计算生成HTML文件,如查询当前某支股票的价格,早起apache,文本server,iss等服务器都不能处理动态的资源请求.所以需要对web服务器的功能进行扩展,扩展方式是通过调用Servlet来处理动态资源请求. 容器在创建好Servlet对象后,就会调用此方法,该方法接收一个ServletConfig类型的参数,Servlet容器通过这个参数向Servlet传递初始化配置信息 用于获取Servlet对象的配置信息,返回Servlet的ServletConfig对象 返回一个字符串,其中包含关于Servlet的信息,例如作者,版本和版权等想信息 负责响应用户的请求,当容器接收到客户端访问Servlet对象的请求时,就会调用此方法,容器会构造一个表示客户端请求的ServletRequest对象和一个用户响应客户端的ServletResponse对象作为参数传递给service( )方法,在service( )方法中,可以通过ServletRequest对象得到客户端的相关信息和请求信息,在对请求进行处理后,调用ServletRequest对象的方法设置响应信息. 赋值释放Servlet对象占用的资源,当服务器关闭或者Servlet对象被移出时,,Servlet对象会被销毁,容器会调用此方法. 使用标准的http协议跟浏览器进行通讯且提供相应的资源,早期的web服务器(Apache,webserver,iis)只能处理静态的请求(即需要事先将html文件写好并添加到服务器上)不能够处理动态资源的 请求(即需要经过计算而生成html),所以需要扩展这些web服务器的功能.早期使用CGI来扩展. CGI:(Common Getway Interface)公共网关接口 可以使用c,perl等来开发符合CGI接口的规范.CGI开发繁琐,不好移植,所以用的就比较少了. 软件从附着于电脑硬件之日起,就在不断的进行着自我完善和演变,从其使用模式的角度出发,可以简单分为单机程序和网络程序.发展到今日仍有大量的不依赖网络的单机程序被我们使用,如记事本.Excel,PPT,ZIP压缩等软件都是大家熟知的装机必备软件. 当电脑越来越多的参与到日常生产生活中,单机程序已经不能满足企业的需要.企业应用能够最大程度的让更多的客户端参与到协同办公中,所以依赖于网络的程序开始大力发展起来.最早的网络程序是基于主机+终端模式的,也就是整个应用中只有一台大型主机,各个操作地点都是使用一条专线与主机相连,中断不提供运算和界面,类似于unix形式,所有的运算和处理都由主机来完成,主机 一般处理能力非常大.并且稳定,主要机型都是有IBM这样的大公司提供,但主机的高昂的价格和扩展难,维护费用高等弊端并不是一般企业能承受的,所以除银行,航空,证券,订票等大型企业在使用外,大大多数企业开始转投cs架构等程序,即客户端服务器架构. CS架构的发展过程经历了两层CS架构,三层CS架构以及多层CS架构的演变. 两层的cs架构是由客户端是客户端和后面的数据库组成的,数据库用于存放数据,并且使用数据库编程语言编写 业务逻辑,客户端使用VB、VC、Delphi这样的可视化变成方便的语言来开发客户端的输入输出界面. 用户通过界面向服务器发送请求,服务器发回的数据通过界面进行显示,服务器的角色就由数据来充当,这样做的好处就是开发效率高,满足企业需求,但是这种架构存在着很大的弊端,第一是可移植性差,如当数据库从SQL Server更换为Oracle时就必须将业务逻辑用新的语言在重新写一遍:第二则是大型系统做不了,因为客户端与数据库建立连接需要持续的连接,而数据库能够支持的最大连接数是有限的.所以在2000年这样的架构流行之后,慢慢的就开始向三层cs架构转变. 所谓的三层cs架构指的是客户端+应用服务器+数据库.即将混合在数据库的 业务逻辑从业务中分离出来放到应用服务器中,数据库只负责数据的管理,存储,检索.客户端负责界面.三层之中的应用服务器其实也是程序,类似于前面讲过的TCP socket编程,任何支持TCP编程的语言都可以作为应用服务器,三层CS架构的工作流程如图所示. 用户通过GUI(图形用户界面)进行操作,然后通用客户端的通信模块,将请求数据打包,通过网络发送请求,到达应用服务器同样也有一个通信模块,将受到的数据包按照协议尽心拆包,调用相应的业务处理模块,处理数据,其中可能需要访问数据库来完成数据的获取,将处理完的结果再次发送给通信模块,通信模块将结果按照自定义的协议进行打包,然后将数据包发送的客户端的通信模块,客户端进行拆包获取响应数据,将结果显示在界面,更新界面上的数据显示. 这样的程序结果虽然在一定程度上降低了对数据库编程的依赖,并且能够使用大型应用程序,但数据通信模块的增加却提升了开发的难度以及整体架构的复杂度. 什么是组件? 组件比喻成轮胎.运行Servlet的容器比喻为汽车, 符合规范,具有部分功能,并且需要部署到相应的容器里面才能运行的软件模块.Servlet就是一个符合Servlet规范的组件,不需要部署到Servlet容器里面才能运行. 什么是容器? 符合规范,提供组件的一卞环境的程序.Servlet容器(比如Tomcat雄猫)也是 要符合相应的Servlet规范. 在浏览器输入请求地址后,浏览器会依据IP地址及端口号找到对应的web服务器如果请求的是静态资源,web服务器直接提供相应:如果请求的是动态资源,web服务器的通信模块会将该请求 传递给Servlet容器的通信模块,Servlet容器负责创建Servlet实例,并将其中的数据解析出来传递给Servlet,在Servlet处理完数据后,相应结果也是由容器的通信模块负责返回给web服务器,后续的Servlet的销毁及管理都由容器来负责. 能够充当Servlet容器这个角色的有很多软件.如:Tomcat.所以Tomcat软件就同时具备了web服务器及Servlet容器的双重功能. 第一步:写一个java类,实现Servlet接口或者继承HTTPServlet抽象类. 第二步:编译 第三步:打包(即将Servlet变成一个组件)要创建一个具体有如下结构的文件夹: 文件夹: appname:(应用名,可以自定义) web-INF(固定写法) class(固定写法,存放.class文件) lib(可以没有,存放.jar文件) web.xml(固定写法,部署描述文件) 第四步:将 第三步创建好的整个文件夹拷贝到容器指定的位置. 注:可以将第三步创建好的整个文件夹使用jar命令压缩成.war文件,然后再拷贝. 第五步:启动容器,访问Servlet 打开浏览器,输入http.//ip:port/appname/url-pattern. 注:ip.port:容器所在的机器的ip地址,容器所监听的端口号(Tomcat默认的端口是8080)url-pattern:在web.xml中定义. 404 404是一个状态码,表示服务器找不到对应的资源. 产生原因: 1.请求路径写错 2.没有部署成功 500 1.500也是一个状态码,表示服务器运行出错. 2.产生的原因: --配置文件写错. --源代码出错. 比如没有继承HTTPServlet. 代码不严谨,比如对用户的输入的数据 没有做检查就做强势转换. 405 1.405也是一个状态码,表示服务器找不到处理方法. 2.产生的原因 --service方法不合法: bin目录存放启动和关闭服务器上的一些脚本(命令)common目录共享(部署在该服务器上的所有程序都可以使用)的一些jar包conf目录存放服务器的一些配置文件. webapps目录部署目录 work目录 服务器运行时,生成一些临时文件. 1.编写Servlet 创建package 创建一个类,名为xxxServlet 继承HTTPServlet,从而间接的实现了Servlet接口 重写父类的Servlet( )方法 2.配置Servlet 先声明类,并给他取别名(昵称) 再通过别名引用此类,给他取一个访问路径 在servers视图下选择Tomcat7 右键单击add and remove 在弹出窗口里将左边的待部署项目移动到右侧就可以了 启动Tomcat即可 格式:http://ip:port/项目名/网名--www.taobao.com 类是我们写的,但是管理和调用时容器帮我们做的. 1.是服务器的组件 2.满足sun规范 3.可以动态的拼资源(html/图片)等 是一种网络应用层协议,规定了浏览器与web服务器之间入户套通信以及相应的数据包的结构. 1.TCP/IP:网络层协议,可以保证数据可靠的传输(100%不出问题) 2.http:应用层协议:负责解释数据(接收方收到之后如何截取,如何编码解码等的问题) 1.建立连接 2.先打包后发送请求 3.打包后发送响应 4.关闭连接 为什么浏览器访问服务器是4个步骤,服务器访问数据库也是4个步骤? 1.请求行(请求方式,请求资源路径,协议和版本) 2.若干消息头 注:消息头是一些键值对(用”:”隔开)由http协议定义,表示特定的含义,比如:浏览器可以通过user-agent消息头告诉服务器,浏览器的类型和版本. 3.实体内容:具体返回的数据. 1.不用程序员处理的地方: --浏览器自动打包请求数据 --浏览器自动发送请求数据 --服务器自动打包响应数据 --服务器自动发送响应数据 2.需要我们处理的地方 --提供具体的请求中的业务数据 --提供具体响应中的返回数据 --通过request对象处理请求数据,通过response处理 响应数据 总而言之:我们只要会使用resquest和response对象就可以了. 写一个Servlet计算一个人的bmi指数 注:bmi=体重(公斤)/身高(米)/身高(米) 如何获得请求参数值 对于表单提交的数据,Servlet可以从容器构建的request对象中获取,如下两个方法可以在不同情况下获取表单数据: --String getParameter(String ParaName) --String []getParameterValues(String ParamName) getParameter( )方法: 主要用于获取表单中控件的数据.其中参数名一定要与客户端表单中的控件name属性一致,所以在构建表单各个元素时,name属性一定要有.而Name属性和id属性的区别在于id属性一般是作为客户端区分控件的标识,name属性是服务器端区分各控件的标识,如果参数名写错,则该方法返回null.
身高(米): 体重(公斤):
1.当有多个请求参数名相同时,使用此方法 2.对于多选框,如果不选择任何选项,则会获得null值. 1.get请求 哪些情况下,浏览器会发送get请求? 1.直接在浏览器地址栏输入某个地址 2.表达式默认的提交方式 3.点击链接 特点: 会将请求参数添加到请求行里面,只能提交少量数据 请求行只有一行,大约能存放2k左右的数据 缺点: 会将请求参数显示在浏览器的地址栏,不安全. 2.post请求 哪些情况下浏览器会发送post请求? 设置表单的method属性值为”post” 特点: 会将请求参数添加到实体内容里面所以可以提交大量数据. 不会将请求参数显示在浏览器的地址栏中,相对安全. 我们在使用out.println( )输出时,默认会使用”iso-8859-1”来编码,如果出现乱码,如何解决? response.setContentType(“text/html;charset=utf-8”); 练习:写一个ListUserServlet以表格的形式显示所有的用户信息,首先创建一个t_user表,表中有 字段username,password,phone.email.利用jdbc查询出t-user表中所有的用户信息.遍历ResultSet输出表格. Servlet容器如何创建Servlet对象,如何为Servlet对象分配,准备资源.如何调用对应的方法来处理请求以及如何销毁Servlet对象的整个过程即Servlet的生命周期. 1.实例化 --实例化是容器调用Servlet的构造器,创建响应的对象 2.什么时候实例化 1.容器收到请求后 2.容器启动之后,立即实例化 注:容器只会创建一个实例! 2.初始化 1.什么是初始化 --容器创建Servlet实例之后,接下来会调用该实例的init( )方法. --init( )方法只会执行一次! 注:init( )方法用于获取一些资源. --GenericServlet已经实现了init方法: 将容器传递进来的ServletConfig对象保存下来了,并且提供了getServletConfig方法用于获得该对象 --如何事项自己的初始化逻辑? 只要override GenericServlet的init( )方法.注意:是不带参数的init( )方法 a--容器在收到请求之后,会调用Servlet实例的service( )方法来处理请求. b--HTTPServlet类已经实现了service( )方法. 注:b1.(依据请求类型(get/post)调用对应的doGet或者doPost方法. b2.doGet( )方法和doPost( )方法只是一个抛出了一个异常. b3.可以override doGet和doPost,或者也可以Override service()方法来实现自己的处理路评级. 1.什么是销毁 1.容器在删除Servlet实例之前,会调用该实例的destroy方法. 2.该方法只执行一次 3.可以Override GenericServlet的destroy方法来实现自己的销毁处理逻辑. init(ServletConfig config) service(ServletRequest request,ServletResponse response); destroy( ) 实现了Servlet接口中的部分方法(init,destroy). 继承了GenericServlet,实现了Service方法. 练习:计算bmi指数 bmi=体重(公斤)/身高(米)/身高(米): 如果bmi指数 如果bmi指数>max 体重过重 春花秋月何时了往事知多少小楼昨夜又春风故国不堪回首月明中 当在浏览器中输入http://localhost:8080/firstweb/do这个地址后,容器首先会根据firstweb这个应用名找到webapps下面 的对应的文件夹,然后根据地址中的/do到web.xml文件中寻找与之匹配的 在ServletAPI中,最重要的是Servlet接口,所有Servlet都会直接或间接的与该接口发生联系,或是直接实现该接口,或间接继承实现了该接口的类. 该接口包括以下三个方法: --init(ServletConfig config) --service(ServletRequest request,ServletResponse response) --destroy( ) 在最开始指定Servlet规范时,设计者希望这套规范能够支持多种协议的组件开发,所以Servlet接口是一个最重要的接口,虽然我们的程序中编写的Servlet都是继承自HTTPServlet的,但本质上都是对该接口的实现,因为HTTPServlet就是针对Servlet这个接口的一个抽象实现类,可以理解为 HTTPServlet是支持HTTP协议的分支的一部分.设计Servlet接口中的service方法时,也是希望该方法能够处理多种协议的请求及响应,所以参数类型时ServletRequest,而在HTTPServlet这个支持HTTP协议的分支中,service方法的参数则变成了HTTPServletRequest和HTTPServletResponse.这两个类分别继承于ServletRequest和ServletResponse,也就是对这两个类的一个具体协议的包装,区别是增加了很多与HTTP协议相关的使用API. 制定的这种规范在实际使用中发现,并不会扩展为http协议之外,所以有了过度设计的缺陷,也在编写http协议的web应用时添加了一些不必要的操作. ServletAPI中另一个重要的类就是GenericServlet这个抽象类,它对Servlet接口中部分方法(init和destroy)添加了实现,使得开发时只需要考虑针对service方法的业务实现即可. HttpServlet又是在继承GenericServlet的基础上进一步扩展,一个是public void (ServletConfig config),另一个是public void init( ).他们有如下的关系: init(servletConfig config)方法由Tomcat自动调用,它读取web工程下的web.xml,将读取的信息打包传给此参数,此方法的参数同时将接受的信息传递给GenericServlet类中的成员变量config,同时调用init().以后程序员想重写init( )方法可以选择init(ServletConfig config)或者init( ),但是选择(ServletConfig config)势必会覆盖此方法已实现的内容,没有为config变量赋值,此后若是想调用getServletConfig( )方法返回config时会产生空指针异常,所以想重写init( ServletConfig config)方法,必须在方法体中第一句写上super.init(config).为了防止程序员忘记重写super.init(config)方法.sun公司自动为用户生成一个public void init( )方法. GenericServlet具体的定义如下所示: GenericServlet{ ServletConfig config; public void init ( ){}此方法什么也没做,就是为编程人员预留了接口. 1.断点 2.打桩:System.out.pringln( ); sun公司制定的一种服务器端动态页面,但是过于繁琐(需要使用out.pringln输出)并且难以维护(指的是修改页面,此时需要修改java代码所以繁琐),因此sun公司才制定了jsp规范. jsp是一个以.jsp为后缀的文件,该文件被容器转换成一个对应的Servlet然后执行,也就是说jsp的本质就是一个Servlet. 注:jsp里面既有html 也有java代码. 1.添加一个以.jsp为后缀的文件.在该文件里面,可以添加如下内容: --html( css, JavaScript):直接写 --java代码 1.java代码片段(不是完整的java类)<%java代码%>注意:”<”与”>”与%之间不能有空格. 2.jsp表达式<%=java表达式%> --隐含对象 1.可以直接使用的对象比如:out,request,response 2.为什么可以使用这些隐含对象呢?容器会添加获得这些隐含对象的代码. --指令 1.指令是通知容器,在将jsp转换成Servlet时,做一些额外的处理,比如导包. 2.语法<%@page import=”java.util.*”%> <%@page import=”java.util.*,java.text.*”%> contentType属性:设置response.setContentType方法的参数值 pageEncoding属性:告诉容器,在读取jsp文件的内容时使用指定的字符集去 解码. session属性:默认值是true,如果值是false,则session隐含对象就不能用了,即不能生成.class文件. errorpage属性:指定一个异常处理页面.注:当jsp运行时发生了异常,容器会调用指定的异常的处理页面. html(css,js)à在service( )方法里面,使用out.write输出. 注:out.writ( )方法会将null转换成””输出 而out.println( )方法会将null直接输出 <% %>àservice( )方法里面照搬过来 <%= %>àservice( )方法里面使用out.println输出 out.write( )不支持object类型,他只支持基本类型包括字符串. out.println( )支持对象类型的输出 写一个DelUserServlet依据id删除指定用户 response.sendRedriect(“list”); response.getWriter( ).println(“系统繁忙,稍后重试”); 服务器通知浏览器 访问一个新的地址.注:服务器可以通过发送一个302状态码及一个loaction消息头(该消息头的值是一个地址,一般称之为重定向地址)给浏览器,浏览器收到以后会立即向重定向地址发送请求. 语法:response.serdRedirect(String url); 画图解释 浏览器 服务器 数据库 什么是转发 在web服务器端处理用户请求的时候,会后需要多个文本组件配合才能完成的情况.一个web组件(Servlet/jsp)将未完成的处理通过容器转交给另外一个web组件继续完成.这个转交的过程称为转发. 常见的情况是Servlet负责获取数据,然后将数据交给jsp进行展现. 第一步 1.通常将数据绑定到请求对象request上面,request.setAttribute(String name,object obj)它的本质是什么呢?(setAttribute的源代码的实现方式) 以name作为key,以obj作为value,把数据放到map里面,所绑定的实质是将数据放到了map里面. 比如:request.setAttribute(“user”,user) 在map中只有给定key就可以找到对应的value,所以map中还有一个方法: object request.getAttribute(String name)这个方法的含义就是根据绑定名把绑定值取出来,如果绑定名对应的值不存在,就会返回null. 第二步 获得转发器 RequestDispatcher rd=request.getRequestDispatcher(String uri; 注:RequestDispatcher是一个接口. uri和url的区别 uri:uniform Resource Identifier统一资源标识符(是转发的目的地,通常是一个jsp.) url:uniform Resource Locator 统一资源定位符(网页地址) url是uri的子集,任何东西只要能够唯一地标识出来,都可以说这个标识是uri,如果这个标识是一个可获取到上述对象的路径,那么同时他也可以是一个url,但如果这个标识不提供获取到对象的路径,那么它就必然不是url 第三步 转发 rd.forward(request,response) 转发的本质:是Servlet通过转发器来通知容器调用另外一个web组件. 1.能否共享request和response 转发可以 ,重定向不可以 注: request和response的生存时间是一次请求和一次响应期间存在. 2.浏览器地址栏有无变换 转发没有变化,重定向有变化 3.目的地有无限制 转发是有限制(同一个应用里面),重定向没有限制. 链接地址,表单提交,重定向,转发 表单提交:” ”> 重定向:response.sendRedirect(“”) 转发:request.getRequestDispatcher(“”) 相对路径 不以斜杠开头的”/ ”路径. 如何写绝对路径? 链接地址,表单提交,重定向从应用名开始写,而转发从应用名之后开始写. 注意:不要将应用名直接写在路径里面,而应该使用以下方法来获得实际部署时的应用名 String request.getContextPath( ) 建议使用绝对路径,易写易维护. 在jsp页面中可以添加两种类型的注释 1. 2.<%-注释的内容--%> 第一种注释也叫HTML注释,可以出现在jsp页面之中,注释内容中可以包含了一些java代码,但这些代码会被执行. 第二种注释是jsp注释,不允许注释的内容出现java代码,写了java代码也会被忽略,不会执行. <%=3+5%> <%=add()%> <%=xx.getName( )%> <%=xx.getName()+”abc”%> 将浏览器与服务器之间多次交互,当做一个整体来看待并且将多次涉及交互的数据(即状态)保存下来. 1.将状态保存在浏览器端(cookie:临时存放浏览器端的少量数据) 2.将状态保存在服务端(session) 当浏览器第一次访问服务器时,服务器会将少量数据以set-cookie消息头的形式发送给浏览器,浏览器会将这些数据保存下来.当浪浏览器去再次访问服务器时,会将这些数据以cookie消息头的形式发送给服务器.如图所示: Cookie c=new Cookie (String name ,String value); 注:name称之为cookie的名称,value 称之为cookie的值. response.addCookie(C); 注:读取浏览器发送过来的cookie Cookie[ ]request.getCookets( ); 注:该方法有可能返回null! String cookie.getName ( ); String cookie.getValue( ); 1.什么是cookie的编码问题? cookie只能存放合法的ASCII私服,中文需要转换成ascii字符的形式来存放. 2.如何处理? 1.在添加cookie时,使用encode方法 String URLDecoder.encode(String str ,String charsset); 2.在读取cookie时,使用decode方法. String URLDecoder.decode(String str,String charset); 建议:添加cookie时,最好统一使用encode方法编码. 1.浏览器默认情况下,会将cookie保存在内存里面. 注:浏览器只要不关闭,cookie就会一直存在,关了,则cookie会被销毁. 2.可以调用一下方法来设置生存时间 cookie.setMaxAge(int seconds) 注:b1.单位是秒 cookie.setMaxAge(365*24*60*60); b2.seconds可以大于0,等于0和小于0 大于0:浏览器会把cookie保存在硬盘上,超过指定时间,浏览器会删除该cookie 小于 0:(缺省值),即把cookie存放到内存里. 等于0:浏览器会立即删除该cookie. 比如,要删除名称为uid的cookie: Cookie c=new Cookie( “uid”,” ”); c.setMaxAge(0); response.addCookie(c); 1.什么是路径 问题 浏览器在向服务器上的牟特地址发送请求时,会查看cookie的路径是否与该路径匹配,只有匹配的cookie才会被发送. 2.cookie的默认路径 等于添加该cookie的文本组件的路径. 比如:/day07/biz01/addCookie.jsp添加了一个cookie,则该cookie的默认路径是”/day07/biz01” 3.匹配规则 请求路径必须等于cookie的路径,或者是其子路径. 例如:cookie的路径是”/day07/biz01”,则如果请求路径是”/day07/findCookie1.jsp”不匹配(即该cookie不会发送给服务器).如果请求路径是”/day07/biz01/findCookie2.jsp”,则匹配.如果请求路径是”/day07/biz01/sub/findCookie3.jsp”则匹配. 1.cookie不安全 对于敏感数据,尽量不要以cookie的形式存放,如果要存放cookie里面一定要加密. 2.cookie可以被用户加密 3.cookie只能保存少量的数据(大约是4k左右) 4.cookie的数量也有限制. 注:浏览器只能存放约几百个cookie. 5.cookie只能存放字符串. 添加cookie保存用户名 String username =URLEncoding.encode( “ username“,”utf-8”); 服务器为了保存状态而创建的一个特殊的对象. 注:该对象有一个唯一的id,一般称之为sessionId. 当浏览器第一次访问服务器时,服务器会创建session对象,并且将sessionID默认以cookie的形式发送给浏览器.当浏览器再次访问服务器时,会将sessionID发送过来,服务器可以利用sessionId找到对应的session对象. 1.方式一 HttpSession s=request.getSession(Boolean flag); 注: 1.HttpSession是一个接口 2.当flag为true时 先查看请求当中有没有sessionid,如果没有,创建一个session对象.如果有,则依据sessionId查找对应的session对象,如果找到了,则返回,找不到,则创建一个新的session对象 3.当flat为false时 先查看请求当中有没有sessionId,如果没有,返回null,如果有,则依据sessionId查找对应的session对象,如果找到了,则返回,找不到,则返回null. 2.方式二 HttpSession s=request.getSession( ); 等价于request.getSession(true) //绑定数据 setAttribute(String name,Object obj) //依据绑定名,获得绑定值 Object.getAttribute(String name) //解除绑定 removeAttribute(String name) 1.什么是session超时? 服务器会将空闲时间长的session对象删掉. 1.这样做的目的是为了节省内存空间的占用. 2.大部分服务器默认的时间限制是30分钟. 2.如何修改超时的时间限制? 1.方式一 修改web.xml文件中的配置 2.方式二 setMaxInactiveInterval(int seconds) invalidate( ); 1.流程 用户填写用户名和密码并提交,服务器端根据用户名和密码查询数据库,如果有匹配的记录,则登录成功(返回欢迎页面);否则登录失败(在登录页面中,提示用户名或密码错误). session既然区分不同的客户端,所以可以利用session来实现对访问资源的保护,如:可以将资源划分为登录后才能访问,session多用于记录身份信息,在保护资源被访问前可以通过判断session内的信息来决定是否允许,这是依靠session实现的验证 1.第一步 HttpSession s=requestgetSession( ); s.setAttribute(“username”,”jim”); 2.第二步 读取Session对象中的绑定值,读取成功代表验证成功,读取失败则跳转回登录页面. HTTPSession s=request.getSession( ); if(s.getAttribute(“username”)==null){ response.sendRedirect(“login.jsp”); }else{ … } session对象的数据由于保存在服务器端,并不在网络中进行传输,所以安全一些,并且能够保存的数据类型更丰富,同时session也能够保存更多的数据,Cookie只能保存大约4kb的字符串. session的安全性是以牺牲服务器资源为代价的,如果用户量大,会严重影响服务器的性能. session对象的查找依靠的是SID,而这个ID保存在客户端是以cookie的形式保存,一旦浏览器禁用cookie,那么SID无法保存,session对象将不再能使用. 为了禁用cookie后依然能使用session,那么将使用其他的存储方法来完成SID的保存,URL地址在网络传输过程中,不仅仅能起到标示地址的作用,还可以在其后,携带一些较短的数据,SID就可以通过URL来实现保存,及URL重写. 浏览器在访问服务器的某个地址时,会使用一个改写过的地址,即在原有地址后追加SessionID,这种重写定义URL内容的方式叫做URl重写 如:原有地址的写法为http://localhost:8080/test/some 重写后的地址写法为http://localhost:8080/test/some/;jsessionid=4E113CB3…DEF23… 生成链接地址和表单提交时,使用如下代码: ”<%=response.encodeURl(String url)”>%>>链接地址 如果是重定向,使用如下代码代替response.sendRedirect( ). response.encodeRedirectURL(String url); 验证码技术可以防止对于应用恶意发送数据,因 其不规律且不能由机器代劳,所以一定程度上避免了恶意程序对网站服务器的攻击. 验证码本质上是一张图片图片内容的准确解析不容易用程序来实现,所以能避免内容被快速读取,并且,图片的内容是使用程序随机生成后绘制得到.注册,登录这样的功能一般都会配备验证码,一定程度上避免恶意代码的攻击. 绘制验证码图片不仅仅需要随机生成要绘制的 内容,同时要配合java中与绘图有关的一套API来完成,绘制API将画板,画笔,颜料,字体等都解释为对象,绘制过程就是这些对象相互配合完成的,主要涉及Graphics,Font等类型. 是Servlet规范中定义的一种特设的组件,用于拦截Servlet容器的调用过程 注:Servlet容器收到请求后悔先调用过滤器. 第一步 写一个java类,实现filter接口/ 第二步 在接口方法(dofilter)当中实现拦截处理逻辑 第三步 配置过滤器 编写过滤器遵循以下步骤 1.编写一个实现了Filter接口的类 2.实现Filter接口的三个方法,过滤逻辑在doFilter方法中实现 3.在web组件中注册过滤器 4.把过滤器和web应用一起打包部署. 在一个web应用中,可以有多个过滤器,他们的优先级由位于web.xml 文件中的声明顺序决定,具体是按照 客户端答案来请求后不会直接执行,先去过滤. 当有多个过滤器都满足过滤的条件,则容器依据配置的先后顺序来执行. Servlet规范中定义的一种特殊的组件,用于监听容器产生的时间并进行相应的处理 1.生命周期相关的事件: 容器创建或者销毁了request,session,Servlet上下文时产生的事件. 2.绑定数据相关的事件: request,session,Servlet上下文执行了setAttribute,removeAttribute产生的事件. 3.什么是Servlet上下文 容器启动后,会为每一个web应用创建一个符合servletContext接口要求的对象.该容器对象一般称之为Servlet上下文. 注:该对象有两个特点: 唯一性:一个web应用对应一个上下文 持久性:只要容器不关闭,应用没有被卸载,上下文就会一直存在. 4.如何获得Servlet上下文. GenericServlet,ServletConfig,FilterConfig,HTTPSession都提供了getServletContext方法. 5.Servlet上下文的作用 1.绑定数据 setAttribute,getAttribute,removeAttribute 其中request,session,Servlet上下文都可以绑定数据,但是有区别: 区别 1 从生存的时间长度来看,request 区别2 绑定到上下文上数据,所有用户都可以共享,绑定到session上的数据,只有session对应的用户可以使用. 第一步: 写一个java类,实现响应的监听器接口. 注:要跟根据监听的事件类型,选择实现响应的接口,比如,要监听session的创建和销毁,应该实现HTTPSessionListener接口. 第二步: 在接口方法中,实现监听处理逻辑. 第三步: 配置监听器,web.xml 1.为什么说Servlet会有线程安全问题? --容器只会创建一个Servlet实例 --容器收到一个请求,就会启动一个线程来处理请求.如果有多个线程同时访问某个Servlet实例,比如都去修改实例的属性,就有可能产生 线程安全问题. 1.什么是指令? 通知容器,在将jsp装换成Servlet时做一些额外的处理比如导包 2.语法 <%@ 指令名 属性=值 %> 3.page指令 1.contentType属性:设置 response.setContentType方法的参数值. 2.pageEncoding属性:设置jsp页面的编码. 3.import属性:导包 4.session属性:缺省值是true,如果是false,则session隐含对象就不能用了. 容器会为每一个jsp实例创建唯一的一个符合pageContext接口要求的对象,一般称之为page上下文. 特点: 唯一性:一个jsp实例对应一个page上下文. 持久性:只要jsp实例还在,那么page上下文就一直存在. pageContext的作用 1.绑定数据. 注:绑定到page上下文的数据,只有对应的jsp实例能够 访问. 2.通过该对象,找到其它所有隐含对象. exception(只有当isErrorPage属性为true时,才能使用) page(jsp实例本身) 注:jsp 先转换成Servlet,然后实例化,jsp实例指的就是这个对应的Servlet实例 . config(ServletConfig) 参见9.jsp实例 1. 如果注释的内容是java代码,java代码会执行. 2.<%--注释的内容--%> 如果注释的内容是java代码,java代码不执行. 1.容器要将jsp转换成Servlet. htmll--àservice( )方法,使用out.writer输出 <% %>--àservice( )方法,照搬过来 <%= %>--àservice( )方法,使用out.print输出 <%! %>--à增加新的属性和方法. 2.执行该Servlet. jsp标签是sun指定的一种用来代替jsp中java代码的技术规范,语法类似于HTML标签(有开始标记和结束标记,有属性). 注:因为直接在jsp文件中写java代码,不利于jsp文件的维护(比如,将包含有个java代码的jsp文件交给美工去修改就很不方便,)所以sun制定了jsp标签技术. 使用jsp标签的好处 1.方便美工区修改. 2.jsp文件变得更简洁,而且可以实现代码的重用. el表达式是什么? 是一套简单的运算规则,用来给jsp标签的属性赋值. 注:el表达式也可以脱离jsp标签,直接使用 . el表达式的使用 1.读取bean的属性 注:如果一个java类满足如下几个条件,就可以称之为一个Javabean: --public class --public 构造器 --有一些属性及对应的get/set方法 --实现Serializable接口 方式一 ${user.username} 注: 1.执行流程:容器依次从pageContent,request,session,application中查找绑定名为”user”的对象,找到了,则调用该对象的”getUsername”方法,然后输出. 2.优点:跟直接写java代码相比,更简洁,会将null转换成” ”输出.如果找不到对应的对象,不会报空指针异常. 3.如果要指定查找范围,可以使用pageScope,requestScope,sessionScope,applicationScope来指定. 方式二 ${user[‘username’]} 1.等价于${user.username}. 2.[ ]里面,可以使用绑定名. 3.[ ]里面,可以使用从0开始的下标,用于访问数组中的某个元素. 例:student s1=new Student(“ 建国 ”); s1.study( ); java虚拟机是如何执行以上两行代码的? JVM启动后操作系统会为虚拟机分配一块内存空间,JVM就是一个进程,JVM拿到内存空间后,会对其进行分配,分成三大块,堆,栈,方法区,其中堆最大且只有一个,方法区也只有一个,栈可以有很多个.栈的数量取决于你启动了多少个线程,一个线程一个栈,当JVM读取Student s1=new Student(“建国区”)的时候,JVM会看方法区里是否有Student类对应的.class对象( 等同于字节码文件 ) class对象就相当于硬盘上的.class字节码文件中的内容读到内存中的对应物. 刚开始的时候没有.class对象,JVM会派遣其手下的一员大将. 类加载器(ClassLoader)将硬盘上的.class字节码文件读到方法区中,那么在方法区中就会生成一个对象,这个对象就叫class对象. 只要方法前加了注解,方法就自动执行,把注解看成java类. @override @test ajax(asynchronous JavaScript and xml) 创建交互式 Web 应用程序而无需牺牲浏览器兼容性的流行方法(Asynchronous JavaScript and XML); ajax是一种用来改善用户体验的技术,其实质是利用浏览器提供的一个特殊对象(XMLHttpRequest)对象异步地向服务器发送请求,服务器一般只需要返回部分数据(包括文本或者xml文档),浏览器利用这些数据更新当前页面,整个过程就是页面的刷新,不打断用户操作,增加用户体验. 注: 异步:ajax对象向服务器发送请求时,浏览器不会销毁当前页面,用户依然可以对当前页面做其他操作. function getXhr( ){ var xhr=null; if(window.XMLHttpRequest){ //非IE浏览器 xhr=new XMLHttpRequest( ); }else{ xhr=new ActiveXObject(‘Microsoft.XMLHttp’); } return xhr; } 1.onreadystatechange:用来绑定一个事件处理函数,(该函数用来处理readystatechange事件). 注:当ajax对象的readyState属性发生了改变,比如从0变成1,就会产生readystate事件. 2.readyState:有5个属性,分别是0,1,2,3,4表示ajax对象与服务器之间通信的状态,比如:值为4时表示ajax对象已经获得了服务器返回的所有的数据 3.responseText:作用是获得服务器返回的文本 4.responseXML:作用是获得服务器返回的XML文档. 5.status:获得服务器返回的状态码. 1.获得ajax对象 比如:var xhr =getXhr( ); 2.使用ajax对象发送请求, (1).get请求 xhr.open(‘get’,’check_uname.do?uname=Jim’,true); xhr.onreadystatechange=f1 xhr.send(null也可以是字符串); 注:如果是true:发送 异步请求(浏览器不会销毁当前页面,用户任然可以对当前页面做其他操作).如果是false:发送同步请求(浏览器不会销毁当前页面,但是浏览器会锁定当前页面,用户就不能对当前页面进行操作了) 3.编写服务端的程序,一般不需要返回完整的页面,只需要返回部分数据. 4.编写事件处理函数f1 function f1 ( ){ //必须等到ajax 对象获得了服务器返回的所有数据. if(xhr.readyState==4){ var txt=xhr.responseText; //使用txt更新当前页面. } } Spring一个分层的java SE/EE full-stack(一站式)轻量级开源框架,它以IOC(Inversion of Control,控制反转)和AOP(Aspect Oriented Programming,面向切面编程)为内核,使用基本的JavaBean来完成之前只可能由EJB(Enterprise Java Beans,java企业Bean)完成的工作,取代了EJB臃肿低效的开发模式. Spring致力于Java EE应用各层的解决方案,在表现层它提供了 Spring MVC以及与Struts框架的整合功能;在业务逻辑层可以管理实务,记录日志等;在持久层可以整合MyBatis,Hibernate,JdbcTemplate等技术,因此,可以说Spring是企业开发很好的一站式原则,虽然Spring贯穿于表现层,业务逻辑层和持久层,但它并不想取代那些已有的框架,而是以高度的开放性与他们进行无缝整合. Spring具有简单,可测试和松耦合的特点,从这个角度出发,Spring不仅可以用于服务器端开发,也可以应用于任何Java应用开发中,优点如下: 1.非侵入式设计 Spring是一种非侵入式框架(Non-invasive).可以使应用程序代码对框架的依赖最小化. 2.方便解耦,简化开发 Spring就是一个大工程,可以将所有对象的创建和依赖关系的维护工作都交给Spring容器,大大降低了组件之间的耦合性. 3.支持AOP Spring提供了对AOP的支持,它允许一些通用任务,如安全,事务,日志等进行集中式处理,从而提高了程序的复用性. 4.支持声明式事务处理 只需要通过配置就可以完成对事务的管理,而无需手动编程. 5.方便程序的测试 Spring提供了对Junit4的支持,可以通过注解方便的测试Spring程序 6.方便集成各种优秀框架. Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架(如Struts,Hibernate,MuBaties,Quartz等)的直接支持. 7.降低了javaEE APIDE使用难度 Spring对javaEE开发中非常难用的一些API(如 JDBC,JavaMail)都提供了封装,是使这些API应用难度大大降低 Spring框架采用分层结构,它的一系列功能分为20个模块,大体分为Core Container ,Data Access/Integration.Web,AOP(Aspect Oriented Programming),Instrumentation,Messaging和Test,如下图所示. 其中灰色背着主讲. 1.Core Container(核心容器) Spring的核心容器是其他模块的建立的基础,,它主要由 Beans模块,Core模块,Context模块,Context-support模块和SpEl(Spring Expression Language,spring表达式语言)模块组成,具体介绍如下: 1.Beans模块: 提供了BeanFactory,是工厂模式的经典实现,Spring将管理对象称之为Bean 2.Core核心模块: 提供了Spring框架的基本组成部分,包括loCal和DI功能. 3.Context上下文模块: 建立在Core和Beans模块的基础之上,它是访问定义和配置的任何对象的媒介.其中Application接口是上下文模块的焦点. 4.Context-support模块: 提供了对第三方嵌入Spring应用的集成支持,比如缓存(EhCache,Guava,JCache),邮件服务(JavaMail),任务调度(CommonJ,Quartz)和模板引擎(FreeMarker,JasperReports,速率). 5.SpEl模块: 是Spring3.0后新增的模块,提供Spring Expression Language支持,是运行时查询和操作对象图的强大的表达式语言 2.Data Access/Integration(数据访问/集成) 数据访问/集成层包括JDBC,ORM,OXM.JMS和Transactions模块 6.JDBC模块 提供了一个JDBC的抽象层,大幅度减少了在开发过程中对数据库的操作编码 7.ORM模块: 对流行的对象关系映射API,包括,JPA,JDO和Hibernate提供了集成层支持 8.OXM模块: 提供了一个支持对象/XML映射的抽象层实现,如JAXB,Castor,XMLBeans,JIBX和XStream. 9.JMS模块: 指的是java消息传递服务,包含使用和生成信息的特性,自4.1版本后支持与Spring-message模块的集成. 10.Transaction事务模块: 支持对实现特殊接口以及所有POJO类的编程和声明式的事务管理 3.Web Spring的web层包括WebSocket,Servlet,Web和Portlet模块 11.WebSocket模块: 支持webSocket和SockJS的实现,以及对STOMP的支持 12.Servlet模块: 也称为Spring-webmvc模块,包含了Spring的模型--视图--控制器 13.Web模块: 提供了基本的Web开发集成特性,例如多文件上传,使用Servlet监听器来初始化loC容器以及Web应用上下文 14.Protlet模块: 提供在Protlet环境中使用MVC实现,类似Servlet模块的功能. 4.其他模块 15.AOP模块 提供面向切面编程实现,允许定义方法拦截器和切入点,将代码按照功能进行分离,以降低耦合性 16.Aspects模块 提供与AspectJ的集成功能,AspectJ是一个功能强大的且可成熟的面向切面编程(框架) 17.Instrumentation模块 提供了类工具的支持和类加载器的实现,可以在特定的应用服务器中使用 18.Messaging模块 Spring4.0后新增,提供对消息传递体现结构和协议的支持 19.Test模块 提供了对单元测试和集成测试的支持 1.BeanFactory 2.ApplicationContext Id 是一个Bean表示符,Spring容器对Bean name Spring容器同样通过此属性对容器中的Bean进行配置和管理,name属性中可以为Bean指定多个名称,每个名称之间用逗号或者分号隔开 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。 注意: 1、单例类只能有一个实例。 2、单例类必须自己创建自己的唯一实例。 3、单例类必须给所有其他对象提供这一实例。 明确定义后,看一下代码: 饿汉式 public class SingletonEH { /** *是否 Lazy 初始化:否 *是否多线程安全:是 *实现难度:易 *描述:这种方式比较常用,但容易产生垃圾对象。 *优点:没有加锁,执行效率会提高。 *缺点:类加载时就初始化,浪费内存。 *它基于 classloder 机制避免了多线程的同步问题, * 不过,instance 在类装载时就实例化,虽然导致类装载的原因有很多种, * 在单例模式中大多数都是调用 getInstance 方法, * 但是也不能确定有其他的方式(或者其他的静态方法)导致类装载, * 这时候初始化 instance 显然没有达到 lazy loading 的效果。 */ private static SingletonEH instance = new SingletonEH(); private SingletonEH (){} public static SingletonEH getInstance() { System.out.println("instance:"+instance); System.out.println("加载饿汉式...."); return instance; } } 饿汉就是类一旦加载,就把单例初始化完成,保证getInstance的时候,单例是已经存在的了。 懒汉式 public class SingletonLH { /** *是否 Lazy 初始化:是 *是否多线程安全:否 *实现难度:易 *描述:这种方式是最基本的实现方式,这种实现最大的问题就是不支持多线程。因为没有加锁 synchronized,所以严格意义上它并不算单例模式。 *这种方式 lazy loading 很明显,不要求线程安全,在多线程不能正常工作。 */ private static SingletonLH instance; private SingletonLH (){} public static SingletonLH getInstance() { if (instance == null) { instance = new SingletonLH(); } return instance; } } 而懒汉比较懒,只有当调用getInstance的时候,才回去初始化这个单例。 1、线程安全: 饿汉式天生就是线程安全的,可以直接用于多线程而不会出现问题, 懒汉式本身是非线程安全的,为了实现线程安全有几种写法。 例: public class SingletonLHsyn { /** *是否 Lazy 初始化:是 *是否多线程安全:是 *实现难度:易 *描述:这种方式具备很好的 lazy loading,能够在多线程中很好的工作,但是,效率很低,99% 情况下不需要同步。 *优点:第一次调用才初始化,避免内存浪费。 *缺点:必须加锁 synchronized 才能保证单例,但加锁会影响效率。 *getInstance() 的性能对应用程序不是很关键(该方法使用不太频繁)。 */ private static SingletonLHsyn instance; private SingletonLHsyn (){} public static synchronized SingletonLHsyn getInstance() { if (instance == null) { instance = new SingletonLHsyn(); } return instance; } } 2、资源加载和性能: 饿汉式在类创建的同时就实例化一个静态对象出来,不管之后会不会使用这个单例,都会占据一定的内存,但是相应的,在第一次调用时速度也会更快,因为其资源已经初始化完成。 而懒汉式顾名思义,会延迟加载,在第一次使用该单例的时候才会实例化对象出来,第一次调用时要做初始化,如果要做的工作比较多,性能上会有些延迟,之后就和饿汉式一样了。 意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。 主要解决:一个全局使用的类频繁地创建与销毁。 何时使用:当您想控制实例数目,节省系统资源的时候。 如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。 关键代码:构造函数是私有的。 应用实例: 1、一个党只能有一个主席。 2、Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。 3、一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。 优点: 1、在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。 2、避免对资源的多重占用(比如写文件操作)。 缺点:没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。 使用场景: 1、要求生产唯一序列号。 2、WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。 3、创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。 注意事项:getInstance() 方法中需要使用同步锁 synchronized (Singleton.class) 防止多线程同时进入造成instance 被多次实例化。 框架是一系列已经完成的代码的集合,用于解决特定的问题. 框架表现为某些.jar包文件,在开发时,需要在开发环境中倒入这些.jar文件,然后按照框架的约定的语法和工作流程来编程. 每种框架都是为了解决某个特定的问题而存在的. 当在项目中需要某个对象时,不必再使用new关键字创建对象,而是通过Spring容器获取对象, 1.创建Maven Project,在弹出的对话框中勾选Create a simple ,,,,然后再下一个界面中填写GroupId,Artifact Id,并将Packageing选为war即可. 2.通过Eclipse生成web.xml文件 3.添加Spring依赖:打开网页Maven.tedu.cn(如果连接的不是公司的网络,换成Maven.aliyun.com),搜索spring-webmvc结果中找到Group为org.springframework,且Artifact为spring-webmvc的项,并选择版本,然后将配置代码粘贴到项目的pom.xml中(事先在pom.xml中自行添加
4.将applicationContext.xml,复制并粘贴到项目中的src\main\resources文件夹中 5.在applicationContext.xml中添加配置:
6.编写代码,获取对象,测试运行: public static void main(String[ ]args){ //确定配置文件的文件名 String filename=”applicationContext.xml”; //加载配置文件,获取Spring容器 Application ac=new ClassPathApplication(fileName); //从Spring容器中获取对象 //getBean( )的方法的参数是配置文件中的bean id Date date=(Date)av.getBean(“date”); //测试 system.out.println(date); } 在ApplicationContext接口中并没有声明close( )方法. 而AbstractApplicationContext抽象类中是有声明这个方法的,所以将对象声明为抽象类的类型即可调用close( )方法. 即: AbstractApplicationContext ac=new ClassPathXmlApplicationContext(fileName); 在配置spring时,为 singleton(单例的默认值) prototype(非单例的). 一般情况下使用spring配置的都会是单例的!代码如下: 饿汉式与懒汉式的区别,只是在第一次调用的时候有区别,以后就没有区别了: 用哪一种好取决于对类的需求,如果这个类一定能用得上,就用饿汉式,如果这个类可能被用上,就用懒汉式. 在spring中. 在spring配置中,为 Resource leak表示内存泄漏对象包含什么?
js中常用的对象有:
1.String对象

2.number对象

正则表达式


边界匹配;
复习
--Array
Math对象的常用方法:
--在函数中,可以使用arguments数组对象访问参数列表
全局函数
外部对象
外部对象包括BOM和DOM



js相关的BOM操作
1.window的常用方法

js


window常用对象
1.location对象
2.screen对象
3.history对象
4.navigator:
BOM对象
BOM的属性的书写方法
window.location
window.onload事件.
js相关的DOM
总结:
--读写节点的属性

查询节点:
1.根据元素id查询节点
2.根据层次查询节点:
3.根据标签名查询节点:
鼠标悬停事件
Event对象


使用event对象:
事件的绑定
event对象总结
1.如何获取event对象
Jquery对象
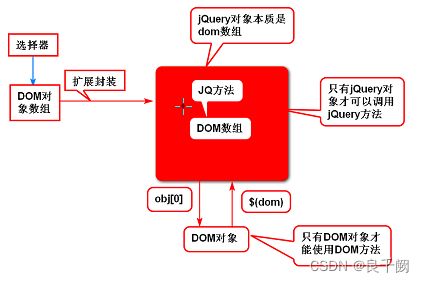
jQuery选择器
1.基本选择器(标签,类,id)
2.层次选择器
3.过滤器
4.表单选择器
JQuery操作dom节点:
jQuery中创建
添加到dom树上
--删除节点
jQuery样式操作
1.函数式编程,jQuery对象
2.修改的方法一般返回值都为jQuery对象
3.查询节点对象返回值都是jQuery对象
4.读取节点的值,一般都返回String类型
5.万能的验证方式
节点之间的关系导航
使用jQuery实现事件的绑定
语法

数据库
数据库原理:
1.文件存储:
2.DB和DBMS
关系型数据库简介
市场上主流的数据库产品:
表的概念:
Oracle数据库概述
DB2数据库概述
Sybase数据库概述
SQL数据库概述
MySQL数据库概述
结构化查询语言:
SQL分为:
数据定义语言(DDL)
数据操作语言(DML)
TCL(事务控制语言)
DQL(数据查询语言)
DCL(数据控制 语言)
Oracle数据库的按装和访问
更改密码


表的意义
SQL(structured query language)
别名用法:
表格操作










Desc

例子



对已经建好的表进行修改




例子



update语句
Delete语句:
char 和varchar2
char和varchar2的存储编码
long和clob了类型
字符串函数


LENGTH:
UPPER、LOWER和INITCAP
TRIM、LTRIM、RTRIM
substr

instr


Oracle数值操作
1.数值类型
number的变种数据类型:
数值函数
Oracle日期操作
date类型
timestamp

跳出时间



add_months
months_between
next_day

least,greatest
extract
空值操作
null的含义
显示插入和隐式插入
null条件查询
空值函数:
SQL(基础查询):
基础查询语句
使用别名:
where子句
select 子句
使用and,or关键字
使用like条件(模糊查询)
使用in和not in
between…and…
is null和is not null
any 和all条件:
查询条件中使用表达式和函数
使用distinct过滤重复:
排序
使用order by子句
asc和desc
多个列排序
聚合函数:
什么是聚合函数:
max和min
count
子句
1.having子句
查询语句的执行顺序
SQL(关联查询):
关联基础,关联的概念
关联查询:

笛卡尔积:




全连接(full outer join)
using子句:
on子句.
交叉连接:cross join(了解)
练习:



SQL高级查询
子查询:




搜索结果分页:limit子句
关联查询:
权限管理
视图
什么是视图:
视图的使用方式和表一样的
视图的分类:
视图的字段
视图的数据污染:
视图的作用
删除视图:
创建复杂视图
序列
什么是序列
索引:
索引概述:

创建索引:
修改和删除索引
约束
4.唯一性约束:
主键约束
外键约束:
检查约束
事务:
什么是事务?
事务有四个性质
JDBC
1.JDBC是什么?

jdbc访问数据库的工作过程
Connection接口:


Statement接口:
处理SQL执行结果:

从类路径中加载属性文件
连接池技术:
Apache DBCP连接池:

PrepareStatement(预编译)
Servlet
静态资源( )
什么是静态资源请求?
Servlet接口的抽象方法
1.void init(ServletConfig config)
2.ServletConfig getServletConfig( )
3.String getServlet
4.void service(ServletRequest request,ServletResponse response)
5.void destroy( )
什么是web服务器
CGI(Common Getway Interface)
单机程序
网路程序
网络程序--cs架构

组件规范:

如何写一个Servlet呢?
Servlet的运行过程:

常见问题的解决方式:
开发Servlet
一、开发Servlet
二.部署(拷贝)
三.访问
四.Servlet的特显
专业术语:处理http协议
什么是HTTP协议?
http通信步骤:
数据包的结构
对开发者的要求:
Servlet如何处理表单
两种请求方式:
Servlet输出中文,要注意什么
Servlet的生命周期
一.什么是Servlet的生命周期
二.生命周期分成几个阶段


3.调用(就绪)

4.销毁
三.生命周期相关的几个接口与类( )
1.Servlet接口
2.GenericServlet抽象类
3.HTTPServlet抽象类
容器如何找到service( )方法
Servlet接口:
Servlet涉及到的抽象类

调错:
jsp(java server page)
1.什么是jsp?
2.如何写jsp?
各个属性含义

jsp是如何运行的?
1.容器要将jsp 转换成Servlet
2.容器调用该Servlet
重定向
什么是重定向?

Nginx Webserver服务器
apache WebServer服务器
jap开发要点
一.转发
二.如何转发

重定向和转发的区别:
路径问题:
jsp页面中的注释:
jsp表达式
一.状态管理
1.什么是状态管理?
2.如何进行状态管理
cookie的工作原理

1.如何添加cookie
2.如何读取cookie?
3.cookie的编码问题
4.cookie生存的时间问题
5.cookie的路径问题

6.cookie的限制
二.session会话
1.什么是session?
2.工作原理
3.如何获得session对象

4.绑定数据相关的几个方法
5.如何统计每个客户访问的次数?


6.session超时
7.删除session
三.session相关案例
1.登录
四.session验证
1.session验证
2.使用session实现验证的步骤如下:
3.session优缺点
4.禁用cookie的后果
5.什么是URL重写
6.如何实现URL重写
五.验证码
1.验证码的作用
2.验证码的绘制

Servlet:过滤器
过滤器
1.什么是过滤器?
2.如何写 过滤器?

3.过滤器的优先级
二.监听器
注:主要有两大类事件:


如何写监听器?

Servlet的线程安全问题

3.指令
5.注释:
6.jsp是如何执行的?
7.jsp标签是什么?
java反射

java注解
ajax
ajax
1.ajax是什么?

2.ajax对象如何获得
3.ajax对象的几个重要的属性
4.编程步骤
spring
1.spring概述
1.什么是Spring(概述)
2.Spring框架的优点
3.Spring的体系结构

2.Spring核心容器
3.Spring入门程序
4.依赖注入
5.Bean的配置
的配置,管理都通过该属性来完成.
单例模式懒汉式和饿汉式区别
框架:
1.什么是框架
2.为什么要用框架
Spring框架:
作用:
创建过程:
配置依赖
close( )方法的来历
在spring配置中的节点
封装这个概念