- Hive详解
一:Hive的历史价值1,Hive是Hadoop上的KillerApplication,Hive是Hadoop上的数据仓库,Hive同时兼具有数据仓库中的存储引擎和查询引擎的作用;而SparkSQL是一个更加出色和高级的查询引擎,所以在现在企业级应用中SparkSQL+Hive成为了业界使用大数据最为高效和流行的趋势。2,Hive是Facebook的推出,主要是为了让不动Java代码编程的人员也能
- zookeeper和hadoop
zookeeper操作连接zkCli.sh-server服务名称查看客户端指令helpZooKeeper-serverhost:portcmdargs statpath[watch] setpathdata[version] lspath[watch] delquota[-n|-b]path ls2path[watch] setAclpathacl setquot
- Hadoop 之 ZooKeeper (一)
devalone
HadoopHadoopZooKeeperHbaseChubbyznode
Hadoop之ZooKeeper本文介绍使用Hadoop的分布式协调服务构建通用的分布式应用——ZooKeeper。ZooKeeper是Hadoop分布式协调服务。写分布式应用是比较难的,主要是因为部分失败(partialfailure).当一条消息通过网络在两个节点间发送时,如果发生网络错误,发送者无法知道接受者是否接收到了这条消息。接收者可能在发生网络错误之前已经收到了这条消息,也可能没有收到
- ZooKeeper在Hadoop中的协同应用:从NameNode选主到分布式锁实现
码字的字节
hadoop布道师分布式zookeeperhadoop分布式锁
Hadoop与ZooKeeper概述Hadoop与ZooKeeper在大数据生态系统中的核心位置和交互关系Hadoop的架构与核心组件作为大数据处理的基石,Hadoop生态系统由多个关键组件构成。其核心架构主要包含HDFS(HadoopDistributedFileSystem)和YARN(YetAnotherResourceNegotiator)两大模块。HDFS采用主从架构设计,由NameNo
- 大数据开发系列(六)----Hive3.0.0安装配置以及Mysql5.7安装配置
Xiaoyeforever
hivemysqlhivehadoop数据库
一、Hive3.0.0安装配置:(Hive3.1.2有BUG)hadoop3.1.2Hive各个版本下载地址:http://archive.apache.org/dist/hive/,这里我们下载hive3.0.01、解压:tar-xzvfapache-hive-3.0.0-bin.tar.gz-C/usr/lib/JDK_2021cd/usr/lib/JDK_20212.改名称.将解压以后的文件
- 大数据编程基础
芝麻开门-新的起点
大数据大数据
3.1Java基础(重点)内容讲解Java是大数据领域最重要的编程语言之一。Hadoop、HBase、Elasticsearch等众多核心框架都是用Java开发的。因此,扎实的Java基础对于深入理解这些框架的底层原理和进行二次开发至关重要。为什么Java在大数据领域如此重要?生态系统:Hadoop生态系统原生就是Java构建的,使用Java进行开发可以无缝集成。跨平台性:Java的“一次编译,到
- HDFS常用命令
BenChuat
大数据学习hdfshadoop大数据
常用命令说明:-put和-get:上传和下载文件,是HDFS和本地文件系统交互的关键命令。-rm和-mkdir:删除和创建文件/目录,-rm支持递归删除。-ls和-cat:文件查看操作中最常用的命令,分别用于列出文件和查看内容。权限管理:通过-chmod、-chown和-chgrp命令对HDFS文件的权限、所有者和所属组进行管理。检查文件状态:通过-stat和-checksum命令,可以查看文件的
- 深入解析HBase如何保证强一致性:WAL日志与MVCC机制
码字的字节
hadoop布道师hadoopHBaseWALMVCC
HBase强一致性的重要性在分布式数据库系统中,强一致性是确保数据可靠性和系统可信度的核心支柱。作为Hadoop生态系统中关键的列式存储数据库,HBase需要处理金融交易、实时风控等高敏感场景下的海量数据操作,这使得强一致性成为其设计架构中不可妥协的基础特性。分布式环境下的数据一致性挑战在典型的HBase部署环境中,数据被分散存储在多个RegionServer节点上,同时面临以下核心挑战:1.跨节
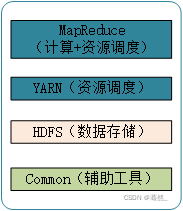
- Hadoop中MapReduce和Yarn相关内容详解
接上一章写的HDFS说,Hadoop是一个适合海量数据的分布式存储和分布式计算的一个平台,上一章介绍了分布式存储,这一章介绍一下分布式计算——MapReduce。一、MapReduce设计理念map——>映射Reduce——>归纳mapreduce是一种必须构建在hadoop之上的大数据离线计算框架。因为mapreduce是给予磁盘IO来计算存储文件的,所以它具有一定的延时性,因此一般用来处理离线
- 阿里云MaxCompute SQL与Apache Hive区别面面观
大模型大数据攻城狮
阿里云odpssql物化maxcomputeudf开发sql语法
目录1.引爆开场:MaxCompute和Hive,谁才是大数据SQL的王者?2.架构大比拼:从Hadoop到Serverless的进化之路Hive的架构:老派但经典MaxCompute的架构:云原生新贵3.SQL语法的微妙差异:90%相似,10%决定胜负建表语句分区与分桶函数与UDF4.执行引擎的较量:MapReducevs飞天引擎Hive的MapReduce执行流程MaxCompute的飞天引擎
- 一文说清楚Hive
Hive作为ApacheHadoop生态的核心数据仓库工具,其设计初衷是为熟悉SQL的用户提供大规模数据离线处理能力。以下从底层计算框架、优点、场景、注意事项及实践案例五个维度展开说明。一、Hive底层分布式计算框架对比Hive本身不直接执行计算,而是将HQL转换为底层计算引擎的任务。目前支持的主流引擎及其特点如下:计算引擎核心原理优点缺点适用场景MapReduce基于“Map→Shuffle→R
- HBase 简介
HBase简介什么是HBaseApacheHBase是Hadoop数据库,一个分布式的、可伸缩的大数据存储。当您需要对大数据进行随机的、实时的读/写访问时,请使用ApacheHBase。这个项目的目标是在商品硬件的集群上托管非常大的表——数十亿行百万列的列。ApacheHBase是一个开源的、分布式的、版本化的、非关系的数据库,它模仿了Google的Bigtable:一个结构化数据的分布式存储系统
- AI人工智能的SGLang、vllm和YaRN大语言模型服务框架引擎的对比
没刮胡子
Linux服务器技术软件开发技术实战专栏人工智能AI人工智能语言模型自然语言处理
简介SGLang、vLLM和YaRN在大语言模型中的应用场景和功能特点有所不同,具体如下:SGLang定位:是一种专为大型语言模型(LLMs)和视觉语言模型(VLMs)设计的高效服务框架。核心特点:通过优化前端和后端语言的协同设计,提升与模型的交互速度和可控性。前端语言灵活,原生支持Python语法,提供多种原语和控制机制;后端运行时使用RadixAttention技术实现前缀缓存和跳跃式解码,支
- sqoop的几个注意参数
yayooo
vimsqoop_export.shsqoop导出脚本:#!/bin/bashdb_name=gmallexport_data(){/opt/module/sqoop/bin/sqoopexport\--connect"jdbc:mysql://hadoop102:3306/${db_name}?useUnicode=true&characterEncoding=utf-8"\--username
- 大数据领域Hadoop集群搭建的详细步骤
AI天才研究院
ChatGPT实战ChatGPTAI大模型应用入门实战与进阶大数据hadoop分布式ai
大数据领域Hadoop集群搭建的详细步骤关键词:Hadoop集群、HDFS、YARN、大数据平台、分布式系统、集群配置、故障排查摘要:Hadoop作为大数据领域的基石框架,其集群搭建是数据工程师和运维人员的核心技能。本文从Hadoop核心架构出发,结合生产环境实践,详细讲解从环境准备、配置文件调优到集群启动验证的全流程,并涵盖常见问题排查与最佳实践。无论你是初学者还是需要优化现有集群的工程师,本文
- 2025年7月23日 AI 今日头条
tanak
AI日报信息差人工智能microsoft
阿里通义千问发布Qwen3-Coder,编程能力超越GPT-4.1阿里通义千问团队推出Qwen3-Coder-480B-A35B-Instruct,采用4800亿参数混合专家模型,支持256Ktoken上下文,并通过YaRN技术扩展至1Mtoken。在LiveBench、BigCodeBench等编程评测中,该模型表现优异,超越GPT-4.1,尤其在复杂代码调试和多语言支持上展现出强大能力。阿里计
- npm全局安装后,依然不是内部或外部命令,也不是可运行的程序或批处理文件
安心不心安
前端学习笔记npm前端node.js
虽然通过npminstall-gyarn安装了Yarn,但系统无法识别yarn命令。这通常是因为npm的全局安装目录没有添加到系统的PATH环境变量中C:\Users\Administrator>npminstall-gyarnadded1packagein518msC:\Users\Administrator>yarn'yarn'不是内部或外部命令,也不是可运行的程序或批处理文件。解决方法1.找
- Zookeeper简单入门
灬哆啦A梦不吃鱼
zookeeper简介ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)的管理员,同时ApacheHBase、ApacheSolr、LinkedInSensei等众多项目中都采用了ZooKeeper。ZooKeeper曾是Hadoop的正式子项目,后发展成为Apache顶级项目,与Hadoop密切相关但却没有任何依赖。它是一个针对大型应用
- React Native 双向无限滚动组件教程
ReactNative双向无限滚动组件教程项目介绍react-native-bidirectional-infinite-scroll是一个基于ReactNative的FlatList组件扩展库,旨在实现双向无限滚动功能,并保持平滑的滚动体验。该组件允许用户在列表的顶部和底部进行无限滚动加载,适用于需要大量数据展示的应用场景。项目快速启动安装首先,通过npm或yarn安装react-native-
- 解锁Hive:高效数据查找的秘密武器
YangRyeon
hivehadoop数据仓库
Hive是什么?Hive是基于Hadoop的一个数据仓库工具,它能够进行数据提取、转化和加载操作,为存储、查询和分析Hadoop中的大规模数据提供了有效的机制。Hive能将结构化的数据文件映射为一张数据库表,让用户可以通过熟悉的SQL查询功能来处理数据。其内部机制是将SQL语句巧妙地转变成MapReduce任务来执行,大大降低了开发的难度和复杂性。例如,在面对海量的用户行为日志数据时,Hive就能
- Hive/Spark小文件解决方案(企业级实战)–参数和SQL优化
陆水A
大数据hivehadoopsparkpython
重点是后面的参数优化一、小文件的定义在Hadoop的上下文中,小文件的定义是相对于Hadoop分布式文件系统(HDFS)的块(Block)大小而言的。HDFS是Hadoop生态系统中的核心组件之一,它设计用于存储和处理大规模数据集。在HDFS中,数据被分割成多个块,每个块的大小是固定的,这个大小在Hadoop的不同版本和配置中可能有所不同,但常见的默认块大小包括128MB、256MB等。基于这个背
- C++与Hive、Spark、libhdfs、ACID交互技巧
KENYCHEN奉孝
C++开发语言springC++hivespark
C++与Hive交互的实例以下是C++与Hive交互的实例代码片段,涵盖连接、查询、数据操作等常见场景。假设使用libhdfs或thrift接口实现,部分示例需要结合Hive环境配置。基础连接与查询示例1:通过Thrift连接HiveServer2#include#include#includeusingnamespaceapache::thrift;usingnamespaceapache::h
- 一个前端小白的学习路径规划1(叠甲:还有很多不懂的地方,不全面的后面慢慢补充)
#开发工具/环境配置#(这个部分网上很多安装教程)代码编辑器:VSCode配置与插件推荐✔(一开始把vscode搞好就行版本控制:Git基础命令与团队协作流程(进程中...包管理工具:npm/yarn/pnpm的使用与依赖管理(进程中...#HTML#第一步进入html的学习,HTML不难,培养“动手惯性”!1、HTML是什么?(明确学习目标与基础认知)2、HTML的骨架--文档基本结构3、学习H
- vue3 + vite || Vue3 + Webpack创建项目
qq_41521625
webpack前端
1.vue3+vite搭建项目方法(需要提前装node,js)1.使用官方create-vite工具(推荐)1.使用npm-----------------------------npmcreatevue@latest2.使用pnpm-----------------------------pnpmcreatevue@latest3.使用yarn--------------------------
- 快速将前端得依赖打为tar包(yarn.lock版本)并且推送至nexus私有依赖仓库(笔记)
职场马喽
前端
第一步创建js文件文件名为downloadNpmPackage.jsprocess.env.NODE_TLS_REJECT_UNAUTHORIZED="0";constfs=require("fs");constpath=require("path");constrequest=require("request");//设置依赖目录constdownUrl="./npm-dependencies-
- NPM/Yarn完全指南:前端开发的“基石“与“加速器“
软件老王子
前端实战npm前端node.js
开篇:当你第一次运行npminstall时..."这node_modules文件夹怎么比我的项目代码还大100倍?!"——每个前端新手第一次看到node_modules时的反应都出奇地一致。别担心,今天我要带你彻底搞懂这个让项目"膨胀"的"罪魁祸首",以及如何用NPM/Yarn这两个神器优雅地管理它!一、包管理器:前端世界的"快递小哥"1.1为什么需要包管理器?想象你要做一道菜:没有包管理器:自己
- Yarn 3.x版本容器内存控制功能失效排查
极伪
hadoopyarn内存控制
问题背景Yarn集群中一部分节点的内存被打爆,排查发现作业使用内存超出了NodeManager的最大内存限制找出故障时间点运行的作业,发现作业内存设置不合理,用户只设置了mapreduce.map.java.opts=-Xmx40240m;mapreduce.reduce.java.opts=-Xmx80240m;而没有设置mapreduce.map.memory.mb(默认为1536)mapre
- 深入解析Hadoop资源隔离机制:Cgroups、容器限制与OOM Killer防御策略
码字的字节
hadoop布道师Hadoop资源隔离机制Cgroups容器限制OOMKiller
Hadoop资源隔离机制概述在分布式计算环境中,资源隔离是保障多任务并行执行稳定性的关键技术。Hadoop作为主流的大数据处理框架,其资源管理能力直接影响集群的吞吐量和任务成功率。随着YARN架构的引入,Hadoop实现了计算资源与存储资源的解耦,而资源隔离机制则成为YARN节点管理器(NodeManager)最核心的功能模块之一。资源隔离的必要性在共享集群环境中,典型问题表现为"资源侵占"现象:
- Mocha 使用
比特森林探险记
Js&NodeJsjavascript
Mocha是一个功能丰富、灵活的JavaScript测试框架,主要用于在Node.js和浏览器环境中运行测试用例。它以简单性、异步支持强大和可扩展性著称,常与断言库(如Chai、Node.js内置的assert)结合使用。以下是Mocha的核心用法和关键概念详解:1.安装使用npm或yarn安装Mocha:npminstall--save-devmocha#或yarnadd--devmocha2.
- Spark大数据处理讲课笔记4.8 Spark SQL典型案例
酒城译痴无心剑
#Spark基础学习笔记(1)spark笔记sql
文章目录零、本讲学习目标一、使用SparkSQL实现词频统计(一)提出任务(二)实现任务1、准备数据文件2、创建Maven项目3、修改源程序目录4、添加依赖和设置源程序目录5、创建日志属性文件6、创建HDFS配置文件7、创建词频统计单例对象8、启动程序,查看结果9、词频统计数据转化流程图二、使用SparkSQL计算总分与平均分(一)提出任务(二)完成任务1、准备数据文件2、新建Maven项目3、修
- 对股票分析时要注意哪些主要因素?
会飞的奇葩猪
股票 分析 云掌股吧
众所周知,对散户投资者来说,股票技术分析是应战股市的核心武器,想学好股票的技术分析一定要知道哪些是重点学习的,其实非常简单,我们只要记住三个要素:成交量、价格趋势、振荡指标。
一、成交量
大盘的成交量状态。成交量大说明市场的获利机会较多,成交量小说明市场的获利机会较少。当沪市的成交量超过150亿时是强市市场状态,运用技术找综合买点较准;
- 【Scala十八】视图界定与上下文界定
bit1129
scala
Context Bound,上下文界定,是Scala为隐式参数引入的一种语法糖,使得隐式转换的编码更加简洁。
隐式参数
首先引入一个泛型函数max,用于取a和b的最大值
def max[T](a: T, b: T) = {
if (a > b) a else b
}
因为T是未知类型,只有运行时才会代入真正的类型,因此调用a >
- C语言的分支——Object-C程序设计阅读有感
darkblue086
applec框架cocoa
自从1972年贝尔实验室Dennis Ritchie开发了C语言,C语言已经有了很多版本和实现,从Borland到microsoft还是GNU、Apple都提供了不同时代的多种选择,我们知道C语言是基于Thompson开发的B语言的,Object-C是以SmallTalk-80为基础的。和C++不同的是,Object C并不是C的超集,因为有很多特性与C是不同的。
Object-C程序设计这本书
- 去除浏览器对表单值的记忆
周凡杨
html记忆autocompleteform浏览
&n
- java的树形通讯录
g21121
java
最近用到企业通讯录,虽然以前也开发过,但是用的是jsf,拼成的树形,及其笨重和难维护。后来就想到直接生成json格式字符串,页面上也好展现。
// 首先取出每个部门的联系人
for (int i = 0; i < depList.size(); i++) {
List<Contacts> list = getContactList(depList.get(i
- Nginx安装部署
510888780
nginxlinux
Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器。 Nginx 是由 Igor Sysoev 为俄罗斯访问量第二的 Rambler.ru 站点开发的,第一个公开版本0.1.0发布于2004年10月4日。其将源代码以类BSD许可证的形式发布,因它的稳定性、丰富的功能集、示例配置文件和低系统资源
- java servelet异步处理请求
墙头上一根草
java异步返回servlet
servlet3.0以后支持异步处理请求,具体是使用AsyncContext ,包装httpservletRequest以及httpservletResponse具有异步的功能,
final AsyncContext ac = request.startAsync(request, response);
ac.s
- 我的spring学习笔记8-Spring中Bean的实例化
aijuans
Spring 3
在Spring中要实例化一个Bean有几种方法:
1、最常用的(普通方法)
<bean id="myBean" class="www.6e6.org.MyBean" />
使用这样方法,按Spring就会使用Bean的默认构造方法,也就是把没有参数的构造方法来建立Bean实例。
(有构造方法的下个文细说)
2、还
- 为Mysql创建最优的索引
annan211
mysql索引
索引对于良好的性能非常关键,尤其是当数据规模越来越大的时候,索引的对性能的影响越发重要。
索引经常会被误解甚至忽略,而且经常被糟糕的设计。
索引优化应该是对查询性能优化最有效的手段了,索引能够轻易将查询性能提高几个数量级,最优的索引会比
较好的索引性能要好2个数量级。
1 索引的类型
(1) B-Tree
不出意外,这里提到的索引都是指 B-
- 日期函数
百合不是茶
oraclesql日期函数查询
ORACLE日期时间函数大全
TO_DATE格式(以时间:2007-11-02 13:45:25为例)
Year:
yy two digits 两位年 显示值:07
yyy three digits 三位年 显示值:007
- 线程优先级
bijian1013
javathread多线程java多线程
多线程运行时需要定义线程运行的先后顺序。
线程优先级是用数字表示,数字越大线程优先级越高,取值在1到10,默认优先级为5。
实例:
package com.bijian.study;
/**
* 因为在代码段当中把线程B的优先级设置高于线程A,所以运行结果先执行线程B的run()方法后再执行线程A的run()方法
* 但在实际中,JAVA的优先级不准,强烈不建议用此方法来控制执
- 适配器模式和代理模式的区别
bijian1013
java设计模式
一.简介 适配器模式:适配器模式(英语:adapter pattern)有时候也称包装样式或者包装。将一个类的接口转接成用户所期待的。一个适配使得因接口不兼容而不能在一起工作的类工作在一起,做法是将类别自己的接口包裹在一个已存在的类中。 &nbs
- 【持久化框架MyBatis3三】MyBatis3 SQL映射配置文件
bit1129
Mybatis3
SQL映射配置文件一方面类似于Hibernate的映射配置文件,通过定义实体与关系表的列之间的对应关系。另一方面使用<select>,<insert>,<delete>,<update>元素定义增删改查的SQL语句,
这些元素包含三方面内容
1. 要执行的SQL语句
2. SQL语句的入参,比如查询条件
3. SQL语句的返回结果
- oracle大数据表复制备份个人经验
bitcarter
oracle大表备份大表数据复制
前提:
数据库仓库A(就拿oracle11g为例)中有两个用户user1和user2,现在有user1中有表ldm_table1,且表ldm_table1有数据5千万以上,ldm_table1中的数据是从其他库B(数据源)中抽取过来的,前期业务理解不够或者需求有变,数据有变动需要重新从B中抽取数据到A库表ldm_table1中。
- HTTP加速器varnish安装小记
ronin47
http varnish 加速
上午共享的那个varnish安装手册,个人看了下,有点不知所云,好吧~看来还是先安装玩玩!
苦逼公司服务器没法连外网,不能用什么wget或yum命令直接下载安装,每每看到别人博客贴出的在线安装代码时,总有一股羡慕嫉妒“恨”冒了出来。。。好吧,既然没法上外网,那只能麻烦点通过下载源码来编译安装了!
Varnish 3.0.4下载地址: http://repo.varnish-cache.org/
- java-73-输入一个字符串,输出该字符串中对称的子字符串的最大长度
bylijinnan
java
public class LongestSymmtricalLength {
/*
* Q75题目:输入一个字符串,输出该字符串中对称的子字符串的最大长度。
* 比如输入字符串“google”,由于该字符串里最长的对称子字符串是“goog”,因此输出4。
*/
public static void main(String[] args) {
Str
- 学习编程的一点感想
Cb123456
编程感想Gis
写点感想,总结一些,也顺便激励一些自己.现在就是复习阶段,也做做项目.
本专业是GIS专业,当初觉得本专业太水,靠这个会活不下去的,所以就报了培训班。学习的时候,进入状态很慢,而且当初进去的时候,已经上到Java高级阶段了,所以.....,呵呵,之后有点感觉了,不过,还是不好好写代码,还眼高手低的,有
- [能源与安全]美国与中国
comsci
能源
现在有一个局面:地球上的石油只剩下N桶,这些油只够让中国和美国这两个国家中的一个顺利过渡到宇宙时代,但是如果这两个国家为争夺这些石油而发生战争,其结果是两个国家都无法平稳过渡到宇宙时代。。。。而且在战争中,剩下的石油也会被快速消耗在战争中,结果是两败俱伤。。。
在这个大
- SEMI-JOIN执行计划突然变成HASH JOIN了 的原因分析
cwqcwqmax9
oracle
甲说:
A B两个表总数据量都很大,在百万以上。
idx1 idx2字段表示是索引字段
A B 两表上都有
col1字段表示普通字段
select xxx from A
where A.idx1 between mmm and nnn
and exists (select 1 from B where B.idx2 =
- SpringMVC-ajax返回值乱码解决方案
dashuaifu
AjaxspringMVCresponse中文乱码
SpringMVC-ajax返回值乱码解决方案
一:(自己总结,测试过可行)
ajax返回如果含有中文汉字,则使用:(如下例:)
@RequestMapping(value="/xxx.do") public @ResponseBody void getPunishReasonB
- Linux系统中查看日志的常用命令
dcj3sjt126com
OS
因为在日常的工作中,出问题的时候查看日志是每个管理员的习惯,作为初学者,为了以后的需要,我今天将下面这些查看命令共享给各位
cat
tail -f
日 志 文 件 说 明
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信
- [应用结构]应用
dcj3sjt126com
PHPyii2
应用主体
应用主体是管理 Yii 应用系统整体结构和生命周期的对象。 每个Yii应用系统只能包含一个应用主体,应用主体在 入口脚本中创建并能通过表达式 \Yii::$app 全局范围内访问。
补充: 当我们说"一个应用",它可能是一个应用主体对象,也可能是一个应用系统,是根据上下文来决定[译:中文为避免歧义,Application翻译为应
- assertThat用法
eksliang
JUnitassertThat
junit4.0 assertThat用法
一般匹配符1、assertThat( testedNumber, allOf( greaterThan(8), lessThan(16) ) );
注释: allOf匹配符表明如果接下来的所有条件必须都成立测试才通过,相当于“与”(&&)
2、assertThat( testedNumber, anyOf( g
- android点滴2
gundumw100
应用服务器android网络应用OSHTC
如何让Drawable绕着中心旋转?
Animation a = new RotateAnimation(0.0f, 360.0f,
Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF,0.5f);
a.setRepeatCount(-1);
a.setDuration(1000);
如何控制Andro
- 超简洁的CSS下拉菜单
ini
htmlWeb工作html5css
效果体验:http://hovertree.com/texiao/css/3.htmHTML文件:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>简洁的HTML+CSS下拉菜单-HoverTree</title>
- kafka consumer防止数据丢失
kane_xie
kafkaoffset commit
kafka最初是被LinkedIn设计用来处理log的分布式消息系统,因此它的着眼点不在数据的安全性(log偶尔丢几条无所谓),换句话说kafka并不能完全保证数据不丢失。
尽管kafka官网声称能够保证at-least-once,但如果consumer进程数小于partition_num,这个结论不一定成立。
考虑这样一个case,partiton_num=2
- @Repository、@Service、@Controller 和 @Component
mhtbbx
DAOspringbeanprototype
@Repository、@Service、@Controller 和 @Component 将类标识为Bean
Spring 自 2.0 版本开始,陆续引入了一些注解用于简化 Spring 的开发。@Repository注解便属于最先引入的一批,它用于将数据访问层 (DAO 层 ) 的类标识为 Spring Bean。具体只需将该注解标注在 DAO类上即可。同时,为了让 Spring 能够扫描类
- java 多线程高并发读写控制 误区
qifeifei
java thread
先看一下下面的错误代码,对写加了synchronized控制,保证了写的安全,但是问题在哪里呢?
public class testTh7 {
private String data;
public String read(){
System.out.println(Thread.currentThread().getName() + "read data "
- mongodb replica set(副本集)设置步骤
tcrct
javamongodb
网上已经有一大堆的设置步骤的了,根据我遇到的问题,整理一下,如下:
首先先去下载一个mongodb最新版,目前最新版应该是2.6
cd /usr/local/bin
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.6.0.tgz
tar -zxvf mongodb-linux-x86_64-2.6.0.t
- rust学习笔记
wudixiaotie
学习笔记
1.rust里绑定变量是let,默认绑定了的变量是不可更改的,所以如果想让变量可变就要加上mut。
let x = 1; let mut y = 2;
2.match 相当于erlang中的case,但是case的每一项后都是分号,但是rust的match却是逗号。
3.match 的每一项最后都要加逗号,但是最后一项不加也不会报错,所有结尾加逗号的用法都是类似。
4.每个语句结尾都要加分