PaddleClas--部署并训练自定义数据集
https://github.com/PaddlePaddle/PaddleClas (尝鲜版)分类模型
PaddleClas
图像分类基础知识
训练集(train dataset):用来训练模型,使模型能够识别不同类型的特征;
验证集(val dataset):训练过程中的测试集,方便训练过程中查看模型训练程度;
预训练模型
使用在某个较大的数据集训练好的预训练模型,即被预置了参数的权重,可以帮助模型在新的数据集上更快收敛。尤其是对一些训练数据比较稀缺的任务,在神经网络参数十分庞大的情况下,仅仅依靠任务自身的训练数据可能无法训练充分,加载预训练模型的方法可以认为是让模型基于一个更好的初始状态进行学习,从而能够达到更好的性能。
迭代轮数(epoch)
模型训练迭代的总轮数,模型对训练集全部样本过一遍即为一个 epoch。当测试错误率和训练错误率相差较小时,可认为当前迭代轮数合适;当测试错误率先变小后变大时,则说明迭代轮数过大,需要减小迭代轮数,否则容易出现过拟合。
损失函数(Loss Function)
训练过程中,衡量模型输出(预测值)与真实值之间的差异
一、环境配置
环境配置 Python3.7 cuda10.2
git clone https://github.com/PaddlePaddle/PaddleClas.git -b release/2.3
pip install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple
二、数据准备
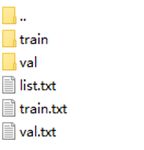
目录结构
/dataset
----data_siji
--------train
------------normal
------------abnormal
--------val
------------normal
------------abnormal
----list.txt
----train.txt
----val.txt
train.txt中存储结构—>文件名和类别编号用’\t’隔断 因为有些文件名字中有空格

list.txt中类别标号在前 类别名称在后

cd 到paddleclas项目下
运行 python preparedata.py

显示如下:

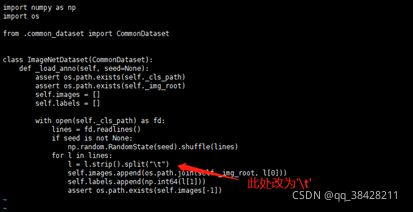
更改imagenet_dataset.py中的标签分隔方式
vi ppcls/data/dataloader/imagenet_dataset.py
三、训练
cp –r /ppcls/configs/quick_start/ResNet50_vd.yaml ../ paddleclas/
vi ResNet50_vd.yaml



device: 训练或者推理使用的设备(cpu、 cuda)
class_num: 训练的总类别数(abnormal和normal为2个类别)
epoch: 训练轮数
batch: 每轮训练一次性送入图片数
image_root: 数据集根目录
cls_label_path: 训练集的txt (测试集相应也要更改)
topk 1: 预测结果中概率最大的所在分类正确,则判定为正确
python tools/train.py -c ResNet50_vd.yaml -o Arch.pretrained=True
ResNet50_vd.yaml 自己的配置文件
Arch.pretrained 是否使用预训练模型
显示如下结果:
四、预测
python tools/infer.py -c ResNet50_vd.yaml -o Infer.infer_imgs=dataset/flowers102/jpg/image_00001.jpg -o Global.pretrained_model=output/ResNet50_vd/best_model
ResNet50_vd.yaml 自己的配置文件
Infer.infer_imgs 测试图片
Global.pretrained_model 训练好最佳的模型
preparedata.py 地址
preparedata.py-深度学习文档类资源-CSDN下载
封面如有侵权请联系作者删除