VisT理解与MindSpore框架下的实现
VisT 视频分类
具体可执行案例可下载Notebook。
1.VisT网络介绍
VisT(又称Swin3D) 是微软亚研院推出的基于 Shifted Window Attention 的视频动作识别模型。通过将原始图像特征按照 Window 进行切块,并利用 Shifted Window Attention 计算全局特征,在 Kinetics400,Kinetics600 和 Something-Something V2 数据集上获得了SOTA的性能。
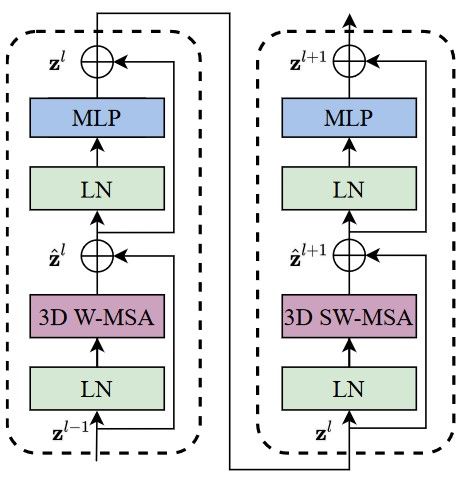
图1.两个连续的Video Swin Transformer模块
Swin3D 是 Swin2D 的3D扩展版,其主要结构是 3D Window Based Multi-head Attention (3D W-MSA)。每一个 3D W-MSA 模块配合 Layer_Norm,MLP 等结构可构成一个基础的 Swin Transformer Block(简称Block)。每两个具有不同 Shift 参数的 Block 按顺序连接就可以对全局特征进行感知。多个 Block 构成一个Stage,Swin3D 模型包含4个Stage。通过设置每个 Stage 中 Block 的数量,可得到不同体量的模型,比如Swin3D-Tiny,Swin3D-Small,Swin3D-Base 等。Swin3D 在前向传播时,视频帧数据先完成 Window 分块和升维,之后输入至四个级联的 Swin3D Stage 提取特征,之后对这些特征采用全局平均池化和 Softmax 获取动作分类 Logits 分数。

图2.Swin3D-Tiny的整体架构
了解 VisT 网络更多详细内容,参见论文 VisT论文。
msvideo环境准备
为能使用基于MindSpore框架下的VisT模型,可以使用以下命令安装msvideo环境:
git clone https://gitee.com/yanlq46462828/zjut_mindvideo.git
cd zjut_mindvideo
# Please first install mindspore according to instructions on the official website: https://www.mindspore.cn/install
pip install -r requirements.txt
pip install -e .数据集介绍
使用Kinetics400数据集。
数据集描述:kineics -400是视频领域中常用的基准数据集。详情请参考其官方网站Kinetics。下载方式请参考官方地址ActivityNet,并使用其提供的下载脚本下载数据集。
数据集大小:
Category |
Number of data |
Training set |
238797 |
Validation set |
19877 |
下载后的数据集目录如下:
|-kinetic-400
|-- train
| |-- ___qijXy2f0_000011_000021.mp4 // video file
| |-- ___dTOdxzXY_000022_000032.mp4 // video file
| ...
|-- test
| |-- __Zh0xijkrw_000042_000052.mp4 // video file
| |-- __zVSUyXzd8_000070_000080.mp4 // video file
|-- val
| |-- __wsytoYy3Q_000055_000065.mp4 // video file
| |-- __vzEs2wzdQ_000026_000036.mp4 // video file
| ...
|-- kinetics-400_train.csv // training dataset label file.
|-- kinetics-400_test.csv // testing dataset label file.
|-- kinetics-400_val.csv // validation dataset label file. 然后,使用msvideo.dataset.kinetics400接口来加载数据集,并进行相关的图像增强操作。
模型的训练过程
本节介绍使用Kinetics400数据集对不同体量的 swin3d 模型进行训练,以swin3d_t为例。
from mindspore import context, load_checkpoint, load_param_into_net
from mindspore import nn
from mindspore.common import set_seed
from mindspore.nn import Accuracy
from mindspore.nn import SoftmaxCrossEntropyWithLogits
from mindspore.profiler import Profiler
from mindspore.train import Model
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
set_seed(42)
profiler = False # use profiler or not
# 设置训练模式与训练设备
context.set_context(mode=context.PYNATIVE_MODE, device_target="GPU", device_id=0)
if profiler:
profiler = Profiler(output_path='./profiler_data')加载训练数据集
训练中使用msvideo.dataset.kinetics400接口来加载数据集。
创建训练数据集
from msvideo.data.kinetics400 import Kinetic400
dataset_train = Kinetic400(path="/usr/publicfile/kinetics-400",
split='train',
seq=32,
seq_mode='interval',
batch_size=1,
shuffle=False,
num_parallel_workers=1,
frame_interval=2,
num_clips=1
)
ckpt_save_dir = "./pretrained"数据处理
用VideoShortEdgeResize根据短边来进行Resize,再用VideoRandomCrop对Resize后的视频进行随机裁剪,通过VideoRescale对视频进行缩放,利用VideoReOrder对维度进行变换,再用VideoNormalize进行归一化处理。
from msvideo.data import transforms
dataset_train.transform = [transforms.VideoShortEdgeResize(size=256, interpolation='linear'),
transforms.VideoRandomCrop(size=(224, 224)),
transforms.VideoRescale(shift=0),
transforms.VideoReOrder(order=(3, 0, 1, 2)),
transforms.VideoNormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]加载数据集
dataset_train = dataset_train.run()
step_size = dataset_train.get_dataset_size()构建网络
Swin3D的Backbone包含了4个Stage,每个Stage包含了若干个Swin3D Block,每个Block的基础元素是一个WindowAttention3D结构。Swin3D共有4个版本,他们的Stages数量均为4,但是每个Stage的Block数量不同,Block越少,模型体量越小,速度越快,精度越低,分别命名为swin3d_tiny, swin3d_small, swin3d_base, swin3d_large。
Swin3D的特殊性在于Shifted Window Attention。偶数序号的Block使用Window Attention,奇数序号的Block使用Shifted Window Attention。对于Shited Window Attention,为了节省计算资源,需要对特征进行排列组合并加上Mask后再计算矩阵QKV乘积。具体细节可以参考原论文。Window相关的操作需要用到utils/windows.py中的一些接口。
在Backbone之前需要对原始视频图像进行patch分割和特征升维,该过程由PatchEmbed3D类完成,主要依赖于Conv3D算子来实现。
经由Backbone提取到的视频特征会通过一个全局平均池化层得到一组形状为(B,N, C)的特征,其中N=w×h×t,w,h为视频特征的空间尺寸,t为视频帧数。之后经过FC层和Softmax层,得到最终的分类结果。
Swin3D采用了多个Clip综合打分的方式来获得最终的测试精度成绩。模型在使用Softmax生成某个Clip的分类分数后,会计算多个Clip的分类分数均值作为最终分类分数。
Swin3D不同体量网络的划分如下:
Swin-T: embed_dim = 96, depths = {2, 2, 6, 2}
Swin-S: embed_dim = 96, depths = {2, 2, 18, 2}
Swin-B: embed_dim = 128, depths = {2, 2, 18, 2}
Swin-L: embed_dim = 192, depths = {2, 2, 18, 2}
构建Swin3D_Tiny网络
构建Swin3D网络主要用到Swin3D模块,以Swin3D_Tiny为例构造网络。
from msvideo.models.swin3d import Swin3D
import ml_collections as collections
def swin3d_t(num_classes: int = 400,
patch_size: int = (2, 4, 4),
window_size: int = (8, 7, 7),
embed_dim: int = 96,
depths: int = (2, 2, 6, 2),
num_heads: int = (3, 6, 12, 24),
representation_size: int = 768,
droppath_keep_prob: float = 0.9,
) -> nn.Cell:
"""
Video Swin Transformer Tiny (swin3d-T) model.
"""
config = collections.ConfigDict()
config.num_classes = num_classes
config.patch_size = patch_size
config.window_size = window_size
config.embed_dim = embed_dim
config.depths = depths
config.num_heads = num_heads
config.representation_size = representation_size
config.droppath_keep_prob = droppath_keep_prob
return Swin3D(**config)# from msvideo.models.swin3d import swin3d_t, swin3d_s, swin3d_b, swin3d_l # 直接导入已经搭建好的swin3d模型
# Create model.
model_name = "swin3d_t"
pretrained = False
pretrained_model_dir = "./pretrained/ms_swin_tiny_patch244_window877_kinetics400_1k.ckpt"
if model_name == "swin3d_t":
network = swin3d_t()
elif model_name == "swin3d_s":
network = swin3d_s()
elif model_name == "swin3d_b":
network = swin3d_b()
elif model_name == "swin3d_l":
network = swin3d_l()
if pretrained:
param_dict = load_checkpoint(pretrained_model_dir)
load_param_into_net(network, param_dict)设置学习率
from msvideo.schedule.lr_schedule import warmup_cosine_annealing_lr_v1
# Set learning rate scheduler.
lr = warmup_cosine_annealing_lr_v1(lr=0.001, steps_per_epoch=step_size,
warmup_epochs=2.5, max_epoch=30, t_max=30, eta_min=0)设置优化器
# Define optimizer.
network_opt = nn.AdamWeightDecay(network.trainable_params(), lr, beta1=0.9, beta2=0.999, weight_decay=0.02)设置损失函数
# Define loss function.
network_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")网络的预训练
# Set the checkpoint config for the network.
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100)
ckpt_callback = ModelCheckpoint(prefix=model_name, directory=ckpt_save_dir, config=ckpt_config)初始化模型
# Init the model.
model = Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc": Accuracy()})开始训练
# Begin to train.
from msvideo.utils.callbacks import LossMonitor
epoch_size = 30
print('[Start training `{}`]'.format(model_name))
print("=" * 80)
model.train(epoch_size,
dataset_train,
callbacks=[ckpt_callback, LossMonitor(lr.tolist())],
dataset_sink_mode=False)
print('[End of training `{}`]'.format(model_name))
if profiler:
profiler.analyse()训练效果
运行上述代码后,可以得到如下所示的训练过程:
[Start training `swin3d_t`]
================================================================================
Epoch:[ 0/ 30], step:[ 1/238796], loss:[5.683/5.683], time:15730.846 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 2/238796], loss:[5.940/5.811], time:1369.720 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 3/238796], loss:[6.123/5.915], time:624.709 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 4/238796], loss:[6.140/5.972], time:1307.396 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 5/238796], loss:[6.085/5.994], time:1389.049 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 6/238796], loss:[6.155/6.021], time:974.963 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 7/238796], loss:[5.948/6.011], time:736.551 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 8/238796], loss:[5.925/6.000], time:1064.217 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 9/238796], loss:[5.942/5.993], time:778.660 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 10/238796], loss:[5.913/5.985], time:858.309 ms, lr:0.00000
Epoch:[ 0/ 30], step:[ 11/238796], loss:[5.883/5.976], time:959.051 ms, lr:0.00000
......模型的验证流程
以swin3d_t为例,对上述训练好的模型进行验证,流程如下所示:
set_seed(42)
# 设置训练模式与训练设备
context.set_context(mode=context.GRAPH_MODE, device_target="GPU", device_id=0)
if profiler:
profiler = Profiler(output_path='./profiler_data')加载验证数据集
创建验证数据集
if profiler:
profiler = Profiler(output_path='./profiler_data')
# Data Pipeline.
dataset_eval = Kinetic400(path="/usr/publicfile/kinetics-400",
split='test',
seq=32,
seq_mode='interval',
batch_size=1,
shuffle=False,
num_parallel_workers=1,
frame_interval=2,
num_clips=1
)数据处理
用VideoShortEdgeResize根据短边来进行Resize,再用VideoThreeCrop对Resize后的视频实现论文中的裁剪增强,通过VideoRescale对视频进行缩放,利用VideoReOrder对维度进行变换,再用VideoNormalize进行归一化处理。
dataset_eval.transform = [transforms.VideoShortEdgeResize(size=224, interpolation='linear'),
transforms.VideoThreeCrop(size=(224, 224)),
transforms.VideoRescale(shift=0),
transforms.VideoReOrder(order=(3, 0, 1, 2)),
transforms.VideoNormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]加载数据集
dataset_eval = dataset_eval.run()开始验证
# Define loss function.
network_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
# Define eval metrics.
eval_metrics = {'Top_1_Accuracy': nn.Top1CategoricalAccuracy(),
'Top_5_Accuracy': nn.Top5CategoricalAccuracy()}
# Init the model.
model = Model(network, loss_fn=network_loss, metrics=eval_metrics)
# Begin to eval.
print('[Start eval `{}`]'.format(model_name))
result = model.eval(dataset_eval, dataset_sink_mode=True)
print(result)
if profiler:
profiler.analyse()验证效果
运行上述代码后,可以得到如下所示的验证结果:
[Start eval `swin3d_t`]
{'Top_1_Accuracy': 0.7727, 'Top_5_Accuracy': 0.9329}结果展示
在MindSpore框架下进行精度测试,得到如下精度:
模型 |
Swin3D-Tiny |
Swin3D-Small |
Swin3D-Base |
Top-1 Acc(Mindspore, %) |
77.27 |
78.89 |
81.16 |
Top-5 Acc(Mindspore, %) |
93.29 |
93.88 |
95.16 |