Java进阶2 - 易错知识点整理(待更新)
Java进阶2 - 易错知识点整理(待更新)
该章节是Java进阶1- 易错知识点整理的续篇;下一章节为Java进阶3- 易错知识点整理(待更新)
在前一章节中介绍了关于JavaEE、网络基础、Mysql、Spring/SpringMVC,SpringBoot/SpringCloud相关的面试题,而在该章节中主要记录关于ORM框架,中间件的常见面试题。
Note:
Java中间件有哪些?(标红表示“Java进阶1/2/3章节”有简单介绍) 参考Java中间件有哪些网关:
Nginx、Kong、Zuul
缓存:Redis、MemCached、OsCache、EhCache
搜索:ElasticSearch、Solr
熔断:Hystrix、resilience4j
负载均衡:DNS、F5、LVS、Nginx、OpenResty、HAproxy
注册中心:Eureka、Zookeeper、Redis、Etcd、Consul、Nacos
认证鉴权:JWT、SpringSecurity
消费队列:RabbitMQ、Kafka、RocketMQ、ActiveMQ、Redis
系统监控:Grafana、Prometheus、Influxdb、Telegraf、Lepus
文件系统:OSS、NFS、FastDFS、MogileFS
RPC框架:Dubbo、Motan、Thrift、grpc、OpenFeign
构建工具:Maven、Gradle
集成部署:Docker、Jenkins、Git、Maven
分布式配置:Disconf、Apollo、Spring Cloud Config、Diamond
压测:LoadRunner、JMeter、AB、webbench
数据库:MySQL、Redis、MongoDB、PostgreSQL、Memcache、HBase
网络:专用网络VPC、弹性公网IP、CDN
数据库中间件:DRDS、Mycat、360 Atlas、Cobar
分布式框架:Dubbo、Motan、Spring-Cloud
分布式任务:XXL-JOB、Elastic-Job、Saturn、Quartz
分布式追踪:Pinpoint、CAT、zipkin
分布式日志:elasticsearch、logstash、Kibana 、redis、kafka
版本发布:蓝绿部署、A/B测试、灰度发布/金丝雀发布- 中间件这么多,应该怎么学习?
- 从需求角度出发,对这些中间件的使用其实是更关注于非功能性的需求,即整个项目是否高可用,代码是否易维护,是否支持动态伸缩扩展等。
- 最好能结合具体的项目(如果没有大型项目经验,看架构书也可以,这里推荐Java游戏服务器架构实战),对各个类型中间件要解决的问题,以及各自的使用说明进行了解,这样既能让你在项目中实际用起来,也能让你下次在碰到同类型问题时能尝试选择该中间件(程序员到架构师的必由之路)。
- 我很喜欢某个大佬曾说过的一句话:
架构是根据需求变化的,应该根据项目的需求来选择合适的架构,架构也是随着项目变化而变化的,不能贪图一次性的完美。总之,架构应该以满足目前需求为先,并具有一定的前瞻性。
- 对于中间件的使用,需要根据项目所处的需求阶段以及项目的整体架构设计来进行选择。中间件虽然有很多但没有必要什么都学,选择适合项目架构的,互联网里目前用得较多,社区比较活跃的中间件进行学习即可。
文章目录
- Java进阶2 - 易错知识点整理(待更新)
-
- 6、Hibernate
- 7、MyBatis(jdbc缺点,mybatis映射配置,封装原理,常用标签)
- 8、Redis
- 9、MongoDB
- 10、RabbitMQ(AMQP组件,集群,消息可靠传输)
- 11、Nginx
- 12、Dubbo
- 13、Nacos
6、Hibernate
- 【问】为什么要使用 hibernate?
- 【问】什么是 ORM 框架?
- 【问】hibernate 中如何在控制台查看打印的 sql 语句?
- 【问】hibernate 有几种查询方式?
- 【问】hibernate 实体类可以被定义为 final 吗?
- 【问】在 hibernate 中使用 Integer 和 int 做映射有什么区别?
7、MyBatis(jdbc缺点,mybatis映射配置,封装原理,常用标签)
参考MyBatis面试题(2020最新版),【金三银四】Mybatis面试题(2021最新版),Mybatis-Spring源码分析(二) Mapper接口代理的生成,Mybatis-Spring源码分析(四) Mybatis的初始化,Mybatis-Spring源码分析(五) MapperMethod和MappedStatement解析,Mybatis源码解析: sql执行方法过程
-
【问】MyBatis是什么?(Mybatis是一个半自动ORM的持久化框架)
-
【问】ORM是什么(将关系型数据库中的数据与Java的Pojo对象进行映射,完成Pojo对象自动持久化到数据库中)
-
【问】为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?(Hibernate是全自动ORM框架,通过其提供的方法完成Pojo对象的增删改查操作;而Mybatis需要手动编写sql来完成CRUD,但Mybatis-plus是全自动ORM映射工具))
-
【问】Mybatis与Mybatis-plus的区别?(提供增删改查操作的方法,支持使用注解方式进行 SQL 语句的编写,提供了代码生成器,支持 Lambda 表达式和链式调用方式,提供了分页插件和性能分析插件),参考
ChatGPTNote:
-
MyBatis Plus和MyBatis的区别:
-
MyBatis Plus 提供了常用的增删改查操作的方法,可以减少重复编写 SQL 语句的工作量,提高开发效率。
-
MyBatis Plus 支持使用注解方式进行 SQL 语句的编写,不仅简化了 XML 配置文件的编写,还可以更加方便地进行动态 SQL 的操作。
-
MyBatis Plus 提供了代码生成器,可以根据数据库表结构自动生成 Entity、Mapper、Service、Controller 等各个层次的代码,从而大大提高了开发效率。
-
MyBatis Plus 支持 Lambda 表达式和链式调用方式,可以更加方便地进行条件构造和链式操作。
-
MyBatis Plus 提供了分页插件和性能分析插件,可以方便地进行分页操作和性能优化。
总之,MyBatis Plus 是 MyBatis 的增强版,提供了更加便利的功能和增强特性,可以帮助开发者更加高效地进行数据库操作。
-
-
MyBatis-Plus是一个全自动的ORM(对象关系映射)框架。它是在MyBatis的基础上进行扩展和增强的,提供了更加便捷的开发方式。MyBatis-Plus提供了许多自动化的功能,使得数据库操作更加简单和高效。它可以根据实体类自动生成数据库表,自动完成常见的增删改查操作,支持条件查询、分页查询、排序等常用功能,还提供了强大的查询构造器、Lambda查询、代码生成器等工具,极大地简化了开发人员的工作。
-
-
【问】JDBC 中preparedStatement和Statement区别(
preparedStatement变量替换在DBMS内执行,而Statement在DBMS外;preparedStatement只有在执行多条相似SQL时比Statement更具优势)-
PreparedStatement:数据库系统会对sql语句进行预编译处理(如果JDBC驱动支持的话),预处理语句将被预先编译好,这条预编译的sql查询语句能在将来的查询中重用,这样一来,在执行相似
sql时它比Statement对象生成的查询速度更快。String sql = "update account set money = money - ? where id = ?"; PreparedStatement prepareStatement = connection.prepareStatement(sql); preparedStatement.setInt(1, 100); preparedStatement.setInt(2, 1); ResultSet resultSet = prepareStatement.executeUpdate(); //在DBMS内完成变量拼接,可以避免sql注入 -
Statement:使用
Statement对象。在对数据库只执行一次性存取的时侯,用 Statement 对象进行处理。PreparedStatement对象的开销比Statement大,对于一次性操作并不会带来额外的好处。String sql = "update account set money = money - 100 where id = 1"; //在DBMS外完成变量拼接 Statement stmt = conn.getStatement(); stmt.executeQuery(sql);
-
-
【问】传统JDBC开发存在的问题(
jdbc需要自建线程池(DBCP,C3P0,Druid)来避免创建、释放连接带来的资源开销;jdbc创建的sql语句在where参数传值上存在硬编码问题,需要改动java代码不方便维护;遍历取出结果集中的值再装配对象),参考学习JDBC这一篇就够了-
频繁创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池解决这个问题。但是使用
jdbc需要自己实现连接池。 -
sql语句定义、参数设置、结果集处理存在硬编码。实际项目中sql语句变化的可能性较大,一旦发生变化,需要修改java代码,系统需要重新编译,重新发布。不好维护。使用preparedStatement向占位符传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。 -
需要遍历取出结果集中的值再装配对象,处理麻烦。
-
Druid连接池代码如下:jdbc在查询操作时- 先创建连接 -> 编写sql -> sql预编译 -> sql执行(在mysqld中执行命令步骤类似)
- 需要从
sql执行返回的结果集中遍历取出相应的字段,再装配到指定对象中
import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import com.alibaba.druid.pool.DruidDataSource; public class DruidTest { public static void main(String[] args) throws SQLException { DruidDataSource dataSource = new DruidDataSource(); dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/mytest"); dataSource.setUsername("root"); dataSource.setPassword("root"); Connection connection = dataSource.getConnection(); String sql = "select * from admin"; //Statement stmt = conn.getStatement(); //stmt.executeQuery(sql); PreparedStatement prepareStatement = connection.prepareStatement(sql); ResultSet resultSet = prepareStatement.executeQuery(); while (resultSet.next()) { Object id = resultSet.getObject(1); Object username = resultSet.getObject(2); Object password = resultSet.getObject(3); System.out.println(id + ":" + username + ":" + password); } resultSet.close(); sql = "update account set money = money - ? where id = ?"; preparedStatement = connection.prepareStatement(sql); // 扣钱, 扣ID为 1 的100块钱 preparedStatement.setInt(1, 100); preparedStatement.setInt(2, 1); preparedStatement.executeUpdate(); int rows = preparedStatement.executeUpdate(sql); if (rows > 0) { System.out.println("修改成功"); } else { System.out.println("修改失败"); } connection.close(); dataSource.close(); } }
-
-
【问】JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?(MyBatis在xml中配置数据库连接池;对sql语句和java代码进行解耦;
where配合-
1)数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。
解决:在
mybatis-config.xml中配置数据链接池(druid等),使用连接池管理数据库连接。 -
2)Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在
XXXXmapper.xml文件中与java代码分离(Mybatis通过namespace和动态代理,帮我们实现mapper接口的代理实现类)。 -
3)向sql语句传参数麻烦,因为sql语句的
where条件不一定,可能多也可能少,占位符需要和参数一一对应。解决: Mybatis自动将
java对象映射至sql语句(通过#{}传值,通过 -
4)对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将
sql执行结果映射至java对象(通过resultType参数对返回的数据库数据和java pojo对象进行自动映射,或者通过自定义的resultMap参数来对返回的数据库数据和javapojo对象进行手动映射)。
-
-
【问】Mybatis优缺点?(优点是减少了代码量且易维护,参考上一问;缺点是考察开发人员对sql的功底,参考下一问
-
【问】Hibernate 和 MyBatis 的区别(MyBatis 半自动化,需手动编写sql,但提供了对象关系映射标签,支持动态sql;Hibernate全自动化,无需手动编写sql,提供的HQL适合多种数据库,但对sql优化困难)
- 相同点:都是对
jdbc的封装,都是持久层的框架,都用于dao层的开发。 - 不同点:
- 映射关系
- MyBatis 是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单
- Hibernate 是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂
- SQL优化和移植性
- Hibernate 对SQL语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
- MyBatis 需要手动编写 SQL,支持动态 SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优化容易。
- 开发难易程度和学习成本
- Hibernate 是重量级框架,学习使用门槛高,适合于需求相对稳定,中小型的项目,比如:办公自动化系统
- MyBatis 是轻量级框架,学习使用门槛低,适合于需求变化频繁,大型的项目,比如:互联网电子商务系统
- 映射关系
- 相同点:都是对
-
【问】MyBatis框架适用场景(适合于需求变化频繁,大型的项目,参考上一问)
-
【问】MyBatis使用 SqlSession的编程步骤是什么样的?,参考mybatis 最常用的 SqlSessionFactory 和 SqlSession,你真的了解吗?
-
1)创建
SqlSessionFactory -
2)通过
SqlSessionFactory创建SqlSession -
3)通过
sqlsession执行数据库操作 -
4)调用
session.commit()提交事务 -
5)调用
session.close()关闭会话 -
参考代码(使用了
BatchExecutor,通过openSession.getMapper(EmployeeMapper.class);获得了对应接口的代理对象)://批量保存方法测试 @Test public void testBatch() throws IOException{ SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); //可以执行批量操作的sqlSession SqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH); //批量保存执行前时间 long start = System.currentTimeMillis(); try { EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class); //获得对应Mapper接口的代理对象 for (int i = 0; i < 1000; i++) { mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1")); } openSession.commit(); long end = System.currentTimeMillis(); //批量保存执行后的时间 System.out.println("执行时长" + (end - start)); //批量 预编译sql一次==》设置参数==》10000次==》执行1次 677 //非批量 (预编译=设置参数=执行 )==》10000次 1121 } finally { openSession.close(); } } //mapper.java public interface EmployeeMapper { //批量保存员工 Long addEmp(Employee employee); } //mapper.xml如下 <mapper namespace="com.jourwon.mapper.EmployeeMapper" <!--批量保存员工 --> <insert id="addEmp"> insert into employee(lastName,email,gender) values(#{lastName},#{email},#{gender}) </insert> </mapper>
-
-
【问】请说说MyBatis的工作原理?(
mapperMethod.execute()怎么调用jdbc的,看MappedMethod那一问),参考MyBatis基本工作原理介绍,Mybatis-Spring源码分析(二) Mapper接口代理的生成,Mybatis-Spring源码分析(五) MapperMethod和MappedStatement解析,Mybatis解析-执行器Executor详解Note:
-
具体过程如下:参考Mybatis源码解析(三)执行方法过程
1)读取
config.xml2)加载xml映射文件
3)创建
SqlSessionFactory4)创建
session会话对象5)通过
sqlSession.getMapper(UserMapper.class)获取指定Mapper接口的代理对象,该mapper代理对象中最初代的代理对象为MapperProxy,通过Mapper接口、实现了InvocationHandler接口的PlainMethodInvoker来创建;6)代理对象调用
Mapper接口的方法(比如addEmp())时,会调用最初代的代理对象MapperProxy的invoke(),由于PlainMethodInvoker对象中封装着MapperMethod对象,MapperMethod对象中封装着MappedStatement对象,PlainMethodInvoker通过mapperMethod.execute(sqlSession, args)来执行sql命令,而代理对象MapperProxy在执行invoke()时会执行mapperMethod.execute(),进而调用jdbc模块中的Statement或preStatement完成sql语句的执行。
-
上面中的流程就是MyBatis内部核心流程,每一步流程的详细说明如下文所述:
- 1)读取
MyBatis的配置文件:mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接信息。 - 2)加载映射文件:映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,需要在MyBatis配置文件mybatis-config.xml中加载。
mybatis-config.xml文件可以加载多个映射文件,每个文件对应数据库中的一张表。 - 3)构造会话工厂:通过MyBatis的环境配置信息构建会话工厂
SqlSessionFactory。 - 4)创建会话对象:由会话工厂创建
SqlSession对象,该对象中包含了执行SQL语句的所有方法。 - 5)
Executor执行器。MyBatis底层定义了一个Executor接口来操作数据库,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。 - 6)
MappedStatement对象。在Executor接口的执行方法中有一个MappedStatement类型的参数,该参数是对映射信息的封装,用于存储要映射的SQL语句的id、参数等信息(只是封装了参数和返回值等信息,并没有预编译,预编译由jdbc模块的prepareStatement完成)。 - 7)输入参数映射。输入参数类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输入参数映射过程类似于JDBC对
preparedStatement对象设置参数的过程。 - 8)输出结果映射。输出结果类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输出结果映射过程类似于JDBC对结果集的解析过程。
- 1)读取
-
-
【问】为什么需要预编译?(数据库驱动在DBMS执行sql之前会对sql进行预编译,即把sql语句参数化),参考预编译语句(Prepared Statements)介绍,以MySQL为例 ,JDBC 中preparedStatement和Statement区别
-
定义:SQL 预编译指的是数据库驱动(mysql服务端)在发送 SQL 语句和参数给 DBMS 之前 对 SQL 语句进行编译,这样 DBMS 执行 SQL 时,就不需要重新编译。
-
为什么需要预编译:
所谓预编译语句就是将这类语句中的值用占位符替代,可以视为将
sql语句模板化或者说参数化,一般称这类语句叫Prepared Statements或者Parameterized Statements
预编译语句的优势在于归纳为:一次编译、多次运行,省去了解析优化等过程;此外预编译语句能防止sql注入。
-
-
【问】Mybatis的Executor有什么作用?都有哪些Executor执行器?它们之间的区别是什么?(不缓存/缓存/批量缓存
Statement对象,区别在于是否重用预编译语句),参考预编译语句(Prepared Statements)介绍,以MySQL为例 ,JDBC 中preparedStatement和Statement区别,Mybatis解析-执行器Executor详解,SqlSession对象之ExecutorSqlSession执行增删改查都是委托给Executor完成的,Mybatis的Executor主要完成以下几项内容:-
1)处理缓存,包括一级缓存和二级缓存
-
2)获取数据库连接
-
3)创建
Statement或者PrepareStatement对象 -
4)访问数据库执行SQL语句(通过调用
MappedMethod执行) -
5)处理数据库返回结果。
-
Mybatis有三种基本的Executor执行器,
SimpleExecutor、ReuseExecutor、BatchExecutor。SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。

作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
-
-
【问】Mybatis中如何指定使用哪一种Executor执行器?(通过
sqlSessionFactory.openSession(ExecutorType execType)创建sqlsession对象)- 在Mybatis配置文件中,在设置(settings)可以指定默认的
ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数,如SqlSession openSession(ExecutorType execType)。 - 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。
- 在Mybatis配置文件中,在设置(settings)可以指定默认的
-
【问】Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?(Mybatis的
association和collection支持延迟加载,即在实际调用该成员对象时,再从数据库中查询并赋值;原理是通过CGLIB实现静态代理,利用setter给成员对象赋值)-
Mybatis仅支持
association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。 -
它的原理是,使用
CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
-
-
【问】
#{}和${}的区别?(建议使用#{}:#{}预编译处理,变量替换在DBMS中进行,替换时会自动在变量外侧加上'xx';${}字符串拼接处理,变量替换在DBMS之外,不会自动在变量外侧加上'xx')-
#{}是占位符,预编译处理,Mybatis 在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;${}是拼接符,字符串替换,没有预编译处理(容易造成sql注入问题),Mybatis 在处理${}时,就是把${}替换成变量的值。(辅助记忆:$表示为了挣快钱,所以不能预编译) -
#{}的变量替换是在DBMS 中;${}的变量替换是在 DBMS 外 -
变量替换后,
#{}对应的变量自动加上单引号‘’;变量替换后,${}对应的变量不会加上单引号‘’ -
#{}可以有效的防止SQL注入,提高系统安全性;${}不能防止SQL 注入。
-
-
【问】模糊查询like语句该怎么写(建议使用
CONCAT(’%’,#{question},’%’)),参考MySql like模糊查询语句用法-
1)
’%${question}%’可能引起SQL注入,不推荐 -
2)
"%#{question}%"注意:因为#{…}解析成sql语句时候,会在变量外侧自动加单引号‘’,所以这里%需要使用双引号" ",不能使用单引号‘’,不然会查不到任何结果。 -
3)
CONCAT(’%’,#{question},’%’)使用CONCAT()函数,推荐 -
4)使用
bind标签:<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User"> <bind name="pattern" value="'%' + username + '%'" /> select id,sex,age,username,password from person where username LIKE #{pattern} select>
-
-
【问】在mapper中如何传递多个参数(建议使用@Param,Map和javaBean传参,但要注意场合)
-
方法1:顺序传参法(不推荐)
//UserMapper.java public User selectUser(String name, int deptId); //UserMapper.xml <select id="selectUser" resultMap="UserResultMap"> select * from user where user_name = #{0} and dept_id = #{1} select>#{}里面的数字代表传入参数的顺序。这种方法不建议使用,sql层表达不直观,且一旦顺序调整容易出错。
-
方法2:
@Param注解传参法(推荐在参数不多时使用)//UserMapper.java public User selectUser(@Param("userName") String name, int @Param("deptId") deptId); //UserMapper.xml <select id="selectUser" resultMap="UserResultMap"> select * from user where user_name = #{userName} and dept_id = #{deptId} select>#{}里面的名称对应的是注解@Param括号里面修饰的名称。这种方法在参数不多的情况还是比较直观的,推荐使用。
-
方法3:Map传参法(推荐在参数易变情况下使用)
//UserMapper.java public User selectUser(Map<String, Object> params); //UserMapper.xml <select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap"> select * from user where user_name = #{userName} and dept_id = #{deptId} </select>#{}里面的名称对应的是Map里面的key名称,parameterType设置为"java.util.Map"。这种方法适合传递多个参数,且参数易变能灵活传递的情况。
-
方法4:Java Bean传参法
//UserMapper.java public User selectUser(User user); //UserMapper.xml <resultMap id="UserResultMap" type="com.jourwon.pojo.User"> ... resultMap> <select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap"> select * from user where user_name = #{userName} and dept_id = #{deptId} select>#{}里面的名称对应的是User类里面的成员属性,parameterType设置为com.jourwon.pojo.User这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。
-
-
【问】parameterType,resultType,resultMap的区别?(
namespace用于绑定mapper接口和mapper.xml;parameterType为传参类型,看上一问;resultType自动映射;resultMap手动映射),参考Mybatis自动映射和手动映射:namespace,resultMap和resultType & 自动映射规则- 映射文件中的
namespace是用于绑定Dao接口的,即面向接口编程。当你的namespace绑定接口后,你可以不用写接口实现类,mybatis会通过该绑定自动帮你找到对应要执行的SQL语句(生成相应接口的动态代理对象执行sql)。 resultMap是Mybatis最强大的元素,支持自定义,而resultType直接返回java对象类型,但两者不能同时存在。resultMap可以将查询到的复杂数据(比如查询到几个表中数据)映射到一个结果集当中。通过type属性设置要进行手动映射的pojo类型。resultType实现数据库数据和pojo对象的自动映射(可以不完全一致,自动映射规则参考 https://mybatis.org/mybatis-3/sqlmap-xml.html#Auto-mapping),而resultMap支持手动映射。
- 映射文件中的
-
【问】如何获取生成的主键(在
mapper.xml的insert方法中使用useGeneratedKeys="true",mybatis会自动将生成的id封装到传入的javaBean对象中),参考Mybatis 获取自增主键Note:
-
要想获得数据库中自动生成的主键,要用
Java Bean或者Map来传递Mapper参数,Mapper接口的代理实现类会将返回的自增id自动装填回JavaBean或者Map中。 -
虽然这里的
parameterType可以省略,Mybatis会可以推断出传入的数据类型,但是为了代码的可读性,建议加上。//mapper.java public int addEmp(employee); //mapper.xml <insert id="addEmp" databaseId="mysql" parameterType="employee" useGeneratedKeys="true" keyProperty="id"> insert into tbl_employee (id, last_name, email, gender) values (#{id}, #{lastName}, #{email}, #{gender}); insert>
-
-
【问】当实体类中的属性名和表中的字段名不一样 ,怎么办?(为字段名定义别名,再使用
resultType自动映射;使用resultMap手动映射,返回类型仍然是pojo对象)-
第1种: 通过在查询的SQL语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
<select id="getOrder" parameterType="int" resultType="com.jourwon.pojo.Order"> select order_id id, order_no orderno ,order_price price form orders where order_id=#{id}; select>第2种: 通过
<resultMap type="com.jourwon.pojo.Order" id="orderResultMap"> <!–用id属性来映射主键字段–> <id property="id" column="order_id"> <!–用result属性来映射非主键字段,property为实体类属性名,column为数据库表中的属性–> <result property ="orderno" column ="order_no"/> <result property="price" column="order_price" /> reslutMap> <select id="getOrder" parameterType="int" resultMap="orderResultMap"> select * from orders where order_id=#{id} select>
-
-
【问】Mapper 编写有哪几种方式?
共3种,这里介绍最常用的一种:
- 1)定义 mapper 接口:
- 2)mapper.xml 中的 namespace 为 mapper 接口的地址
- 3)mapper 接口中的方法名和 mapper.xml 中的定义的 statement 的
id保持一致
-
【问】什么是MyBatis的接口绑定?有哪些实现方式?(在xml指定
namespace进行接口绑定;直接在接口方法上使用@Select,@Update等注解;使用哪种绑定方式看sql是否复杂度来决定)-
接口绑定,就是在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定,我们直接调用接口方法就可以,这样比起原来了
SqlSession提供的方法我们可以有更加灵活的选择和设置。 -
接口绑定有两种实现方式:
- 通过注解绑定,就是在接口的方法上面加上
@Select、@Update等注解,里面包含Sql语句来绑定; - 通过
xml里面写SQL来绑定, 在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名。
当Sql语句比较简单时候,用注解绑定, 当SQL语句比较复杂时候,用
xml绑定,一般用xml绑定的比较多。 - 通过注解绑定,就是在接口的方法上面加上
-
-
【问】使用MyBatis的mapper接口调用时有哪些要求?
-
Mapper.xml文件中的
namespace即是mapper接口的类路径。 -
Mapper接口方法名和mapper.xml中定义的**每个sql的
id**相同。 -
Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的
parameterType的类型相同。 -
Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的
resultType的类型相同。
-
-
【问】最佳实践中,通常一个xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗(通过“全限名 + 方法名(id)”查找唯一指定的
MappedStatement),参考Mybatis-Spring源码分析(五) MapperMethod和MappedStatement解析- Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的
namespace的值,接口的方法名,就是映射文件中**MappedStatement的id值**,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,"接口全限名+方法名"拼接字符串作为key值,可唯一定位一个MappedStatement,举例:如果方法名为com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个、MappedStatement对象。 - Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
- Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理
proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。
- Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的
-
【问】MappedMethod和MappedStatement有什么作用?sql语句究竟是如何执行的?(参考上一问 和 之前的Mybatis原理问题),参考Mybatis-Spring源码分析(二) Mapper接口代理的生成,Mybatis-Spring源码分析(五) MapperMethod和MappedStatement解析,MyBatis中的适配器模式(MapperMethod类图),Mybatis中sql执行过程的类图
-
MapperMethod它就有点像Spring中的BeanDefinition,用来描述一个Mapper里面一个方法的内容的。比如UserMapper接口里面有一个query()方法,那么这个的MapperMethod就是描述这个query()方法,比如有没有注解,参数是什么之类,用于后续调用执行。既然说到要解析这个类,那就要找到它出现的位置,MapperProxy#cachedInvoker方法,可以看到它的第一次使用是在PlainMethodInvoker中new出来了,传入的方法是mapperInterface用来表示是哪个mapper接口;method方法用来表示是接口中的哪个方法。 -
MapperMethod构造器通过new SqlCommand(config, mapperInterface, method);获得sql命令,而在SqlCommand构造器中则是通过resolveMappedStatement(mapperInterface, methodName, declaringClass,configuration);获得MappedStatement对象; -
在
resolveMappedStatement方法中可以发现,MappedStatement对象则是通过"接口全限名+方法名"拼接成的字符串作为key值从Map中获取得到的,主要用来存储要映射的SQL语句的id、参数等信息。 -
因此
mybatis如何利用与指定Mapper接口绑定的映射文件 完成sql语句的执行操作,简单理解就是:参考Mybatis源码解析(三)sql执行方法过程-
通过
sqlSession.getMapper(UserMapper.class)获取指定Mapper接口的代理对象,该mapper代理对象中最初代的代理对象为MapperProxy,通过Mapper接口、实现了InvocationHandler接口的PlainMethodInvoker来创建; -
代理对象调用
Mapper接口的方法(比如addEmp())时,会调用最初代的代理对象MapperProxy的invoke(),由于PlainMethodInvoker对象中封装着MapperMethod对象,MapperMethod对象中封装着MappedStatement对象,PlainMethodInvoker通过mapperMethod.execute(sqlSession, args)来执行sql命令,而代理对象MapperProxy在执行invoke()时会执行mapperMethod.execute();
-
在执行
mapperMethod.execute(sqlsession,args)时,会完成指定接口方法中的sql语句,具体流程如下:-
1)首先通过
switch case判断执行的Sql类型,是增删改查的哪一种,接着判断方法的返回值类型,看看是返回的是集合还是单个对象。这里假设调用的是executeMany(sqlsession,args); -
2)在
executeForMany(...)方法中,调用convertArgsToSqlCommandParam()将参数转换为sql的参数 -
3)
executeForMany(...)中通过sqlsession.selectList(...)来完成核心的查询功能 -
4)在
sqlsession.selectList(...)中,先通过key获取mappedStatement,接着executor利用mappedStatement,通过executor.query(...)来完成查询 -
5)在
executor.query(...)中,其查询逻辑是先通过CacheExecutor查看二级缓存是否有数据,如果没有会调用BaseExecutor查看一级缓存,如果还没有再通过SimpleExecutor或者BatchExecutor创建StatementHandler,构建prepareStatement,进而对我们熟悉的jdbc操作进行封装。

-
-
-
-
【问】如果使用Spring的IoC容器对mybatis的bean进行创建和管理,则Spring-mybatis的sql执行过程是怎样的? ,参考Mybatis-Spring源码分析(四) Mybatis的初始化
-
Mybatis-Spring初始化分为:
MapperFactoryBean实例化和赋值 和MapperFactoryBean初始化。 -
MapperFactoryBean实例化和赋值:通过分析源码可以得出
@MapperScan主要做了三个工作:-
扫描出所有的
Mapper接口所对应的BeanDefinition -
当
ApplicationContext容器启动结束后,通过获取关于Mapper接口所对应BeanDefinition对象中的信息(配置注册表),实例化所有的bean,具体来说,是把Mapper接口转换为FactoryBean,或者说MapperFactoryBean的BeanDefinition。 -
当
MapperFactoryBean赋完值之后,在Spring实例化过程中根据这个Class返回相对应的代理对象。
-
-
MapperFactoryBean初始化:- Mybatis主要通过Spring的初始化方法扩展点来完成对
Mapper接口信息的初始化,比如SQL语句的初始化等等。其实就是利用MapperFactoryBean实现了InitializingBean接口,然后使用AfterPropertiesSet()方法机制进行初始化。由于MapperFactoryBean其实就是一个Mapper,所以又可以理解为其就是一个Mapper信息的缓存,因为是被代理的并没有真正的代码。当所有的Mapper都被解析完毕以后,再缓存到一个Map中,共给后面调用时使用。

- Mybatis主要通过Spring的初始化方法扩展点来完成对
-
-
【问】Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
namespace+id是作为Map的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
-
【问】简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?(封装成
Configuration,以及将各种标签解析成对应的对象)- Mybatis将所有
Xml配置信息都封装到All-In-One重量级对象Configuration内部:- 在xml映射文件中,
ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。 ResultMap对象,其每个子元素会被解析为ResultMapping对象。- 每一个
、MappedStatement对象,标签内的sql会被解析为BoundSql对象。
- 在xml映射文件中,
- Mybatis将所有
-
【问】Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?,参考MyBatis的9种动态标签,Mybatis sql 片段重用
-
还有很多其他的标签,
-
使用
sql片段重用:<-- sql片段定义: 定义所有的字段 --> <sql id="columns_query"> ${alias}.id, ${alias}.name, ${alias}.sex, ${alias}.age, ${alias}.entryDate sql> <select id="queryAll" resultType="EmployeePO"> select <include refid="columns_query"> <property name="alias" value="emp"/> include> from t_employee emp select>sql标签:
- sql 标签中不能通过
#{}来引用参数, 因为#{} 是处理占位符参数的 - sql 标签中只能使用
${}接收引用时传入的参数, ${} 表示的是字符串替换 ${}可获取接口传入的或自定义的参数(include 标签中定义的参数)
include标签:
include标签用于引用自定义的sql片段, 可以嵌套在任何sql语句的任何位置refid: 指的是引用sql片段的idproperty属性: 自定义参数, value 可使用ognl表达式
- sql 标签中不能通过
-
动态sql的9个标签:
trim|where|set|foreach|if|choose|when|otherwise|bind-
If: 当参数满足条件才会执行某个条件 -
choose、when、otherwise: choose标签是按顺序判断其内部when标签中的test条件是否成立,如果有一个成立,则choose结束;如果所有的when条件都不满足时,则执行otherwise中的SQL。类似于java的switch语句。 -
where:where标签会在只有一个以上的if条件满足的情况下才去插入WHERE关键字,而且,若最后的内容是”AND”或”OR”开头的,where也会根据语法决定是否需要保留。 -
set:set标签会动态前置SET关键字,同时也会消除无关的逗号,因为用了条件语句后,可能就会在生成的赋值语句的后面留下逗号。 -
trim:trim标签可实现where/set标签的功能;Trim标签有4个属性,分别为prefix、suffix、prefixOverrides、suffixOverrides<select id="findName" resultType="String"> SELECT stu.name FROM tab_stu stu <trim prefix="where" prefixOverrides="and |or"> <if test="age != null"> age = #{age} if> <if test="name!= null"> AND name= #{name} if> <if test="class!= null"> OR class = #{class} if> trim> select> <update id=”updateStu”> Update tab_stu <trim prefix="set" suffix="where id=#{id}" suffixOverrides=","> <if test="name != null"> name=#{name},if> <if test="age != null"> age=#{age},if> <if test="class != null"> class=#{class},if> <if test="subject != null"> subject=#{subject}if> trim> update>
-
-
-
【问】Mybatis映射文件中,如果A标签通过
sql标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?(如果标签A引用的B标签没有被解析,则A标签会被延迟解析)-
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
-
原理:Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
-
-
【问】Mybatis如何执行批量操作(使用
ExecutorType.BATCH创建BatchExecutor对象,都可以在实现批处理时复用sql预编译语句,提高更新的效率,但是ExecutorType.BATCH),参考MyBatis批量插入几千条数据慎用foreach-
方法1:使用
foreach的主要用在构建in条件中,它可以在SQL语句中进行迭代一个集合。
foreach标签的属性主要有item,index,collection,open,separator,close。item 表示集合中每一个元素进行迭代时的别名,随便起的变量名; index 指定一个名字,用于表示在迭代过程中,每次迭代到的位置,不常用; open 表示该语句以什么开始,常用“(”; separator 表示在每次进行迭代之间以什么符号作为分隔符,常用“,”; close 表示以什么结束,常用“)”。 在使用foreach的时候最关键的也是最容易出错的就是
collection属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下3种情况:-
如果传入的是单参数且参数类型是一个List的时候,collection属性值为list
-
如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
-
如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map,实际上如果你在传入参数的时候,在MyBatis里面也是会把它封装成一个Map的,
map的
key就是参数名,所以这个时候collection属性值就是传入的List或array对象在自己封装的map里面的key
-
写法1:
INSERT INTO语句内://EmpMapper.java int addEmpsBatch(@Param("emps") List<Employee> emps); //EmpMapper.xml //推荐使用 <insert id="addEmpsBatch"> INSERT INTO emp(ename,gender,email,did) VALUES <foreach collection="emps" item="emp" separator=","> (#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id}) foreach> insert> -
写法2:
INSERT INTO语句外,但是这种方式需要设置数据库连接属性allowMutiQueries=true<insert id="addEmpsBatch"> <foreach collection="emps" item="emp" separator=";"> INSERT INTO emp(ename,gender,email,did) VALUES(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id}) foreach> insert>
-
-
方法2:使用
ExecutorType.BATCHMybatis内置的
ExecutorType有3种,默认为simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;而batch模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然batch性能将更优; 但batch模式也有自己的问题,比如在Insert操作时,在事务没有提交之前,是没有办法获取到自增的id,这在某型情形下是不符合业务要求的。具体用法如下
//批量保存方法测试 @Test public void testBatch() throws IOException{ SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); //可以执行批量操作的sqlSession SqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH); //批量保存执行前时间 long start = System.currentTimeMillis(); try { EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class); for (int i = 0; i < 1000; i++) { mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1")); } openSession.commit(); long end = System.currentTimeMillis(); //批量保存执行后的时间 System.out.println("执行时长" + (end - start)); //批量 预编译sql一次==》设置参数==》10000次==》执行1次 677 //非批量 (预编译=设置参数=执行 )==》10000次 1121 } finally { openSession.close(); } } //mapper.java public interface EmployeeMapper { //批量保存员工 Long addEmp(Employee employee); } //mapper.xml如下 <mapper namespace="com.jourwon.mapper.EmployeeMapper" <!--批量保存员工 --> <insert id="addEmp"> insert into employee(lastName,email,gender) values(#{lastName},#{email},#{gender}) </insert> </mapper> -
-
在使用
Executor类型为Simple,会为每个语句创建一个新的预处理语句,也就是创建一个PreparedStatement对象。在我们的项目中,会不停地使用批量插入这个方法,而因为MyBatis对于含有由于在实验时,
foreach后有5000+个values,所以这个PreparedStatement特别长,包含了很多占位符,对于占位符和参数的映射尤其耗时。并且,查阅相关资料可知,values的增长与所需的解析时间,是呈指数型增长的。
-
如果MyBatis需要进行批量插入,推荐使用
ExecutorType.BATCH的插入方式,如果非要使用
-
-
-
【问】MyBatis实现一对一,一对多有几种方式,怎么操作的?(
association和collection标签,这两标签会在正在调用该对象时才延迟加载,即分步查询,原理是基于CGLIB静态代理实现),参考MyBatis:association和collection标签 - 分步查询 -
【问】Mybatis是否可以映射Enum枚举类?(利用
TypeHandler完成映射)- Mybatis可以映射枚举类,不单可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方式为自定义一个
TypeHandler,实现TypeHandler的setParameter()和getResult()接口方法。 TypeHandler有两个作用,一是完成从javaType至jdbcType的转换,二是完成jdbcType至javaType的转换,体现为setParameter()和getResult()两个方法,分别代表设置sql问号占位符参数和获取列查询结果。
- Mybatis可以映射枚举类,不单可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方式为自定义一个
-
【问】Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?(原理为使用
OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql) -
【问】Mybatis是如何进行分页的?分页插件的原理是什么?
-
【问】简述Mybatis的插件运行原理,以及如何编写一个插件?
- Mybatis仅可以编写针对
ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。 - 实现Mybatis的Interceptor接口并复写
intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
- Mybatis仅可以编写针对
-
【问】Mybatis的一级、二级缓存(一级缓存作用域为session,默认开启;二级缓存作用域在mapper Namespaces,默认不开启;在C/U/D时会对缓存进行更新)
- 1)一级缓存:基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
- 2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现
Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 - 3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有
select中的缓存将被 clear。
8、Redis
参考 Redis官方中文文档,Redis面试题(2020最新版)
- 【问】Redis是什么?Redis支持的数据类型有哪些?(数据结构为
key-value的内存数据库,其中value的数据类型包括string、hash、list、set和zset,这些数据结构都支持pop/push和remove/add操作;redis将数据存储在内存中,并定期把更新的数据写入磁盘或者把修改操作写入追加的日志文件中(以快照或追加的方式刷新到磁盘中),可参考redis五大基本类型以及应用场景
Note:Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的。5.0版本中,Redis新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列。
- 【问】Redis都有哪些使用场景?(利用
redis将CPU高频访问的数据放在内存中,配合其它数据库作为存储层,大大加快系统读写速度,降低后端数据库的压力;实时计数器;利用redis将用户的session进行集中管理,用户在刷新界面时,通过内存中的session而非客户端的cookies来实现重新 登录),可参考redis五大基本类型以及应用场景 - 【问】Redis有哪些功能?(将访问mysql的数据保存在内存中,下次再次访问时直接从内存里拿;持久化;哨兵;集群
- 【问】Redis实现高可用的四种方式,可参考Redis哨兵模式及集群,一文了解Redis高可用四种模式----持久化、主从复制、哨兵模式与集群搭建
Note:
Redis高可用有四种实现方法:持久化、主从复制、哨兵模式、集群模式- 1)持久化适用于单台服务器,主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失,其是最简单的一种高可用方式;
Redis 4.0之前为RDB和AOF持久化,Redis 4.0后使用两种模式的混合持久化功能。 - 2)主从复制/主从同步:主从复制是高可用
Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡(从节点同步主节点的内容,在访问数据时从不同的数据节点上读)和简单的故障恢复(当主服务器宕机之后,可以很迅速的把从节点提升为主节点,但原来的主节点需要手动恢复);
缺陷是故障恢复无法自动化,写操作无法负载均衡,存储能力受到单机的限制。 - 3)哨兵(sentinel) 是一个分布式系统(哨兵节点不存储数据,只负责监控,而主从为数据节点),哨兵集群的作用是对主从结构中的每台服务器进行监控,自动进行故障转移(实现自动化的故障恢复)、以及通知客户端。
- 在故障转移机制中,哨兵节点会每隔
1s检测主节点,从节点和其它哨兵节点的心跳;如果主节点客观下线,需要选举出一个哨兵作为leader,负责处理主节点的故障转移工作; - 当Master出现故障时通过投票机制选择新的 Master 并将所有 Slave 连接到新的 Master(原主节点恢复之后会变成从节点)。因此整个运行的节点数量、哨兵的节点数量不得少于3个。
- 故障转移之后需要通知客户端主节点已经更换。
缺陷是写操作无法负载均衡,存储能力受到单机的限制。
- 在故障转移机制中,哨兵节点会每隔
- 4)集群(Cluster) 提供了分布式存储方案解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案,其集群最低需要6个节点,三主三从,实现
Redis高可用。
- 1)持久化适用于单台服务器,主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失,其是最简单的一种高可用方式;
- 【问】说说Redis哈希槽的概念?,参考redis分布式介绍
Note:Redis集群没有使用一致性hash,而是引入了哈希槽(slot)的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽,进而实现负载均衡。

- 【问】Redis取值存值问题(直接创建
jedis对象,也可以通过JedisPool创建的jedis连接池对象,从连接池对象中获得与redis连接的对象),参考【Redis高手修炼之路】Jedis—Jedis的基本使用,jedis-2.1.0操作文档,jedis api中文文档 - 【问】Redis为什么是单线程的?能否支持多线程(网络处理模块支持多线程,而执行命令模块依旧单线程
Note:Redis6.0之前是单线程的,不存在加锁和释放锁的操作,不存在死锁问题,不存在多线程切换而消耗CPU,可以通过开启多个Redis实例实现多线程(复制redis.conf,修改Redis-server端口),参考【Redis运维篇】同一台机器上启动多个Redis实例Redis6.0后开始支持多线程,Redis主要的性能瓶颈是内存和网络,内存瓶颈加内存条就行,而在网络瓶颈处理上,Redis6.0在网络IO处理方面引入了多线程,如网络数据的读写和协议解析等,但执行命令的核心模块还是单线程的。
- 【问】Redis持久化有几种方式?(快照
RDB和追加AOF)
Note:RDB(Redis DataBase,快照方式)是将某一个时刻的内存数据,以二进制的方式写入磁盘。优点是以二进制存储、占用空间更小、数据存储更紧凑,与AOF相比,RDB具备更快的重启恢复能力。AOF(Append Only File,文件追加方式)是指将所有的操作命令,以文本的形式追加到文件中。优点是存储频率更高,因此丢失数据的风险就越低,相比与RDB数据恢复的完整度越高,缺点是占用空间大,重启之后的数据恢复速度比较慢。Redis 4.0后使用两种模式的混合持久化功能,可以兼顾两者的优点,如果Redis重启的话,则会优先采用AOF方式来进行数据恢复。- 持久化功能是
Redis和Memcached的主要区别之一,因为只有Redis提供了此功能,在Redis不开启RDB和AOF时,相当于Memcached。
- 【问】Redis和 memcache 有什么区别?,参考redis与memcache区别
Note:memcache也是key-value,但数据结构单一,无类型,仅用于缓存数据;Redis内存利用率高于Memcache;Redis只使用单核、支持持久化和数据恢复,memcache使用多核、不能支持持久化;Redis支持分布式集群,memcache不支持- 应用场景:
Memcached:动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量场景。Redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统。
- 【问】Redis支持的 java 客户端都有哪些?(
Redisson、Jedis、lettuce等),参考Redis 客户端 - 【问】jedis 和 redisson 有哪些区别?(
Jedis只是简单的封装了 Redis 的API库,而redisson不仅封装了 redis ,还封装了对更多数据结构的支持,以及锁等功能;Jedis更原生,redisson功能更强大) - 【问】怎么保证缓存和数据库数据的一致性?(缓存双删除;利用Binlog和消息队列异步更新缓存),可参考如何设计DB+缓存,真的长见识了!
Note:-
1)淘汰缓存:对于较为复杂的数据的更新操作,选择不更新缓存,而是淘汰缓存;
-
2)对于更新请求,选择先淘汰缓存,再更新数据库:
- 场景1:先更新
mysql再 淘汰缓存,如果淘汰缓存失败,下次请求读的是脏数据,直至缓存过期,会出现数据库和缓存数据不一致的问题;如果数据库更新失败,缓存和数据库并不会出现数据不一致; - 场景2:先淘汰缓存 再 更新
mysql,如果更新数据库失败,缓存淘汰成功,则下次只会产生一次缓存穿透获取mysql数据,此时数据库和缓存数据一致;
- 场景1:先更新
-
3)延时双删策略:过一段时间再次删除缓存(2次),下次请求时通过缓存穿透再次访问数据库,保证缓存和数据库数据一致。
- 场景1:两个事务同时写同一个
key,出现缓存和数据库数据不一致1.请求A进行写操作,删除缓存 2.请求B查询发现缓存不存在 3.请求B去数据库查询得到旧值 4.请求B将旧值写入缓存 5.请求A将新值写入数据库 - 场景2:一个事务写,一个事务读,读写分离出现缓存和数据库数据不一致
采用延时双删策略解决以上两个问题:1.请求A进行写操作,删除缓存 2.请求A将数据写入数据库了, 3.请求B查询缓存发现,缓存没有值 4.请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值 5.请求B将旧值写入缓存 6.数据库完成主从同步,从库变为新值
public void write(String key,Object data){ redisUtils.del(key); db.update(data); Thread.Sleep(100); redisUtils.del(key); }这么做,可以将1秒内所造成的缓存脏数据,再次删除,时间设置根据业务场景设定(但是这种手动设置
500ms延迟的双删方案让人不敢苟同)。

主要原因是对于查询请求
B和更新请求A,要想保证删除缓存 在 回写缓存之后,则需要手动设置500ms延迟,让请求B来完成缓存双删,但是如果查询时间很长,实际上设置500ms并不合适,因此仍然无法保证mysql和缓存的数据一致性,不建议使用。
替换方案是通过消息队列的异步&串行,实现最后一次缓存删除;
缓存删除失败,增加重试机制。 - 场景1:两个事务同时写同一个
-
4)先写
mysql,通过Binlog,异步更新redis:
这种方案,主要是监听 MySQL 的Binlog,然后通过异步的方式,将数据更新到 Redis,这种方案有个前提:查询的请求不会回写 Redis。

这个方案,是实现最终一致性的终极解决方案,但是不能保证实时性。 -
5)小总结:
- 实时一致性方案 :采用“先写
mysql,再删除 Redis”的策略,这种情况虽然也会存在两者不一致,但是需要满足的条件有点苛刻,所以是满足实时性条件下,能尽量满足一致性的最优解。 - 最终一致性方案 :采用“先写
mysql,通过Binlog,异步更新 Redis”,可以通过 Binlog,结合消息队列异步更新 Redis,是最终一致性的最优解。
- 实时一致性方案 :采用“先写
-
- 【问】Redis什么是缓存穿透?怎么解决?(缓存穿透:有些恶意的请求会故意查询不存在的
key,缓存中没有对应value,需要到后台找,如果数据量大会增加后台数据库的访问压力;缓存雪崩:缓存内的key-value集中在某一段时间内失效,会给后端带来很大的访问压力),可参考缓存穿透和缓存雪崩问题解决!!!
Note:- 缓存穿透解决:
- 1)对查询结果为空,即不存在的
key设置较短的缓存时间,在该key数据insert之后清理之前的缓存。 - 2)利用大的
Bitmap存放所有可能存在的key(利用hash函数存放key),在查询时利用Bitmap对不存在的key进行过滤(布隆过滤器)。
- 1)对查询结果为空,即不存在的
- 缓存雪崩解决:
- 1)加锁排队: 在缓存失效后,通过加锁或者队列来控制读数据库(
mysql)写缓存的线程数量(避免大量请求同时访问后台数据库造成崩溃)。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。 - 2)数据预热:通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀;
- 3)做二级缓存(双缓存策略):
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。 - 4)缓存的
key永远不过期。
- 1)加锁排队: 在缓存失效后,通过加锁或者队列来控制读数据库(
- 缓存穿透解决:
- 【问】Redis怎么实现分布式锁?
- 【问】Redis分布式锁有什么缺陷?
- 【问】Redis如何做内存优化?
9、MongoDB
参考学习 MongoDB 一篇文章就够了(珍藏版),MongoDB(精简版)
10、RabbitMQ(AMQP组件,集群,消息可靠传输)
参考RabbitMQ消息队列常见面试题总结,Python中RabbitMQ的使用,消息中间件MQ与RabbitMQ面试题(2020最新版)
-
【问】AMQP协议的工作流程?以及一些细节问题?,参考深入理解AMQP协议
Note:AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是一个进程间传递异步消息的网络协议(两个对等节点的信息交换规则,基于观察者模式的实现)。

- 工作流程如下:
1)发布者(Publisher)发布消息(Message),经由交换机(Exchange);
2)交换机根据路由规则将收到的消息分发给与该交换机绑定的队列(Queue);
3)最后AMQP代理会将消息投递给订阅了此队列的消费者,或者消费者按照需求自行获取。 - 细节问题:
- 1)发布者、交换机、队列、消费者都可以有多个。同时因为
AMQP是一个网络协议,所以这个过程中的发布者,消费者,消息代理可以分别存在于不同的设备上。 - 2)发布者发布消息时可以给消息指定各种消息属性(
Message Meta-data)。有些属性有可能会被消息代理(Brokers)使用,然而其他的属性则是完全不透明的,它们只能被接收消息的应用所使用。 - 3)从安全角度考虑,网络是不可靠的,又或是消费者在处理消息的过程中意外挂掉,这样没有处理成功的消息就会丢失。基于此原因,AMQP 模块包含了一个消息确认(
Message Acknowledgements)机制:当一个消息从队列中投递给消费者后,不会立即从队列中删除,直到它收到来自消费者的确认回执(Acknowledgement)后,才完全从队列中删除。 - 4)在某些情况下,例如当一个消息无法被成功路由时(无法从交换机分发到队列),消息或许会被返回给发布者并被丢弃。或者,如果消息代理执行了延期操作,消息会被放入一个所谓的死信队列中。此时,消息发布者可以选择某些参数来处理这些特殊情况。
- 1)发布者、交换机、队列、消费者都可以有多个。同时因为
-
【问】什么是消息队列,消息队列的优缺点?(优点:解耦,异步(非主业务,减少等待),削峰/限流(请求队列);缺点:增加系统复杂度)
Note:- 优点:
- 1)解耦:将系统按照不同的业务功能拆分出来,消息生产者只管把消息发布到 MQ 中而不用管谁来取,消息消费者只管从 MQ 中取消息而不管是谁发布的。消息生产者和消费者都不知道对方的存在;
- 2)异步:主流程只需要完成业务的核心功能;对于业务非核心功能,将消息放入到消息队列之中进行异步处理,减少请求的等待,提高系统的总体性能;
- 3)削峰/限流:将所有请求都写到消息队列中,消费服务器按照自身能够处理的请求数从队列中拿到请求,防止请求并发过高将系统搞崩溃;
- 缺点:
- 1)系统的可用性降低:系统引用的外部依赖越多,越容易挂掉,因此需要考虑MQ高可用。
- 2)系统复杂度提高:加入消息队列之后,需要保证消息没有重复消费、如何处理消息丢失的情况、如何保证消息传递的有序性等问题;
- 优点:
-
【问】RabbitMQ的使用场景有哪些?
Note:- 1)解决异步问题
例如用户注册,发送邮件和短信反馈注册成功,可以使用RabbitMQ消息队列,用户无需等待反馈,还有体育新闻网站可以用它来近乎实时地将比分更新分发给移动客户端,股票价格更新(以及其他类型的金融数据更新)。 - 2)服务间解耦(观察者模式对观察者,被观察者解耦)
订单系统和库存系统,中间加入RabbitMQ消息队列,当库存系统出现问题时,订单系统依旧能正常使用,降低服务间耦合度。 - 3)削峰/限流:配合
redis实现秒杀系统,用于缓存某一时刻的大量请求,避免多个用户同时修改同一个商品的数量。 参考基于Redis和RabbitMQ简单实现秒杀回顾
具体流程如下:- 1)redis缓存预热,先将秒杀产品的ID和数量value缓存到redis中;
- 2)用户加入购物车时需要判断value是否小于0,如果否,则将请求放入消息队列;
- 3)用户在点击确认消费时,消息不管是否投递到交换机都进行ConfirmCallback回调,如果消息可以投递到交换机就返回true,投递不到交换机就返回false,之后交换机匹配到队列成功则不进行ReturnCallback回调;
- 4)消费者在处理请求时,需要再次查询redis中该ID的value,判断预减后的值是否小于0,如果否,则生成订单,redis中的value减去商品数。
- 1)redis缓存预热,先将秒杀产品的ID和数量value缓存到redis中;
- 1)解决异步问题
-
【问】消息队列的选型问题(Kafka、ActiveMQ、RabbitMQ、RocketMQ对比)
Note:ActiveMQ、RabbitMQ、RocketMQ、Kafka的比较如图所示:

- 1)中小型软件公司,技术实力较为一般,建议选
RabbitMQ:管理界面用起来十分方便。代码是开源的,而且社区十分活跃。 - 2)大型软件公司:根据具体使用场景在高吞吐MQ中,
rocketMq和kafka之间二选一
-
【问】RabbitMQ的构造?包括哪些组件?
Note:-
RabbitMQ是AMQP协议的一个开源实现,所以其内部实际上也是AMQP中的基本概念:
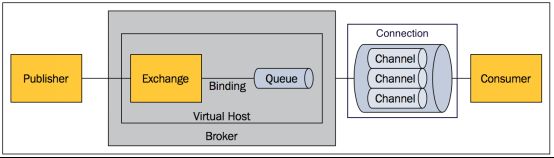
- 1)生产者Publisher:生产消息,就是投递消息的一方。消息一般包含两个部分:消息体(payload)和标签(Label)
- 2)消费者Consumer:消费消息,也就是接收消息的一方。消费者连接到
RabbitMQ服务器(Broker),并订阅到队列上。消费消息时只消费消息体,丢弃标签。 - 3)Broker服务节点:表示消息队列服务器实体。一般情况下一个
Broker可以看做一个RabbitMQ服务器。 - 4)Queue消息队列:用来存放消息。一个消息可投入一个或多个队列,多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
- 5)Exchange交换器:接受生产者发送的消息,根据路由键(
routing Key)将消息路由到绑定的队列上。 - 6)Routing Key路由关键字:用于指定这个消息的路由规则,需要与交换器类型和绑定键(
Binding Key)联合使用才能最终生效。 - 7)Binding绑定:通过绑定将交换器和队列关联起来,一般会指定一个
BindingKey,通过BindingKey,交换器就知道将消息路由给哪个队列了。 - 8)Connection网络连接:,比如一个
TCP连接,用于连接到具体broker - 9)Channel信道:,
AMQP命令都是在信道中进行的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为建立和销毁TCP都是非常昂贵的开销,所以引入了信道的概念,以复用一条TCP连接,一个TCP连接可以用多个信道。客户端可以建立多个channel,每个channel表示一个会话任务(类似NIO中多个channel对应多个buffer,多个channel对应一个selector)。 - 10)Message消息:由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
- 11)Virtual host虚拟主机:用于逻辑隔离,表示一批独立的交换器、消息队列和相关对象。一个
Virtual host可以有若干个Exchange和Queue,同一个Virtual host不能有同名的Exchange或Queue。最重要的是,其拥有独立的权限系统,可以做到vhost范围的用户控制。当然,从RabbitMQ的全局角度,vhost可以作为不同权限隔离的手段。
-
-
【问】Exchange交换器的类型?(直连/扇形/主题/头交换机),参考深入理解AMQP协议
Note:- 交换机是用来发送消息的 AMQP 实体。交换机拿到一个消息之后将它路由给一个或零个队列。它使用哪种路由算法是由交换机类型和绑定(Bindings)规则所决定的。

- 交换机可以有两个状态:持久(durable)、暂存(transient)。持久化的交换机会在消息代理(broker) 重启后依旧存在,而暂存的交换机则不会(它们需要在代理再次上线后重新被声明)。
- 直连交换机:direct 规则是严格意义上的匹配,换言之
Routing Key必须与Binding Key相匹配的时候才将消息传送给 Queue; - 扇形交换机:如果
N个队列绑定到某个扇型交换机上,当有消息发送给此扇型交换机时,交换机会将消息的拷贝分别发送给这所有的N个队列。扇型用来交换机处理消息的广播路由(broadcast routing)。 - Topic交换机:与direct不同,Topic 的路由规则是一种模糊匹配,可以通过通配符满足一部分规则就可以传送。
routingkey必须为单词列表,单词之间以点号分隔开,*号代表一个单词,#号可以替代零个或多个单词。参考RabbitMq——主题(topic)交换机 - header交换机:headers 类型的 Exchange 不依赖于
routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。
- 交换机是用来发送消息的 AMQP 实体。交换机拿到一个消息之后将它路由给一个或零个队列。它使用哪种路由算法是由交换机类型和绑定(Bindings)规则所决定的。
-
【问】生产者消息的过程?
Note:- 1)Producer 先连接到 Broker,建立连接 Connection,开启一个信道 channel
- 2)Producer 声明一个交换器并设置好相关属性
- 3)Producer 声明一个队列并设置好相关属性
- 4)Producer 通过绑定键将交换器和队列绑定起来
- 5)Producer配置完毕后,发送消息到 Broker,其中包含路由键、交换器等信息
- 6)交换器根据接收到的路由键查找匹配的队列
- 7)如果找到,将消息存入对应的队列,如果没有找到,会根据生产者的配置丢弃或者退回给生产者。
- 8)关闭信道
-
【问】消费者接收消息过程?
Note:- 1)Consumer 先连接到 Broker,建立连接 Connection,开启一个信道 channel
- 2)向 Broker 请求消费相应队列中消息,可能会设置响应的回调函数。
- 3)等待 Broker 回应并投递相应队列中的消息,接收消息。
- 4)Consumer 确认收到的消息,发送ack。
- 5)RabbitMQ从队列中删除已经确定的消息。
- 6)关闭信道
-
【问】如何保证消息不被重复消费?(版本号/唯一主键约束/key设置,该问与下一问相对)
Note:- 服务器可能没有接收到消费者发送过来的确认号,使得消息队列不知道这个消息被消费了没有,就会再次发送给其他消费者;
常使用消息队列将消息异步写入到数据库(redis、mysql)中; - 解决方法:
- 1)对数据增加版本号限制,消费者在取数据的时候比对消息中的版本号和数据库中的版本号是否相同(如果相同则不消费);
- 2)对消息增加唯一主键约束(
MQ -> mysql),消费者每次获取信息时会将信息写入到数据库中; - 3)设置记录的key,用于标识该记录是否被消费过(
MQ -> redis),比如在redis中,先判断关于订单ID的key是否存在,如果存在则不消费。
- 服务器可能没有接收到消费者发送过来的确认号,使得消息队列不知道这个消息被消费了没有,就会再次发送给其他消费者;
-
【问】如何保证消息不丢失,进行可靠性传输?(按生产者,以及rabbitMQ/消费者服务器宕机情况进行讨论)
Note:丢数据需要划分成3种情况:- 生产者丢数据:生产者未能将消息成功投递到消息队列上。解决方法有两种:
- 1)事务机制(开启事务(
channel.txSelect()) 后如果出现异常则回滚(channel.txRollback()),如果成功则提交channel.txCommit())。
该缺点是生产者需要阻塞等待事务的执行结果,吞吐量低。- 2)确认机制:生产环境中常用
confirm模式。首先生产者将信道设置为confirm模式,接着生产者在该信道上发送消息,每个消息在信道上会被赋予唯一的ID,当消息成功投递到指定的消息队列上时,RabbitMQ会向生产者返回一个带唯一ID的确认ack;如果消息投递失败则会发送一个Nack。
优点是异步的,生产者在等待信道返回确认的同时可以继续向信道发送消息,吞吐量大。
- 2)确认机制:生产环境中常用
- 1)事务机制(开启事务(
- 消息队列丢数据:主要原因是在使用未持久化的消息队列时,
rabbitMQ就挂掉了;- 解决方法是:使用持久化的消息队列,并配合
confirm机制使用;在消息持久化到磁盘后,会发送ack给生产者,如果生产者没有收到ack,则会重新发送消息。队列持久化配置如下:持久化设置如下(必须同时设置以下 2 个配置):
- 1)创建queue的时候,将queue的持久化标志
durable=true,代表是一个持久的队列,这样就可以保证 rabbitmq 持久化 queue 的元数据,但是不会持久化queue里的数据; - 2)发送消息的时候将
deliveryMode=2,将消息设置为持久化的,此时 RabbitMQ 就会将消息持久化到磁盘上去。
- 1)创建queue的时候,将queue的持久化标志
- 解决方法是:使用持久化的消息队列,并配合
- 消费者丢数据:消费者消息丢失的原因是自动确认机制,消费者从消息队列中消费了消息,消费者在处理消息的时候,会自动向
rabbitMQ发送一个ack,如果此时消费者宕机了,未处理完的消息就丢失了。- 解决方法:消费者设置手动确认,当消费者完成消息处理之后,再向
rabbitMQ发送ack。 - 采用手动确认消息的方式,需要考虑一下2种特殊情况:
- 1)当消费者取消订阅或者断开连接时,
rabbitMQ会认为消费者没有消费该消息,会继续向消费者分发,这样容易出现信息重复消费问题。 - 2)如果
rabbitMQ没有接收到消费者的确认消息,并且消费者连接并没有中断,此时rabbitMQ会认为消费者在忙,并不会分发更多消息。
- 1)当消费者取消订阅或者断开连接时,
- 解决方法:消费者设置手动确认,当消费者完成消息处理之后,再向
- 生产者丢数据:生产者未能将消息成功投递到消息队列上。解决方法有两种:
-
【问】rabbitMQ如何保证消息的有序性?(只存在消费信息乱序场景),参考RabbitMQ如何保证消息的顺序性【重点】,如何保证MQ消息有序性?
Note:- 在使用
mysql binlog进行两个数据库的数据同步时,如果执行顺序错误,比如插入->更新->删除变成删除->插入->更新,则会出现异常。 - 对于消息的有序性要考虑两种:生产者生产信息的有序性,和消费者消费信息的有序性。
- 生产者生产信息乱序:
- rabbitMQ一个
topic对应一个channel,一个channel对应一个队列,因此生产者生产的信息不会出现顺序问题;

- kafka的一个topic的消息会进行分片(
partition)存储在不同的队列中,这样生产的信息就会出现顺序问题,因此解决方法和rabbitMQ一样,设置一个partition
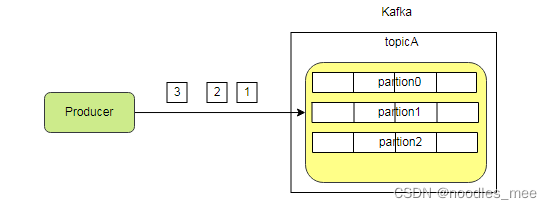
- rabbitMQ一个
- 消费者消费消息乱序的场景:
- 1)一个
queue,有多个consumer去消费(rabbitMQ); - 2)一个
queue对应一个consumer,但是consumer里面进行了多线程消费(kafka);
- 1)一个
- 消费者消费消息乱序解决方案
- 方案1:对于一个
queue只使用一个消费者,但这样吞吐量会降低,容易造成消息积压,实际中很少使用;

- 方案2:一个
topic中的消息使用多个队列来存储,并将同一个类消息放在同一个队列中,一个队列中消息依然对应一个消费者,这样引起消息积压的概率较小;
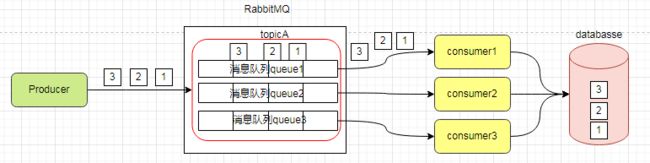
缺点:每个topic都需要创建多个队列,需要维护大量的队列。
- 方案1:对于一个
- 生产者生产信息乱序:
- 在使用
-
【问】如何处理消息堆积情况?(速度不匹配,rabbit队列过期时间设置;改逻辑 / 临时扩容处理积压 / 批量重导)
Note:-
消息堆积的原因:往往是生产者的生产速度与消费者的消费速度不匹配导致的
- 有可能就是消费者消费能力弱;
- 或者消息消费失败反复复重试造成的;
- 也有可能是消费端出了问题(消费端每次消费之后要写mysql,结果mysql挂了;
解决方法1:需要在代码层面优化逻辑解决bug。
-
解决方法2:临时扩容,快速处理积压的消息,比如临时将 queue 资源和 consumer 资源扩大 N 倍,以正常 N 倍速度消费。
- 1)先去掉原来的
consumer; - 2)
queue扩容N倍; - 3)编写消费者脚本将原
queue数据轮询写入到N倍的queue中; - 4)临时部署N个
consumer程序来消费积压数据; - 5)积压数据消费完后,用原先架构继续运行;
- 1)先去掉原来的
-
解决方法3:在流量低峰期,批量重导丢失的数据
如果使用的是rabbitMQ,并且设置了过期时间,消息在queue里积压超过一定的时间会被rabbitmq清理掉,导致数据丢失,丢失的数据需要通过**“批量重导”** 的方案来解决。
在流量低峰期,写一个程序,手动去查询丢失的那部分数据,然后将消息重新发送到mq里面,把丢失的数据重新补回来。
-
-
【问】如何保证消息队列的高可用?(镜像队列集群,master负责写,消费时slave需和master同步,同步导致吞吐量低)
Note:RabbitMQ是基于主从(非分布式)做高可用性的,RabbitMQ有三种模式:单机模式、普通集群模式、镜像集群模式;- 单机模式:自个玩玩,不用于生产环境
- 普通集群模式:在普通集群中,
queue数据只存放在一个rabbitMQ实例中,其余实例都同步queue的元数据,在消费时如果连接了某个实例,该实例可以通过queue元数据中的一些配置信息 找到queue数据对应的实例,完成读写操作。
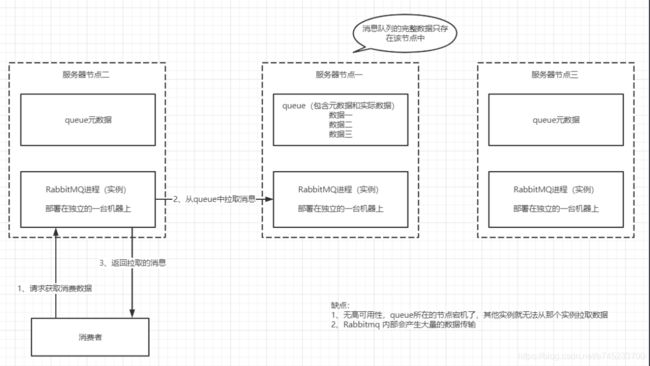
- 镜像队列集群模式:该模式是
RabbitMQ真正的高可用模式(镜像模式作为集群模式,可以保证数据不会丢失),一般包括一个master节点和多个slave节点,master节点如果挂了,则将最早加入的slave节点作为master节点
镜像队列下,所有的消息只会向master发送,再由master将命令的执行结果广播给slave,所以master与slave节点的状态是相同的。-
1)生产过程:生产者向
master发送写消息,master会自动将消息同步到各个slave实例的queue; -
2)消费过程:消费者与
slave建立连接并进行订阅消费,其实质上也是从master上获取消息,因为消费者与slave执行Basic.get(),实际上是由slave将Basic.Get请求发往master,再由master准备好数据返回给slave,最后由slave投递给消费者。

-
缺点:
- ① 性能开销大,消息需要同步到所有机器上,导致网络带宽压力和消耗很重
- ② 不具有分布式计算和分布式存储的能力,在存储上不具有扩展性,如果 queue 的数据量大到这个机器上的容量无法容纳了,此时该方案就会出现问题了。
-
-
【问】RabbitMQ镜像队列集群与hadoop,redis简单比较?
Note:- 1)
hadoop的master/slave能实现分布式,slave是一个工作节点; - 2)
redis在搭建集群时,可以通过hash槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽来实现负载均衡; - 3)
rabbitmq中的master/slave不能实现分布式,queue在slave节点上的备份是为了防止master宕机,实际上在生产和消费时slave都需要与master进行同步、取数据,所以slave是一个存储节点不是工作节点。参考rabbitMq集群之镜像模式
- 1)
-
【问】RabbitMQ中 vhost 的作用是什么?(提供逻辑分组和资源分离,可以配合集群使用;可以将不同用户区分开,避免队列和交换器命名冲突),参考RabbitMQ Virtual Hosts
Note:虚拟主机提供逻辑分组和资源分离。- 每个 RabbitMQ 服务器都能创建虚拟的消息服务器,我们称之为虚拟主机(vhost)每一个
vhost本质上是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器和绑定等等 - 更重要的是,他拥有自己的权限机制,这使得你能够安全地使用一个 RabbitMQ 服务器来服务众多的应用程序
vhost就像是虚拟机之与物理服务器一样:他们在各个实例间提供逻辑上的分离,允许你为不同程序安全保密地运行数据,它既能将同一个Rabbit的众多客户区分开来,又可以避免队列和交换器命名冲突;vhost是AMQP概念的基础,你必须在连接时进行指定- RabbitMQ 包含了一个开箱即用的默认
vhost:”/“,如果你不需要多个 vhost,那么就使用默认的吧,使用缺省的guest用户名和密码gues就可以访问默认的 vhost - 当你在 RabbitMQ 集群上创建
vhost,整个集群上都会创建该vhost,vhost 不仅消除了为基础架构中的每一层运行一个 RabbitMQ 服务器的需要,同样也避免了为每一层创建不同集群。
- 每个 RabbitMQ 服务器都能创建虚拟的消息服务器,我们称之为虚拟主机(vhost)每一个
-
【问】RabbitMQ实现高可用的解决方案,参考RabbitMQ 高可用集群搭建
Note:rabbitMQ中基于镜像模式的集群本身不具备分布式计算和负载均衡(不同节点负载不同),因此可以使用HAProxy实现负载均衡,使用keepAlived的虚拟路由协议(VRRP)解决单点失效的问题,实现故障转移。参考HAproxy实现负载均衡
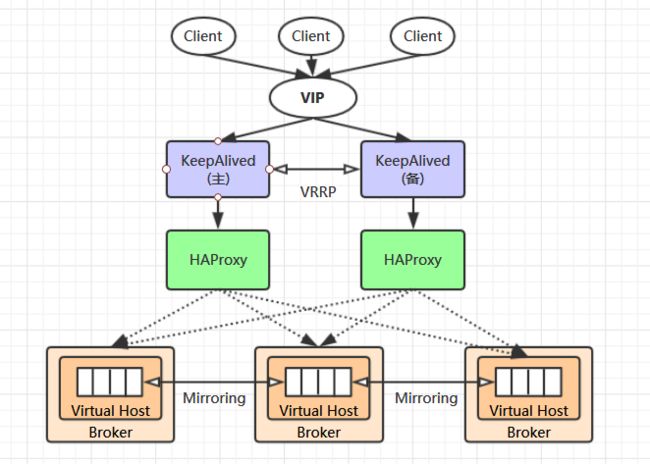
-
【问】RabbitMQ的消息是怎么发送的?(消息生产与消费过程,见上面解析)
-
【问】RabbitMQ怎么保证消息的稳定性?(消费消息的有序性,见上面解析)
-
【问】RabbitMQ怎么避免消息丢失?(生产数据丢失用唯一ID确认机制;消息队列数据丢失使用持久化队列+确认机制;消费者数据丢失则手动确认,见上面解析)
-
【问】要保证消息持久化成功的条件有哪些?(两个配置:queue设置
durable=true,发送消息设置deliveryMode=2见上面解析) -
【问】RabbitMQ持久化有什么缺点?(必然导致性能的下降,因为写磁盘比写
RAM慢的多,message 的吞吐量可能有 10 倍的差距),参考消息中间件MQ与RabbitMQ面试题(2020最新版) -
【问】RabbitMQ有几种分发类型?(直连/扇形/主题/头部,见上面解析)
-
【问】RabbitMQ怎么实现延迟消息队列?(查询延迟任务和执行延时;利用TTL(队列的消息存活时间或者消息存活时间),加上死信交换机),参考实现延迟队列的4种方案,rabbitmq面试题
-
【问】消息在什么时候会变成死信?,参考rabbitmq面试题
Note:- 消息因无法成功被路由而被拒绝,并且没有设置重新入队
- 消息过期
- 消息堆积,并且队列达到最大长度,先入队的消息会变成DL
-
【问】RabbitMQ集群有什么用?(避免单点失效,见上面解析)
-
【问】RabbitMQ节点的类型有哪些?(主从节点,见上面解析)
-
【问】RabbitMQ集群搭建需要注意哪些问题?
-
【问】RabbitMQ每个节点是其他节点的完整拷贝吗?为什么?(镜像模式,见上面解析)
-
【问】RabbitMQ集群中唯一一个磁盘节点崩溃了会发生什么情况?
-
【问】RabbitMQ对集群节点停止顺序有要求吗?
11、Nginx
参考nginx学习 – 从入门到精通
- 【问】Nginx是什么?(提供反向代理的http服务器,采用服务器轮询、权重或者
ip_hash机制,配置proxy pass来实现负载均衡) - 【问】Nginx主配置文件包括哪些内容?(可以在
http中配置多个server监听器)
Note:- 配置文件的主要内容(初始
nginx.conf):#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} } https服务配置内容如下,参考Nginx配置SSL认证实现https服务server { listen 80; server_name domain.com www.domain.com; rewrite ^(.*)$ https://$host$1 permanent; # 重定向 } server { listen 443 ssl; server_name domain.com www.domain.com; ssl_certificate ./xxx.crt; ssl_certificate_key ./xxx.key; ssl_session_timeout 5m; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_prefer_server_ciphers on; location / { proxy_buffer_size 128k; proxy_buffers 32 32k; proxy_busy_buffers_size 128k; proxy_pass http://127.0.0.1:5000; } }
- 配置文件的主要内容(初始
- 【问】Nginx的location路径映射?,参考Nginx路径匹配规则,nginx匹配规则
- 语法规则:
location [=|~|~*|^~] /uri/ {… }符号 含义 =精确匹配 ^~非正则匹配 ~正则匹配(区分大小写) ~*正则匹配(不区分大小写) !~正则不匹配(区分大小写) !~*正则不匹配(不区分大小写) 空 普通匹配(这里没有符号,即 location /path) - 语法规则例子:
- 例子1:
location /match { return 200 'Prefix match: will match everything that starting with /match'; } location ~* /match[0-9] { return 200 'Case insensitive regex match'; } location ~ /MATCH[0-9] { return 200 'Case sensitive regex match'; } location ^~ /match0 { return 200 'Preferential match'; } location = /match { return 200 'Exact match'; } : - 例子2:
location = / { # 精确匹配 / ,主机名后面不能带任何字符串 } location ^~ /images/ { # 匹配任何以 /images/ 开头的地址,匹配符合以后,停止往下搜索正则,采用这一条。 } location ~ /documents/Xyz { # 匹配任何以 /documents/Xyz 开头的地址,匹配符合以后,还要继续往下搜索 # 只有后面的正则表达式没有匹配到时,这一条才会采用这一条 } location ~* \.(gif|jpg|jpeg)$ { # 匹配所有以 gif,jpg或jpeg 结尾的请求 } location /documents/ { # 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索 # 只有后面的正则表达式没有匹配到时,这一条才会采用这一条 } location / { # 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求 # 但是正则和最长字符串会优先匹配 } - 例子1:
- 当配置的
location比较多的时候,需要考虑以上语法的优先执行顺序。- 匹配优先级
(location=) > (location完整路径) > (location^~路径) > (location~,~*从上向下正则顺序,匹配在最后一条终止) > (location 部分起始路径) > (/) - 匹配规则:
- 精准匹配命中时,停止location
- 一般匹配(普通和非正则)命中时,对比所有命中的一般匹配,选出最长的一条
- 如果最长的那一条为非正则匹配,直接匹配此条,停止location
- 如果最长的那一条为普通匹配,继续尝试正则location(以上至此都不存在代码顺序)
- 按代码顺序执行正则匹配,当第一条正则location命中时,停止location
- 匹配优先级
- 语法规则:
- 【问】Nginx的三种负载均衡的策略?
Nginx的三种负载均衡的策略轮询:将客户端发起请求,平均分配给每一台服务器
权重:会将客户端的请求,根据服务器的权重值不同,分配不同的数量。
ip_hash:基于发起请求的客户端的ip地址不同,他始终会将请求发送到指定的服务器上就是说如果这个客户端的请求的ip地址不变,那么处理请求的服务器将一直是同一个。- 轮询配置:配置
upstream daili_server,并在匹配路径时进行代理转发。upstream daili_server{ server localhost:8080; #服务器IP或域名 server localhost:8081; #服务器IP或域名 } server { listen 80; listen [::]:80; server_name localhost; location / { proxy_pass http://daili_server/; #负载均衡 } } - 权重配置:
upstream daili_server{ server localhost:8080 weight=10; #服务器IP或域名 server localhost:8081 weight=2; #服务器IP或域名 } server { listen 80; listen [::]:80; server_name localhost; location / { proxy_pass http://daili_server/; #负载均衡 } } ip_hash配置:upstream daili_server{ ip_hash; server localhost:8080; #服务器IP或域名 server localhost:8081; #服务器IP或域名 } server { listen 80; listen [::]:80; server_name localhost; location / { proxy_pass http://daili_server/; #负载均衡 } }
- 【问】Nginx如何实现动静资源分离
Nginx动静分离可以提高用户访问静态代码的速度,降低对后台应用访问:我们将静态资源放到nginx中,动态资源转发到tomcat服务器中。Nginx的并发能力公式:worker_processes * worker_connections / 4|2= Nginx最终的并发能力,即动态资源需要/4,静态资源只需要/2。- 动静资源分离配置:
动态资源代理:
静态资源代理:location / { proxy_pass 路径; }location / { root 静态资源路径; index 默认访问路径下的什么资源; autoindex on;#可以不写,写了则代表展示静态资源的全部内容,以列表的形式展开 }
12、Dubbo
- 【问】为什么要用 Dubbo?
- 【问】Dubbo 的整体架构设计有哪些分层?
- 【问】默认使用的是什么通信框架,还有别的选择吗?
- 【问】服务调用是阻塞的吗?
- 【问】一般使用什么注册中心?还有别的选择吗?
- 【问】默认使用什么序列化框架,你知道的还有哪些?
- 【问】服务提供者能实现失效踢出是什么原理?
- 【问】服务上线怎么不影响旧版本?
- 【问】如何解决服务调用链过长的问题?
- 【问】说说核心的配置有哪些?
- 【问】Dubbo 推荐用什么协议?
- 【问】同一个服务多个注册的情况下可以直连某一个服务吗?
- 【问】画一画服务注册与发现的流程图?
- 【问】Dubbo 集群容错有几种方案?
- 【问】Dubbo 服务降级,失败重试怎么做?
- 【问】Dubbo 使用过程中都遇到了些什么问题?
- 【问】Dubbo Monitor 实现原理?
- 【问】Dubbo 用到哪些设计模式?
- 【问】Dubbo 配置文件是如何加载到 Spring 中的?
- 【问】Dubbo SPI 和 Java SPI 区别?
- 【问】Dubbo 支持分布式事务吗?
- 【问】Dubbo 可以对结果进行缓存吗?
- 【问】服务上线怎么兼容旧版本?
- 【问】Dubbo 必须依赖的包有哪些?
- 【问】Dubbo telnet 命令能做什么?
- 【问】Dubbo 支持服务降级吗?
- 【问】Dubbo 如何优雅停机?
- 【问】Dubbo 和 Dubbox 之间的区别?
- 【问】Dubbo 和 Spring Cloud 的区别?
- 【问】你还了解别的分布式框架吗?
13、Nacos
-
【问】Nacos架构图由哪几部分组成(provider,consumer,Name Server(Virtual IP),Nacos Server(OpenAPI),参考Nacos 为什么这么强?,微服务:注册中心ZooKeeper、Eureka、Consul 、Nacos对比
-
服务注册中心本质上是为了解耦服务提供者和服务消费者(观察者模式)。对于任何一个微服务,原则上都应存在或者支持多个提供者,这是由微服务的分布式属性决定的。更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,也是无法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心。
-
nacos架构图:

其中分为这么几个模块:
-
Provider APP:服务提供者。
-
Consumer APP:服务消费者。
-
Name Server:通过
Virtual IP或者DNS的方式实现Nacos高可用集群的服务路由。 -
Nacos Server:Nacos服务提供者。
-
OpenAPI:功能访问入口(服务注册和服务发现)。 -
Config Service、Naming Service:Nacos提供的配置服务、名字服务模块。 -
Consistency Protocol:一致性协议,用来实现Nacos集群节点的数据同步,使用Raft算法实现。
-
其中包含:
- Nacos Console :Nacos控制台。
-
-
小总结:
-
服务提供者通过
VIP(Virtual IP)访问Nacos Server高可用集群 -
基于
OpenAPI完成服务的注册和服务的查询。 -
Nacos Server的底层则通过数据一致性算法(Raft)来完成节点的数据同步。
-
-
-
【问】Nacos服务的发现发生在什么时候?,参考Nacos 为什么这么强?
- 例如在微服务发生远程接口调用的时候。一般我们在使用
OpenFeign进行远程接口调用时,都需要用到对应的微服务名称,而这个名称就是用来进行服务发现的。
- 例如在微服务发生远程接口调用的时候。一般我们在使用
-
【问】Nacos实现原理(使用
registerInstance()完成服务注册(前提是健康检查要通过);openFeign将serviceId传入到selectInstance(),通过subscribe决定读取本地注册表还是Nacos注册中心,最后从本地的serviceInfoMap获取serviceInfo),参考Nacos 为什么这么强?-
1)服务注册和服务发现的实现原理图如下:

首先,服务注册的功能体现在:
-
服务实例启动时注册到服务注册表、关闭时则注销(服务注册)。
-
服务消费者可以通过查询服务注册表来获得可用的实例(服务发现)。
-
服务注册中心需要调用服务实例的健康检查API来验证其是否可以正确的处理请求(健康检查)。
-
-
2)
Nacos服务注册流程:-
服务(项目)启动时,根据
spring-cloud-commons中spring.factories的配置,自动装配了类AutoServiceRegistrationAutoConfiguration。 -
AutoServiceRegistrationAutoConfiguration类中注入了类AutoServiceRegistration,其最终实现子类实现了Spring的监听器。 -
根据监听器,执行了服务注册方法。而这个服务注册方法则是调用了
NacosServiceRegistry的register()方法。 -
该方法主要调用的是Nacos Client SDK中的
NamingService下的registerInstance()方法完成服务的注册。registerInstance()方法主要做两件事:-
服务实例的健康监测
this.beatReactor.addBeatInfo(); -
实例的注册
this.serverProxy.registerService();
-
-
通过
schedule()方法定时的发送数据包,检测实例的健康。 -
若健康监测通过,调用
registerService()方法,通过OpenAPI方式执行服务注册,其中将实例Instance的相关信息存储到HashMap中。
-
-
3)
Nacos服务发现的流程:-
以调用远程接口(
OpenFeign)为例,当执行远程调用时,需要经过服务发现的过程。 -
服务发现先执行
NacosServerList类中的getServers()方法,根据远程调用接口上@FeignClient中的属性作为serviceId,传入NacosNamingService.selectInstances()方法中进行调用。 -
根据
subscribe的值来决定服务是从本地注册列表中获取还是从Nacos服务端中获取。 -
以本地注册列表为例,通过调用
HostReactor.getServiceInfo()来获取服务的信息(serviceInfo),Nacos本地注册列表由3个Map来共同维护:-
本地Map–>
serviceInfoMap, -
更新Map–>
updatingMap -
异步更新结果Map–>
futureMap
最终的结果从
serviceInfoMap当中获取。-
HostReactor类中的getServiceInfo()方法通过this.scheduleUpdateIfAbsent()方法和updateServiceNow()方法实现服务的定时更新和立刻更新。 -
而对于
scheduleUpdateIfAbsent()方法,则通过线程池来进行异步的更新,将回调的结果(Future)保存到futureMap中,并且发生提交线程任务时,还负责更新本地注册列表中的数据。
-
-
-
4)Note:Nacos有个好处,就是当一个服务挂了之后,短时间内不会造成影响,因为有个本地注册列表,在服务不更新的情况下,服务还能够正常的运转,其原因如下:
-
Nacos的服务发现,一般是通过订阅的形式来获取服务数据。而通过订阅的方式,则是从本地的服务注册列表中获取(可以理解为缓存)。相反,如果不订阅,那么服务的信息将会从
Nacos服务端获取,这时候就需要对应的服务是健康的。(宕机就不能使用了) -
在代码设计上,通过Map来存放实例数据,key为实例名称,value为实例的相关信息数据(
ServiceInfo对象)。
-
-
-
【问】Nacos与其他服务注册中心ZooKeeper,Eureka,以及Consul的区别(一致性协议,健康检查,负载均衡策略,雪崩保护,访问协议等,参考微服务:注册中心ZooKeeper、Eureka、Consul 、Nacos对比
Nacos Eureka Consul CoreDNS Zookeeper 一致性协议 CP或AP AP CP — CP 健康检查 TCP/HTTP/MYSQL/Client Beat Client Beat TCP/HTTP/gRPC/Cmd — Keep Alive 负载均衡策略 权重/metadata/Selector Ribbon Fabio RoundRobin — 雪崩保护 有 有 无 无 无 自动注销实例 支持 支持 支持 不支持 支持 访问协议 HTTP/DNS HTTP HTTP/DNS DNS TCP 监听支持 支持 支持 支持 不支持 支持 多数据中心 支持 支持 支持 不支持 不支持 跨注册中心同步 支持 不支持 支持 不支持 不支持 SpringCloud集成 支持 支持 支持 不支持 支持 Dubbo集成 支持 不支持 支持 不支持 支持 K8S集成 支持 不支持 支持 支持 不支持 -
[【问】Nacos和Eureka的区别(CAP理论,连接方式,服务异常剔除,实例监听界面,自我保护机制,参考详解Nacos和Eureka的区别
-
CAP理论:
-
eureka只支持AP -
nacos支持CP和AP两种:nacos是根据配置识别CP或AP模式,如果注册Nacos的client节点注册时是ephemeral=true即为临时节点, 那么Naocs集群对这个client节点效果就是AP,反之则是CP,即不是临时节点。#false为永久实例,true表示临时实例开启,注册为临时实例 spring.cloud.nacos.discovery.ephemeral=true
-
-
连接方式:
nacos使用的是netty和服务直接进行连接,属于长连接eureka是使用定时发送和服务进行联系,属于短连接
-
服务异常剔除:
-
eureka:
Eureka client在默认情况每隔30s想Eureka Server发送一次心跳,当Eureka Server在默认连续90s秒的情况下没有收到心跳, 会把Eureka client 从注册表中剔除,在由Eureka-Server 60秒的清除间隔,把Eureka client 给下线EurekaInstanceConfigBean类下 private int leaseRenewalIntervalInSeconds = 30; //心跳间隔30s private int leaseExpirationDurationInSeconds = 90; //默认90s没有收到心跳从注册表中剔除 EurekaServerConfigBean 类下 private long evictionIntervalTimerInMs = 60000L; //异常服务剔除下线时间间隔也就是在极端情况下Eureka 服务 从异常到剔除在到完全不接受请求可能需要 30s+90s+60s=3分钟左右(还是未考虑ribbon缓存情况下)
- nacos:
nacos client通过心跳上报方式告诉 nacos注册中心健康状态,默认心跳间隔5秒,nacos会在超过15秒未收到心跳后将实例设置为不健康状态,可以正常接收到请求,超过30秒nacos将实例删除,不会再接收请求。
- nacos:
-
-
操作实例方式:
-
eureka:仅提供了实例列表,实例的状态,错误信息,相比于nacos过于简单
-
nacos:提供了
nacos console可视化控制界面,可以对实例列表进行监听,对实例进行上下线,权重的配置,并且config server提供了对服务实例提供配置中心,且可以对配置进行CRUD,版本管理。
-
-
自我保护机制:
-
相同点:保护阈值都是个比例,0-1 范围,表示健康的 instance 占全部instance 的比例。
-
不同点:
-
1)保护方式不同:
-
Eureka保护方式:当在短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下,Eureka Server不会剔除任何的微服务,等到正常后,再退出自我保护机制。自我保护开关(
eureka.server.enable-self-preservation: false) -
Nacos保护方式:当域名健康实例 (Instance) 占总服务实例(Instance) 的比例小于阈值时,无论实例 (Instance) 是否健康,都会将这个实例 (Instance) 返回给客户端。这样做虽然损失了一部分流量,但是保证了集群的剩余健康实例 (Instance) 能正常工作。
-
-
2)范围不同:
Nacos 的阈值是针对某个具体 Service的,而不是针对所有服务的。但 Eureka的自我保护阈值是针对所有服务的。
-
-
-