【Python】Risk Factors
kaggle discussion - Adding Risk Factors
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import matplotlib.pyplot as plt
Load data and look at distributions of features
train_df = pd.read_csv('/kaggle/input/playground-series-s3e3/train.csv')
train_df['NumCompaniesWorked'] = train_df['NumCompaniesWorked'].replace(0, 1)
train_df.head()
| id | Age | BusinessTravel | DailyRate | Department | DistanceFromHome | Education | EducationField | EmployeeCount | EnvironmentSatisfaction | ... | StandardHours | StockOptionLevel | TotalWorkingYears | TrainingTimesLastYear | WorkLifeBalance | YearsAtCompany | YearsInCurrentRole | YearsSinceLastPromotion | YearsWithCurrManager | Attrition | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 36 | Travel_Frequently | 599 | Research & Development | 24 | 3 | Medical | 1 | 4 | ... | 80 | 1 | 10 | 2 | 3 | 10 | 0 | 7 | 8 | 0 |
| 1 | 1 | 35 | Travel_Rarely | 921 | Sales | 8 | 3 | Other | 1 | 1 | ... | 80 | 1 | 4 | 3 | 3 | 4 | 2 | 0 | 3 | 0 |
| 2 | 2 | 32 | Travel_Rarely | 718 | Sales | 26 | 3 | Marketing | 1 | 3 | ... | 80 | 2 | 4 | 3 | 3 | 3 | 2 | 1 | 2 | 0 |
| 3 | 3 | 38 | Travel_Rarely | 1488 | Research & Development | 2 | 3 | Medical | 1 | 3 | ... | 80 | 0 | 15 | 1 | 1 | 6 | 0 | 0 | 2 | 0 |
| 4 | 4 | 50 | Travel_Rarely | 1017 | Research & Development | 5 | 4 | Medical | 1 | 2 | ... | 80 | 0 | 31 | 0 | 3 | 31 | 14 | 4 | 10 | 1 |
5 rows × 35 columns
Additional features
train_df['AverageTenure'] = train_df["TotalWorkingYears"] / train_df["NumCompaniesWorked"]
train_df['YearsAboveAvgTenure'] = train_df['YearsAtCompany'] - train_df['AverageTenure']
train_df['JobHopper'] = ((train_df["NumCompaniesWorked"] > 2) & (train_df["AverageTenure"] < 2.0)).astype(int)
train_df['MonthlyIncome_Age'] = train_df['MonthlyIncome'] / train_df['Age']
Visualizing Risk Factors
See How are risk factors determined? and Visualizing risk factors for stroke from the previous competition.
sns.set_style("whitegrid", {"xtick.bottom" : True, "ytick.left" : True})
df_train0 = train_df[train_df["Attrition"] == 0]
df_train1 = train_df[train_df["Attrition"] == 1]
features = ["Age", "HourlyRate", "DistanceFromHome", "AverageTenure", "YearsAboveAvgTenure", "JobHopper",
"YearsAtCompany", "YearsInCurrentRole", "YearsSinceLastPromotion", "YearsWithCurrManager",
"MonthlyIncome_Age"]
for feature in features:
plt.figure(figsize=(12, 6))
'''
核密度估计(kernel density estimation)
'''
sns.kdeplot(df_train0[feature], shade=True, label="0")
sns.kdeplot(df_train1[feature], shade=True, label="1")
plt.title("{}".format(feature), fontsize=15)
plt.ylabel("y")
plt.xlabel("x")
plt.tight_layout()
plt.savefig("distributions_%s.png" % feature, dpi=150)
plt.legend()
plt.show()
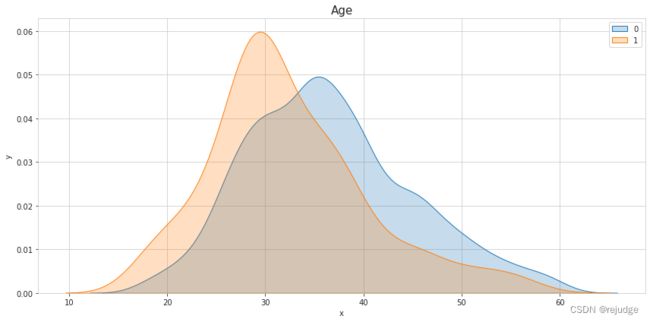
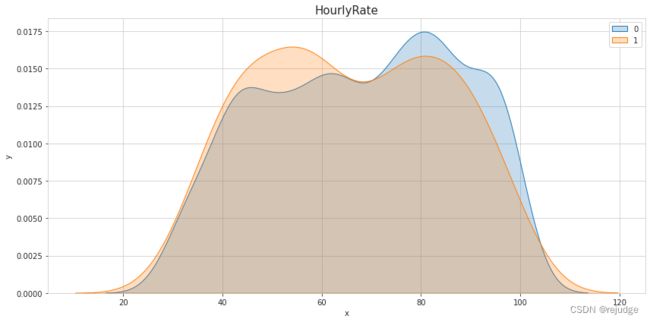

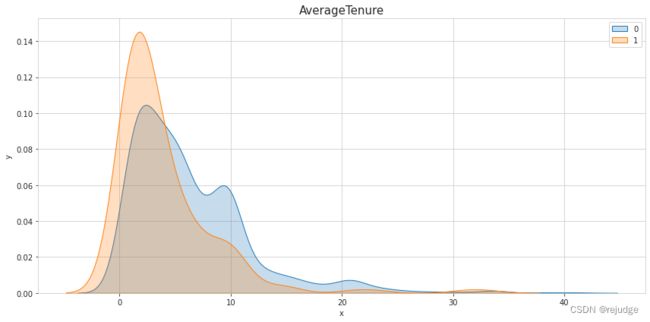

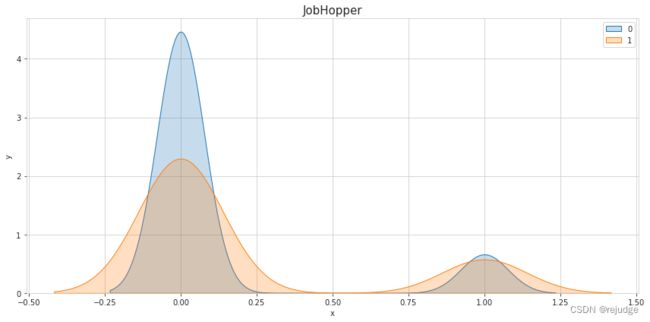

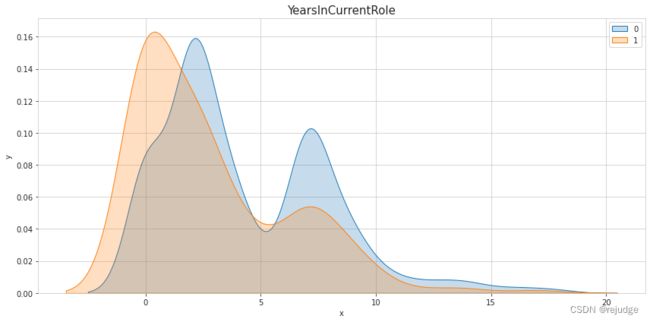
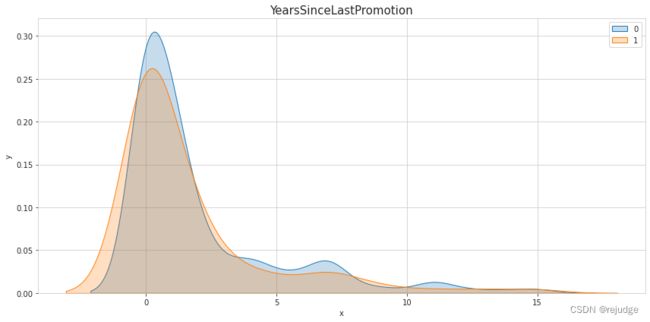 s
s

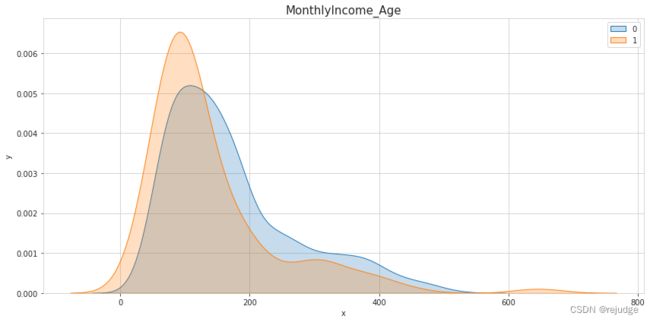
Insights:
- It looks like we can set risk factors for
AgeandHourlyRate. - There is a small increased risk with
DistanceFromHome. - There is a risk involved with all of the features
YearsAtCompany,YearsInCurrentRole,YearsWithCurrManager, but the last two might just correlate highly toYearsAtCompany. - A low
MonthlyIncome/Ageratio looks like it might be a risk factor.
df["Age_risk"] = (df["Age"] < 34).astype(int)
df["HourlyRate_risk"] = (df["HourlyRate"] < 60).astype(int)
df["Distance_risk"] = (df["DistanceFromHome"] >= 20).astype(int)
df["YearsAtCo_risk"] = (df["YearsAtCompany"] < 4).astype(int)
df["AttritionRisk"] = df["Age_risk"] + df["HourlyRate_risk"] + df["Distance_risk"] + df["YearsAtCo_risk"]
最终决胜代码是在一个baseline上添加了这些:
kaggle discussion - 1st place. That was unexpected…
df['MonthlyIncome/Age'] = df['MonthlyIncome'] / df['Age']
df["Age_risk"] = (df["Age"] < 34).astype(int)
df["HourlyRate_risk"] = (df["HourlyRate"] < 60).astype(int)
df["Distance_risk"] = (df["DistanceFromHome"] >= 20).astype(int)
df["YearsAtCo_risk"] = (df["YearsAtCompany"] < 4).astype(int)
df['NumCompaniesWorked'] = df['NumCompaniesWorked'].replace(0, 1)
df['AverageTenure'] = df["TotalWorkingYears"] / df["NumCompaniesWorked"]
# df['YearsAboveAvgTenure'] = df['YearsAtCompany'] - df['AverageTenure']
df['JobHopper'] = ((df["NumCompaniesWorked"] > 2) & (df["AverageTenure"] < 2.0)).astype(int)
df["AttritionRisk"] = df["Age_risk"] + df["HourlyRate_risk"] + df["Distance_risk"] + df["YearsAtCo_risk"] + df['JobHopper']