SpringBoot根据模板生成Word文件,然后Word转PDF
1.在pom文件中导入相关依赖
<!--根据模板生成Word 需要依赖 开始-->
<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-base</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jcommon</artifactId>
<version>1.0.24</version>
</dependency>
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jfreechart</artifactId>
<version>1.5.0</version>
</dependency>
<!--根据模板生成Word 需要依赖 结束-->
<!--word转pdf 需要依赖 开始-->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.1.2</version>
<exclusions>
<!--生成word的依赖包里 有该依赖了,所以剔除-->
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-export-fo</artifactId>
<version>6.0.0</version>
</dependency>
<!--word转pdf 需要依赖 结束-->
2.创建Word模板文件test.docx,设置属性,放入到项目中。

test.docx模板用{{姓名}}符号包起来。

3.新建工具类PdfUtil3
import cn.afterturn.easypoi.word.WordExportUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.docx4j.Docx4J;
import org.docx4j.convert.out.FOSettings;
import org.docx4j.fonts.IdentityPlusMapper;
import org.docx4j.fonts.Mapper;
import org.docx4j.fonts.PhysicalFonts;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.springframework.util.Assert;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.util.HashMap;
import java.util.Map;
@Slf4j
public class PdfUtil3 {
private static String separator = File.separator;//文件夹路径分格符
/**
* 生成word 只支持docx
*
* @param templatePath 模板文件路径
* @param temDir 生成文件的目录
* @param fileName 生成文件名
* @param params 参数
*/
public static String exportWord(String templatePath, String temDir, String fileName, Map<String, Object> params) {
Assert.notNull(templatePath, "模板路径不能为空");
Assert.notNull(temDir, "临时文件路径不能为空");
Assert.notNull(fileName, "导出文件名不能为空");
Assert.isTrue(fileName.endsWith(".docx"), "word导出请使用docx格式");
if (!temDir.endsWith("/")) {
temDir = temDir + File.separator;
}
File dir = new File(temDir);
if (!dir.exists()) {
dir.mkdirs();
}
String tmpPath = "";
try {
XWPFDocument doc = WordExportUtil.exportWord07(templatePath, params);
tmpPath = temDir + fileName;
FileOutputStream fos = new FileOutputStream(tmpPath);
doc.write(fos);
fos.flush();
fos.close();
} catch (Exception e) {
//e.printStackTrace();
}
return tmpPath;
}
public static void downloadFile(HttpServletResponse response,String ID, String NAME) throws UnsupportedEncodingException {
String downloadFilePath = "swxxPDF/"+NAME+ID+"事务信息表.pdf";//被下载的文件在服务器中的路径,
String fileName =NAME+"的事务信息表.pdf";//被下载文件的名称
File file = new File(downloadFilePath);
if (file.exists()) {
response.setContentType("application/force-download");// 设置强制下载不打开
// response.addHeader("Content-Disposition", "attachment;fileName=" + fileName);
//中文名称下载
response.setHeader("Content-Disposition",
"attachment;filename=" + URLEncoder.encode(fileName, "UTF-8"));
byte[] buffer = new byte[1024];
FileInputStream fis = null;
BufferedInputStream bis = null;
OutputStream outputStream = null;
try {
fis = new FileInputStream(file);
bis = new BufferedInputStream(fis);
outputStream = response.getOutputStream();
int i = bis.read(buffer);
while (i != -1) {
outputStream.write(buffer, 0, i);
i = bis.read(buffer);
}
outputStream.flush();
} catch (Exception e) {
//e.printStackTrace();
} finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
//e.printStackTrace();
}
}
if (bis != null) {
try {
bis.close();
} catch (IOException e) {
//e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
//e.printStackTrace();
}
}
}
}
}
/**
* word(docx)转pdf
*
* @param wordPath docx文件路径
* @return
*/
public static String convertDocx2Pdf(String wordPath,String ID,String NAME) {
OutputStream os = null;
InputStream is = null;
try {
is = new FileInputStream(new File(wordPath));
WordprocessingMLPackage mlPackage = WordprocessingMLPackage.load(is);
Mapper fontMapper = new IdentityPlusMapper();
fontMapper.put("隶书", PhysicalFonts.get("LiSu"));
fontMapper.put("宋体", PhysicalFonts.get("SimSun"));
fontMapper.put("微软雅黑", PhysicalFonts.get("Microsoft Yahei"));
fontMapper.put("黑体", PhysicalFonts.get("SimHei"));
fontMapper.put("楷体", PhysicalFonts.get("KaiTi"));
fontMapper.put("新宋体", PhysicalFonts.get("NSimSun"));
fontMapper.put("华文行楷", PhysicalFonts.get("STXingkai"));
fontMapper.put("华文仿宋", PhysicalFonts.get("STFangsong"));
fontMapper.put("宋体扩展", PhysicalFonts.get("simsun-extB"));
fontMapper.put("仿宋", PhysicalFonts.get("FangSong"));
fontMapper.put("仿宋_GB2312", PhysicalFonts.get("FangSong_GB2312"));
fontMapper.put("幼圆", PhysicalFonts.get("YouYuan"));
fontMapper.put("华文宋体", PhysicalFonts.get("STSong"));
fontMapper.put("华文中宋", PhysicalFonts.get("STZhongsong"));
mlPackage.setFontMapper(fontMapper);
//输出pdf文件路径和名称
// String fileName = "pdfNoMark_" + System.currentTimeMillis() + ".pdf";
// String fileName = "事务信息表.pdf";
String fileName =NAME+ID+"事务信息表.pdf";
// String pdfNoMarkPath = System.getProperty("java.io.tmpdir").replaceAll(separator + "$", "") + separator + fileName;
String pdfNoMarkPath = "swxxPDF/" + separator + fileName;
os = new java.io.FileOutputStream(pdfNoMarkPath);
//docx4j docx转pdf
FOSettings foSettings = Docx4J.createFOSettings();
foSettings.setWmlPackage(mlPackage);
Docx4J.toFO(foSettings, os, Docx4J.FLAG_EXPORT_PREFER_XSL);
is.close();//关闭输入流
os.close();//关闭输出流
return "";
} catch (Exception e) {
//e.printStackTrace();
try {
if (is != null) {
is.close();
}
if (os != null) {
os.close();
}
} catch (Exception ex) {
ex.printStackTrace();
}
} finally {
File file = new File(wordPath);
if (file != null && file.isFile() && file.exists()) {
file.delete();
}
}
return "";
}
}
4.Conttroller
@ApiResponses({
@ApiResponse(code = 200, message = "成功", response = Activity.class)
})
@ApiOperation(value = "导出Word的PDF")
@GetMapping(value = "/exportWordPDF", produces = "application/octet-stream")
public void exportWord(@ApiIgnore MyHttpServletRequestWrapper request, HttpServletResponse response, String affairid) throws UnsupportedEncodingException, UnsupportedEncodingException {
SysUserVO user = request.getUser();
String ID = user.getSysUserId();
Map<String, Object> map = new HashMap<>();
//数据库查询字段数据
List<Map<String, Object>> listMessageDetail = activityService.getlList(affairid);
String sysuserrealname = " ";
String sysusercertificatetype = " ";
if (listMessageDetail.size() > 0) {
if (listMessageDetail.get(0).get("sysuserrealname") != null && listMessageDetail.get(0).get("sysuserrealname").toString().length() != 0) {
sysuserrealname = listMessageDetail.get(0).get("sysuserrealname").toString();
}
if (listMessageDetail.get(0).get("sysusercertificatetype") != null && listMessageDetail.get(0).get("sysusercertificatetype").toString().length() != 0) {
sysusercertificatetype = listMessageDetail.get(0).get("sysusercertificatetype").toString();
}
}
map.put("姓名", sysuserrealname);
map.put("证件类型", sysusercertificatetype);
String filepath = PdfUtil3.exportWord("templates/test.docx", "swxxPDF/", "生成文件.docx", map);
PdfUtil3.convertDocx2Pdf(filepath, ID, sysuserrealname);
PdfUtil3.downloadFile(response, ID, sysuserrealname);
}
4.Excel循环输出

格式:{{$fe:maplist t.时间 t.操作人 t.联系方式 t.操作内容}}
代码查询放入maplist
List<Map<String, String>> listMapA = new ArrayList<Map<String, String>>();
//数据库查询数据
List<Map<String, Object>> listMap = activityService.getlLisbllc(affairid);
for (int i = 0; i < listMap.size(); i++) {
String flowlogtime = " ";
String sysuserrealnameczry = " ";
String sysuserphoneczry = " ";
String flowlogcontentczry = " ";
if (listMap.get(i).get("flowlogtime") != null && listMap.get(i).get("flowlogtime").toString().length() != 0) {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("YYYY-MM-dd HH:mm:ss");
flowlogtime = simpleDateFormat.format(listMap.get(i).get("flowlogtime"));
}
if (listMap.get(i).get("sysuserrealnameczry") != null && listMap.get(i).get("sysuserrealnameczry").toString().length() != 0) {
sysuserrealnameczry = listMap.get(i).get("sysuserrealnameczry").toString();
}
if (listMap.get(i).get("sysuserphoneczry") != null && listMap.get(i).get("sysuserphoneczry").toString().length() != 0) {
sysuserphoneczry = listMap.get(i).get("sysuserphoneczry").toString();
}
if (listMap.get(i).get("flowlogcontentczry") != null && listMap.get(i).get("flowlogcontentczry").toString().length() != 0) {
flowlogcontentczry = listMap.get(i).get("flowlogcontentczry").toString();
}
Map<String, String> lm = new HashMap<String, String>();
lm.put("时间", flowlogtime);
lm.put("操作人", sysuserrealnameczry);
lm.put("联系方式", sysuserphoneczry);
lm.put("操作内容", flowlogcontentczry);
listMapA.add(lm);
}
map.put("maplist", listMapA);
map.put("姓名", sysuserrealname);
map.put("证件类型", sysusercertificatetype);
String filepath = PdfUtil3.exportWord("templates/test.docx", "swxxPDF/", "生成文件.docx", map);
PdfUtil3.convertDocx2Pdf(filepath, ID, sysuserrealname);
PdfUtil3.downloadFile(response, ID, sysuserrealname)
注意事项
在通过easypoi导出word模板和通过docx4j将导出的word转换成pdf的过程中会出现很多问题,下面将介绍比较重要的几个注意事项。
1.遍历指令的使用
假设有如下的指令,其中一行遍历写在表格中,另一行遍历写在表格外

导出的结果如下,会发现只有表格内的指令生效了

因为easypoi本身是用来导出excel表格的,所以遍历的指令是没有兼容word模板的。
表格中的遍历指令

可以发现表格最后一列应有的数据不见了,而且可以推测数据是被覆盖而不是没有插入。
但是如果在遍历指令的下一行表格中插入数据
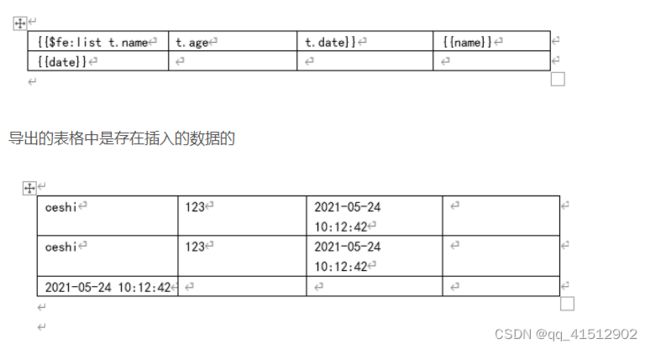
可以得出结论表格中如果出现遍历数据,那么同一行的其他数据会被覆盖(包括被空白覆盖)。如果遍历的指令没有写在第一列也是无法生效的。
