[23] HeadSculpt: Crafting 3D Head Avatars with Text
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第1张图片](http://img.e-com-net.com/image/info8/2bc8e769b14b4ac1b2ec0f22a43381e6.jpg)
paper | project
- 本文主要想解决:1)生成图像的不连续问题;2)3D修改中的保ID问题。
- 针对第一个问题,本文引入了Landmark-based ControlNet特征图和
的text embedding; - 针对第二个问题,本文引入了原描述词的Instruct-Pix2Pix特征图。
目录
摘要
近期工作
Text-to-3D generation
3D head modeling and creation
方法
Preliminaries
3D-Prior-driven score distillation
Landmark-based ControlNet
Enhanced view-dependent prompt via textual inversion
Identity-aware editing score distillation
Experiments
Qualitative evalutions
Ablation Study
摘要
- text-guided 3D generative methods发展迅速,但是现有方法无法创造高保真的3D head avatars,具体来说包含两个问题:1)缺少3D头像先验;2)无法细粒度修改;
- 为解决上述问题,本文提出HeadSculpt,通过文本提示词craft(生成和修改)3D head avatars:1)通过landmark-based ControlNet和textual inversion,找到表示头后的texural embedding,做到3D-consistent head avatar generations;2)提出identity-aware editing score distillation策略,在保ID的情况下,根据提示词修改人像。
近期工作
Text-to-3D generation
- DreamFusion、Magic3D、Latent-NeRF、FramAvatar、Fantasia3D、3DFuse
3D head modeling and creation
- statistical mesh-based models(3DMM、FLAME)、T2P、Rodin、DreamFace。上述方法需要大量数据监督训练,并且很难生成non-human-like avatars;
方法
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第2张图片](http://img.e-com-net.com/image/info8/8c5ce1d5a8ce494d9f32399279768667.jpg)
- 包含粗回归和细回归两步,粗回归是基于FLAME-based NeRF学习,细回归则是基于DMTET学习。
Preliminaries
Score distillation sampling:DreamFusion提出的一种借助预训练text-to-2D diffusion model,训练NeRF的损失。该损失对NeRF的渲染图加噪,并通过预训练文生图大模型预测噪声,训练损失为(预测噪声 - 添加噪声)对NeRF求导。该损失的优点在于,不需要3D数据集。
![]()
3D scene optimization:NeRF和DMTET
3D prior-based NeRF:DreamAvatar中提出一中density-residual setup,用于增强生成3D NeRF的鲁棒性。对于给定点x,其密度和颜色可以根据prior-based density field求的:
![]()
其中,gama是hash-grid frequency encoder,sigma和c是密度和RGB颜色。sigma_hat是从3D形状先验(FLAME模型)中求得:
![]()
最后通过volume rendering,从隐式表达中渲染出图片:
![]()
3D-Prior-driven score distillation
现有模型主要存在两个问题:1)不同视角的生成图片不连续;2)缺少3D级别的控制幸好,导致模型很难确定前脸、头后等。为解决这些问题,本文在diffusion model中引入了3D head priors。
Landmark-based ControlNet
引入2D Landmark maps作为ControlNet的控制信号。具体来说,本文引入ControlNet C。对任意相机位姿,从FLAME中提取出人脸关键点,并得到landmark map。landmark map会送入ControlNet,其输出特征会被加到diffusion U-Net的中间特征中:
![]()
Enhanced view-dependent prompt via textual inversion
Landmark map可以一定程度缓解不同视角渲染图片的一致性问题。但是3D关键点在脸前和头后视角存在歧义性。
为解决头后的生成问题,现有方法提出了view-dependent text("front view", "side view" 或"back view")。
本文提出学习文本编码:
![]()
Identity-aware editing score distillation
为修改3D场景,现有方法会根据提示词fine-tune 3D场景。但这类方法直接应用在3D人像上,会导致ID丢失和外观变化。
为此,本文提出identity-aware editing score distillation (IESD)。具体来说,本文引入ControlNet-based InstructPix2Pix I。对于任意提示词y和编辑指引y_hat,并分别送入两个ControlNets,得到两个预测噪声,两个噪声通过超参数w_e合并在一起:
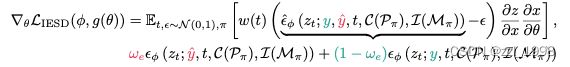
Experiments
Implementation details:粗回归是64 x 64,细回归是512 x 512。前者需要7000 iter,后者需要5000 iter。
Baseline methods:DreamFusion、Latent-NeRF、3DFue、Fantasia3D和DreamFace
Qualitative evalutions
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第3张图片](http://img.e-com-net.com/image/info8/d9e5f04557044b5d91820d851ccb8958.jpg)
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第4张图片](http://img.e-com-net.com/image/info8/47f9e92fbcd14c08a73d14a20c9d2289.jpg)
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第5张图片](http://img.e-com-net.com/image/info8/f881054ccd884348af1b2255fab73ce3.jpg)
Ablation Study
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第6张图片](http://img.e-com-net.com/image/info8/8a1dc220f5cd4ec7aa2c5bfdafaa4e1a.jpg)
![[23] HeadSculpt: Crafting 3D Head Avatars with Text_第7张图片](http://img.e-com-net.com/image/info8/ca5bd675d31e4dec92bb53b58536546e.jpg)