JVM(Java Virtual Machine)
哥几个来学 JVM 啦~~

目录
一、JVM 执行流程( JVM 是如何运行的?)
二、JVM 运行时数据区
1. 堆(线程共享)
2. Java 虚拟机栈(线程私有)
3. 本地方法栈(线程私有)
4. 程序计数器(线程私有)
5. 方法区(线程共享)
三、JVM 类加载(Class Loading)
(一)类加载过程
1. 加载(Loading)
2.连接
3. 初始化(Initialization)
(二)双亲委派模型
四、死亡对象的判断算法
1. 引用计数算法
2. 可达性分析
五、垃圾回收算法
1. 标记-清除算法
2. 复制算法
3.标记-整理算法
4. 分代算法
JVM (Java Virtual Machine)也就是 Java 虚拟机 。
虚拟机就是指通过软件模拟的具有完整硬件功能的、运行在一个完全隔离的环境中的完整计算机系统。
一、JVM 执行流程( JVM 是如何运行的?)
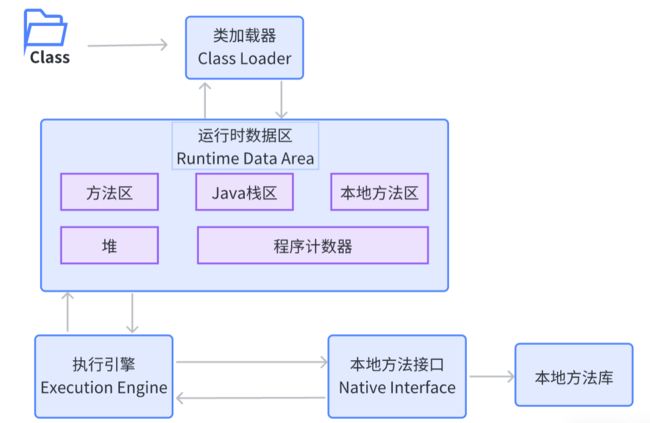
1. 程序在执行之前先要把 Java 代码转换成字节码 (class 文件),JVM 首先把字节码通过一定的方式 —— 类加载器 (ClassLoader)把文件加载到内存中运行时 数据区(Runtime Data Area)。
2. 但字节码文件是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器,也就是 JVM 的执行引擎 (Execution Engine)会将字节码翻译成底层系统指令再由 CPU 去执行。
3. 在执行的过程中,也需要调用其他语言的接口,如通过调用本地库接口 (Native Interface)来实现整个程序的运行。如上图所示:
二、JVM 运行时数据区
JVM 运行时数据区域也叫内存布局,它由以下五个部分组成:
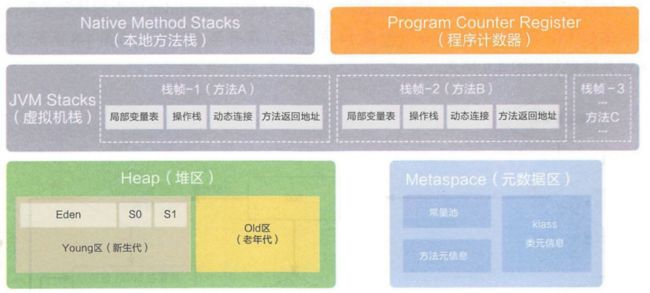
1. 堆(线程共享)
堆的作用:程序中创建的所有对象(对象实例、数组)都在保存在堆中。(只要是 new 出来的对象都是存储在堆中的)
2. Java 虚拟机栈(线程私有)
Java 虚拟机栈的作用:用于存储方法执行时的局部变量表、操作数栈、动态链接、方法出口等消息。每个方法在执行时都会创建一个 栈帧(Stack Frame)用于存储以上信息。因此 Java 虚拟机栈 是线程私有的。

① 局部变量表:用于存放方法参数和局部变量。
② 操作栈:每个方法都会生成一个先进后出的操作栈。
③ 动态链接:指向运行时常量池的方法引用。
④ 方法返回地址:PC 寄存器的地址。
什么是线程私有?
由于 JVM 的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,因此在任何一个确定的时刻,一个处理器都只会执行一条线程中的指令。因此为了切换线程后能恢复到正确的执行位置,每条线程都需要独立的程序计数器,各线程之间计数器互不影响,独立存储。我们把类似这类区域称之为 “线程私有” 的内存。
3. 本地方法栈(线程私有)
本地方法栈的作用:与 Java 虚拟机栈类似,用于存储本地方法的信息。
4. 程序计数器(线程私有)
程序计数器的作用:用来记录当前线程执行的行号的。
如果线程正在执行的是一个 Java 方法,这个计数器记录的正是执行的虚拟机字节码指令的地址;如果正在执行的是一个 Native(本地) 方法,这个计数器的值为空。
5. 方法区(线程共享)
方法区的作用:用来存储虚拟机加载的类信息、常亮、静态变量、即时编译器编译后的代码等数据。
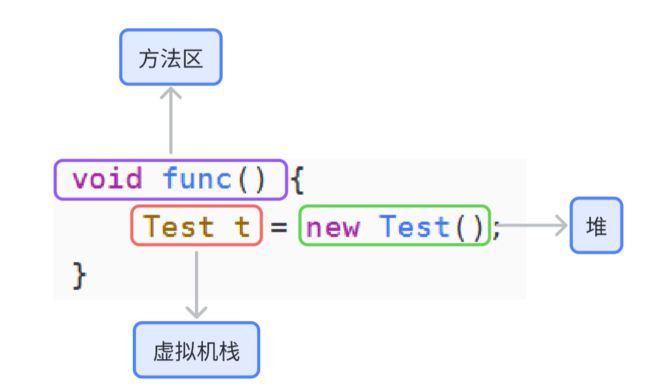
那么在了解完以上知识之后,我们来看一下以下代码:
void func() {
Test t = new Test();
}请指出 ![]() 、
、![]() 、
、![]() 分别处于什么 JVM 运行时数据区 的哪一部分:
分别处于什么 JVM 运行时数据区 的哪一部分:
三、JVM 类加载(Class Loading)
(一)类加载过程
对于一个类,它的生命周期是这样的:
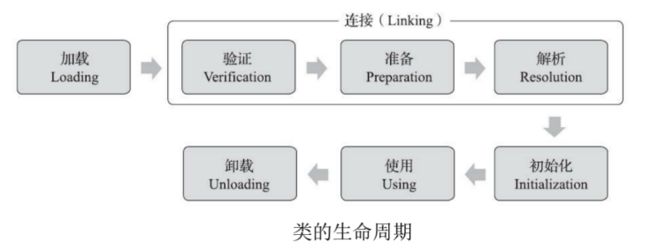
其中前 5 步是固定的顺序,并且也是类加载的过程。其中的 连接(Linking)里面分三步进行,因此对于类加载来说总共分为以下几个步骤:
1. 加载
2. 连接 :① 验证 ② 准备 ③ 解析
3.初始化
我来详细地拆分一下以上步骤:
1. 加载(Loading)
查找并加载类的二进制数据。这个过程可以通过类的全限定名来完成,也可以通过其他方式完成,比如使用 ClassLoader.loadClass() 方法。
在 加载(Loading)阶段,Java 虚拟机要完成以下三件事:
- 通过一个类的全限定名来获取定义此类的二进制字节流;
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构;
- 在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口。
注意:加载(Loading)只是 类加载(Class Loading)中的一个过程,它和 类加载(Class Loading)是不同的,不要弄混淆了~~
2.连接
① 验证(Verification):验证加载的类是否符合 Java 虚拟机规范,比如是否有正确的文件格式、是否有正确的访问权限等。
这一阶段的目的是为了确保 Class 文件的字节流中包含的信息符合 《Java虚拟机规范》的全部要求,确保这些信息被当做代码运行后不会危害虚拟机自身的安危。
验证选项:
- 文件格式验证
- 字节码验证
- 符号引用验证
- . . . . . .
② 准备(Preparation):为类的静态变量分配内存,并设置为初始值。
准备阶段是正式为类中定义的变量(即静态变量,被 static 修饰的变量)分配内存并设置类变量初始值阶段。
比如此时有这样一段代码:
public static int value = 123;它是初始化 value 的 int 值为 0,而非 123。
③ 解析(Resolution):将类中的符号引用转换为直接饮用。比如将类中的方法名转换为实际的内存地址。解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
3. 初始化(Initialization)
执行类的初始化代码,包括静态赋值和静态代码的执行,这个类如果有父类还要先加载父类。
(二)双亲委派模型
双亲委派模型是 Java 类加载器的一种工作机制。
它是指当一个类加载器要加载一个类时,它首先不会自己尝试加载这个类,而是把这个请求委派给父类加载器去完成。每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
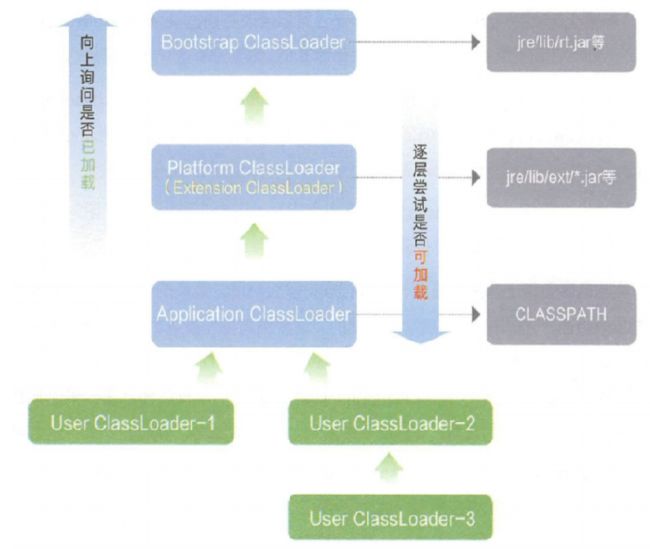
其中:
- 启动类加载器(Bootstrap Class Loader):它是 JVM 的内部组件,负责加载 Java 核心类库(如java.lang)和其他被系统类加载器所需要的类。启动类加载器是由 JVM 实现提供的,通常使用本地代码来实现。
- 扩展类加载器(Extension Class Loader):它是 sun.misc.Launcher$ExtClassLoader 类的实例,负责加载 Java 的扩展类库(如 java.util、java.net)等。扩展类加载器通常从 java.ext.dirs 系统属性所指定的目录或 JDK 的扩展目录中加载类。
- 系统类加载器(System Class Loader):也称为应用类加载器(Application Class Loader),它是sun.misc.Launcher$AppClassLoader 类的实例,负责加载应用程序的类。系统类加载器通常从 CLASSPATH 环境变量所指定的目录或 JVM 的类路径中加载类。
- 用户自定义类加载器(User-defined Class Loader):这是开发人员根据需要自己实现的类加载器。用户自定义类加载器可以根据特定的加载策略和需求来加载类,例如从特定的网络位置、数据库或其他非传统来源加载类。
双亲委派模型的优点:
① 避免重复加载类:比如 A 类 和 B 类 都有一个父类 C 类,那么当 A 启动时就会将 C 类 加载起来,那么在 B 类 进行加载时就不需要再重复加载 C 类了。
② 更安全:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的,因此安全性就不能得到保障了。
四、死亡对象的判断算法
在 Java 中,所有的对象都是要存在内存中的(也可以说内存中存储的是一个个对象),因此我们将内 存回收,也可以叫做死亡对象的回收。
1. 引用计数算法
引用计数器算法的实现思路是,给对象增加一个引用计数器,每当有一个地方引用它时,计数器就 + 1;当引用失效时,计数器就 - 1;任何时刻计数器为 0 的对象就是不能再被使用的,即对象已“死”。
引用计数法的优点:判定简单,判定效率也高。
引用计数法的缺点:浪费内存空间。切无法解决对象的循环引用问题。
观察循环引用问题:
① 现在我们new了两个对象出来
Test a = new Test();
Test b = new Test();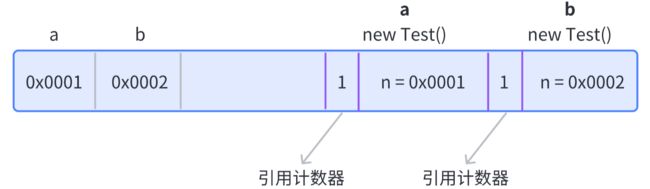
此时,两个对象的引用计算器都是1。
② 我们将 a 的实例指向 b,将 b 的实例指向 a
a.n = b;
b.n = a;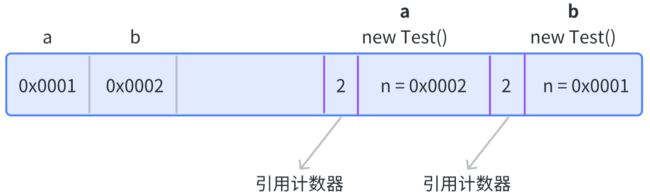
此时,a 和 b 的引用计算器的值都加 1。
③ 然后,我们将 a 和 b 给删除掉
a = null;
b = null;
// 强制jvm进行垃圾回收
System.gc();
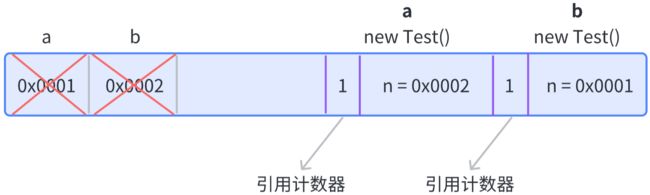
结果就是,a 和 b 都不能被使用了,但是引用计数器都只减 1 了,这两个对象由于引用计算器不为 0 ,因此不会被当做垃圾被回收~~
2. 可达性分析
可达性分析算法是通过一系列称为 “GC Roots” 的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为“引用链”,当一个对象到 GC Roots 没有任何引用链相连时(从 GC Roots 到这个对象不可达)时,证明找个对象是不可用的。
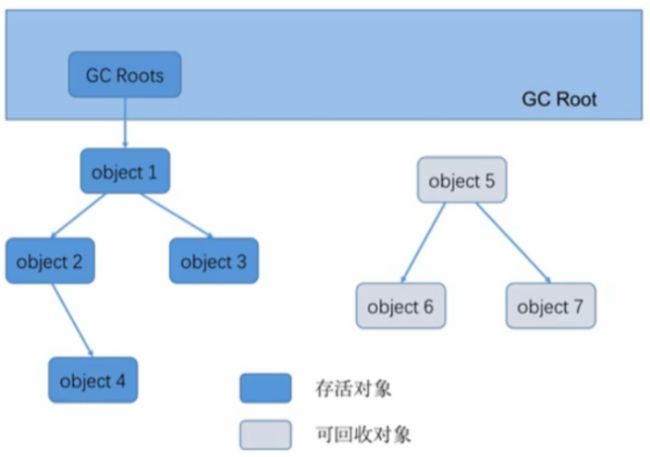
五、垃圾回收算法
1. 标记-清除算法
标记-清除(Mark-Sweep)算法是由标记阶段和记忆清除阶段构成的。标记阶段会给所有存活的对象做上标记,而清除阶段会把没有被标记的死亡对象进行回收。而标记的判断方法就是前面讲的引用计数算法和可达性分析算法。
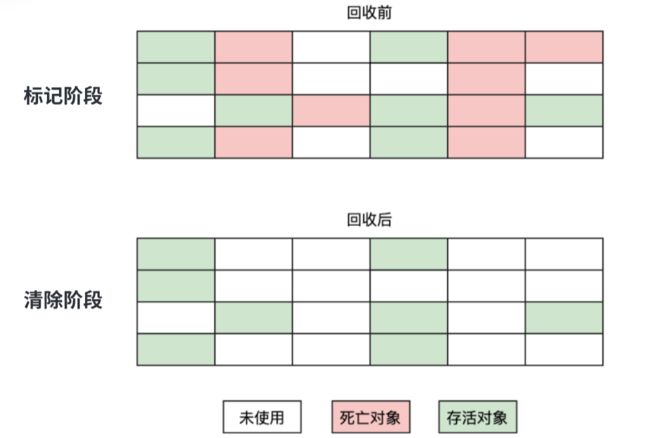
优点:实现简单。
缺点:产生不连续的内存碎片,如果程序需要分配一个连续内存的大对象时,就需要提前触发一次垃圾回收。
2. 复制算法
复制算法是将内存分为大小相同的两块区域,每次只使用其中的一块区域,这样在垃圾回收时就可以直接将存活的东西复制到新的内存上,然后再把另一块内存全部清理掉。这样就不会产生碎片的问题了。

优点 :执行效率高,没有内存碎片的问题。
缺点:空间利用率低,因为复制算法每次只能使用一半的内存。
3.标记-整理算法
标记-整理算法是由两个阶段组成的:标记阶段和整理阶段。标记阶段会给所有存活的对象做上标记,整理阶段是把所有存活的对象移动到内存的一端,然后把另一端的所有死亡对象全部清除。

优点:解决了内存碎片问题,比复制算法空间利用率高。
缺点:因为有局部对象移动,所以效率不是很高。
4. 分代算法
分代算法是通过区域划分,实现不同区域和不同的垃圾回收策略,从而实现更好的垃圾回收。
当前 JVM 垃圾回收采用的都是“分代收集(Generational Collection)”算法,这个算法并没有新思想,只是根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代。在新生代中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法。而老年代中对象存活率高。没有而外空间对它进行担保,就必须使用 “标记-清理” 或者“标记-整理”算法。特殊情况:如果对象非常大,那么直接进入老年代(大对象进行复制算法,成本太高)。
那些对象会进入新生代?那些对象会进入老年代?
- 新生代:一般创建的对象都会进入新生代。
- 老年代:当对象经历了 N 次(一般默认是 15 次)垃圾回收仍然存活下来的对象会从新生代移动到老年代。
为什么要将堆分成新生代和老年代呢?
因为对象分为两种,绝大多数对象都是朝生夕灭的,也是就是用完一次之后就不用了,而剩下一部分对象是要重复使用多次的,将不同对象划分到不同的区域,不同的区域使用不同的垃圾回收算法,这样可以大大提高 Java 虚拟机的工作效率。
面试题:请问了解 Minor GC 和 Full GC 么,这两种 GC 有什么不一样吗?
① Minor GC 又称为新生代 GC:指的是发生在新生代的垃圾收集。因为 Java 对象大多都具备朝生夕灭的特性,因此 Minor GC (采用复制算法)非常频繁,一般回收速度也比较快。
② Full GC 又称 老年代 GC 或者 Major GC:指发生在老年代的垃圾收集。出现了 Major GC,经常会伴随至少一次的 Minor(新生代) GC (并非绝对,在 Parallel Scavenge 收集器中就有直接进行 Full GC 的策略选择过程)。Major(老年代) GC 的速度一般会比 Minor(新生代) GC 慢 10 倍以上。
以上就是 JVM 的基础内容啦,虽然进公司之后都不会让你用到这些知识,但是面试会考呀,所以非常重要!!
