缓存 - Caffeine 不完全指北
文章目录
- 官网
- 概述
- 设计
- Code
-
- POM
- Population
- Eviction Policy
- Refresh
- Statistics

官网
https://github.com/ben-manes/caffeine
wiki:
https://github.com/ben-manes/caffeine/wiki
概述
Caffeine是一个用于Java应用程序的高性能缓存框架。它提供了一个强大且易于使用的缓存库,可以在应用程序中使用,以提高数据访问的速度和效率。
下面是一些Caffeine缓存框架的主要特点:
-
高性能:Caffeine的设计目标之一是提供卓越的性能。它通过使用高效的数据结构和优化的算法来实现快速的缓存访问。与其他一些常见的缓存框架相比,Caffeine在缓存访问的速度和响应时间上表现出色。
-
内存管理:Caffeine提供了灵活的内存管理选项。它支持基于大小、基于数量和基于权重的缓存大小限制。你可以根据应用程序的需求来选择合适的缓存大小策略,并且可以通过配置参数进行进一步的调整。
-
强大的功能:Caffeine提供了许多强大的功能来满足各种需求。它支持异步加载和刷新缓存项,可以设置过期时间和定时刷新策略,支持缓存项的自动删除和手动失效等。此外,Caffeine还提供了统计信息和监听器机制,可以方便地监控和管理缓存的状态和变化。
-
线程安全:Caffeine是线程安全的,可以在多线程环境中安全地使用。它使用了细粒度的锁定机制来保护共享资源,确保并发访问的正确性和一致性。
-
易于集成:Caffeine是一个独立的Java库,可以很容易地与现有的应用程序集成。它与标准的Java并发库和其他第三方库兼容,并且可以与各种框架和技术(如Spring、Hibernate等)无缝集成。
Caffeine 是一个高性能的 Java 缓存框架,旨在提供快速、高效的内存缓存解决方案。它是由 Google 开发的,是 Guava 缓存的升级版。
Caffeine 的设计目标是提供高吞吐量、低延迟的缓存访问,并支持各种缓存策略和功能。以下是一些 Caffeine 框架的关键特点:
-
高性能:Caffeine 的设计优化了缓存的内存访问模式,使用了各种技术来减少缓存访问的开销,从而提高了性能。它使用了类似于 Java ConcurrentHashMap 的数据结构,支持并发访问,并提供了可配置的并发级别。
-
内存管理:Caffeine 提供了灵活的内存管理选项,可以通过设置缓存的最大大小、最大条目数或最大权重来控制缓存的大小。它还支持基于容量、时间或引用等策略来自动清理过期的缓存条目。
-
强大的缓存策略:Caffeine 提供了多种缓存策略,包括基于访问时间、写入时间或自定义规则的过期策略。它还支持最近最少使用(LRU)、最近最不常用(LFU)和固定大小等其他策略。
-
异步加载:Caffeine 支持异步加载缓存条目的功能。当缓存中不存在所需的条目时,它可以自动触发加载过程,并在加载完成后将结果放入缓存。
-
统计和监控:Caffeine 提供了丰富的统计和监控功能,可以跟踪缓存的命中率、加载时间、缓存大小等指标。这些信息对于调优和性能分析非常有用。
-
扩展性:Caffeine 的设计允许开发人员通过自定义策略、缓存加载器和监听器等扩展框架的功能。
使用 Caffeine 缓存框架非常简单。你可以通过以下步骤来开始使用:
-
引入 Caffeine 依赖:在你的项目中添加 Caffeine 的依赖项,可以通过 Maven、Gradle 或直接下载 JAR 文件进行引入。
-
创建缓存实例:使用 Caffeine 的构建器模式创建一个缓存实例,可以设置缓存的参数和策略。
-
存储和获取数据:使用缓存的
put方法将数据存储到缓存中,使用get方法从缓存中获取数据。如果缓存中不存在所需的数据,可以选择触发异步加载或提供自定义加载逻辑。 -
调优和配置:根据应用程序的需求,可以调整缓存的参数和策略,以获得最佳的性能和内存管理。
总之,Caffeine 是一个功能强大、高性能的 Java 缓存框架,适用于各种应用场景,尤其是需要快速访问、低延迟和高吞吐量的内存缓存需求。
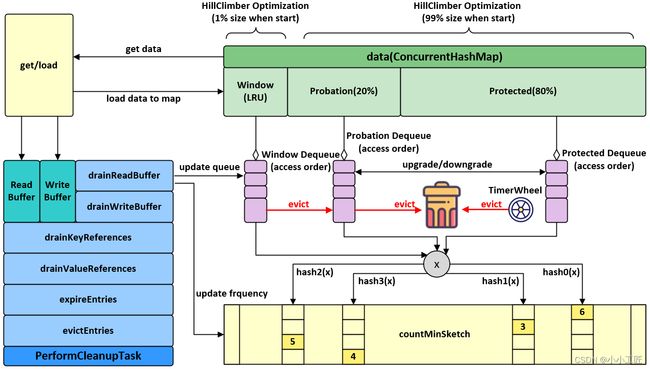
设计
Code
POM
<dependency>
<groupId>com.github.ben-manes.caffeinegroupId>
<artifactId>caffeineartifactId>
<version>2.9.3version>
dependency>
如果是caffeine 3.x的版本,需要JDK 11 以上。
Population
https://github.com/ben-manes/caffeine/wiki/Population
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.AsyncLoadingCache;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import lombok.Builder;
import lombok.Data;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.*;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
@Slf4j
public class CaffeineBaseExampleWithJava {
@SneakyThrows
public static void main(String[] args) {
// initFirstWay();
// initSecondWay();
initThirdWay();
TimeUnit.SECONDS.sleep(10);
}
/**
* Cache手动创建
*
* 最普通的一种缓存,无需指定加载方式,需要手动调用put()进行加载。需要注意的是put()方法对于已存在的key将进行覆盖,这点和Map的表现是一致的。
* 在获取缓存值时,如果想要在缓存值不存在时,原子地将值写入缓存,则可以调用get(key, k -> value)方法,该方法将避免写入竞争。调用invalidate()方法,将手动移除缓存。
*
* 在多线程情况下,当使用get(key, k -> value)时,如果有另一个线程同时调用本方法进行竞争,则后一线程会被阻塞,直到前一线程更新缓存完成;
* 而若另一线程调用getIfPresent()方法,则会立即返回null,不会被阻塞。
*/
@SneakyThrows
public static void initFirstWay() {
Cache<Object, Object> cache = Caffeine.newBuilder()
//初始数量
.initialCapacity(10)
//最大条数
.maximumSize(10)
//expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准
//最后一次写操作后经过指定时间过期
.expireAfterWrite(3, TimeUnit.SECONDS)
//最后一次读或写操作后经过指定时间过期
.expireAfterAccess(3, TimeUnit.SECONDS)
//监听缓存被移除
.removalListener((key, val, removalCause) -> {
log.info("listener remove : {} ,{} ,{}", key, val, removalCause);
})
//记录命中
.recordStats()
.build();
cache.put("name", "小工匠");
//小工匠
log.info((String) cache.getIfPresent("name"));
// 结合初始化的时候设置的过期时间, 模拟程序运行5秒后,再此获取
TimeUnit.SECONDS.sleep(5);
log.info("5秒后再次获取:{}", (String) cache.getIfPresent("name"));
//存储的是默认值
log.info((String) cache.get("noKey", o -> "默认值"));
}
/**
* Loading Cache自动创建
*
* LoadingCache是一种自动加载的缓存。其和普通缓存不同的地方在于,当缓存不存在/缓存已过期时,若调用get()方法,则会自动调用CacheLoader.load()方法加载最新值。
* 调用getAll()方法将遍历所有的key调用get(),除非实现了CacheLoader.loadAll()方法。
*
* 使用LoadingCache时,需要指定CacheLoader,并实现其中的load()方法供缓存缺失时自动加载。
*
* 在多线程情况下,当两个线程同时调用get(),则后一线程将被阻塞,直至前一线程更新缓存完成。
*/
@SneakyThrows
public static void initSecondWay() {
Map<Integer, Artisan> map = getArtisanMap();
log.info("size:{}", map.size());
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
//创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存;refreshAfterWrite仅支持LoadingCache
.refreshAfterWrite(10, TimeUnit.SECONDS)
.expireAfterWrite(10, TimeUnit.SECONDS)
.expireAfterAccess(10, TimeUnit.SECONDS)
.maximumSize(10)
//根据key查询数据库里面的值,这里是个lambda表达式
// TODO 根据其概况初始化 ,比如 build(userId -> getUserFromDatabase(userId));
// private User getUserFromDatabase(String userId) {
// // 这里会从数据库查询用户信息
// // ...
// return user;
// }
.build(key -> map.get(Integer.parseInt(key)).toString());
// 当执行get的时候,会触发 build 中的 lambda表达式
log.info(loadingCache.get("1"));
log.info(loadingCache.get("2"));
log.info(loadingCache.get("3"));
log.info(loadingCache.get("4"));
log.info(loadingCache.get("4", o -> "默认值"));
// 获取一个不存在的值
log.info(loadingCache.get("noKey", o -> "默认值"));
}
/**
* AsyncCache是Cache的一个变体,其响应结果均为CompletableFuture,
* 通过这种方式,AsyncCache对异步编程模式进行了适配。
*
* 默认情况下,缓存计算使用ForkJoinPool.commonPool()作为线程池,如果想要指定线程池,则可以覆盖并实现Caffeine.executor(Executor)方法。
*
* synchronous()提供了阻塞直到异步缓存生成完毕的能力,它将以Cache进行返回。
*
* 在多线程情况下,当两个线程同时调用get(key, k -> value),则会返回同一个CompletableFuture对象。由于返回结果本身不进行阻塞,可以根据业务设计自行选择阻塞等待或者非阻塞。
*/
@SneakyThrows
public static void initThirdWay() {
Map<Integer, Artisan> map = getArtisanMap();
log.info("size:{}", map.size());
AsyncLoadingCache<String, String> asyncLoadingCache = Caffeine.newBuilder()
//创建缓存或者最近一次更新缓存后经过指定时间间隔刷新缓存;仅支持LoadingCache
.refreshAfterWrite(1, TimeUnit.SECONDS)
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
//根据key查询数据库里面的值
.buildAsync(key -> {
Thread.sleep(1000);
return map.get(Integer.parseInt(key)).toString();
});
//异步缓存返回的是CompletableFuture
CompletableFuture<String> future = asyncLoadingCache.get("1");
future.thenAccept(System.out::println);
}
private static Map<Integer, Artisan> getArtisanMap() {
Map<Integer, Artisan> map = new HashMap<>(16);
map.put(1, Artisan.builder().id(1).name("artisan1").hobbies(Arrays.asList("Java")).build());
map.put(2, Artisan.builder().id(2).name("artisan2").hobbies(Arrays.asList("AIGC")).build());
map.put(3, Artisan.builder().id(3).name("artisan3").hobbies(Arrays.asList("HADOOP")).build());
map.put(4, Artisan.builder().id(4).name("artisan4").hobbies(Arrays.asList("GO")).build());
return map;
}
@Data
@Builder
private static class Artisan {
private Integer id;
private String name;
private List<String> hobbies;
}
}
expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准
Eviction Policy
https://github.com/ben-manes/caffeine/wiki/Eviction
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.Scheduler;
import com.github.benmanes.caffeine.cache.Weigher;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
* @desc: 驱逐策略在创建缓存的时候进行指定。常用的有基于容量的驱逐和基于时间的驱逐。
*
* 基于容量的驱逐需要指定缓存容量的最大值,当缓存容量达到最大时,Caffeine将使用LRU策略对缓存进行淘汰;基于时间的驱逐策略如字面意思,可以设置在最后访问/写入一个缓存经过指定时间后,自动进行淘汰。
*
* 驱逐策略可以组合使用,任意驱逐策略生效后,该缓存条目即被驱逐。
*
* LRU 最近最少使用,淘汰最长时间没有被使用的页面。
* LFU 最不经常使用,淘汰一段时间内使用次数最少的页面
* FIFO 先进先出
* Caffeine有4种缓存淘汰设置
*
* 大小 (LFU算法进行淘汰)
* 权重 (大小与权重 只能二选一)
* 时间
* 引用
*/
@Slf4j
public class CaffeineEvictionPolicy {
/**
* 缓存大小淘汰
*/
@Test
public void maximumSizeTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
//超过10个后会使用W-TinyLFU算法进行淘汰
.maximumSize(10)
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
// 模拟写入数据
for (int i = 1; i < 20; i++) {
cache.put(i, i);
}
//缓存淘汰是异步的
Thread.sleep(1000);
// 打印还没被淘汰的缓存
log.info("未淘汰的缓存:{}", cache.asMap());
}
/**
* 权重淘汰
*/
@Test
public void maximumWeightTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
//限制总权重,若所有缓存的权重加起来>总权重就会淘汰权重小的缓存
.maximumWeight(100)
.weigher((Weigher<Integer, Integer>) (key, value) -> key)
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
//总权重其实是=所有缓存的权重加起来
int maximumWeight = 0;
for (int i = 1; i < 20; i++) {
cache.put(i, i);
maximumWeight += i;
}
log.info("总权重={}", maximumWeight);
//缓存淘汰是异步的
Thread.sleep(1000);
// 打印还没被淘汰的缓存
log.info("未淘汰的缓存:{}", cache.asMap());
}
/**
* 访问后到期(每次访问都会重置时间,也就是说如果一直被访问就不会被淘汰)
*/
@Test
public void expireAfterAccessTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterAccess(1, TimeUnit.SECONDS)
//可以指定调度程序来及时删除过期缓存项,而不是等待Caffeine触发定期维护
//若不设置scheduler,则缓存会在下一次调用get的时候才会被动删除
.scheduler(Scheduler.systemScheduler())
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
cache.put(1, 2);
log.info("{}", cache.getIfPresent(1));
Thread.sleep(5000);
//null
log.info("{}", cache.getIfPresent(1));
Thread.sleep(500);
}
/**
* 写入后到期
*/
@Test
public void expireAfterWriteTest() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
//可以指定调度程序来及时删除过期缓存项,而不是等待Caffeine触发定期维护
//若不设置scheduler,则缓存会在下一次调用get的时候才会被动删除
.scheduler(Scheduler.systemScheduler())
.evictionListener((key, val, removalCause) -> {
log.info("淘汰缓存:key:{} val:{}", key, val);
})
.build();
cache.put(1, 2);
Thread.sleep(3000);
//null
log.info("{}", cache.getIfPresent(1));
}
}
Refresh
https://github.com/ben-manes/caffeine/wiki/Refresh
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*
*
* refreshAfterWrite()表示x秒后自动刷新缓存的策略可以配合淘汰策略使用,
*
* 注意的是刷新机制只支持LoadingCache和AsyncLoadingCache
*/
@Slf4j
public class CaffeineRefreshPolicy {
private static int NUM = 0;
@Test
public void refreshAfterWriteTest() throws InterruptedException {
LoadingCache<Integer, Integer> cache = Caffeine.newBuilder()
.refreshAfterWrite(1, TimeUnit.SECONDS)
//模拟获取数据,每次获取就自增1
.build(integer -> ++NUM);
//获取ID=1的值,由于缓存里还没有,所以会自动放入缓存
// 返回结果 1
log.info("get value = {}", cache.get(1));
// 延迟2秒后,理论上自动刷新缓存后取到的值是2
// 但其实不是,值还是1,因为refreshAfterWrite并不是设置了n秒后重新获取就会自动刷新
// 而是x秒后&&第二次调用getIfPresent的时候才会被动刷新
Thread.sleep(2000);
// 返回结果 1
log.info("get value = {}", cache.getIfPresent(1));
//此时才会刷新缓存,而第一次拿到的还是旧值 ,这时候拿到的就是新的值了 2
// 返回结果2
log.info("get value = {}", cache.getIfPresent(1));
}
}
Statistics
https://github.com/ben-manes/caffeine/wiki/Statistics
package com.artisan.caffeinedemo.java;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.Date;
import java.util.concurrent.TimeUnit;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
@Slf4j
public class CaffeineStatstic {
@Test
public void testStatistic() {
LoadingCache<String, String> cache = Caffeine.newBuilder()
//创建缓存或者最近一次更新缓存后经过指定时间间隔,刷新缓存;refreshAfterWrite仅支持LoadingCache
.refreshAfterWrite(1, TimeUnit.SECONDS)
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
//开启记录缓存命中率等信息
.recordStats()
//根据key查询数据库里面的值
.build(key -> {
Thread.sleep(1000);
return new Date().toString();
});
cache.put("1", "shawn");
cache.get("1");
/*
* hitCount :命中的次数
* missCount:未命中次数
* requestCount:请求次数
* hitRate:命中率
* missRate:丢失率
* loadSuccessCount:成功加载新值的次数
* loadExceptionCount:失败加载新值的次数
* totalLoadCount:总条数
* loadExceptionRate:失败加载新值的比率
* totalLoadTime:全部加载时间
* evictionCount:丢失的条数
*/
log.info("统计信息如下:\n {}", cache.stats());
}
}
