【论文精读】HugNLP: A Unified and Comprehensive Library for Natural Language Processing
HugNLP: A Unified and Comprehensive Library for Natural Language Processing
- 前言
- Abstract
- 1. Introduction
- 2. Background
-
- 2.1 Pre-trained Language Models
- 2.2 Fine-tuning for PLMs
- 3. HugNLP
-
- 3.1 Overview
- 3.2 Library Architecture
-
- 3.2.1 Models
- 3.2.2 Processors
- 3.2.3 Applications
- 3.3 Core Capacities
- 3.4 Featured Applications
- 3.5 Development Workflow
- 4. Experimental Performances
-
- 4.1 Performance of Benchmarks
- 4.2 Evaluation of Code-related Tasks
- 4.3 Effectiveness of Self-training
- 5. Conclusion
- 阅读总结
前言
NLP通用任务框架可以打打降低NLP任务处理的门槛,提供NLP研究人员解决NLP任务高效的处理方案,这将进一步推动NLP领域的发展,可以说是具有里程碑意义的工作~
Abstract
HugNLP是一个统一而全面的自然语言处理库,旨在让NLP研究人员利用现成的算法,在现实世界中使用用户定义的模型和任务开发新方法场景。其结构由模型、处理器和应用程序组成,它统一了预训练模型在不同NLP任务上的学习过程。作者通过一些特色的NLP应用如通用信息抽取、低资源挖掘、代码理解和生成等来展示HugNLP的有效性。
1. Introduction
预训练语言模型在预训练和微调两步作用下,已成为不少NLP下游任务的基建。但是现有的方法架构不同,模式各异,很难上手,因此HugNLP作为一个统一且全面的开源库,可以让研究人员有效开发和评估NLP模型。后端基于HuggingFace的Transformers库,训练部分集成了跟踪工具包MLFlow,便于观察实验进度和记录。HugNLP由模型、处理器和应用三部分组成。
模型提供了常用的PLMs,如BERT、RoBERTa、DeBERTa、GPT-2和T5等。基于这些模型,作者开发了用于预训练和微调的任务特定模块,此外还提供了基于prompt的微调技术,可以对PLM进行参数高效调整,如PET、P-tuning、Prefix-tuning、Adapter-tuning。
处理器部分,为一些常用的数据集和任务特定语料库开发了相关的数据处理工具。
应用部分,提出了KP-PLM,通过将结构知识转换为统一的语言prompt,在模型预训练和微调中实现即插即用的知识注入。此外还开发了HugIE,一种通用信息抽取工具包,通过指令微调和抽取建模实现。
总而言之,HugNLP具有如下特点:
- HugNLP提供一系列预构建组件和模块,可用于快速开发并简化复杂NLP模型和任务的实施;
- HugNLP可以轻松集成到现有的工作流程中,满足研究人员个性化需求;
- HugNLP实现一些针对特定场景的解决方案,如KP-PLM和HugIE;
- 基于PyTorch和HuggingFace两个广泛使用的平台,使用方便。
2. Background
2.1 Pre-trained Language Models
PLM的目标是在预训练阶段通过精心设计的自监督学习任务来学习无监督语料库的语义表示。PLMs架构可以分为encoder-only、encoder-decoder和decoder-only三种架构,然而这些PLM在某些特定任务上可能缺乏背景知识。因此提出知识增强PLM用于从外部数据库获取丰富知识。最近的大模型如GPT-3可以通过prompt或instructions方式作用在低资源场景。因此可以利用跨任务学习来统一不同NLP任务的语义知识。
2.2 Fine-tuning for PLMs
实际场景中,关注于如何微调PLM将知识迁移到下游任务。HugNLP集成了一些面向任务的微调方法,还实现了流行的调优算法如prompt和上下文学习等。
3. HugNLP
3.1 Overview
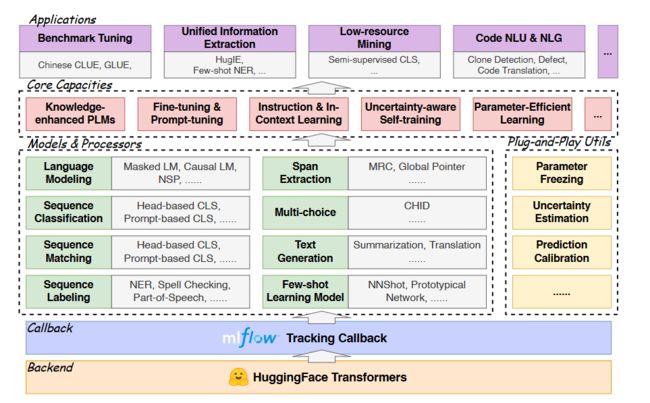
HugNLP是多层式结构的开源库。后端是HuggingFace Transformers平台,提供多个基于transformer的模型。此外,HugNLP集成了MLFlow,一种用于模型训练和实验结果分析的新型跟踪回调工具包。
3.2 Library Architecture
3.2.1 Models
模型提供了流行的基于transformer的模型,并且发布了KP-PLM,一种新颖的知识增强型预训练模型,利用只是promp范式注入事实知识,可以轻松用于任意PLMs。此外,作者还实现了特定于任务的模型,涉及序列分类、匹配、标记、跨度提取文本生成等。对于小样本学习设置,HugNLP在小样本文本分类和NER方面提供了一个原型网络。

HugNLP中还加入了一些即插即用的实用程序。
- 参数冻结。如上图所示,通过冻结PLM中一些参数提高训练效率。
- 不确定性估计。旨在计算半监督学习中模型的准确性。
- 预测校准。通过校准分布和缓解语义偏差来提高准确性。
3.2.2 Processors
HugNLP旨在将数据加载到pipeline中处理任务实例,包括标注数据、采样和生成张量。对于不同的任务,用户需要定义任务特定数据校对器,目的是将原始数据转换为模型张量特征。
3.2.3 Applications
通过对模型和处理器进行设置,为用户提供丰富的模块来构建真实的应用。
3.3 Core Capacities
HugNLP的核心部分如下:
- 知识增强预训练: 常规的预训练方法缺少事实知识,因此KP-PLM提出为预训练提供知识增强。具体来说,通过实体识别和知识对齐为每个输入文本构建知识子图,接着将子图分解为多个关系路径,从而直接转换为语言prompt。
- 基于prompt的推理: 旨在重用预训练目标,利用设计好的模板在语言上进行预测,适合低资源场景。
- Instruction-tuning和In-Context Learning: 无需更新参数,适用于低资源场景。目的是结合任务感知指令来提示GPT风格的PLMs生成可靠的响应。受此启发,作者将其延伸到两种范式:通用抽取范式和推理范式。
- 不确定感知自我训练: 自训练可以标注未标记数据来解决数据稀疏问题,但是标准的自我训练会产生过多的噪声降低模型性能。不确定感知自我训练在少数标记数据上训练教师模型,然后在贝叶斯神经网络上使用蒙特卡罗dropout技术来近似模型确定性,明智选择教师模型上有更高的模型确定性。
- 参数高效学习: 通过冻结backbone的参数以便训练期间只调整少量参数。作者开发了一些新颖的参数高效学习方法,如Prefix-tuning、Adapter-tuning等。
3.4 Featured Applications
- benchmark微调。作者为一些流行的基准开发了训练应用程序,如中文CLUE和GLUE。使用微调(包括prompt微调)方法根据这些benchmark调整PLM。代码示例如下:

- 基于抽取指令的通用信息抽取。作者开发了HugIE,基于HugNLP的通用信息抽取工具包。具体来说,作者收集了多个中文NER和事件抽取数据库。然后使用带有全局指针的抽取式指令来预训练通用信息抽取模型。
- 低资源场景PLMs调优。集成了prompt微调和不确定感知自我训练。前者可以充分利用预训练阶段知识,后者可以增强数据。
- 代码理解和生成。包括克隆检测、代码摘要、缺陷检测。
3.5 Development Workflow
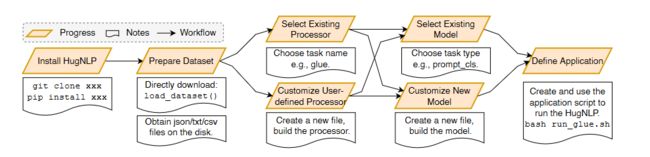
上图展示了如何用HugNLP展开一个新的任务。包括安装、数据准备、处理器选择或设计、模型选择或设计以及应用程序设计五步骤。HugNLP可以简化复杂NLP模型的实现。
4. Experimental Performances
4.1 Performance of Benchmarks
为了验证HugNLP在微调和Prompt上调优的有效性,选择了中文CLUE和GLUE基准。
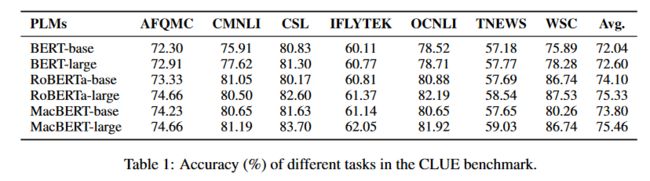
上表是不同规模模型在中文CLUE上的表现。对于CLUE,基于提出的KP-PLM进行全资源微调、小样本即时微调和零样本即时微调,我们选取RoBERTa作为基线如下表所示。
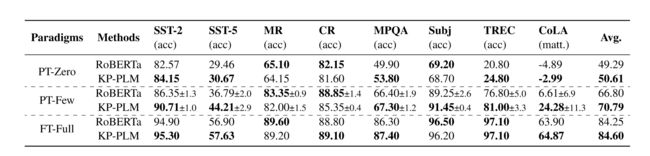
上表体现HugNLP在全资源和低资源场景的可靠性,与其他开源框架和原始实现相比有相似的性能。
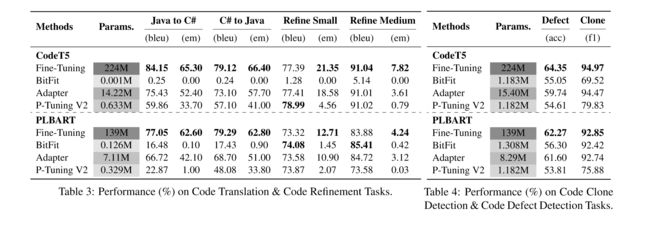
4.2 Evaluation of Code-related Tasks
作者使用HugNLP评估多个代码相关任务的性能,例如代码克隆、缺陷检测、翻译等。微调了两个广泛使用的模型:CodeT5和PLBART,然后和有竞争力的参数高效学习方法比较,下表证明了HugNLP的有效性和高效性。
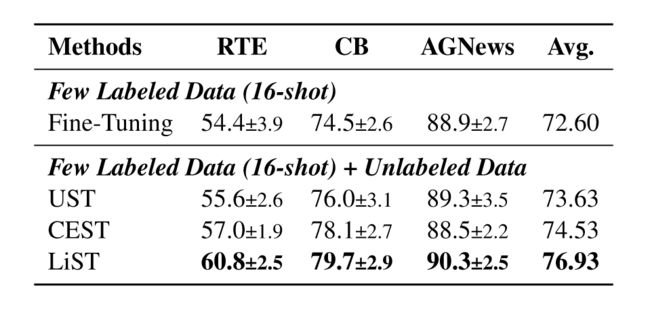
4.3 Effectiveness of Self-training
最后验证了自我训练。在只有16个标注样本表现如下:
5. Conclusion
HugNLP是一个基于PyTorch和HuggingFace的一个统一全面的库,它有三个重要组成部分,处理器,模型和应用,以及多个核心功能和工具。最后通过实验结果,表明HugNLP可以促进NLP的研究和发展。
阅读总结
一篇关于NLP模型工具框架前沿工作的文章,文中没有给出特别的应用示例,之后我会尝试部署HugNLP,不知道其对设备的需求有多高。这篇工作还是让我有所启发的,尤其是当前的大模型通用处理各种任务的能力,比如通用抽取,生成摘要,这些任务一个模型就能搞定,但是要编写不同的代码,这样的时间成本和debug成本还是相对高昂的,有了HugNLP,将许多通用的操作封装好,只需要更改设置,减少了很多费时的工作,这将大大提升之后处理NLP任务的效率。