【无标题】
C++ 23 实用工具(四一) 正则表达式
正则表达式
正则表达式¹是一种描述文本模式的语言。在C++中,可以使用头文件中提供的库函数进行正则表达式操作。正则表达式在以下任务中非常有用:
- 检查文本是否与文本模式匹配:
std::regex_match - 在文本中搜索文本模式:
std::regex_search - 用文本替换文本模式:
std::regex_replace - 迭代文本中的所有文本模式:
std::regex_iterator和std::regex_token_iterator
C++支持六种不同的正则表达式语法。默认情况下,使用ECMAScript语法。这是六种语法中最强大的语法,与Perl 5中使用的语法非常相似。其他五种语法是基本语法、扩展语法、awk语法、grep语法和egrep语法。
使用原始字符串
在正则表达式中,建议使用原始字符串(raw string)来表示文本模式。如果不使用原始字符串,例如要匹配C++这个字符串,正则表达式的写法为C++,这看起来非常丑陋,每个加号都需要用两个反斜杠来转义。原因是加号在正则表达式中是一个特殊字符,而反斜杠在C++中也是一个特殊字符,因此需要使用两个反斜杠来转义加号和反斜杠。
使用原始字符串字面值可以避免这种混乱。原始字符串中的字符不需要进行转义,因为它们被视为字面值。例如,我们可以使用以下代码来表示C++的正则表达式:
#include 这里,第一个字符串是普通字符串,需要使用两个反斜杠来转义加号和反斜杠。而第二个字符串是原始字符串,不需要进行转义,因为它被包含在R"()"中。
使用原始字符串字面值可以让代码更加清晰易读,尤其是在需要使用大量反斜杠的情况下。
使用方式
I. 定义正则表达式:
std::string text="C++ or c++.";
std::string regExpr(R"(C\+\+)");
std::regex rgx(regExpr);
在这个例子中,定义了一个字符串 text 和一个正则表达式 regExpr,其中 R"(C\+\+)" 表示原始字符串,C\+\+ 是要匹配的模式,\+ 表示匹配加号字符。
II. 执行正则表达式匹配:
std::smatch result;
std::regex_search(text, result, rgx);
这里使用 std::regex_search 函数执行正则表达式匹配,将匹配结果存储在 result 对象中。std::smatch 是一个类型,用于存储匹配结果的数据结构。
III. 处理匹配结果:
std::cout << result[0] << '\n';
在使用正则表达式时,文本类型决定了正则表达式的字符类型以及搜索结果的类型。下表展示了四种不同组合的文本类型、正则表达式类型、搜索结果类型和操作方式:
| 文本类型 | 正则表达式类型 | 搜索结果类型 |
|---|---|---|
const char* |
std::regex |
std::cmatch |
std::string |
std::regex |
std::smatch |
const wchar_t* |
std::wregex |
std::wcmatch |
std::wstring |
std::wregex |
std::wsmatch |
本章“搜索”部分的示例程序中提供了以上四种组合的详细使用方法。
在使用正则表达式时,需要根据实际情况选择合适的文本类型、正则表达式类型和搜索结果类型,以确保程序的正确性和高效性。
正则表达式对象
在C++中,正则表达式对象是基于类模板 template 实例化得到的。我们可以根据需要指定不同的字符类型和特性类,特性类定义了对正则语法属性的解释。C++中有两种类型的正则表达式:
typedef basic_regexregex; typedef basic_regexwregex;
此外,我们还可以进一步自定义正则表达式对象,指定使用的语法,适应不同的语法规则。C++支持基本的、扩展的、awk、grep和egrep语法。如果您想要忽略大小写,可以使用 std::regex_constants::icase 标志进行匹配。如果您更改了语法规则,还需要显式指定所使用的语法。
#include 搜索结果 match_results
在C++中,std::match_results 是由 std::regex_match 或 std::regex_search 函数返回的结果对象。std::match_results 是一个序列容器,至少包含一个 std::sub_match 对象的捕获组。std::sub_match 对象是字符序列。
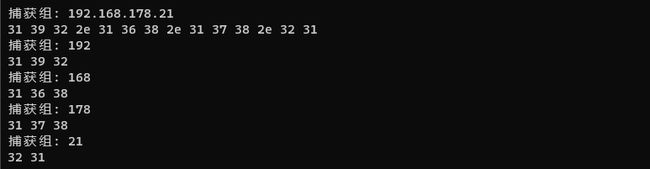
什么是捕获组?捕获组允许在正则表达式的搜索结果中进一步分析。它们由一对括号()定义。正则表达式 ((a+)(b+)(c+)) 有四个捕获组:((a+)(b+)(c+))、(a+)、(b+) 和 (c+)。总的匹配结果是第0个捕获组。
C++ 提供了四种类型的 std::match_results 同义词:
typedef match_resultscmatch; typedef match_resultswcmatch; typedef match_resultstypedef match_results
其中,搜索结果 std::smatch 对象具有强大的接口,可以方便地操作匹配结果。
使用正则表达式对象和 std::match_results 对象可以帮助我们更方便地进行字符串匹配和替换操作,是 C++ 中非常重要的一个功能模块。
#include 这段代码演示了 std::smatch 对象的使用,std::smatch 对象是 std::match_results 的一个特化版本,用于存储正则表达式匹配的结果。在本例中,我们定义了一个字符串 str,其中包含了待匹配的内容。然后定义了一个正则表达式 re,其内容为 (.+) (.+)!,即匹配以一个或多个字符开头,接着是一个空格,然后是另一个或多个字符,最后是一个感叹号的字符串。接着调用 std::regex_search 函数进行正则表达式匹配,如果匹配成功,则将匹配结果存储在 match 对象中。
接下来,我们演示了 std::smatch 对象的一些常用成员函数,包括:
size():返回捕获组的数量。empty():判断搜索结果是否有捕获组。operator[]:返回指定捕获组的 std::sub_match 对象。length(i):返回指定捕获组的长度。position(i):返回指定捕获组的起始位置。str(i):返回指定捕获组的字符串。prefix():返回匹配结果前缀。suffix():返回匹配结果后缀。begin():返回迭代器,指向第一个捕获组。end():返回迭代器,指向最后一个捕获组。
在本例中,我们使用了 operator[]、length、position 和 str 函数遍历了所有的捕获组,并输出了其长度和起始位置。同时,我们也输出了匹配结果的前缀和后缀。
运行代码,输出结果为:
匹配结果: Hello World!
第一个捕获组: Hello
第二个捕获组: World
第 0 个捕获组: Hello World!
长度: 12
位置: 0
第 1 个捕获组: Hello
长度: 5
位置: 0
第 2 个捕获组: World
长度: 5
位置: 6
匹配结果前缀:
匹配结果后缀:
#include 
std::sub_match
在 C++ 中,捕获组的类型是 std::sub_match。与 std::match_results 类似,C++ 定义了以下四个类型的同义词:
typedef sub_match<const char*> csub_match;
typedef sub_match<const wchar_t*> wcsub_match;
typedef sub_match<string::const_iterator> ssub_match;
typedef sub_match<wstring::const_iterator> wssub_match;
您可以进一步分析捕获组 cap。std::sub_match 对象具有以下成员函数:
cap.matched():指示此匹配是否成功。cap.first()和cap.end():返回字符序列的起始和结束迭代器。cap.length():返回捕获组的长度。cap.str():以字符串形式返回捕获组。cap.compare(other):将当前捕获组与其他捕获组进行比较。
以下是一个代码片段,显示了搜索结果 std::match_results 与其捕获组 std::sub_match 之间的交互:
#include 在这个示例中,我们使用 std::regex_search 函数来搜索文本中的匹配项。如果找到匹配项,我们遍历所有捕获组,并使用 std::sub_match 对象的成员函数来输出有关捕获组的信息。
匹配
std::regex_match函数用于确定文本是否匹配某个文本模式,可以进一步分析std::match_results类型的搜索结果。下面的代码片段展示了三种简单应用std::regex_match的方式:C字符串、C++字符串和范围,分别返回一个布尔类型的结果。对于std::match_results对象,也有相应的三种变体。
#include