freeswitch 使用 silero-vad 静音拆分使用 fastasr 识别
silero-vad 在git 的评分挺高的测试好像比webrtc vad好下面测试下
silero-vad 支持c++ 和py 由于识别c的框架少下面使用py
以下基于python3.8+torch1.12.0+torchaudio 1.12.0
1.由于fastasr 需要16k 所以 将freeswitch的实时音频mediabug 8k转成16k 用socket传到py 模块代码百多略 。
pip3 install fastasr
使用阿里的模型吧 感觉还行
下载预训练模型
paraformer预训练模型下载
进入FastASR/models/paraformer_cli文件夹,用于存放下载的预训练模型.
cd ../models/paraformer_cli
从modelscope官网下载预训练模型,预训练模型所在的仓库地址 也可通过命令一键下载。
wget --user-agent="Mozilla/5.0" -c "https://www.modelscope.cn/api/v1/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/repo?Revision=v1.0.4&FilePath=model.pb" mv repo\?Revision\=v1.0.4\&FilePath\=model.pb model.pb
将用于Python的模型转换为C++的,这样更方便通过内存映射的方式直接读取参数,加快模型读取速度。
../scripts/paraformer_convert.py model.pb
查看转换后的参数文件wenet_params.bin的md5码,md5码为c77bc27e5758ebdc28a9024460e48602,表示转换正确。
md5sum -b wenet_params.bin测试:
git clone https://github.com/chenkui164/FastASR

fastasr ok
2、silero-vad安装
需要环境 本文torch1.12.0+torchaudio 1.12.0
pytorch>= 1.12.0torchaudio>= 0.9.0 (used only for examples, IO and resampling, can be omitted in production)
安装好就行
测试:
silero-vad/parallel_example.ipynb at master · snakers4/silero-vad · GitHub
3. 综合:
fs 每帧数据10s 用python3 合并了 vad 推荐30ms 核心代码如下:
其他代码参考
FastASR/paraformer_cli.py at main · chenkui164/FastASR · GitHub
silero-vad/parallel_example.ipynb at master · snakers4/silero-vad · GitHub
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
# 绑定地址和端口
s.bind(ADDR)
# 等待接收信息
datahe = []
allokdata=[]
index=0;
sendstate=0
print("udpstart\n")
while True:
#print('UDP服务启动,准备接收数据……')
# 接收数据和客户端请求地址
data, address = s.recvfrom(BUFFSIZE)
if not data:
break
if (len(data)) < 640:
。。。。。
datahe = np.append( datahe,np.frombuffer( newdata0 , np.int16 ) );
audio_float32 = int2float( datahe )
new_confidence = model(torch.from_numpy(audio_float32), 16000).item()
#print("==",new_confidence)
if new_confidence >=0.5: #合并数据为识别
print("=================",new_confidence);
if sendstate==1:
allokdata = np.append( allokdata, datahe )
else:
sendstate=1
allokdata = datahe
#f.write( datahe.tobytes() )
else:
if sendstate!=0:# 一段有声音的识别
start_time = time.time()
p.reset()
result = p.forward(allokdata)
end_time = time.time()
print('Result: "{}".'.format(result))
print("Model inference takes {:.2}s.".format(end_time - start_time))
allokdata =[]
sendstate=0;
datahe = []
index=0;
最终呼叫实时测试效果如下,效果还行。:
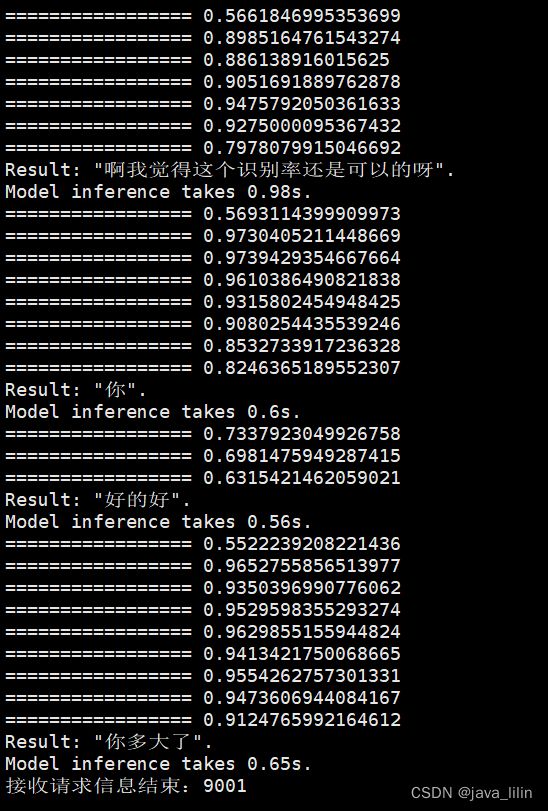
可以在cpu服务器开启做实时翻译、机器人之类 的 。未测试并发能力。
如果需要支持到:https://shop121230895.taobao.com/index.htm