elasticsearch
Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。Kibana 使您能够以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。Elasticsearch 是索引、搜索和分析魔法发生的地方。
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch 都能以支持快速搜索的方式高效地存储和索引它。您可以超越简单的数据检索和聚合信息来发现数据中的趋势和模式。随着您的数据和查询量的增长,Elasticsearch 的分布式特性使您的部署能够随之无缝增长。
什么是搜索引擎
所谓搜索引擎,就是根据用户需求与一定算法,运用特定策略从互联网检索出指定信息反馈给用户的一门检索技术。搜索引擎依托于多种技术,如网络爬虫技术、检索排序技术、网页处理技术、大数据处理技术、自然语言处理技术等,为信息检索用户提供快速、高相关性的信息服务。搜索引擎技术的核心模块一般包括爬虫、索引、检索和排序等,同时可添加其他一系列辅助模块,以为用户创造更好的网络使用环境。
应用场景
- 社会化搜索
社交网络平台和应用占据了互联网的主流,社交网络平台强调用户之间的联系和交互,这对传统的搜索技术提出了新的挑战。
传统搜索技术强调搜索结果和用户需求的相关性,社会化搜索除了相关性外,还额外增加了一个维度,即搜索结果的可信赖性。对某个搜索结果,传统的结果可能成千上万,但如果处于用户社交网络内其他用户发布的信息、点评或验证过的信息则更容易信赖,这是与用户的心里密切相关的。社会化搜索为用户提供更准确、更值得信任的搜索结果。 - 实时搜索
对搜索引擎的实时性要求日益增高,这也是搜索引擎未来的一个发展方向。
实时搜索最突出的特点是时效性强,越来越多的突发事件首次发布在微博上,实时搜索核心强调的就是“快”,用户发布的信息第一时间能被搜索引擎搜索到。不过在国内,实时搜索由于各方面的原因无法普及使用,比如Google的实时搜索是被重置的,百度也没有明显的实时搜索入口。 - 移动搜索
随着智能手机的快速发展,基于手机的移动设备搜索日益流行,但移动设备有很大的局限性,比如屏幕太小,可显示的区域不多,计算资源能力有限,打开网页速度很慢,手机输入繁琐等问题都需要解决。
目前,随着智能手机的快速普及,移动搜索一定会更加快速的发展,所以移动搜索的市场占有率会逐步上升,而对于没有移动版的网站来说,百度也提供了“百度移动开放平台”来弥补这个缺失。 - 个性化搜索
个性化搜索主要面临两个问题:如何建立用户的个人兴趣模型?在搜索引擎里如何使用这种个人兴趣模型?
个性化搜索的核心是根据用户的网络行为,建立一套准确的个人兴趣模型。而建立这样一套模型,就要全民收集与用户相关的信息,包括用户搜索历史、点击记录、浏览过的网页、用户E-mail信息、收藏夹信息、用户发布过的信息、博客、微博等内容。比较常见的是从这些信息中提取出关键词及其权重。为不同用户提供个性化的搜索结果,是搜索引擎总的发展趋势,但现有技术有很多问题,比如个人隐私的泄露,而且用户的兴趣会不断变化,太依赖历史信息,可能无法反映用户的兴趣变化。 - 地理位置感知搜索
目前,很多手机已经有GPS的应用了,这是基于地理位置感知的搜索,而且可以通过陀螺仪等设备感知用户的朝向,基于这种信息,可以为用户提供准确的地理位置服务以及相关搜索服务。目前,此类应用已经大行其道,比如手机地图APP。 - 跨语言搜索
如何将中文的用户查询翻译为英文查询,目前主流的方法有3种:机器翻译、双语词典查询和双语语料挖掘。对于一个全球性的搜索引擎来说,具备跨语言搜索功能是必然的发展趋势,而其基本的技术路线一般会采用查询翻译加上网页的机器翻译这两种技术手段。
7、多媒体搜索
目前,搜索引擎的查询还是基于文字的,即使是图片和视频搜索也是基于文本方式。那么未来的多媒体搜索技术则会弥补查询这一缺失。多媒体形式除了文字,主要包括图片、音频、视频。多媒体搜索比纯文本搜索要复杂许多,一般多媒体搜索包含4个主要步骤:多媒体特征提取、多媒体数据流分割、多媒体数据分类和多媒体数据搜索引擎。 - 情境搜索
情境搜索是融合了多项技术的产品,上面介绍的社会化搜索、个性化搜索、地点感知搜索等都是支持情境搜索的,目前Google在大力提倡这一概念。所谓情境搜索,就是能够感知人与人所处的环境,针对“此时此地此人”来建立模型,试图理解用户查询的目的,根本目标还是要理解人的信息需求。比如某个用户在苹果专卖店附近发出“苹果”这个搜索请求,基于地点感知及用户的个性化模型,搜索引擎就有可能认为这个查询是针对苹果公司的产品,而非对水果的需求。
elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
- 基于Apache Lucene 构建的开源搜索引擎
- 采用java编写的,提供简单易用的RESTFul API
- 轻松的横向拓展, 可以支持PB级的结构化或非结构化数据处理
在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
实时的全文搜索引擎
近实时:数据更新有1秒的延时
在操作上
狭义的上的理解:
专注于 搜索 的 非关系型 数据库
类似于mongodb
elasticsearch应用场景
- 多条件搜索
- 站内搜索
- 地理位置搜索
elasticsearch的安装
下载地址: https://elasticsearch.cn/download/
1:es是Java编写的解压即用的软件,只需要有Java的运行环境即可(需要配置java_home环境变量),如果下载的windows版本,把压缩包解压后,进入到bin目录运行elasticsearch.bat
2:浏览器输入:http://localhost:9200,看到浏览器输出服务器的信息,表示安装成功,可以使用了
版本了解
1.x
2.x
5.x
6.x
7.x
…
注意没有3, 4
原因:elk(Elasticsearch数据存储,Logstash数据加工,Kibana数据展示) 技术整合
版本选择:
最新版本或 7.x 以上都可以
ES可视化客户端-head
Elasticsearch默认的客户端工具是命令行形式的,操作起来不方便,也不直观看到数据的展示,所以我们需要去安装一个可视化插件,但是这些插件都是基于H5开发的,在谷歌的应用商店中找到elasticsearch-head插件,然后安装,使用该插件能比较直观的展示服务器中的数据,不能在谷歌插件下载的,可以到网上下载,然后打开谷歌浏览器的拓展程序添加已解压的拓展程序,安装好后点击拓展程序即可打开
ES操作客户端-kibana
步骤1:下载kibana
下载地址: https://elasticsearch.cn/download/
注意:版本必须跟es一致,安装位置不能有中文和空格
步骤2:修改配置
根/config/kibana.yml
都是默认情况,可以不用修改
步骤3:启动kibana
根/bin/kibana.bat
步骤4:访问客户端
http://localhost:5601
打开开发者工具就可以发送命令了

分词器
步骤1:下载分词器
下载地址: https://elasticsearch.cn/download/
注意:版本必须跟es一致
直接把压缩文件中的内容解压,然后放在elasticsearch安装目录/plugins下,然后重启即可

与MySQL对比核心概念

8.0版本之后放弃类type这个概念,就只是存在索引中(库),7.0版本所有的type都叫_doc
索引操作(库)
添加索引
语法:PUT /索引名
在没有特殊设置的情况下,默认有1个分片,1个备份,也可以通过请求参数的方式来指定
参数格式:
默认:
PUT my_index
明确指定:
PUT /my_index
{
"settings": {
"number_of_shards": 5, //设置5个分片
"number_of_replicas": 1 //设置1个备份
}
}
注意:
1:索引不能有大写字母
2:参数格式必须是标准的json格式
查看索引
#看单个索引
GET /索引名
#看所有索引
GET _cat/indices
删除索引
DELETE 索引名
设置映射(设计表中的列)
创建映射(创建列)
type(_doc)跟映射一起创建
语法:
PUT /索引名
{
"mappings": {
"properties": {
字段名: {
"type": 字段类型,
"analyzer": 分词器类型,
"search_analyzer": 分词器类型,
...
},
...
}
}
}
字段类型就是:数据类型
配置:analyzer search_analyzer 前提是 type:text类型
使用例子
创建类型(_doc)并设置映射(类似于mysql创建表和列)
PUT /my_index
{
"mappings": {
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
}
}
}
}
查看映射(查看表结构)
语法:
GET /索引名/_mapping
如
GET /my_index/_mapping
字段的数据类型
https://www.jianshu.com/p/01f489c46c38
有很多很多
核心类型:
text 类型:当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
keyword类型:适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过等值匹配(=)搜索到。
数值 类型:
byte
short
integer
doule
float
date类型
boolean类型
binary类型
array类型
object类型
ip类型
文档基本操作
文档添加
语法:
//必须明确指定文档id,该文档id对应列中一个_id
PUT /索引名/_doc/文档ID
{
field1: value1,
field2: value2,
...
}
//不指定指定文档id默认使用随机字符串
POST /索引名/_doc
{
field1: value1,
field2: value2,
...
}
注意:
1:当索引/映射不存在时,会使用默认设置自动添加
2:ES中的数据一般是从别的数据库导入的,所以文档的ID会沿用原数据库中的ID
3:操作时,如果指定文档id, 并且索引库中已经存在, 则执行更新操作, 否则执行添加
4:不指定id的添加, es会指定添加一个随机字符串类型_id
添加后返回的结果字段解释:
_index:所属索引
_type:所属类型
_id:文档ID
_version:乐观锁版本号
_source:数据内容
result : 命令操作类型
_shards: 分片相关信息
使用演示
需求1:新增一个文档
PUT /my_index/_doc/1
{
"id":1,
"name":"cy",
"age":18
}
文档更新
语法:
PUT /索引名/_doc/文档ID
{
field1: value1,
field2: value2,
...
}
注意:如果不指定id, 操作失败
需求:替换一个文档
PUT /my_index/_doc/1
{
"id":1,
"name":"cy",
"age":18
}
需求:一个文档中部分字段更新
POST /my_index/_update/1/
{
"doc":{
"name":"cy"
}
}
文档查看
语法:
根据ID查询单个文档
GET /索引名/_doc/文档ID
查询所有(基本查询语句)
GET /索引名/_doc/_search
结果字段解释:
took:耗时
_shards.total:分片总数
hits.total:查询到的数量
hits.max_score:最大匹配度
hits.hits:查询到的文档结果
hits.hits._score:匹配度
需求1:根据文档ID查询一个文档
GET /my_index/_doc/1
返回结果
{
"_index" : "es_index",
"_type" : "users",
"_id" : "1",
"_version" : 4,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : { //结果在这
"id" : 1,
"name" : "xiaofei",
"age" : 18
}
}
需求2:查询所有的文档
GET /my_index/_search #默认查询10个
文档删除
语法:
DELETE /索引名/类型名/文档ID
注意:这里的删除并且不是真正意义上的删除,仅仅是清空文档内容而已,并且标记该文档的状态为删除,等待一段时间后无新的内容覆盖这个文档id才会删除
需求1:根据文档ID删除一个文档
DELETE /my_index/_doc/1
全文搜索语句
match
表示全文检索,也可也做精确查询,value值会被分词器拆分,然后去倒排索引中匹配
语法:
GET /索引/_search
{
"query": {
"match": {field: value}
}
}
需求:查询商品标题中符合"游戏 手机"的字样的商品
GET /product/_search
{
"query": {
"match":{
"title": "游戏 手机"
}
}
}
multi_match
语法:
GET /索引/_search
{
"query": {
"multi_match": {
"query": value,
"fields": [field1, field2, ...]
}
}
}
multi_match:表示在多个字段间做检索,只要其中一个字段满足条件就能查询出来
需求:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品
GET /product/_search
{
"query": {
"multi_match":{
"query":"蓝牙 指纹 双卡",
"fields": ["title", "intro"]
}
}
}
中文分词器
把文本内容按照标准进行切分,默认的是standard,该分词器按照单词切分,内容转变为小写,去掉标点,遇到每个中文字符都当成1个单词处理,对我们中文不能够区分哪些是词语,所以前面会安装开源的中文分词器插件(ik分词器)
默认分词器:
GET /product/_analyze
{
"text":"I am Groot"
}
GET /product/_analyze
{
"text":"英特尔酷睿i7处理器"
}
结论:默认的分词器只能对英文正常分词,不能对中文正常分词
IK分词器的两种分词逻辑:
1、ik_max_word 【细粒度分词】
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart 【粗粒度分词】
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
使用ik分词器
GET /product/_analyze
{
"text":"I am Groot",
"analyzer":"ik_smart"
}
GET /product/_analyze
{
"text":"英特尔酷睿i7处理器",
"analyzer":"ik_smart"
}
GET /product/_analyze
{
"text":"英特尔酷睿i7处理器",
"analyzer":"ik_max_word"
}
这两种都能正常分词
拓展词库
一些陌生的词汇或新词未被收录,我们可以手动添加词汇
最简单的方式就是找到IK插件中的config/main.dic文件,往里面添加新的词汇,然后重启服务器即可
倒排索引
倒排索引源于实际应用中需要根据属性的某个值来查找这个值所在的整个文档。这种索引表中的每一项都包括一个属性值和具有该属性值的各文档的地址。由于不是
从文档中找寻是否有这个属性值,而是由属性值来确定文档的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)
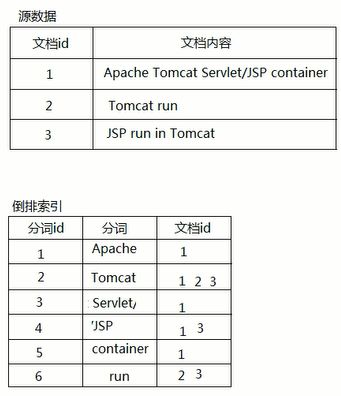
在文档添加进来的那一刻,就按照分词规则,在倒排索引表中记录一个词有哪些文档id拥有,在搜索的时候,将搜索关键词也根据分词器分词,再去匹配这个倒排索引表,结合这些词的文档id给出一个评分,再查询出对应的文档返回
高亮显示搜索的结果
语法:
GET /索引/_search
{
"query": { ... },
"highlight": {
"fields": {
field1: {},
field2: {},
...
},
"pre_tags": 开始标签,
"post_tags" 结束标签
}
}
highlight:表示高亮显示,需要在fields中配置哪些字段中检索到该内容需要高亮显示
必须配合检索(term / match)一起使用
需求:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品,并且高亮显示
GET /product/_search
{
"query": {
"multi_match":{
"query":"蓝牙 指纹 双卡",
"fields": ["title", "intro"]
}
},
"highlight": {
"fields": {
"title": {"type": "plain"},
"intro": {"type": "plain"}
},
"pre_tags": "",
"post_tags": ""
}
}
springboot集成使用elasticsearch
添加依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
配置elasticsearch
application.properties
spring.elasticsearch.rest.uris=http://ip:9200
创建实体类
@Getter
@Setter
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName="product",)
public class Product {
@Id
private String id;
//分词器,搜索分词器,数据类型
@Field(analyzer="ik_smart",searchAnalyzer="ik_smart",type = FieldType.Text)
private String title;
private Integer price;
@Field(analyzer="ik_smart",searchAnalyzer="ik_smart",type = FieldType.Text)
private String intro;
@Field(type=FieldType.Keyword)
private String brand;
}
CRUD
操作接口继承ElasticsearchRepository
//操作接口
public interface ProductRepository extends ElasticsearchRepository<Product, String>{
}
//业务接口
public interface IProductService {
void save(Product product);
void update(Product product);
void delete(String id);
Product get(String id);
List<Product> list();
}
//业务实现类
@Service
public class ProductServiceImpl implements IProductService {
@Autowired
private ProductRepository repository;
@Autowired
private ElasticsearchTemplate template;
@Override
public void save(Product product) {
repository.save(product);
}
@Override
public void update(Product product) {
repository.save(product);
}
@Override
public void delete(String id) {
repository.deleteById(id);
}
@Override
public Product get(String id) {
return repository.findById(id).get();
}
@Override
public List<Product> list() {
//可迭代对象
Iterable<Product> all = repository.findAll();
List<Product> p = new ArrayList<>();
//迭代对象并装进list中返回
all.forEach(a->p.add(a));
return p;
}
}
搜索查询
match单列搜索
// 查询商品标题中符合"游戏 手机"的字样的商品
//注入操作接口对象
@Autowired
private ProductRepository productRepository;
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
/**
* {
* query:{
* match:{title:"游戏 手机"}
* }
* }
*/
builder.withQuery(
QueryBuilders.matchQuery("title", "游戏 手机")
);
builder.withPageable(PageRequest.of(0, 100));
Page<Product> search = productRepository.search(builder.build());
search.getContent().forEach(System.err::println);
multi_match多列搜索
// 查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品
//注入操作接口对象
@Autowired
private ProductRepository productRepository;
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
/**
* {
* query:{
* multi_match:{
* "query":"蓝牙 指纹 双卡",
* "fields":["title", "intro"]
* }
* }
* }
*/
builder.withQuery(
QueryBuilders.multiMatchQuery("蓝牙 指纹 双卡", "title", "intro")
);
builder.withPageable(PageRequest.of(0, 100, Sort.Direction.DESC, "price"));
Page<Product> search = repository.search(builder.build());
search.getContent().forEach(System.err::println);
搜索高亮显示
//注入客户端操作对象
@Autowired
private ElasticsearchRestTemplate template;
//定义索引库
SearchRequest searchRequest = new SearchRequest("product");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//定义query查询
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("蓝牙 指纹 双卡等搜索关键词",
"title", "intro");
HighlightBuilder highlightBuilder = new HighlightBuilder(); // 生成高亮查询器
highlightBuilder.field("title");// 添加需要高亮查询的字段
highlightBuilder.field("intro");// 添加需要高亮查询的字段
highlightBuilder.requireFieldMatch(false); // 如果要多个字段高亮,这项要为false
highlightBuilder.preTags(""); // 高亮标签设置
highlightBuilder.postTags("");
highlightBuilder.fragmentSize(800000); // 最大高亮分片数
highlightBuilder.numOfFragments(0); // 从第一个分片获取高亮片段
Pageable pageable = PageRequest.of(开始索引, 每页大小...); // 设置分页参数
//搜索查询构建
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder) // match查询
.withPageable(pageable).withHighlightBuilder(highlightBuilder) // 设置高亮
.build();
//搜索
SearchHits<Product> searchHits = template.search(searchQuery, Product.class);
List<Product> list = new ArrayList();
//遍历搜索到的数据
for (SearchHit<Product> searchHit : searchHits) {
//获取内容返回封装的单个高亮实体对象
Product content = searchHit.getContent();
// 处理高亮
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
for (Map.Entry<String, List<String>> stringHighlightFieldEntry : highlightFields.entrySet()) {
String key = stringHighlightFieldEntry.getKey();
if (StringUtils.equals(key, "title")) {
List<String> fragments = stringHighlightFieldEntry.getValue();
StringBuilder sb = new StringBuilder();
for (String fragment : fragments) {
sb.append(fragment.toString());
}
content.setTitle(sb.toString());
}
if (StringUtils.equals(key, "intro")) {
List<String> fragments = stringHighlightFieldEntry.getValue();
StringBuilder sb = new StringBuilder();
for (String fragment : fragments) {
sb.append(fragment.toString());
}
content.setIntro(sb.toString());
}
}
list.add(content);
}
Page page = new PageImpl(list, pageable, searchHits.getTotalHits());
list.forEach(System.out::println);