Tomcat 提高 I/O性能的秘密—— AprEndpoint 组件
如果大家觉得文章有错误内容,欢迎留言或者私信讨论~
之前我们提到 Tomcat 支持 NIO、NIO.2、APR 三种连接器。我们已经讲了前两种,今天要来理解一下 APR。APR(Apache Portable Runtime Libraries)是 Apache 可移植运行时库,它是用 C 语言实现的,其目的是向上层应用程序提供一个跨平台的操作系统接口库。 它跟 NIO 一样是非阻塞的,区别就是 NIO 是通过 Java 的 NIO API 来实现非阻塞的,而 APR 则是通过 JNI 调用本地 APR 本地库而实现非阻塞 I/O 的。
那为什么 APR 会比同样是非阻塞的 NIO 快呢,这是因为在某些情况下需要同操作系统频繁交互,这时候的 Java 跟 C 还是有不小差距的。
Tomcat 本身是 Java 编写的,为了调用 C 语言编写的 APR,需要通过 JNI 方式来调用。JNI(Java Native Interface) 是 JDK 提供的一个编程接口,它允许 Java 程序调用其他语言编写的程序或者代码库,其实 JDK 本身的实现也大量用到 JNI 技术来调用本地 C 程序库。
AprEndpoint 工作过程
下面还是通过一张图来帮你理解 AprEndpoint 的工作过程:
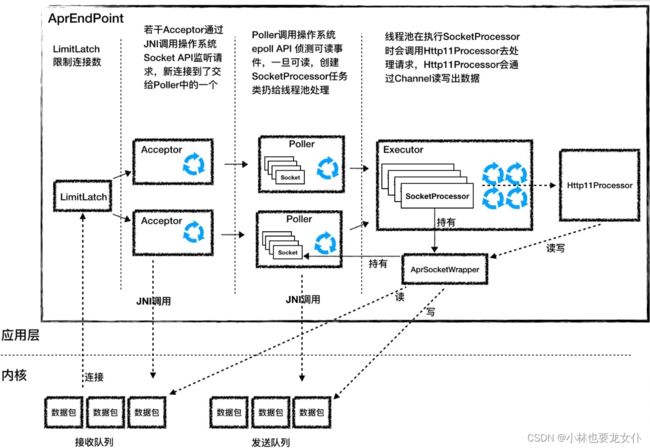
你会发现它跟 NIO 非常相似,实际上在具体实现只有 Acceptor 和 Poller 的不同。
Acceptor
Acceptor 的功能就是监听连接,并接受建立连接。它的本质就是调用了四个操作系统 API:Socket、Bind、Listen 和 Accept。 上面也说了 Java 想要调用 C 语言 API 就需要通过 JNI。具体来说就是分为两步:
- 第一步,先封装个 Java 类,然后用
native关键字修饰:
public class Socket {
...
//用native修饰这个方法,表明这个函数是C语言实现
public static native long create(int family, int type, int protocol, long cont)
public static native int bind(long sock, long sa);
public static native int listen(long sock, int backlog);
public static native long accept(long sock)
}
- 第二步,接着用 C 语言实现这些代码,比如 Bind 的代码就是这样实现的:
//注意函数的名字要符合JNI规范的要求
JNIEXPORT jint JNICALL
Java_org_apache_tomcat_jni_Socket_bind(JNIEnv *e, jlong sock,jlong sa)
{
jint rv = APR_SUCCESS;
tcn_socket_t *s = (tcn_socket_t *)sock;
apr_sockaddr_t *a = (apr_sockaddr_t *) sa;
//调用APR库自己实现的bind函数
rv = (jint)apr_socket_bind(s->sock, a);
return rv;
}
这里就不细讲 JNI, 感兴趣的小伙伴可以私下去了解。我们要注意的是函数名字要符合 JNI 的规范,以及 Java 和 C 语言如何互相传递参数,比如在 C 语言有指针,Java 没有指针的概念,所以在 Java 中用 long 类型来表示指针。
Poller
Acceptor 接受到一个新的 socket 之后,按照 NioEndpoint 就会把这个 socket 交给 poller 去查询 I/O 事件。AprNioEndpoint 也是这样做的,只不过它并不是调用 Java NIO 里的 Selector 来查询 Socket 的状态,而是通过 JNI 调用 APR 中的 poll 方法,而 APR 又是调用了操作系统的 epoll API 来实现的。
APR 提升性能的秘密
APR 除了本身利用 c 语言的特性之后还有其他的提速手段吗?
JVM 堆 vs 本地内存
我们知道 Java 的类实例一般在 JVM 堆上分配,而 Java 是通过 JNI 调用 C 代码来实现 Socket 通信的,那么 C 代码在运行过程中需要的内存又是从哪里分配的呢?C 代码能否直接操作 Java 堆?
为了回答这些问题,需要先来说说 JVM 和用户进程的关系。比如你现在想运行一个 Java 类的文件:
java my.class
这个命令行中的java其实是一个可执行程序,这个程序会创建 JVM 来加载和运行你的 Java 类。 操作系统会创建一个 java 可执行程序,而每个进程都有自己的虚拟地址空间,JVM 用到的内存(包括堆、栈和方法区)就是从进程的虚拟地址空间上分配的。注意,JVM 内存只是进程空间的一部分,除此之外进程空间内还有代码段、数据段、内存映射区、内核空间等。从 JVM 的角度看,JVM 内存之外的部分叫作本地内存,C 程序代码在运行过程中用到的内存就是本地内存中分配的。如下:
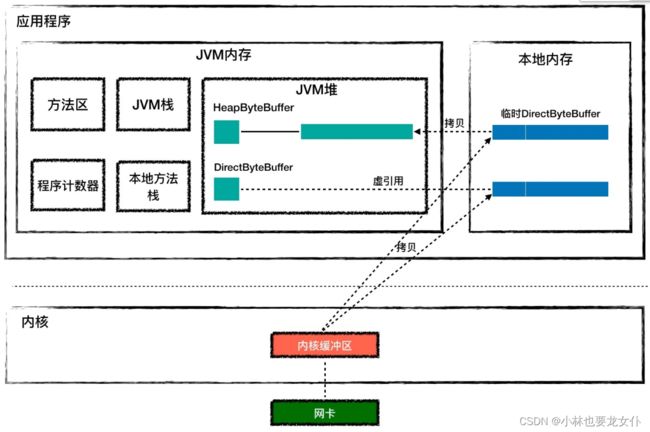
Tomcat 的 Endpoint 组件在接收网络数据时需要预先分配好一块 Buffer,所谓的 Buffer 就是字节数组byte[],Java 通过 JNI 调用把这块 Buffer 的地址传给 C 代码,C 代码通过操作系统 API 读取 Socket 并把数据填充到这块 Buffer。Java NIO API 提供了两种 Buffer 来接收数据:HeapByteBuffer 和 DirectByteBuffer,下面的代码演示了如何创建两种 Buffer。
//分配HeapByteBuffer
ByteBuffer buf = ByteBuffer.allocate(1024);
//分配DirectByteBuffer
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
创建好 Buffer 后直接传给 Channel 的 read 或者 write 函数,最终这块 Buffer 会通过 JNI 调用传递给 C 程序。
//将buf作为read函数的参数
int bytesRead = socketChannel.read(buf);
那 HeapByteBuffer 和 DirectByteBuffer 有什么区别呢?HeapByteBuffer 对象本身在 JVM 堆上分配,并且它持有的字节数组byte[]也是在 JVM 堆上分配。但是如果用 HeapByteBuffer 来接收网络数据,需要把数据从内核先拷贝到一个临时的本地内存,再从临时本地内存拷贝到 JVM 堆,而不是直接从内核拷贝到 JVM 堆上。 这是为什么呢?这是因为数据从内核拷贝到 JVM 堆的过程中,JVM 可能会发生 GC,GC 过程中对象可能会被移动,也就是说 JVM 堆上的字节数组可能会被移动,这样的话 Buffer 地址就失效了。如果这中间经过本地内存中转,从本地内存到 JVM 堆的拷贝过程中 JVM 可以保证不做 GC。
也就是说使用 HeapByteBuffer 中间多了一层中转。而 DirectByteBuffer 用来解决这个问题,DirectByteBuffer 对象本身在 JVM 堆上,但是它持有的字节数组不是从 JVM 堆上分配的,而是从本地内存分配的。 DirectByteBuffer 对象中有个 long 类型字段 address,记录着本地内存的地址,这样在接收数据的时候,直接把这个本地内存地址传递给 C 程序,C 程序会将网络数据从内核拷贝到这个本地内存,JVM 可以直接读取这个本地内存,这种方式比 HeapByteBuffer 少了一次拷贝,因此一般来说它的速度会比 HeapByteBuffer 快好几倍。你可以通过上面的图加深理解。
Tomcat 中的 AprEndpoint 就是通过 DirectByteBuffer 来接收数据的。
sendfile
我们再来考虑另一个网络通信的场景,也就是静态文件的处理。浏览器通过 Tomcat 来获取一个 HTML 文件,而 Tomcat 的处理逻辑无非是两步:
- 从磁盘读取 HTML 到内存。
- 将这段内存的内容通过 Socket 发送出去。
但实际上要发生很多次的内存拷贝:
- 读取文件时,首先是内核把文件内容读取到内核缓冲区。
- 如果使用 HeapByteBuffer,文件数据从内核到 JVM 堆内存需要经过本地内存中转。
- 同样在将文件内容推入网络时,从 JVM 堆到内核缓冲区需要经过本地内存中转。
- 最后还需要把文件从内核缓冲区拷贝到网卡缓冲区。
从下面的图你会发现这个过程有 6 次内存拷贝,并且 read 和 write 等系统调用将导致进程从用户态到内核态的切换,会耗费大量的 CPU 和内存资源。

而 Tomcat 的 AprEndpoint 通过操作系统层面的 sendfile 特性解决了这个问题,sendfile 系统调用方式非常简洁。
sendfile(socket, file, len);
它带有两个关键参数:Socket 和文件句柄。将文件从磁盘写入 Socket 的过程只有两步:
- 将文件内容读取到内核缓冲区。
- 数据并没有从内核缓冲区复制到 Socket 关联的缓冲区,只有记录数据位置和长度的描述符被添加到 Socket 缓冲区中;接着把数据直接从内核缓冲区传递给网卡。这个过程你可以看下面的图。
