【机器学习杂记】Transformer
零 前言
Transformer考虑之前提到的seq2seq问题:输出长度未知。
Seq2Seq的基本模型如下:
下面逐块解释。先说模型的大体框架是什么,然后再说Transformer当中是怎么做的。
\space
一 Encoder
Encoder的任务就是输入一排向量,输出同等数量的向量。完成这个任务可以用Self-attention、CNN、RNN等。
Encoder的框图如下:
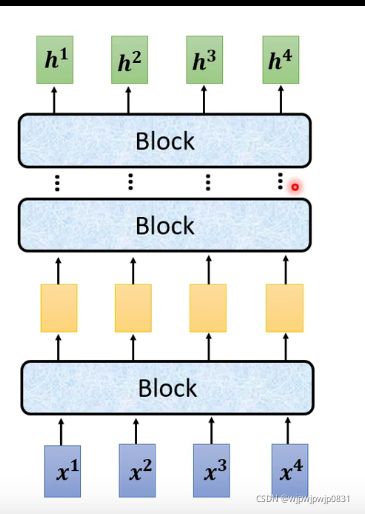
\space
可以看到,输入向量经过很多个Block再输出同等数量的向量。一个Block当中做了好几个layer做的事情。例如,在Transformer里,输入向量序列先经过一个Multi-head Self-attention,然后经过由Fully connection构成的feed forward network.
具体地,Transformer采用了residual connection(残差连接),也就是将Self-attention的输出和原本的输入相加。而后再经过一个Layer Normalization(有关Layer Normalization和Batch Normalization的区别,参见知乎),向量里各元素减去均值再比标准差,得到新向量。框图如下:
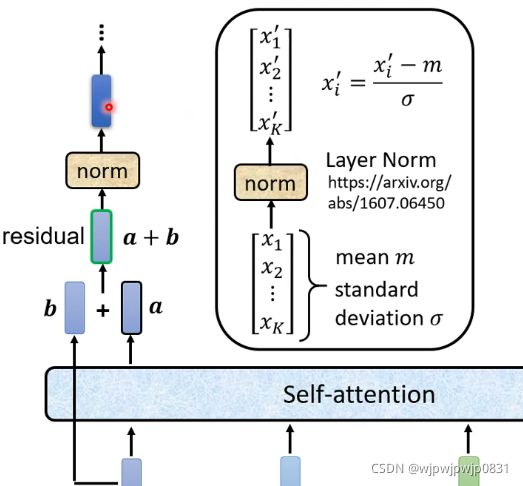
\space
现在得到的输出,再经过Fully connective network,仍然采用Residual方法,且再经过一个Norm,如图:
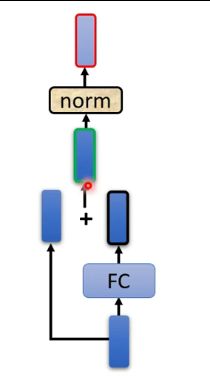
\space
最终的输出才是Block的一个输出。
\space
Transformer的Encoder的架构是:
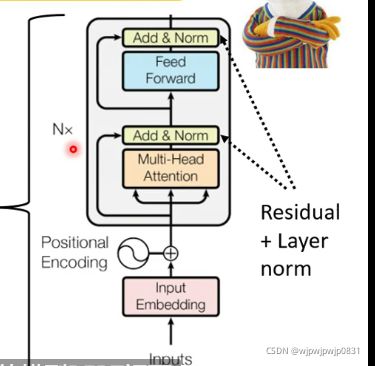
注意: 在输入之后加入了Positional Encoding,一共有 N N N个这样的Block级联。
\space
二 Decoder
Decoder可以分为Autoregressive和Non-Autoregressive。先重点学第一种。
\space
2.1 Autoregressive Decoder
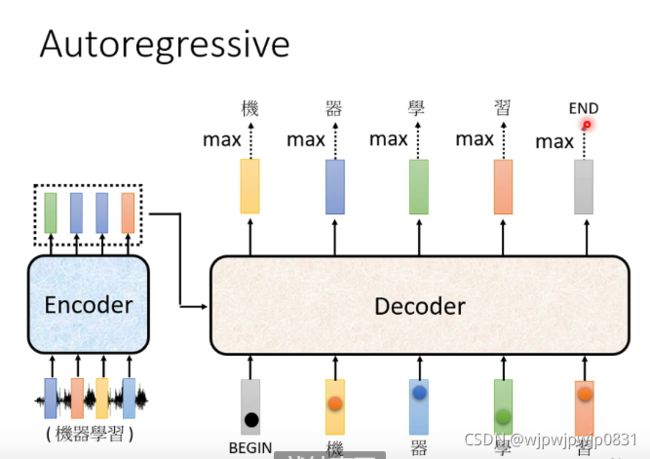
以语音辨识这个应用为例说明(MOT是怎么用的还要学习),首先之前说Encoder输出了一组向量,这组向量要作为Decoder的输入。在Decoder开始工作时,首先要输入一个Begin的token,然后在里面进行计算,输出第一个识别出的word。
所不同的是,下一步Decoder会结合上一次的输出来进行下一个word的辨识。 例如,语音输入“机器学习”这四个字,Decoder接收到Encoder的vector sequence和Begin这个token以后,先输出“机”(可以理解成分类任务,用独热编码表示分类结果,向量长度是Vocabulary的数量),然后下一步根据“机”和之前的输入输出“器”。以此类推。
那么如何结束呢?结束的时候也是用一个特殊的Token,叫做Stop Token。一般Begin和Stop用的是同一个符号。
这个过程可以用下面的图表示:
\space
Transformer中Decoder的架构如下:

\space
观察发现,把block里第二层的Multi-head Attention和Add & Norm去掉(实际上这一层是和Encoder相连接的),架构基本和Encoder一模一样。 所不同的是第一步采用的是Masked Multi-head Attention。
- Masked Multi-head Attention:
所谓Masked,就是在计算Vector sequence里第 i i i个输入的时候,我们要计算一个 b i b^i bi,以往是并行考虑所有的输入,但Masked就是只考虑第 i i i个输入以及之前的。例如计算 b 2 b^2 b2的时候:

ps:Masked有没有一点点像“即时”的感觉,始终根据新的输入计算输出。
\space
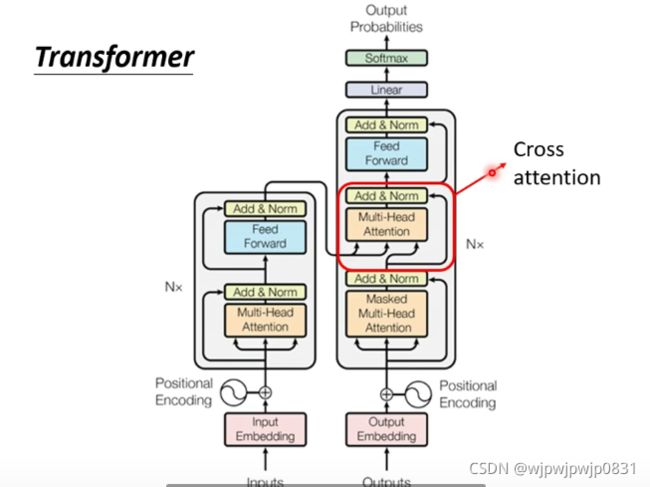
知道了Encoder和Decoder,整个Transformer的架构如下图:
\space
红框里框出的部分是Decoder和Encoder相连的部分,其接受Encoder的输入,叫做Cross Attention,所谓Cross,就是不仅要Attend自己,还要Attend Encoder。 计算过程如下:
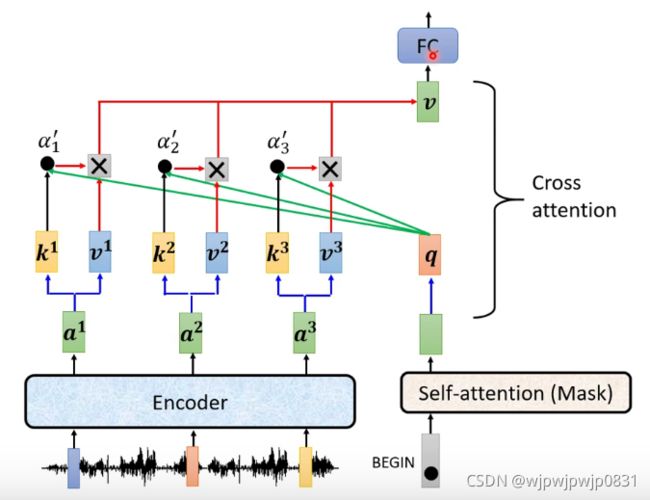
解读: a 1 , a 2 , a 3 a^1,a^2,a^3 a1,a2,a3是Encoder输出的向量。Decoder接收了这组向量后,计算 k , v k,v k,v,并且在开始时,接收一个Begin,吐出一个向量,计算这个向量的 q q q。由 k i k^i ki和 q q q计算出 α i \alpha^i αi(可能会做softmax一类的),然后根据 α i \alpha^i αi和 v i v^i vi计算 v v v, v v v会被送入后来的FC Network。
注意: 在Transformer的模型里,Decoder不管哪一层Block,接受的都是整个Encoder的输出。实际上不一定要这么做,好多人探索了其他的方式。
\space
2.2 Non-Autoregressive Decoder
先记一下和Autoregressive 的对比,之后以后需要了仔细学一学。
对于AT(Autoreg),其更像是 “异步”。在输出句子的过程中不断需要知道之前的输出,但是NAT(Non-Autoreg),更像是 “同步”,它接受一堆Begin和Encoder,就一下子输出整个句子。
如何训练NAT的输出长度,往往有两种办法。一种是加入额外的网络来预测长度,二是用一个足够长的序列,然后预测End。
\space
三 如何训练?
核心就是让输出尽可能接近正确答案。之前说采用的one hot编码,那我们就是要最小化和正确答案之间的交叉熵。尤其重要的是,也要训练End Token的输出,这也是让机器自己学习输出长度的精髓。
尤其尤其值得注意,在训练的时候,Decoder的输入不是之前预测的输出,而是正确答案。也就是在train的时候我们给Decoder看了正确答案。这种思想叫做Teacher forcing。示意图如下:

\space
- 训练Seq2Seq model的Tips:
待补充