Redis深入理解七 :Redis 缓存应用级别架构思想
缓存分析
缓存的分类
- 客户端缓存
- 页面缓存 localstorage
- 浏览器缓存 cache Expires
- APP上的缓存
- 内存
- 文件
- SQLite
- 网络缓存
- Web代理缓存 (正向代理(公司内网登录之后才可以上网)、反向代理(Nginx)和透明代理)
- 边缘缓存 CDN
- 服务端缓存
- 应用级缓存 Ehcache、Voldemort、Caffeine
- 平台级缓存 Redis、MongoDB、Memcached
- 数据库缓存 InnoDB innodb_buffer_pool_size (设置为物理内存的一半)
innodb_buffer_pool_size #整个Mysql BufferPool的大小 一般是50%到80% (75%)
innodb_buffer_pool_instances #并发加锁冲突 多线程访问同一块bufferPool 分段锁(建议一个G对应一个bufferPool)
join_buffer_size #join 连接给的大小 buffer_pool_size*3/4
sort_buffer_size #sort 排序给的大小 buffer_pool_size/2
read_rnd_buffer_size #随机读取时给的大小 buffer_pool_size/2
缓存的数据一致性
- 先更新缓存,再更新数据库 (一般不考虑)
- 先更新数据库,再更新缓存 (一般不考虑)
先删除缓存,后更新数据库

如何解决呢?其实最简单的解决办法就是延时双删的策略
- 先淘汰缓存
- 再写数据库
- 休眠1秒(自行评估),再次淘汰缓存
Mysql 的读写分离的架构的话,那么其实主从同步之间也会有时间差
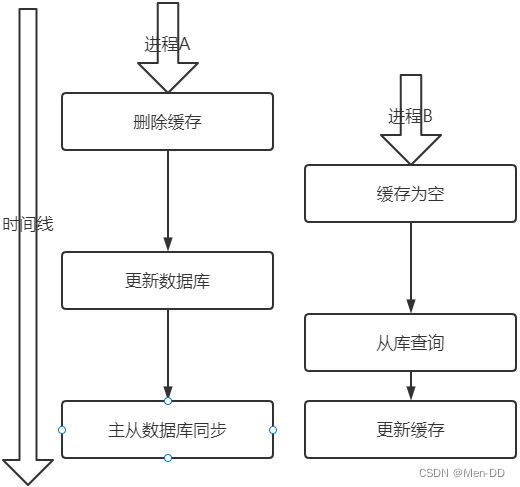
- 还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
- 就是如果是对 Redis 进行填充数据的查询数据库操作,那么就强制将其指向主库进行查询。
采用这种同步淘汰策略,吞吐量降低怎么办?
- 那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
先删除缓存值再更新数据库有可能导致请求因缓存缺失而访问数据库,给数据库带来压力
业务应用中读取数据库和写缓存的时间有时不好估算,导致延迟双删中的sleep时间不好设置
先更新数据库,后删除缓存 (常用)(Cache Aside Pattern)

如果发生上述情况,确实是会发生脏数据。然而,发生这种情况的概率又有多少呢?
- 先天性条件,(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)
一定要解决怎么办?如何解决上述并发问题?
- 给缓存设有效时间是一种方案
- 采用异步延时删除策略
更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功怎么办?
-
利用消息队列进行删除的补偿, 会对业务代码造成大量的侵入,深深的耦合在一起

-
Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作
利用工具(canal)将binlog日志采集发送到MQ中,然后通过ACK机制确认处理删除缓存

缓存更新的设计模式
- Cache Aside
缓存一致性如果追求强一致- 串行化
- 使用分布式读写锁
- 通过2PC或是Paxos协议保证一致性
- 拼命的降低并发时脏数据的概率
而一般大厂包括Facebook都选择了使用这个降低概率的做法,因为强一致的实现性能往往比较差,而且比较复杂,还要考虑各种容错问题
- Read/Write Through
后端就是一个单一的存储,而存储自己维护自己的Cache, 把更新数据库(Repository)的操作由缓存自己代理了 - Read Through
在查询操作中更新缓存,当缓存失效的时候(过期或LRU换出),缓存服务自己来加载,从而对应用方是透明的 - Write Through
当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库 - Write Behind Caching
Write Behind 又叫 Write Back。Linux文件系统的Page Cache也是同样算法
在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库
优化路径
cache 优化
-
原始路径

-
原始路径+Redis集群

-
原始路径+应用级Cache+Redis集群
TIPS:Caffeine基于Google的Guava Cache,提供一个性能卓越的本地缓存(local cache) 实现, 也是SpringBoot内置的本地缓存实现,有资料表明Caffeine性能是Guava Cache的6倍

4. 原始路径+应用级Cache+Redis集群+预热
- 应用级Cache预热 — 从远程获得相关的数据写入本地的Caffeine缓存
org.springframework.boot.CommandLineRunner
@Slf4j
@Component
public class preheatCache implements CommandLineRunner {
@Autowired
private HomeService homeService;
@Override
public void run(String... args) throws Exception {
for(String str : args) {
log.info("系统启动命令行参数: {}",str);
}
homeService.preheatCache();
}
}
- 平台级Cache预热 — 数据从MySQL数据写入到Redis集群
@Slf4j
@Component
public class preheatCache implements CommandLineRunner {
@Autowired
private HomePromotionService homePromotionService;
@Override
public void run(String... args) throws Exception {
for(String str : args) {
log.info("系统启动命令行参数: {}",str);
}
homePromotionService.content(ConstantPromotion.HOME_GET_TYPE_ALL);
}
}
数据一致性 过期时间+Async+Canal
- 本地Caffeine缓存,设置了过期时间(30分钟)
@Configuration
public class CaffeineCacheConfig {
@Bean(name = "promotion")
public Cache<String, HomeContentResult> promotionCache() {
int rnd = ThreadLocalRandom.current().nextInt(10);
return Caffeine.newBuilder()
// 设置最后一次写入经过固定时间过期
.expireAfterWrite(30 + rnd, TimeUnit.MINUTES)
// 初始的缓存空间大小
.initialCapacity(20)
// 缓存的最大条数
.maximumSize(100)
.build();
}
....
}
- 异步任务的形式的刷新缓存,每分钟检查一次本地Caffeine缓存是否已无效,无效则刷新缓存
@Service
@Slf4j
public class RefreshPromotionCache {
....
@Async
@Scheduled(initialDelay=5000*60,fixedDelay = 1000*60)
public void refreshCache(){
if(promotionRedisKey.isAllowLocalCache()){
log.info("检查本地缓存[promotionCache] 是否需要刷新...");
final String brandKey = promotionRedisKey.getBrandKey();
if(null == promotionCache.getIfPresent(brandKey)||null == promotionCacheBak.getIfPresent(brandKey)){
log.info("本地缓存[promotionCache] 需要刷新");
HomeContentResult result = homeService.getFromRemote();
if(null != result){
if(null == promotionCache.getIfPresent(brandKey)) {
promotionCache.put(brandKey,result);
log.info("刷新本地缓存[promotionCache] 成功");
}
if(null == promotionCacheBak.getIfPresent(brandKey)) {
promotionCacheBak.put(brandKey,result);
log.info("刷新本地缓存[promotionCache] 成功");
}
}else{
log.warn("从远程获得[promotionCache] 数据失败");
}
}
}
}
}
- 平台型Cache Redis集群中的数据,利用Canal监测数据库的更新,然后删除缓存中的对应部分
Canal 依赖
<dependency>
<groupId>com.alibaba.ottergroupId>
<artifactId>canal.clientartifactId>
<version>1.1.4version>
<exclusions>
<exclusion>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-clientartifactId>
exclusion>
exclusions>
dependency>
Canal 配置
canal:
server:
ip: canal.localhost.com
port: 9933
# product:
# destination: product
# indexName: product_db
# batchSize: 1000
promotion:
destination: promotion
batchSize: 1000
seckill:
destination: seckill
batchSize: 1000
Canal Bean
@Configuration
@EnableScheduling
@EnableAsync
public class CanalPromotionConfig {
@Value("${canal.server.ip}")
private String canalServerIp;
@Value("${canal.server.port}")
private int canalServerPort;
@Value("${canal.server.username:blank}")
private String userName;
@Value("${canal.server.password:blank}")
private String password;
@Value("${canal.promotion.destination}")
private String destination;
@Bean("promotionConnector")
public CanalConnector newSingleConnector(){
String userNameStr = "blank".equals(userName) ? "" : userName;
String passwordStr = "blank".equals(password) ? "" : password;
return CanalConnectors.newSingleConnector(new InetSocketAddress(canalServerIp,
canalServerPort), destination, userNameStr, passwordStr);
}
}
Canal 同步
@Service
@Slf4j
public class PromotionData implements IProcessCanalData {
private final static String SMS_HOME_ADVERTISE = "sms_home_advertise";
private final static String SMS_HOME_BRAND = "sms_home_brand";
private final static String SMS_HOME_NEW_PRODUCT = "sms_home_new_product";
private final static String SMS_HOME_RECOMMEND_PRODUCT = "sms_home_recommend_product";
/*存储从表名到Redis缓存的键*/
private Map<String,String> tableMapKey = new HashMap<>();
@Autowired
@Qualifier("promotionConnector")
private CanalConnector connector;
@Autowired
private PromotionRedisKey promotionRedisKey;
@Autowired
private RedisClusterUtil redisOpsExtUtil;
@Value("${canal.promotion.subscribe:server}")
private String subscribe;
@Value("${canal.promotion.batchSize}")
private int batchSize;
@PostConstruct
@Override
public void connect() {
tableMapKey.put(SMS_HOME_ADVERTISE,promotionRedisKey.getHomeAdvertiseKey());
tableMapKey.put(SMS_HOME_BRAND,promotionRedisKey.getBrandKey());
tableMapKey.put(SMS_HOME_NEW_PRODUCT,promotionRedisKey.getNewProductKey());
tableMapKey.put(SMS_HOME_RECOMMEND_PRODUCT,promotionRedisKey.getRecProductKey());
connector.connect();
if("server".equals(subscribe))
connector.subscribe(null);
else
connector.subscribe(subscribe);
connector.rollback();
}
@PreDestroy
@Override
public void disConnect() {
connector.disconnect();
}
@Async
@Scheduled(initialDelayString="${canal.promotion.initialDelay:5000}",fixedDelayString = "${canal.promotion.fixedDelay:5000}")
@Override
public void processData() {
try {
if(!connector.checkValid()){
log.warn("与Canal服务器的连接失效!!!重连,下个周期再检查数据变更");
this.connect();
}else{
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
log.info("本次[{}]没有检测到促销数据更新。",batchId);
}else{
log.info("本次[{}]促销数据本次共有[{}]次更新需要处理",batchId,size);
/*一个表在一次周期内可能会被修改多次,而对Redis缓存的处理只需要处理一次即可*/
Set<String> factKeys = new HashSet<>();
for(CanalEntry.Entry entry : message.getEntries()){
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
String tableName = entry.getHeader().getTableName();
if(log.isDebugEnabled()){
CanalEntry.EventType eventType = rowChange.getEventType();
log.debug("数据变更详情:来自binglog[{}.{}],数据源{}.{},变更类型{}",
entry.getHeader().getLogfileName(),entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(),tableName,eventType);
}
factKeys.add(tableMapKey.get(tableName));
}
for(String key : factKeys){
if(StringUtils.isNotEmpty(key)) redisOpsExtUtil.delete(key);
}
connector.ack(batchId); // 提交确认
log.info("本次[{}]处理促销Canal同步数据完成",batchId);
}
}
} catch (Exception e) {
log.error("处理促销Canal同步数据失效,请检查:",e);
}
}
}
刷新
双缓存 — 有规律毛刺现象问题
- promotionBak 将备份缓存作为降级和兜底方案
@Configuration
public class CaffeineCacheConfig {
@Bean(name = "promotion")
public Cache<String, HomeContentResult> promotionCache() {
int rnd = ThreadLocalRandom.current().nextInt(10);
return Caffeine.newBuilder()
// 设置最后一次写入经过固定时间过期
.expireAfterWrite(30 + rnd, TimeUnit.MINUTES)
// 初始的缓存空间大小
.initialCapacity(20)
// 缓存的最大条数
.maximumSize(100)
.build();
}
/*以双缓存的形式提升首页的访问性能,这个备份缓存其实设置为永不过期更好,
* 可以作为首页的降级和兜底方案
* 为了说明缓存击穿和分布式锁这里设置了一个过期时间*/
@Bean(name = "promotionBak")
public Cache<String, HomeContentResult> promotionCacheBak() {
int rnd = ThreadLocalRandom.current().nextInt(10);
return Caffeine.newBuilder()
// 设置最后一次访问经过固定时间过期
.expireAfterAccess(41 + rnd, TimeUnit.MINUTES)
// 初始的缓存空间大小
.initialCapacity(20)
// 缓存的最大条数
.maximumSize(100)
.build();
}
...
}
- 将备份缓存作为降级和兜底方案
/*先从本地缓存中获取推荐内容*/
HomeContentResult result = allowLocalCache ? promotionCache.getIfPresent(brandKey) : null;
if(result == null){
result = allowLocalCache ? promotionCacheBak.getIfPresent(brandKey) : null;
}
/*本地缓存中没有*/
if(result == null){
log.warn("从本地缓存中获取推荐品牌和商品失败,可能出错或禁用了本地缓存[allowLocalCache = {}]",allowLocalCache);
result = getFromRemote();
if(null != result) {
promotionCache.put(brandKey,result);
promotionCacheBak.put(brandKey,result);
}
}
- 刷新 每次都需要刷新 promotionCacheBak
@Async
@Scheduled(initialDelay=5000*60,fixedDelay = 1000*60)
public void refreshCache(){
if(promotionRedisKey.isAllowLocalCache()){
log.info("检查本地缓存[promotionCache] 是否需要刷新...");
final String brandKey = promotionRedisKey.getBrandKey();
if(null == promotionCache.getIfPresent(brandKey)||null == promotionCacheBak.getIfPresent(brandKey)){
log.info("本地缓存[promotionCache] 需要刷新");
HomeContentResult result = homeService.getFromRemote();
if(null != result){
if(null == promotionCache.getIfPresent(brandKey)) {
promotionCache.put(brandKey,result);
log.info("刷新本地缓存[promotionCache] 成功");
}
promotionCacheBak.put(brandKey,result);
log.info("刷新本地缓存[promotionCache] 成功");
}else{
log.warn("从远程获得[promotionCache] 数据失败");
}
}
}
}
降级方案 — 服务异常
if(CollectionUtils.isEmpty( secKills)){
/*极小的概率出现本地两个缓存同时失效的问题,
从远程获取时,只从Redis缓存中获取,不从营销微服务中获取,
避免秒杀的流量冲垮营销微服务*/
secKills = getSecKillFromRemote();
if(!CollectionUtils.isEmpty(secKills)) {
secKillCache.put(secKillKey,secKills);
secKillCacheBak.put(secKillKey,secKills);
}else{
/*Redis缓存中也没有秒杀活动信息,此处用一个空List代替,
* 其实可以用固定的图片或信息,作为降级和兜底方案*/
secKills = new ArrayList<FlashPromotionProduct>();
}
}
其他
- 布隆过滤器
- 分布式锁
大厂Redis Cluster方式
1. Redis Cluster是如何解决高可用问题的呢?
增加从节点,做主从复制
Redis Cluster 支持为每个分片增加一个或多个从节点。并且内部通过选举来确定有主节点的存活
2. 为什么大厂不用Redis Cluster构建集群?
主要原因是,它采用了去中心化的设计。Redis Cluster 采用了一种去中心化的流言(Gossip)协议来传播集群配置的变化。
流言协议也有缺点,那就是传播速度比较慢,而且是集群规模越大,传播的速度就越慢
所以Redis Cluster非常适合用于构建中小规模的Redis集群,这里的中小规模指的是,大概几个到几十个节点这样规模的Redis集群。
3. 为什么槽的范围是0 ~16383?
Redis 作者回答 https://github.com/redis/redis/issues/2576
Redis集群中,在握手成功后,节点之间会定期发送ping/pong消息,交换数据信息,集群中节点数量越多,消息体内容越大,比如说10个节点的状态信息约1kb。同时redis集群内节点,每秒都在发ping消息。在这种情况下,一个总节点数为200的Redis集群,默认情况下,这时ping/pong消息占用带宽达到25M,这还只是槽的范围是0 ~16383的情况。
如果槽位设计为65536,光发送心跳信息的消息头可达8k,发送的心跳包过于庞大,非常浪费带宽。
其次redis的集群主节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。
那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了,可以以确保每个 master 有足够的插槽,没有必要拓展到65536个。
所以Redis作者决定取16384个槽,作为一个设计权衡。
4. 如何用Redis构建超大规模集群?
用Redis构建超大规模集群可以采用多种方式
1. 基于代理的方式
- 负责在客户端和Redis节点之间转发请求和响应,客户端只与代理服务打交道,代理收到客户端的请求之后,会转发到对应的Redis节点上,节点返回的响应再经由代理转发返回给客户端。
- 负责监控集群中所有Redis节点的状态,如果发现存在问题节点,就及时进行主从切换。
- 维护集群的元数据,这个无数据主要是集群所有节点的主从信息,以及槽和节点的关系映射表。像开源的Redis集群方案twemproxy 和 Codis,采用的都是代理服务这种架构。
优点:对客户端透明,从客户端的视角来看,整个集群就像是一个超大容量的单节点Redis一样。除此之外,由于分片算法是受代理服务控制的,因此扩容比较方便,新节点加入集群后,直接修改代理服务中的元数据就可以完成扩容。
缺点:由于增加了一层代理转发,因此每次数据访问的链路变得更长了,这必然会导致一定的性能损失。而且代理服务本身也是集群的单点。当然,我们可以把代理服务也做成一个集群来解决单点问题,那样集群就更复杂了。
2. 不使用代理服务,只是把代理服务的寻址功能前移到客户端中
客户端在发起请求之前,首先会查询元数据,这样就可以知道要访问的是哪个分片和哪个节点,然后直连对应的Redis节点访问数据即可
客户端不用每次都去查询元数据,因为这个元数据基本上是很少会发生变化的,客户端可以自行缓存元数据,这样访问性能基本上就与单机版的Redis 一样了。如果某个分片的主节点宕机了,就会选举新的主节点,并更新元数据中的信息。对集样的扩容操作也比较简单,除了必须完成数据的迁移工作之外,再更新一下元数据就可以了
元数据服务仍然是一个单点,但是它的数据量不大,访问量也不大,相对来说比较容易实现。利用已有的ZooKeeper、etcd甚至MySQL都可以被用来实现上述元数据服务。
缓存实战

cache 分析
@Service
public class ProductService {
@Autowired
private ProductDao productDao;
@Autowired
private RedisUtil redisUtil;
@Transactional
public Product create(Product product) {
Product productResult = productDao.create(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult));
return productResult;
}
@Transactional
public Product update(Product product) {
Product productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult));
return productResult;
}
public Product get(Long productId) {
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
product = JSON.parseObject(productStr, Product.class);
return product;
}
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult));
}
return product;
}
}
public interface RedisKeyPrefixConst {
String PRODUCT_CACHE = "product:cache:"; //产品基础信息缓存前缀
}
问题分析1: 数据量小可以,如果数据量比较大上千万上亿数据全部放Redis?
public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;
public static final String EMPTY_CACHE = "{}";
public static final String LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX = "lock:product:hot_cache_create:";
public static final String LOCK_PRODUCT_UPDATE_PREFIX = "lock:product:update:";
思路1: 设置有效时间: demo 1 day
@Transactional
public Product update(Product product) {
Product productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult), PRODUCT_CACHE_TIMEOUT, TimeUnit.SECONDS);
return productResult;
}
思路2: 简单版本数据的冷热分离:查询数据时给数据设置延期
public Product get(Long productId) {
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
product = JSON.parseObject(productStr, Product.class);
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //数据延期
return product;
}
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
}
return product;
}
思路3: 缓存击穿:(批量更新、批量导入 导致 大批量缓存的失效时间是一样的) — 设置随机时间
private Integer genProductCacheTimeout() {
//加随机超时机制解决缓存批量失效(击穿)问题
return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(6) * 60 * 60;
}
思路4: 缓存穿透: (查询一个根本不存在的数据 cache/db 都查询不到)-- 缓存空对象 、 布隆过滤器
缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。 造成缓存穿透的基本原因有两个:
第一, 自身业务代码或者数据出现问题。
第二, 一些恶意攻击、 爬虫等造成大量空命中。
1. 缓存空对象 & 空数据延期(单个空商品ID)
public Product get(Long productId) {
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
if (EMPTY_CACHE.equals(productStr)) {
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS); //数据延期
return null; //空数据返回null
}
product = JSON.parseObject(productStr, Product.class);
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //数据延期
return product;
}
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); // 查询不到缓存空数据
}
return product;
}
private Integer genEmptyCacheTimeout() {
return 60 + new Random().nextInt(30);
}
2. 布隆过滤器(大量空商品ID)·
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不 存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在; 当它说不存在时,那就肯定不存在。
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。 所谓无偏就是能够把元素的 hash 值算得 比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度 进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就 完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位 置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组 比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为 复杂, 但是缓存空间占用很少。
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,布隆过滤器
缓存过滤伪代码:
//初始化布隆过滤器
RBloomFilter<String>bloomFilter=redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
//把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
// 从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "数据不存在";
}
............
注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
思路5:突发缓存热点重建:(直播带货) ---- synchronized 锁重建 (问题:单节点、所有商品)
public Product get(Long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
synchronized (this) {
product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); // 查询不到缓存空数据
}
}
return product;
}
private Product getProductFromCache(String productCacheKey) {
Product product = null;
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
if (EMPTY_CACHE.equals(productStr)) {
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
}
product = JSON.parseObject(productStr, Product.class);
//缓存读延期
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
}
return product;
}
- 问题1:synchronized (this) 是单节点有效
- 问题2:synchronized (this) 锁的是所有商品
思路5:突发缓存热点重建:(直播带货) ---- 分布式锁 Redisson
public Product get(Long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
RLock hotDataCacheCreateLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX+productId);
hotDataCacheCreateLock.lock();
try {
product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); // 查询不到缓存空数据
}
} finally {
hotDataCacheCreateLock.unlock();
}
return product;
}
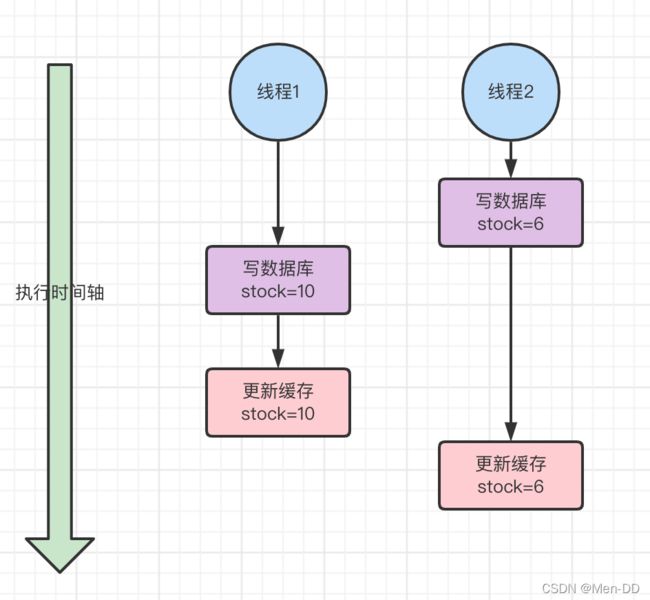
思路5:缓存与数据库数据双写不一致问题 — 分布式锁
@Transactional
public Product create(Product product) {
RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock productUpdateLock = productUpdateLock.lock();
try {
Product productResult = productDao.create(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(productResult), genProductCacheTimeout(), TimeUnit.SECONDS);
} finally {
productUpdateLock.unlock();
}
return productResult;
}
@Transactional
public Product update(Product product) {
RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock productUpdateLock = productUpdateLock.lock();
try {
Product productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(productResult), genProductCacheTimeout(), TimeUnit.SECONDS);
} finally {
productUpdateLock.unlock();
}
return productResult;
}
public Product get(Long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
RLock hotDataCacheCreateLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX+productId);
hotDataCacheCreateLock.lock();
try {
product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock productUpdateLock = productUpdateLock.lock();
try {
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); // 查询不到缓存空数据
}
} finally {
productUpdateLock.unlock();
}
} finally {
hotDataCacheCreateLock.unlock();
}
return product;
}
性能问题 :读写互斥、读读互斥
思路5:缓存与数据库数据双写不一致问题 — 分布式读写锁
@Transactional
public Product create(Product product) {
//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
//RLock productUpdateLock = productUpdateLock.lock();
RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock wLock = productUpdateLock.writeLock();
try {
Product productResult = productDao.create(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(productResult), genProductCacheTimeout(), TimeUnit.SECONDS);
} finally {
//productUpdateLock.unlock();
wLock.unlock();
}
return productResult;
}
@Transactional
public Product update(Product product) {
//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
//RLock productUpdateLock = productUpdateLock.lock();
RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock wLock = productUpdateLock.writeLock();
try {
Product productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + product.getId(), JSON.toJSONString(productResult), genProductCacheTimeout(), TimeUnit.SECONDS);
} finally {
//productUpdateLock.unlock();
wLock.unlock();
}
return productResult;
}
public Product get(Long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
RLock hotDataCacheCreateLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX+productId);
hotDataCacheCreateLock.lock();
try {
product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
//RLock productUpdateLock = productUpdateLock.lock();
RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock rLock = productUpdateLock.readLock();
try {
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); // 查询不到缓存空数据
}
} finally {
//productUpdateLock.unlock();
rLock.unlock();
}
} finally {
hotDataCacheCreateLock.unlock();
}
return product;
}
问题 如果是有上万个线程过来就会等待着
思路5:缓存与数据库数据双写不一致问题 — 分布式读写锁— tryLock(long time, TimeUnit unit)
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
public Product get(Long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
RLock hotDataCacheCreateLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX+productId);
//hotDataCacheCreateLock.lock();
//这个优化谨慎使用,防止超时导致的大规模并发重建问题
hotDataCacheCreateLock.tryLock(1, TimeUnit.SECONDS);
try {
product = getProductFromCache(productCacheKey);
if (product != null) {
return null;
}
//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
//RLock productUpdateLock = productUpdateLock.lock();
RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock rLock = productUpdateLock.readLock();
try {
product = productDao.get(productId);
if (product != null) {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); // 查询不到缓存空数据
}
} finally {
//productUpdateLock.unlock();
rLock.unlock();
}
} finally {
hotDataCacheCreateLock.unlock();
}
return product;
}

如果在1s内没有处理完: 大量数据就击穿了 并发问题了
思路6:缓存雪崩问题: 大V热点事件
缓存雪崩指的是缓存层支撑不住或宕掉后, 流量会像奔逃的野牛一样, 打向后端存储层。
由于缓存层承载着大量请求, 有效地保护了存储层, 但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降), 于是大量请求都会打到存储层, 存储层的调用量会暴增, 造成存储层也会级联宕机的情况。
预防和解决缓存雪崩问题, 可以从以下三个方面进行着手。
1) 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
2) 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
3) 提前演练。 在项目上线前, 演练缓存层宕掉后, 应用以及后端的负载情况以及可能出现的问题, 在此基础上做一些预案设定。
多级缓存架构demo:
- JVM map jvm 进程内存不够
- mq 订阅 监听 更新 jvm map
- zk
- ehcache guava caffeine
- 热点中热点需要实时变更的(热点缓存系统aop切面分布式实时计算)
思路7:热点缓存key重建优化
开发人员使用“缓存+过期时间”的策略既可以加速数据读写, 又保证数据的定期更新, 这种模式基本能够满足绝大部分需求。 但是有两个问题如果同时出现, 可能就会对应用造成致命的危害:
当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
重建缓存不能在短时间完成, 可能是一个复杂计算, 例如复杂的SQL、 多次IO、 多个依赖等。
在缓存失效的瞬间, 有大量线程来重建缓存, 造成后端负载加大, 甚至可能会让应用崩溃。
要解决这个问题主要就是要避免大量线程同时重建缓存。
我们可以利用互斥锁来解决,此方法只允许一个线程重建缓存, 其他线程等待重建缓存的线程执行完, 重新从缓存获取数据即可。
示例伪代码:
String get(String key) {
// 从Redis中获取数据
String value = redis.get(key);
// 如果value为空, 则开始重构缓存
if (value == null) {
// 只允许一个线程重建缓存, 使用nx, 并设置过期时间ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写Redis, 并设置过期时间
redis.setex(key, timeout, value);
// 删除key_mutex
redis.delete(mutexKey);
}// 其他线程休息50毫秒后重试
else {
Thread.sleep(50);
get(key);
}
}
return value;
}