Kudu(分布式数据存储引擎)
Kudu(分布式数据存储引擎)
Kudu是cloudera开源的运行在hadoop平台上的列式存储系统,拥有Hadoop生态系统应用的常见技术特性,运行在一般的商用硬件上,支持水平扩展,高可用。
kudu 定位是 「Fast Analytics on Fast Data」,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
原数据存储于HDFS或HBase都有优缺点:
- 直接存放于HDFS中,适合离线分析,却不利于记录级别的随机读写。
- 直接将数据存放于HBase/Cassandra中,适合记录级别的随机读写,对离线分析却不友好。

1、基本概念
Table
table 是数据存储在 Kudu 的位置,具有 schema 和全局有序的 primary key。table 被分成称为 tablets 的 segments。

Tablet
一个 tablet 是一张 table 连续的 segment,与其它数据存储引擎或关系型数据库中的 partition(分区)相似。给定的 tablet 冗余到多个 tablet 服务器上,并且在任何给定的时间点,其中一个副本被认为是 leader tablet。任何副本都可以对读取进行服务,并且写入时需要在为 tablet 服务的一组 tablet server之间达成一致性。
Tablet Server
一个 tablet server 存储 tablet 和为 tablet 向 client 提供服务。对于给定的 tablet,一个 tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。只有 leader 服务写请求,然而 leader 或 followers 为每个服务提供读请求。leader 使用 Raft Consensus Algorithm 来进行选举 。一个 tablet server 可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。
Master
该 master 保持跟踪所有的 tablets,tablet servers,Catalog Table 和其它与集群相关的 metadata。在给定的时间点,只能有一个起作用的 master(也就是 leader)。如果当前的 leader 消失,则选举出一个新的 master,使用 Raft Consensus Algorithm 来进行选举。
master 还协调客户端的 metadata operations(元数据操作)。例如,当创建新表时,客户端内部将请求发送给 master。 master 将新表的元数据写入 catalog table,并协调在 tablet server 上创建 tablet 的过程。
所有 master 的数据都存储在一个 tablet 中,可以复制到所有其他候选的 master。
tablet server 以设定的间隔向 master 发出心跳(默认值为每秒一次)。
Raft Consensus Algorithm
Kudu 使用 Raft consensus algorithm 作为确保常规 tablet 和 master 数据的容错性和一致性的手段。通过 Raft,tablet 的多个副本选举出 leader,它负责接受以及复制到 follower 副本的写入。一旦写入的数据在大多数副本中持久化后,就会向客户确认。给定的一组 N 副本(通常为 3 或 5 个)能够接受最多(N - 1)/2 错误的副本的写入。
Catalog Table
catalog talbe 是 Kudu 的 metadata(元数据中)的中心位置。它存储有关 tables 和 tablets 的信息。该 catalog table(目录表)可能不会被直接读取或写入。相反,它只能通过客户端 API 中公开的元数据操作访问。catalog table 存储两类元数据。
Logical Replicationa
Kudu 复制操作的不是磁盘上的数据。 insert(插入)和 update(更新)确实通过网络传输数据,deletes(删除)不需要移动任何数据。delete(删除)操作被发送到每个 tablet server,它在本地执行删除。物理操作,如 compaction,不需要通过 Kudu 的网络传输数据。这与使用 HDFS 的存储系统不同,其中 blocks (块)需要通过网络传输以满足所需数量的副本。
2、架构
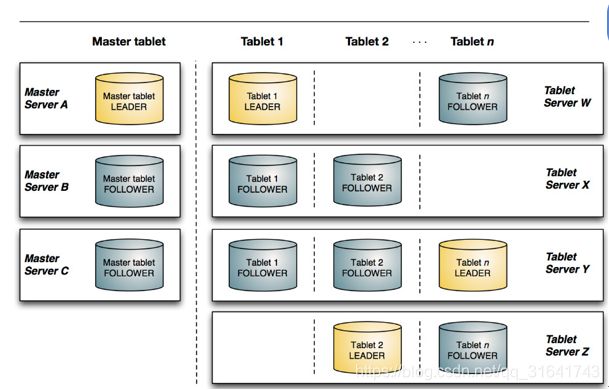
采用了Master-Slave形式的中心节点架构,管理节点被称作 Master Server,数据节点被称作Tablet Server(可对比理解HBase中的RegionServer角色)。
- Mater Server:负责集群(TS)管理、元数据管理等功能
- Tablet Server:负责数据存储,并提供数据读写服务
一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。 Kudu Master在Kudu集群中,发挥如下的一些作用:
- 用来存放一些表的Schema信息,且负责处理建表等请求。
- 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
- 存放Tablet到Tablet Server的部署信息。
3、底层数据模型
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。这套实现基于如下目标:
- 可提供快速的列式查询。
- 可支持快速的随机更新
- 可提供更为稳定的查询性能保障。
- 为了实现如上目标,Kudu参考了一种类似于Fractured Mirrors的混合列存储架构。Tablet在底层被进一步细分成了一个称之为RowSets的单元:
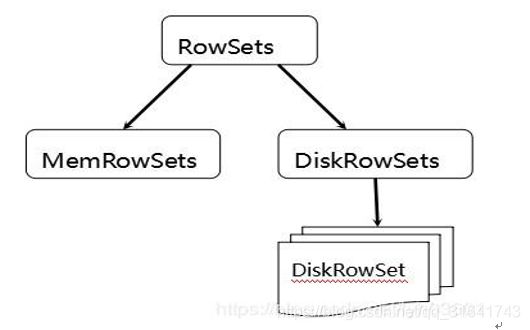
- MemRowSets中的数据按照行进行存储,数据结构为B-Tree。MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。 DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。
- DiskRowSet中的数据按照列进行组织,与Parquet类似。这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。
- Kudu可支持单条记录级别的更新/删除,是通过增加一条新的记录来描述这次更新/删除操作的。一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Delta Stores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
- Delta数据部分包含REDO与UNDO两部分,这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。 而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异:
- REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。
- UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。

4、读写流程
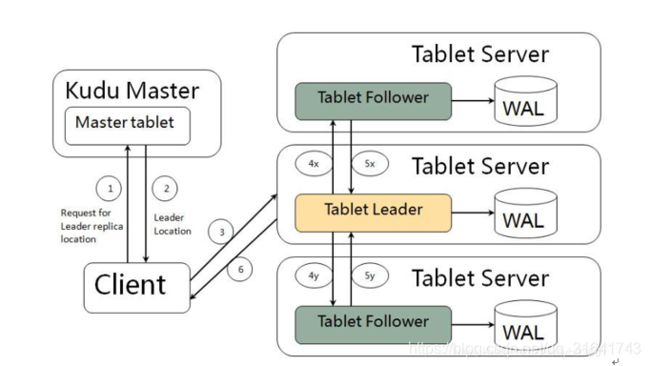
Kudu不允许用户数据的Primary Key重复,因此,在Tablet内部写入数据之前,需要先从已有的数据中检查当前新写入的数据的Primary Key是否已经存在,尽管在DiskRowSets中增加了BloomFilter来提升这种判断的效率,但可以预见,Kudu的这种设计将会明显增大写入的时延。
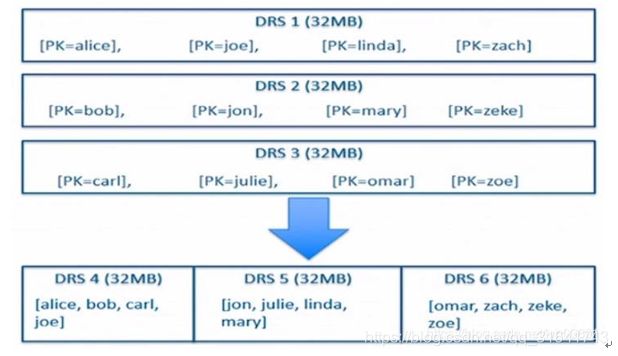
数据一开始先存放于MemRowSets中,待大小超出一定的阈值之后,再Flush成DiskRowSets。随着Flush次数的不断增加,生成的DiskRowSets也会不断的增多,在Kudu内部也存在一个Compaction流程,这样可以将已经存在的多个存在Primary Key交集的DiskRowSets重新排序而生成一个新的DiskRowSets。如下图所示:
官方网站:https://kudu.apache.org/