linux知识点复习
-
基础命令
-
磁盘
(1)fdisk:磁盘进行分区
主分区最多有4个;扩展分区0个或1个;逻辑分区可以是0个,1个,多个
(2)lvm:逻辑卷管理器
(3)mdadm:创建磁盘阵列
0 100%
1 50%
5 (n-x)/n
10 50% -
centos7系统启动过程
(1)BIOS初始化,开始post开机自检
(2)加载MBR
(3)GRUB阶段
(4)加载内核
(5)内核初始化,使用systemd代替centos6以前的init程序 -
网络
(1)DNS
端口:
tcp/53 udp/53 用于客户端查询
tcp/953 udp/953 用于DNS主从同步正向解析:将域名解析成IP地址
反向解析:将IP地址解析成域名递归查询:DNS服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS服务器本地没有储存查询DNS信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
迭代查询:当客户机发送查询请求时,DNS服务器并不直接回复查询结果,而是告诉客户机另一台DNS服务器地址,客户机再向这台DNS服务器提交请求,依次循环知道返回查询的结果为止。
A 正向
PTR 反向
NS 指定该域名由哪个DNS服务器来进行解析
(2)DHCP原理
端口:67、68
客户端向DHCP服务器发送广播(呼叫)要IP地址,DHCP服务器回答客户端给IP地址,客户端挑选DHCP服务器回答的IP地址给DHCP服务器,DHCP服务器不再向客户端发送IP地址。
二次链接时客户端向DHCP服务器发送上次的ip信息,DHCP服务器会尽可能给客户端相同的IP地址
二次链接时客户端原来的ip被用了后再重复第一次阶段过程。
(3)FTP主被动模式
主动模式:
1)客户端本地开启一个监听端口,后向服务器发送PROT指令
2)服务收到PROT指令,立刻用本地20号端口向客户端进行建链(数据链路)
3)数据链路建链完成后,数据信息走数据链路、控制指令信息走控制链路。
被动模式:
1)客户端向服务器发送PASV指令,告诉服务器使用被动模式(控制链路)
2)服务器收到指令后,开启一个监听端口高位端口(大于1024),并将该端口信息回复客户端
3)客户端收到服务的监听端口信息后,立刻再起一个端口向高位端口进行建链(数据链路)
4)数据链路建链完成后,数据信息走数据链路、控制指令信息走控制链路
-
OSI七层网络模型
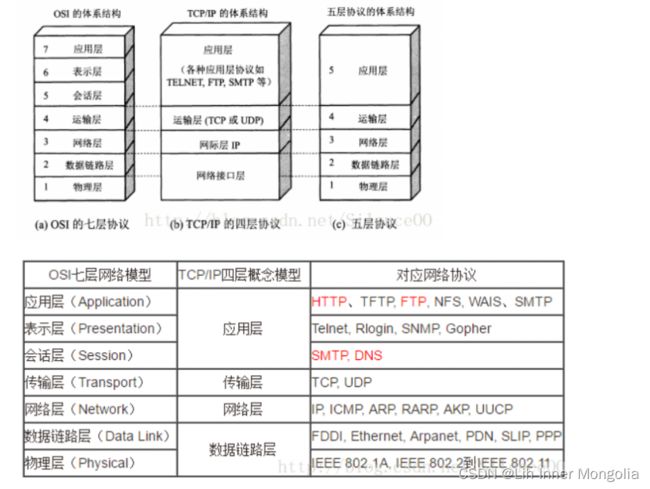 TCP:传输控制协议
TCP:传输控制协议
UDP:用户数据包协议
三次握手与四次挥手
(1)三次握手
第一次握手:客户端向服务器端发送tcp建立链接的请求报文,报文中包含一个随机生成的seq序列号
第二次握手:服务器端恢复客户端发送的tcp建立链接的请求报文,将客户端发送来的SYN+1成为ACK验证字段,并返回ACK确认控制字段
第三次握手:客户端收到服务器端发送的tcp请求后,将自己原有的序列号+1发送,回复ACK验证请求,同时回复ACK确认控制字段
为什么要进行三次握手?
第一次握手,客户端发送网络包,服务器端收包;此时客户端的发送能力正常,服务器端的接收能力正常
第二次握手,服务器端发包,客户端收包;此时服务器端的发送能力正常,客户端的接收能力正常,但此时服务器端不知道客户端的接收能力是否正常
第三次握手,客户端发包,服务器端收包;告知服务器端客户端的发送和接收能力均是正常的(2)四次挥手
第一次挥手:客户端发送一个FIN报文,报文中包含一个随机生成的序列号(FIN wait)
第二次挥手:服务器端收到客户端发送过来的FIN报文后,将序列号值+1作为ACK报文(closed wait)
第三次挥手:服务器端发送一个FIN报文,报文中包含一个随机生成的序列号(lact ACK)
第四次挥手:客户端收到服务器端发送的FIN报文,将报文中的序列号值+1作为ACK报文(closed) -
端口
NFS:2049
DHCP:67、68
DNS:
tcp/53 udp/53 用于客户端查询
tcp/953 udp/953 用于DNS主从同步
FTP:20(传输数据)、21(传输指令)、高位端口(>1024)
apache(httpd):80
nginx:80
https:443
Tomcat:
8005:关闭端口 telnet 127.0.0.1 8005 SHUTDOWN
8009:接收jsp协议,与其他建立httpd链接
8080:访问端口
MariaDB(mysql):3306 集群(galera):4567 wsrep协议
redis:6379 -
web服务器
(1)apache 80
配置文件:/etc/httpd/conf/httpd.conf
网站根目录:/var/www/html/(index.html、index.php)
日志:/var/log/httpd/(access_log、error_log)
优点:
1)在rewriter频繁的情况下,选用Apache
2)处理动态文件好,对php支持比较简单
3)模块超多,基本想用的模块都可以找到
4)成熟,少bug
5)apache依然是目前的主流web服务器
(2)nginx 80
配置文件:/etc/nginx/nginx.conf
upstream:定义的是url池
server:定义负载均衡等
location(proxy):请求至upstream中;还可以做黑名单
网站根目录:/usr/share/nginx/html
日志文件:/var/log/nginx/
优点:
1)轻量级,采用c语言进行编写,占用的系统资源少
2)抗并发,采用异步非阻塞,官方支持5万并发
3)处理静态能力要比apache高3倍以上
4)模块化
5)配置简洁,支持正则,配置完成后支持-t进行检测
6)本身就是一个反向代理服务器
7)支持7层负载均衡
静态资源与动态资源
静态资源:web服务器收到请求后,不需要访问数据库,也不需要进行处理,直接就可以展示给客户
动态资源:web服务器收到请求后,需要去访问数据库,进行处理后才能展示给客户
cgi:web服务器根据请求内容fork一个进程,web收到的请求由进程完成,处理完的结果返回给web服务器,访问完毕,结束。进程退出
fastcgi:web服务器在启动时已经fork一个进程,web收到的请求由进程完成,处理完的结果返回给web服务器,访问完毕,结束。进程不退出,等待下一次的请求
(3)tomcat 8005、8009、8080
8005:关闭端口 telnet 127.0.0.1 8005 SHUTDOWN
8009:接收jsp协议,与其他建立httpd链接
8080:访问端口
目录结构
bin:用来启动、关闭tomcat其他功能的脚本(.bat和.sh文件)
conf:用来配置tomcat的xml和dtd文件
lib:存放web应用能访问的jar包
logs:catalina和其他web应用程序的日志文件
temp:临时文件
webapps:web应用程序根目录,var包放在该目录下会自动解压
work:用以jsp编译出的servlet的.java和.class文件
日志:logs/catalina.out
优点:动态解析容器,jsp/servlet的容器
缺点:只能用作java容器,处理html请求的能力不如nginx和Apache
web请求在tomcat的流程
1)浏览器输入url
2)查询本机的host文件
3)查询dns
4)向具体ip发送请求
5)tomcat容器解析主机名
6)tomcat解析web服务
7)tomcat解析资源
8)tomcat获取资源
9)回应请求
访问一个网站的流程
1)浏览器输入url
2)查询hosts文件
3)查询缓存(缓存没有查询dns)
4)查询dns
5)向具体ip发送请求,三次握手四次挥手建立链接
6)访问完毕,结束
- shell脚本
if语句的单分支:
if 条件表达式; then
命令
fi
if语句的双分支:
if 条件表达式; then
命令
else
命令
fi
if语句的多分支:
if 条件表达式;then
命令
elif 条件表达式;then
命令
else
命令
fi
for语句
for 变量名 in 取值列表
do
命令
done
while语句:条件为真就进入死循环,条件为假就退出循环
while 条件表达式; do
命令
done
case语句:一般用于选择性来执行部分块命令
*case 模式名 in
模式1)
命令
;;
模式2)
命令
;;
)
不符合以上模式的命令
esac
实例:




- MariaDB(mysql) 关系型数据库
MariaDB与mysql的区别

MariaDB是mysql开发者离开公司后单独开发,使用方面几乎找不到差别
主从架构:mater将改变记录到二进制日志当中,开启一个IO线程发送给从服务器,从服务器将二进制日志中的事件拷贝到自己的中继日志中,开启一个sql线程重放操作;从服务器通常不接受任何可以从本地进行改变数据库的操作,避免主从不一致
目的:1.缓解主服务器的读写压力,提高其可用性 2.将从节点对外开放,提高安全性
mysql主从复制存在的问题
1)主库宕机后,可能会存在数据丢失
2)从库只有一个sql线程,复制可能会延迟
解决办法:级联复制,半同步复制
mysql主从复制产生延迟的原因
1)大量的读写操作超过可服务器可承受的范围
2)大型的语句产生了锁等待
3)网络波动
判断主从延迟的方法:
1)show slave status\G;
查看是否为yes状态
mysql忘记密码解决办法
1)vim /etc/my.cnf.d/server.cnf 加入
skip-grant-tables
2)mysql -uroot -p
use mysql;
update user set password=root where user=‘root’;
mysql的索引类型
1)普通索引:没有任何限制
2)唯一索引:可空,唯一 如果是组合索引,唯一
3)主键索引:一个表只能有一个主键索引
4)组合索引:多个字段上设置,只有在查询时使用创建索引的第一个字段才会生效,遵循最左前缀集合
5)全文索引:查找关键字,myisam支持,innodb不支持
mysql安全
1)避免直接从网络登录数据库
2)定期备份数据
3)移除不常用的用户
4)限制主机登录
5)限制用户权限
生产中一主多从从库宕机,如何恢复
1)停止mysql
2)导入备份数据
3)启动slave
4)检查slave状态信息
mysql中的innodb与myisam的区别
1)innodb支持行级锁,myisam支持表级锁
2)innodb支持事务,myisam不支持
3)innodb支持外键,myisam不支持
4)innodb支持mvcc,myisam不支持
5)innodb不支持全文索引,myisam支持
误执行drop操作,如何处理
1)停止数据库
2)移除数据库中的data目录和数据
3)导入备份的数据
4)重新启动mysql
mysql的日志
1)查询日志:记录了mysql中每一条增删改查
2)慢查询日志:记录了执行时长超过指定时间的查询语句
3)错误日志:
记录了mysql运行过程中产生的错误信息
记录了mysql启动和关闭过程中产生的错误信息
记录了event scheduler的错误信息
4)二进制日志:主从架构通过二进制日志实现备份与还原
5)中继日志:主从架构中,从服务器用于保存主服务器二进制日志当中读取到的事件
6)事务日志:数据库中增删改查等操作在一段时间后写入到磁盘当中
mysql中日志的记录格式:
1)statement:记录每条sql语句
2)row:记录数据更改
3)mixedlevel:混合模式
mysql的备份方式
1)mysqlbinlog --start-datetime=“2022-7-19 21:00:00” --stop-datetime=“2022-7-19 22:00:00” binlog…> *.log
mysql -uroot -proot
source *.log
2)mysqlbinlog /var/lib/mysql/binlog… --stop-position=值 | mysql -uroot -proot
3)磁盘快照
mkfs.ext4 /dev/vg1/lv1
mount /var/lib/mysql /dev/vg1/lv1
flush tables with read locak;
lvcreate -L 100G -s -p r -n snap1 /dev/vg1/lv1
4)mariaback
全备
yum install mariaback -y
mariaback --backup --target-dir=/var/lib/mysql --user=root --password=root
mariaback --prepare --target-dir=/var/lib/mysql --user=root --password=root
mariaback --copy-back --target-dir=/var/lib/mysql --user=root --password=root
全备+增量
mariaback --backup --target-dir=/var/lib/mysql --user=root --password=root
mariaback --backup --target-dir=/root/inc1 --increment-basedir=/root/fullback --user=root --password=root
mariaback --prepare --target-dir=/var/fullback --user=root --password=root
mariaback --prepare --target-dir=/root/fullback --increment-dir=/root/inc1 --apply-log-only --user=root --password=root
mariaback --copy-back --target-dir=/root/fullback --user=root --password=root
5)mysqldump
mysqldump -uroot -proot -l --database 库名 > *.sql
mysqldump -uroot -proot - --all-database > all.sql
mysql -uroot -proot
source *.sql
6)Xtrabakcup
innobackupex --user=root --password=root /home/mysqlbackup/
innobackupex --user=root --password=root /home/mysqlbackup/ 2>> /home/mysqlbackup/bakcup.log
innobackupex --user=root --password=root --no-timestam /home/mysqlbackup/test 2>> /home/mysqlbackup/bakcup-test.log
innobackupex --copy-back /home/mysqlbackup/2022-08-19_11-25-59/
innobackupex --apply-log --redo-only /home/mysqlbackup/2022-08-19_11-31-32/
innobackupex --apply-log --redo-only /home/mysqlbackup/2022-08-19_11-31-32/ --incremental-dir=/home/mysqlbackup/2022-08-19_13-52-49
事务:begin、commit、rollback
增删改查
增:
create database 库 character set utf8;
create table 表 (***);
insert into 表 (字段) values (数据);
删:
drop database 库;
drop table 表;
alter table 表 drop 字段;
drop user 用户名;
delete from 表;
delete from 表 where 字段=值;
truncate 表;
改:
alter database 库 defalut character set latin;
alter table 表 add 字段 约束;
alter table 表 change 原字段 新字段 约束;
alter table 表 modify 字段 新约束;
update 表 set 字段=值 where 字段=值;
查:
show create database 库;
desc 表;
select * from 表;
select * from 表 where 字段 not between 值 and 值;
select 字段 from 库.表;
select * from 表 where 字段 like “%关键字%”;
select * from 表 字段 not null;
select * from 表 order by 字段 asc;
select * from 表 order by 字段 desc;
select * from 表 order by 字段 limit 1;
select * from 表1 inner join 表2 where 表1.字段=表2.字段;
select count() from 表;
select max(字段) from 表;
select min(字段) from 表;
select sum(字段)/count(字段) from 表;
select round(sum(字段)/count(字段),2) from 表;
select round(avg(字段),2) from 表;
select * from 表 group by 字段;
- redis 非关系性数据库 缓存数据库 6379
定时将内存中的数据同步到磁盘上(默认为900秒)
daemonize yes 后台运行
redis-server redis.conf
redis-cli -h ip -p port
redis-cli shutdown
redis的数据结构
1)string:最简单的k/v形式
set key value
get key
kyes *
del key
set key value ex timeout
ttl key
2)列表
设置列表值
lpush rpush
查看列表值
lrange
删除头元素
lpop
rpop
查看元素个数
llen key
指定返回第几个元素
lindex key index
删除指定元素
lrem key count value
3)集合
sadd key value1 value2
smembers key
srem key value
sinter key1 key2 交集
sunion key1 key2 并集
sdiff key1 key2 差集
4)哈希hash
hset key faild value
hget key faild
hgetall key
hkyes key
hvals key
hexixts key faild
5)hypeloglog
6)stream
发布与订阅
subscribe channel 订阅
publish channel 发布
redis主从(redis.conf)
port 6379
bind ip
redis-server redis.conf
redis-cli -h ip -p port
slaveof ip port
select (0~15)
reids集群(最少要求三主三从)
port port
bind ip
daemonize yes
pidfile
cluster_enabled yes
cluster_config_file
cluster_node_timeout
appendonly yes
redis-server redis.conf
redis-cli --cluster create ip:port … --cluster-replicas 1
redis-cli -c -h ip -p port
redis的持久化(RDB文件和AOF文件)
RDB文件
1)类似于快照
2)RDB文件是经过压缩的,占用空间少
3)RDB文件适合做灾难备份恢复
4)RDB文件可以最大化redis的性能
缺点:
1)RDB文件在做备份时可能会丢失时间间隔的数据
2)RDB在做恢复时,fork一个进程进行恢复,如果数据量太大,可能会造成停止服务N毫秒的情况
AOF文件
1)AOF文件记录写入的命令
2)AOF比RDB可靠,有不同的fsync策略 no everysec always
3)AOF是一个纯追加的日志类型
4)AOF文件太大会自动进行重写
5)AOF文件保存以redis协议进行保存,易读
缺点:
1)AOF文件比RDB文件要大
2)AOF文件恢复速度要比RDB要慢
redis恢复(如进行误操作flush all)
1)紧急停止redis,立刻查看aof文件和rdb文件
2)redis-check-aof --fix aof文件名
3)redis-check-rdb rdb文件名
4)redis-cli -h ip -p port
5)keys *
redis为什么这么快?
1)完全基于内存
2)数据结构简单
3)单线程(核心) redis从4.0开始引入多线程,但核心操作还是单线程的
4)非阻塞IO
5)redis自己构建了VM机制
memcache和redis的区别
1)memcache没有持久化,停电或重启后数据丢失
2)memcache可以缓存图片,视频等
缓存雪崩:redis挂掉后,大量的数据全部走数据库
缓存穿透:当查询某一个一定不存在的key时,由于容错机制,会去数据库进行查找
缓存击穿:当某一个key扛着高并发,当这个key失效的一瞬间,大量的并发全部走数据库
- LVS
LB:load balance
HA:high available
HP:high performance
VIP:用来向客户端提供服务的ip地址
RIP:集群节点ip
DIP:LB与RIP进行交互的ip地址
CIP:公网ip
**三种模式(NAT、DR、TUN)
1)NAT
LB收到用户请求后,将请求包中的IP地址转换为某个特定RS的ip地址,转发给RS,RS将应答包发送给LB,LB将应答包中的ip转为虚拟服务ip回送给用户
要求:请求响应报文均经过LB。对LB的性能要求比较高;支持端口映射
2)DR
LB收到用户请求后,将请求包中的mac地址转为某个特定RS的mac地址,转发给RS,RS可直接将应答包回送给客户
要求:LB与RS在同一个物理段,共享一个虚拟ip;RS的网关不允许指向LB,应为响应报文不通过LB;不支持端口映射
3)IP TUN
LB收到用户请求后,根据ip隧道协议封装该包转发给某个特定的RS,RS解出请求信息之后,将应答内容回送给用户
要求:LB与RS都要支持ip隧道协议
调度算法:
1)静态
rr:轮询
wrr:加权轮询
sh:源地址转换
dh:目标地址转换
2)动态
lc:最少链接
wlc:加权最少链接
sed:最少期望延迟
nq:永不排队
lblc:基于局部性能的最少链接
lblcr:带复制的基于局部性能的最少链接
常用操作:
ipvsadm -Ln --stats 显示详细信息并展示进出站
ipvsadm -C 清除所有规则
ipvsadm -S 保存规则
ipvsadm -R 恢复保存的规则
ipvsadm -E 修改
ipvsadm -D 删除
- keepalived 轻量级高可用集群软件 vrrp协议(虚拟路由冗余协议、主备协议)
功能:
1)转发功能
2)故障隔离
3)恢复添加
主要模块
1)core 负责主进程的启动和维护,配置文件的加载和解析
2)check 健康检查
3)vrrp 实现vrrp功能
配置文件:/etc/keepalived/keepalived.conf
配置文件也包含三模块
1)全部配置:global defs部分
2)vrrp部分
3)lvs部分
工作原理:在虚拟路由器中,处于master的节点会一直发送vrrp数据包,处于backup的节点只会接受来自master的报文信息,用来监控master,当master出现故障时,处于backup的节点就收不到来自master的报文信息,认为master出现故障,从而选举一个优先级更高的backup成为新的master,过程迅速,保证了服务的可持续性
关键点:在于实现了一个vip的漂移
- firewalld防火墙
四表:
filter:过滤
nat:路由转发
mangle:拆分报文
raw:关闭nat表上启用的链接机制
常用优先级:filter>nat>mangle>raw
应用优先级:raw>mangle>nat>filter
五链:
prerouting:对数据做路由选择前
input:进站规则
forward:转发规则
output:出站规则
postrouting:对数据做路由选择后
常用选项:
-t:指定表
-A:追加策略(最小优先级)
-I:插入策略(最大优先级)
-L:列出当前iptables中的规则
-n:以数字形式显示
-F:清除所有规则
-X:清除自定义链
-s:源IP
-d:目标ip
-j:要执行的动作(ACCEPT接收、DROP丢弃、REJECT拒绝、DANT目标地址转换、SNAT源地址转换)
-p:指定协议
-i:指定网卡
如:
(1)指定仅能10.220.5.138可以ping(访问)本机
iptables -A INPUT -s 10.220.5.138 -j ACCEPT
(2)允许所有进入10.220.5.138的流量
iptables -A INPUT -d 10.220.5.138 -j ACCEPT
(3)允许从eth0进入的流量
iptables -A INPUT -i eth0 -j ACCEPT
(4)可以从10.220.5.1 ping 其他主机,禁止其他主机ping 10.220.5.1
iptables -I INPUT -p icmp --icmp-type 0 -d 10.220.5.1 -j ACCEPT
iptables -I INPUT -p icmp --icmp-type 8 -s 10.220.5.1 -j ACCEPT
0是应答包
8是请求包
(5)让所有主机可以访问10.220.5.1上的网站,但是禁止10.220.5.191访问网站
iptables -A INPUT -p tcp --dport 80 -d 10.220.5.1 -j ACCEPT
iptables -I INPUT -p tcp --dport 80 -s 10.220.5.191 -j DROP
(6)只允许从10.220.5.182发送连接httpd请求
iptables -I INPUT -p tcp -s 10.220.5.182 --tcp-flags syn,ack,fin syn -j ACCEPT
(7)让所有人都可以访问web站点
iptables -A INPUT -m state --state NEW,ESTABLISHED -p tcp --dport 80 -j ACCEPT
iptables -A OUTPUT -m state --state ESTABLISHED -p tcp --sport 80 -j ACCEPT
(8)允许让10.220.5.182访问本机的80 22 443 3389 3306端口
允许让10.220.5.182访问本机的80 22 443 3389 3306端口
(9)10.220.5.1~10.220.5.100无法访问web
iptables -I INPUT -p tcp --dport 80 -m iprange --src-range 10.220.5.1-10.220.5.100 -j DROP
(10)限制只有10.220.5.188可以连接ssh
iptables -A INPUT -s 10.220.5.188 -p tcp --dport 22 -j ACCEPT
(11)防暴力破解&DOS攻击,限制请求登录22端口的频率
iptables -A INPUT -p tcp --dport 22 -m state --state NEW -m limit --limit 10/minute --limit-burst 20 -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -m state --state ESTABLISHED -j ACCEPT
(12)限制只能从10.220.5.188登录后台界面(admin.php)
iptables -A INPUT -s 10.220.5.188 -m string --algo bm --string “admin.php” -j ACCEPT
(13)限制每个用户只能同时登录5个ssh
iptables -A INPUT -p tcp --dport 22 -m connlimit ! --connlimit-above 5 -j ACCEPT
(14)限制每个客户端只能与80端口并发连接10个链接
iptables -A INPUT -p tcp --dport 80 -m state --state NEW,ESTABLISHED -m connlimit !–connlimit-above 10 -j ACCEPT
(15)指定在1h只登录达到5次之上的,该次链接请求会被丢弃
iptables -A INPUT -p tcp --dport 22 -m state --state NEW -m recent --name loginSSH --update --seconds 3600 --hitcount 5 -j DROP
(16)保存和恢复
iptables-save > 1.txt
iptables-restone < 1.txt
- ansible自动化运维工具
进程是最小的管理单元,线程是最小的调度单位。
先要配置好epel源(yum install epel-release -y && yum install ansible -y)
控制方式:
(1)免秘钥,配置方式:vim /etc/ansible/hosts
ip1 ansible_ssh_user=用户名 ansible_ssh_pass=密码 ansible_ssh_port=22
ip2 ansible_ssh_user=用户名 ansible_ssh_pass=密码 ansible_ssh_port=22
(2)host inventory:记录着客户端的ip信息
调用ansible的三种模式:
hoc:命令行[敲一条命令执行一条命令(需要运维人员一直在操作)]
playbooks:剧本|脚本(按照playbooks中的顺序一行一行的执行,类似shell脚本)
roles:角色(减少命令的复写,减少代码的复写)
注:若控制主机报错时可以修改/etc/ansible/ansible.cfg中host_key_check=false注释打开
ansible默认控制的并发数为5台最高255台,可通过修改/etc/ansible/ansible.cfg中参数进行修改
常用选项
ansible -f:控制并发数
ansible -doc -l:查看所支持的模块
ansible all --list:查看所有组下的控制主机
ansible 组名 --list:查看特定组下的控制主机
ansible all -m 模块 -a ‘命令’ :控制所有主机执行
ansible 组名 -m 模块 -a ‘命令’ :控制某个组下的所有主机
ansible ip -m 模块 -a ‘命令’ :指定某个主机执行
如:
命令行
ansible all -m service -a ‘name=httpd state=(restarted、stopped、started)’
ansible all -m service -a ‘name=nginx enabled=(true、false)’
ansible 组 -m copy -a ‘src=/源文件路径 dest=/目标路径’
ansible 组 -m copy -a ‘content=内容 dest=/目标路径’
ansible all -m shell -a ‘systemctl stop firewalld’
ansible 组 -m command -a ‘date’
ansible all -m script -a ‘/路径/*.sh’
ansible all -m yum -a ‘name=ntpdate state=(present、latest、absent)’
playbook

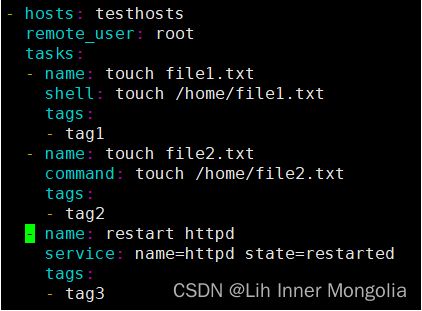

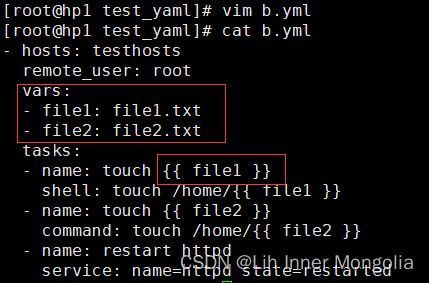

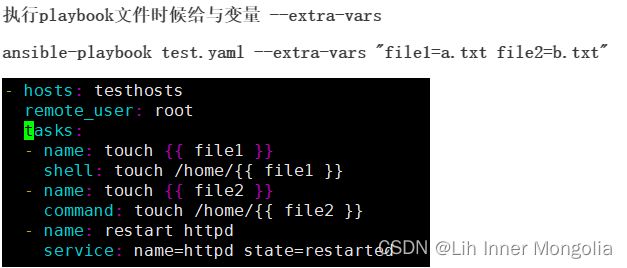




模板拷贝
(1)copy换成template
(2)在/etc/ansible/hosts中增加变量

roles本意是为了减少代码的复写,但由于目录结构复杂,不进行展示
15.zabbix基于web界面提供分布式监控机制
自动发现
自动注册
自定义监控
邮件报警
- docker容器
docker与kvm对比
kvm:
(1)虚拟一个完整的操作系统,可以登录并实现管理
(2)使用复杂
(3)启动速度慢
(4)模板文件大
(5)和物理机完全隔离
docker:
(1)虚拟一部分用户空间
(2)使用简单
(3)启动速度快
(4)模板文件小
(5)和物理机在一定程度上实现隔离
(1)镜像:
build:从dockerfile中制作镜像
history:显示镜像的创建历史
import:从tar包文件制作镜像,通常和export配合使用
inspect:显示一个镜像的详细信息
load:从tar包文件导入镜像
ls:列出当前镜像
prune:移除不经常使用的镜像
pull:从仓库当中拉取镜像
push:把一个镜像推送到远程仓库当中
rm:删除一个或多个镜像
save:把一个或多个镜像导入到tar包文件中
tag:镜像改名
(2)容器:
attach 进入容器;退出时容器退出
cp 在容器和宿主机之间复制文件
create 创建新的容器
diff 显示容器当中哪些文件被改变
events 从服务器获取实时事件
exec 在运行的容器当中执行命令;可以进入容器,退出时容器不会退出
export 把容器制作成镜像(tar包文件)
history 显示镜像的构建历史
images 镜像列表
import 从tar包导入内容以创建文件系统镜像
info 显示系统范围的信息
inspect 显示容器详细信息
kill 强制关闭容器;相当于kill -9
logs 查看容器日志
ls 查看容器
pause 暂停容器
port 显示容器的端口映射信息
prune 删除已经停止运行的容器;停止的容器可以看到,但是删除的容器就看不到
ps 查看正在运行的容器;如果想查看正在运行和已经退出的容器需要加上选项-a
rename 容器改名
restart 重启容器;先停止再开启
rm 删除容器;默认是无法删除正在运行的容器,可以加-f强制删除
run 运行容器
start 把停止的容器再次开启
stats 显示容器内存,CPU,磁盘IO详细信息
stop 停止正在运行的容器;相当于kill -15
top 显示正在运行的容器PID,命令等信息
unpause 解锁容器
update 更新容器的内存,CPU,磁盘IO信息
version 显示docker的版本信息
wait 等待一个容器停止,并打印出来容器退出的返回码(非0均为不正常退出)
(3)端口映射:
-P:容器端口映射为宿主机的一个随机端口
docker run -d -P --name nginx nginx --rm
-p:容器端口映射为宿主机的特定端口
docker run -d -p 80:80 --name nginx nginx
-p:容器端口映射为宿主机特定网卡上的随机端口
docker run -d -p 192.168.31.11::80 --name nginx nginx
-p:容器端口映射为宿主机特定网卡上的特定端口
docker run -d -p 192.168.31.11:80:80 --name nginx nginx \
(4)容器底层技术
cgroup:实现资源的限额
cpu限额:docker run -d -c 512 --name nginx nginx
内存限额:docker run -d -m 512M --name nginx nginx
内存限额需要长期积累经验才能找到一个较为合适的值,cpu限额在并发量不大的情况下,即使设置了限额也会用到全部的cpu资源,只有在搞并发的情况下才可体现
namespace:实现资源隔离
mount:使容器拥有自己的文件系统,mount、umount等不会影响到其他的容器
uts:域名解析 docker run -d -p 80:80 -h hp1 --name nginx nginx
ipc:虚拟内存,默认为3G
pid:进程号
network:容器拥有自己的网卡、ip、路由等资源
user:容器能够自己管理自己的账户,host不能看到容器创建的用户
union file system:联合文件系统
如:新镜像时base镜像一层一层构建而来,多个镜像都是从相同的base镜像构建而来,docker host只需在磁盘上保存一份基础的base镜像,在内存中也只需要加载一份base镜像就可以为所有的容器进行服务
多个镜像共享一份基础的base镜像,当某个容器要修改基础镜像内容的时候,其他容器的基础镜像内容不会被修改(copy on write)
当某个容器要修改基础镜像内容的时候,一个新的可写层被加载到容器的顶端,容器要进行的增删改等操作都在该层完成
(5)数据卷管理 作用:实现与宿主机之间的文件共享和持久化
与特定目录相关联 -v
docker run -d -p 80:80 -v /home/html:/usr/share/nginx/html --name nginx nginx
自管理 -v
docker run -d -v /hello -p 80:80 --name nginx nginx 容器内部的hello目录挂载到宿主机的特定目录
docker inspect nginx 找到mount对应的目录位置,容器内的hello目录与该位置进行了挂载
资源共享 --volumes-from
docker run -d -p 80:80 -v /home/html:/usr/share/nginx/html --name nginx nginx
docker run -d -p 81:80 --volumes-from nginx nginx
数据卷的批量删除
docker volume rm $(docker volume ls -q)
(6)docker镜像的创建
docker save 镜像 > 镜像名.tar.gz
docker load < 镜像名.tar.gz
docker export container id/names > 镜像名.tar.gz
docker import 镜像名.tar.gz 镜像名:版本号
docker dun -d -p 80:80 --name nginx nginx
docker commit -p nginx 镜像名:版本号
dockerfile
FROM:声明使用哪个镜像作为base镜像
LABEL:声明源数据信息
RUN:执行命令
注:命令1;命令2 命令1执行成功不成功都执行命令2
多个命令再第一行使用;换行使用
命令1&&命令2 命令1执行成功再执行命令2
COPY:复制文件
注:源文件用相对路径,目标文件用绝对路径
可使用通配符
源文件必须在工作目录或工作目录的子目录当中
目标路径可以不存在但会自动创建
源文件是一个目录,会自动递归复制目录下的文件到目标位置,目录本身不会复制
ADD:添加文件
注:复制文件
可以自动解压tar包文件
可以从网络上下载文件
如果从网络上下载的是tar包文件不会自动解压
WORKDIR:声明工作目录
EXOPSE:声明暴露的端口
CMD:执行命令
ONBUILD:触发器
ENTRYPOINT:执行命令
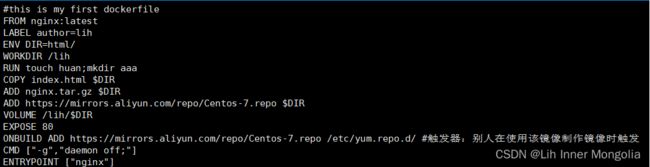
(7)镜像仓库
共有仓库:dockerhub.com
私有仓库:registry
docker pull registry
docker run -d -p 5000:5000 -v /root/lih:/var/lib/registry --name registry registry
docker tag nginx 192.168.31.14:/5000nginx:v1
vim /etc/docker/daemon.json

systemctl daemon-reload
systemctl restart docker
docker restart registry
docker push 192.168.31.14:/5000nginx:v1
阿里云镜像仓库
登录阿里云官网
控制台
产品与服务,容器镜像仓库
按照提示进行操作即可
(8)docker的三种网络模式
none:封闭的网络意味着隔离,一些对安全性要求高,且不需要联网的应用可以使用此网络
host:容器实现简易通信,使用此网络模式要注意与宿主机的端口冲突问题(可不做端口映射)
bridge:默认使用网络
connect:给容器添加一块其他网络模式的网卡
create:创建网络
disconnect:把容器从网络当中断开
insoect:显示网络的详细信息
ls:列表
prune:移除没有使用的网络
rm:删除网络
docker network create -d bridge mynet1
docker run -d -p —network=mynet1 --name nginx1 nginx
docker network create -d bridge --subnet=192.168.31.0/24 --gateway=192.168.31.1 mynet2
docker run -d -p 80:80 --network=mynet1 --ip=192.168.31.51 --name nginx2 nginx
docker network connect mynet1 nginx2
docker network connect mynet2 nginx1
可以使nginx1与nginx2进行通信
- k8s
cluster:计算,存储和网络资源的集合,kubernetes通过这些资源管理容器
master:cluster的大脑,负责调度,决定pod在哪个node上运行
node:pod运行的地方,node负责监控容器的状态,并向master汇报,并根据master的要求管理容器的生命周期
pod:kubernetes的最小工作单元,pod中运行着一个或多个容器,这些容器会作为一个整体被master调度到node上运行
controller:kubernetes通过controller管理pod
service:service为外界提供访问pod的ip,pod可能会被频繁的创建和销毁,但service不变
namespace:可以将cluster划分为多个cluster(default、system、public)
master:
kube-apiserver:k8s的前端接口和其他组件通过apiserver管理集群各种资源
kube-scheduler:决定pod在哪个node上运行
kube-controller-manager:管理集群的各种资源,使其处于一个预期的状态
etcd: 相当于数据库,保存着节点的各种配置信息,如:kubectl get po时从etcd中获取到资源信息
pod:flannel为pod分配网络
node:
kubelet:node的agent,当pod被调度到某个node上运行的时候,node将该节点的配置信息发送给kubelet,kubelet依据这些配置信息创建和运行容器
kube-porxy:外界通过访问service访问pod,service收到的请求由proxy完成,proxy还可以实现k8s集群的负载均衡
pod:flannel为pod分配网络
(1)kubeadm join信息没有保存或过期如何加入?
systemctl stop kubelet
rm -rf /etc/kubernetes/*
kubeadm token create -ttl0 -print-join-command
(2)删除node节点
kubectl drain 节点名 --delete-local-date --force --ignore-daemonsets
kubectl delete no 节点名
(3)启动pod(命令行模式)
kubectl run deploy名 --image=镜像名 --replicas=pod数量
kubectl run deploy名 --image=镜像名 -r pod数量

imagePullPolicy:(镜像拉取规则)
IfNotPresent:本地镜像仓库没有去dockerhub拉取
Always:无论本地有没有镜像,都去dockerhub拉取
Never:本地仓库没有镜像不去dockerhub拉取,容器启动失败
(4)删除pod
kubectl delete deploy deploy名(命令行)
kubectl delete -f *.yml
(5)对node打标签,删除标签
kubectl label no 节点名 标签
kubectl label no hp2 disktype=ssd
kubectl label no 节点名 标签-
kubectl label no hp2 disktype-
(6)标签使用,可以使yml文件中创建的pod到某个node上运行

(7)pod的创建过程
用户通过kubectl或者是yml文件指定创建n个pod
kube-apiserver会通知deploy
deploy通知rs去创建pod
pod被调度,node节点通过kubelet创建运行容器
应用及配置信息存储在etcd中
flannel为每个pod分配网络
service创建后可外界访问
(8)pod的生命周期:pod被创建,pod被调度,pod一旦被分配到node上就不会离开node,除非被删除
(9)滚动更新
kubectl create deploy deploy名 --image=镜像名 --dry-run -o yaml > *.yml
kubectl create deploy nginx --image=nginx --dry-run -o yaml > *.yml
kubectl apply -f *.yml --record
kubectl rollout history deploy名
kubectl rollout undo deploy deploy名 --to-revision=值
(10)pod的动态伸缩
kubectl run deploy名 --image=镜像名 --replicas=pod数量
kubectl run deploy名 --image=镜像名 -r pod数量
kubectl scale --replicas pod数量 deploy deploy名
yml文件动态收缩只需要修改replicas后面的值,重新kubectl apply -f *.yml即可
(11)job和crontab启动为Never和OnFailure


(12)secret和configmap

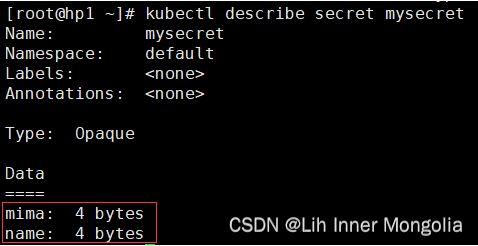
kubectl edit secret mysecret
(13)k8s的数据卷:emptyDir、hostpath、nfs、pvpvc
(14)k8s的探针:
Liveness 探测让用户可以自定义判断容器是否健康的条件。如果探测失败,Kubernetes 就会重启容器。

启动进程首先创建文件/tmp/healthy,30秒后删除,在我们的设定中,如果/tmp/healthy文件存在,则认为容器处于正常状态,反则发生故障。
livenessProbe 部分定义如何执行Liveness探测:
探测的方法是:通过cat命令检查/tmp/healthy文件是否存在。如果命令执行成功,返回值为零,Kubernetes则认为本次Liveness探测成功;如果命令返回值非零,本次Liveness探测失败。
initialDelaySeconds: 10 指定容器启动10秒之后开始执行Liveness探测,我们一般会根据应用启动的准备时间来设置。比如某个应用正常启动要花30秒,那么initialDelaySeconds的值就应该大于30。
periodSeconds: 5指定每5秒执行一次Liveness探测。Kubernetes如果连续执行3次Liveness探测均失败,则会杀掉并重启容器。
Readiness:用户通过Liveness探测可以告诉Kubernetes什么时候通过重启容器实现自愈;Readiness探测则是告诉Kubernetes什么时候可以将容器加入到Service负载均衡池中,对外提供服务。

Liveness探测和Readiness探测做个比较:
(1)Liveness探测和Readiness探测是两种Health Check机制,如果不特意配置,Kubernetes将对两种探测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断探测是否成功。
(2)两种探测的配置方法完全一样,支持的配置参数也一样。不同之处在于探测失败后的行为:Liveness探测是重启容器;Readiness探测则是将容器设置为不可用,不接收Service转发的请求。
(3)Liveness探测和Readiness探测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。用Liveness探测判断容器是否需要重启以实现自愈;用Readiness探测判断容器是否已经准备好对外提供服务。
18. KVM
Ⅰ型虚拟化
Hypervisor 直接安装在物理机上,多个虚拟机在 Hypervisor 上运行。Hypervisor 实现方式一般是一个特殊定制的 Linux 系统。Xen 和 VMWare 的 ESXi 都属于这个类型。
Ⅱ型虚拟化
物理机上首先安装常规的操作系统,比如 Redhat、Ubuntu 和 Windows。Hypervisor 作为 OS 上的一个程序模块运行,并对管理虚拟机进行管理。KVM、VirtualBox 和 VMWare Workstation 都属于这个类型。
(1)yum install libvirt virt-install qemu-kvm -y
libvirt : KVM 的管理工具。Libvirt 包含 3 个东西:后台 daemon 程序 libvirtd、API 库和命令行工具 virsh
qemu-kvm:KVM 和 QEMU 的核心包,提供 CPU、内存和 IO 虚拟化功能
virt-install是一个命令行工具,它能够为KVM、Xen或其它支持libvrit API的hypervisor创建虚拟机并完成GuestOS安装
(2)启动libvirtd
systemctl restart libvirtd
(3)创建磁盘
qemu-img create -f raw /hello/centos7-x86_64.raw 10G
(4)上传镜像
(5)创建虚拟机
virt-install --virt-type kvm --name Centos7-x86_64 --ram 1024 --cdrom=/tmp/CentOS-7.3-x86_64-Minimal-1511.iso --disk path=/ken/centos7-x86_64.raw --network network=default --graphics vnc,listen=0.0.0.0 --noautoconsole
(6)使用vnc链接vmware上的ip,安装系统
(7)查看和启动虚拟机
查看虚拟机:virsh list–all
启动虚拟机:virsh start NAME
克隆虚拟机
(1)创建磁盘位置
mkdir /new/img
(2)使用virt-clone克隆新的虚拟机
virt-clone -o Centos7-x86_64 -n centos7_test -f /ken/img/centos7_test.img
(3)查看虚拟机
virsh list–all
(4)启动虚拟机
virsh start NAME
19. haproxy
端口:5000
haproxy添加后端节点
vim /etc/haproxy/haproxy.cfg

haproxy监控web显示配置
(1)vim /etc/haproxy/haproxy.cfg

stats refresh 30s #统计页面自动刷新时间
stats uri /stats #统计页面url
stats realm baison-test-Haproxy #统计页面密码框上提示文本
stats auth admin:admin123 #统计页面用户名和密码设置
stats hide-version #隐藏统计页面上HAProxy的版本信息
(2)浏览器访问ip:5000
(3)输入用户名和密码