Golang - GMP模型
目录
- 线程池的缺陷
- Goroutine调度
-
- GMP模型
- Processor
-
- Processor常规调度
- Processor系统调用
- Processor数量
- P间的协程窃取
线程池的缺陷
我们以网络模型为例。互联网早起的网络模型有PPC和TPC:
PPC: 即Process Per Connection, 每个网络连接都新fork一个进程来处理TPC: 即Thread Per Connection, 每个网络连接都新建一个线程来处理
不管是fork进程还是新建线程,都存在较大的系统开销(线程相对更小),于是工程师们想到了PreFork和PreThread网络模型:
PreFork, 即预先创建好进程,新网络连接到来之后直接使用之前新建的进程,而不用临时创建,降低网络请求耗时PreThread,同理
再以PreThread为例,预先创建线程,并将其放在一起管理即为线程池。这种模式存在另外一个问题,即当线程处理一个网络请求时需要系统调用(IO),线程就会进入阻塞状态,同一时间可用的线程数减少,线程池的处理能力大大降低
纯粹增加线程池中的线程数量可以一定程度上环节这个问题,但是当线程数达到一个阈值后,线程切换将消耗大量的CPU,系统处理能力很快达到瓶颈
Goroutine调度
CPU线程切换的开销是影响系统处理性能的一大障碍,Go提供了一种机制,可以在用户空间实现任务的切换,上下文切换成本更小,可以达到使用较少的线程数量实现较大并发的能力,即GMP模型
GMP模型
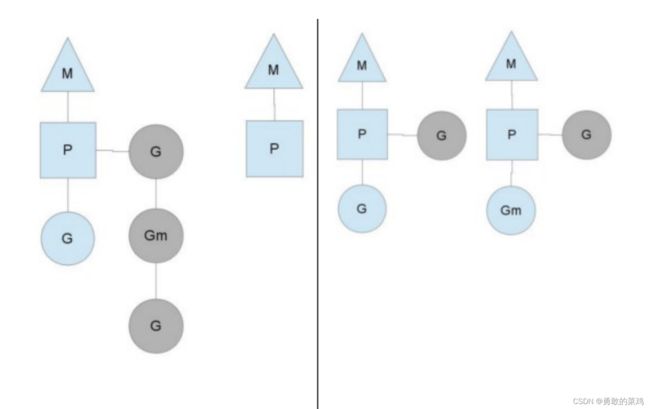
G(Goroutine): 即Golang协程,协程是一种用户态线程,比内核态线程更加轻量。使用go关键字可以创建一个Golang协程M(Machine): 即工作线程。实质上实现业务逻辑的载体P(Processor): 处理器。是Golang内部的定义,非CPU。包含运行Go代码的必要资源,也有调度Goroutine的能力
M必须拥有P,才能执行G中的代码,P负责G的调度,模型结构如下(图片引用自Go编程):

Processor
P的个数在程序启动时决定,默认情况下等同于CPU的核数,由于M必须持有一个P才可以运行Go代码,所以同时运行的 M个数,也即线程数一般等同于CPU的个数,以达到尽可能的使用CPU而又不至于产生过多的线程切换开销
Processor常规调度
每个P维护一个G队列,P周期性的将G调度到M上执行一小段时间,然后保存上下文,并将次G放到队列末尾,继续执行下一个G
除了每个Processor拥有的G队列以外,Go还维护一个全局G队列(主要是一些从系统调用/IO中恢复的G) ,Processor还会周期的查看全局G队列中时候有就绪的G,有的话就拿到自己的队列中,防止全局队列中的G被“饿死”
Processor系统调用
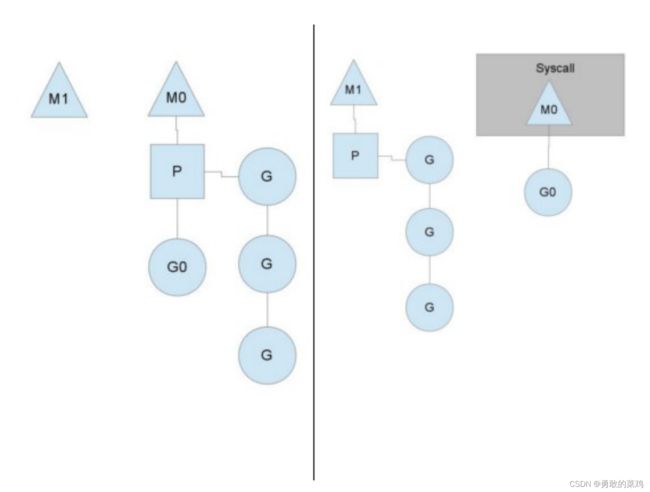
当Processor中的G产生系统调用/IO时,处理流程如下,假设此时运行线程为M0:
- Processor感知M0正在处理的协程G0处于系统调用的阻塞状态
- Processor将G0从自己的G队列中移除
- Processor重新申请新的M1,来继续执行G队列
- 如果有空闲的M,则直接复用空闲M
- 如果无空间的M,则新建一个线程M
- M0执行完G0的系统调用后,G0将存放在全局G队列中,等待某个Processor唤起
- 同时M0也进入空闲状态,等待其他P复用,或者被销毁
所以,系统中M的个数通常会略多于P的个数,但同时执行的M个数和P数量一样
上述流程示意图(图片引用自Go编程):
Processor数量
- Processor数量可以通过
runtime.GOMAXPROCS()设置,一般默认为CPU数量 - 对于IO密集型的应用,可以稍微提高Processor数量,原因在于:
- Processor感知G陷入系统调用也需要一定的时间,如果普遍存在系统调用的情况下,使用稍多的P可以增加感知G陷入系统调用的并发
P间的协程窃取
当协程分布不均匀的时候,如P0拥有10个G,而P1没有G处于空闲状态,此时P1将会从P0中窃取一般的协程进自己的协程队列执行,示意图大致如下(图片引用自Go编程):