【pyspark】CDH升级后Spark写入Hbase报错问题
【pyspark】CDH升级后Spark写入Hbase报错问题
-
- 前言
- 报错一
-
- 找不到StringToImmutableBytesWritableConverte类
- 分析
- 解决办法
- 报错二
-
- 找不到 org.apache.hadoop.hbase.client.Put类中的add方法
- 分析
- 解决办法
- 后记
前言
之前写了一版本Spark推数程序,将hive表内容经过列式转换后写入到Hbase:
- 【pyspark】酷酷的hive推数程序(至Hbase)
现在对于集群进行了升级,升级前的版本是这样的:
- CDH5.1
- Spark1.6(曾通过离线安装parcel升级至2.1)
- Hbase1.2
程序依赖清单为:
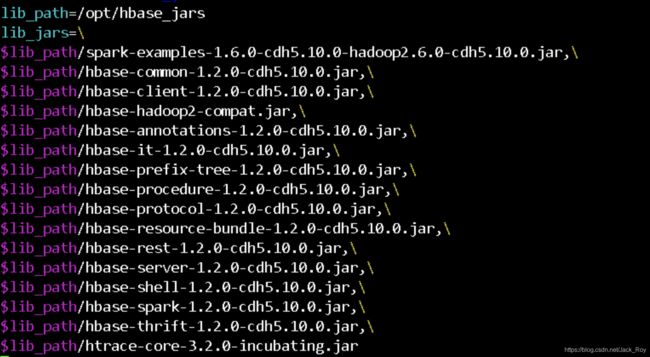
升级后的版本:
- CDH6.3
- Spark2.4
- Hbase2.1
程序依赖清单为:
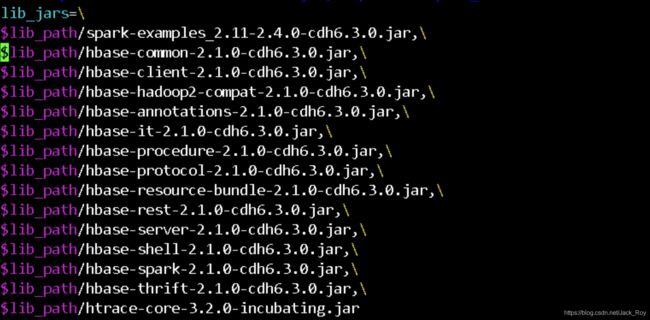
可以看到新版本的jar包均进行了替换,但是运行时还是发成了报错。
报错一
找不到StringToImmutableBytesWritableConverte类
具体报错内容:
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.saveAsHadoopDataset.: java.lang.ClassNotFoundException: org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:238)
at org.apache.spark.api.python.Converter$$anonfun$getInstance$1$$anonfun$1.apply(PythonHadoopUtil.scala:46)
at org.apache.spark.api.python.Converter$$anonfun$getInstance$1$$anonfun$1.apply(PythonHadoopUtil.scala:45)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.api.python.Converter$$anonfun$getInstance$1.apply(PythonHadoopUtil.scala:45)
at org.apache.spark.api.python.Converter$$anonfun$getInstance$1.apply(PythonHadoopUtil.scala:44)
at scala.Option.map(Option.scala:146)
at org.apache.spark.api.python.Converter$.getInstance(PythonHadoopUtil.scala:44)
at org.apache.spark.api.python.PythonRDD$.getKeyValueConverters(PythonRDD.scala:470)
at org.apache.spark.api.python.PythonRDD$.convertRDD(PythonRDD.scala:483)
at org.apache.spark.api.python.PythonRDD$.saveAsHadoopDataset(PythonRDD.scala:580)
at org.apache.spark.api.python.PythonRDD.saveAsHadoopDataset(PythonRDD.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
分析
在我的推数程序里有这么一段:
KEY_CONV="org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter"
VALUE_CONV="org.apache.spark.examples.pythonconverters.StringListToPutConverter"
CONF={"hbase.zookeeper.quorum":ZK_HOSTS,"hbase.mapred.outputtable":HBASE_TABLE_NAME,"mapreduce.outputformat.class":"org.apache.hadoop.hbase.mapreduce.TableOutputFormat","mapreduce.job.output.key.class":"org.apache.hadoop.hbase.io.ImmutableBytesWritable","mapreduce.job.output.value.class":"org.apache.hadoop.io.Writable"}
rdd.saveAsNewAPIHadoopDataset(conf=CONF,keyConverter=KEY_CONV,valueConverter=VALUE_CONV)
可以看到rdd最后save提交时需要指定一个keyConverter,这个keyConverter指的就是org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter类,现在提示找不到,就说明这个类不在我们提供的lib中,解决办法就是提供一个有这个类的jar包。
解决办法
下载spark-examples_2.11-1.6.0-typesafe-001.jar 来替换lib jar中的spark-examples_2.11-2.4.0-cdh6.3.0.jar,之后再运行该报错解决。
报错二
找不到 org.apache.hadoop.hbase.client.Put类中的add方法
具体报错内容:
java.lang.NoSuchMethodError: org.apache.hadoop.hbase.client.Put.add([B[B[B)Lorg/apache/hadoop/hbase/client/Put;
at org.apache.spark.examples.pythonconverters.StringListToPutConverter.convert(HBaseConverters.scala:81)
at org.apache.spark.examples.pythonconverters.StringListToPutConverter.convert(HBaseConverters.scala:77)
at org.apache.spark.api.python.PythonHadoopUtil$$anonfun$convertRDD$1.apply(PythonHadoopUtil.scala:181)
at org.apache.spark.api.python.PythonHadoopUtil$$anonfun$convertRDD$1.apply(PythonHadoopUtil.scala:181)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$4.apply(SparkHadoopWriter.scala:129)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$4.apply(SparkHadoopWriter.scala:127)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)
at org.apache.spark.internal.io.SparkHadoopWriter$.org$apache$spark$internal$io$SparkHadoopWriter$$executeTask(SparkHadoopWriter.scala:139)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$3.apply(SparkHadoopWriter.scala:83)
at org.apache.spark.internal.io.SparkHadoopWriter$$anonfun$3.apply(SparkHadoopWriter.scala:78)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
分析
发生该报错原因是在spark2.4版本中,examples包中的StringListToPutConverter(scala) 类调用了org.apache.hadoop.hbase.client.Put类中的add方法,但是Hbase经过版本升级后,在2.x版本已经废除了add方法,现在提供add原有功能的方法名叫addColumn(add与addColumn这两个方法曾在1.x版本并存过,那时已经不推荐使用add,直到2.x 彻底采用addColumn)。
解决办法
下载spark2.1版的源码,修改顶层pom文件的Hbase版本为1.0.0:
修改StringListToPutConverter类的add方法为addColumn,修改前:
/**
* Implementation of [[org.apache.spark.api.python.Converter]] that converts a
* list of Strings to HBase Put
*/
class StringListToPutConverter extends Converter[Any, Put] {
override def convert(obj: Any): Put = {
val output = obj.asInstanceOf[java.util.ArrayList[String]].asScala.map(Bytes.toBytes).toArray
val put = new Put(output(0))
put.add(output(1), output(2), output(3))
}
}
修改后:
/**
* Implementation of [[org.apache.spark.api.python.Converter]] that converts a
* list of Strings to HBase Put
* 改动!
*/
class StringListToPutConverter extends Converter[Any, Put] {
override def convert(obj: Any): Put = {
val output = obj.asInstanceOf[java.util.ArrayList[String]].asScala.map(Bytes.toBytes).toArray
val put = new Put(output(0))
put.addColumn(output(1), output(2), output(3))
}
}
最后重新打包spark-examples,替换之前的lib包即可,运行之后完美兼容。
后记
这里提供一下我修改后的jar包,需要的可以直接下载:spark-examples_2.10-1.6.4-SNAPSHOT.jar