Seq2Seq之双向解码机制 | 附开源实现

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
在文章玩转Keras之Seq2Seq自动生成标题中我们已经基本探讨过 Seq2Seq,并且给出了参考的 Keras 实现。
本文则将这个 Seq2Seq 再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自 Synchronous Bidirectional Neural Machine Translation,最后笔者也是用 Keras 实现的。


背景介绍
研究过 Seq2Seq 的读者都知道,常见的 Seq2Seq 的解码过程是从左往右逐字(词)生成的,即根据 encoder 的结果先生成第一个字;然后根据 encoder 的结果以及已经生成的第一个字,来去生成第二个字;再根据 encoder 的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解。
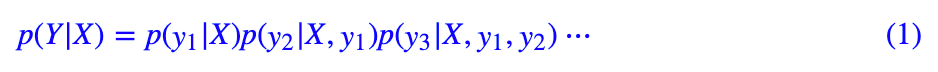
当然,也可以从右往左生成,也就是先生成倒数第一个字,再生成倒数第二个字、倒数第三个字,等等。问题是,不管从哪个方向生成,都会有方向性倾斜的问题。比如,从左往右生成的话,前几个字的生成准确率肯定会比后几个字要高,反之亦然。在 Synchronous Bidirectional Neural Machine Translation 给出了如下的在机器翻译任务上的统计结果:

L2R 和 R2L 分别是指从左往右和从右往左的解码生成。从表中我们可以看到,如果从左往右解码,那么前四个 token 的准确率有 40% 左右,但是最后 4 个 token 的准确率只有 35%;反过来也差不多。这就反映了解码的不对称性。
为了消除这种不对称性,Synchronous Bidirectional Neural Machine Translation 提出了一个双向解码机制,它维护两个方向的解码器,然后通过 Attention 来进一步对齐生成。
双向解码
虽然本文参考自 Synchronous Bidirectional Neural Machine Translation,但我没有完全精读原文,我只是凭自己的直觉粗读了原文,大致理解了原理之后自己实现的模型,所以并不保证跟原文完全一致。此外,这篇论文并不是第一篇做双向解码生成的论文,但它是我看到的双向解码的第一篇论文,所以我就只实现了它,并没有跟其他相关论文进行对比。
基本思路
既然叫双向“解码”,那么改动就只是在 decoder 那里,而不涉及到 encoder,所以下面的介绍中也只侧重描述 decoder 部分。还有,要注意的是双向解码只是一个策略,而下面只是一种参考实现,并不是标准的、唯一的,这就好比我们说的 Seq2Seq 也只是序列到序列生成模型的泛指,具体 encoder 和 decoder 怎么设计,有很多可调整的地方。
首先,给出一个简单的示意动图,来演示双向解码机制的设计和交互过程:
▲ Seq2Seq的双向解码机制图示
如图所示,双向解码基本上可以看成是两个不同方向的解码模块共存,为了便于描述,我们将上方称为 L2R 模块,而下方称为 R2L 模块。开始情况下,大家都输入一个起始标记(上图中的 S),然后 L2R 模块负责预测第一个字,而 R2L 模块负责预测最后一个字。
接着,将第一个字(以及历史信息)传入到 L2R 模块中,来预测第二个字,为了预测第二个字,除了用到 L2R 模块本身的编码外,还用到 R2L 模块已有的编码结果;反之,将最后一个字(以及历史信息)传入到 R2L 模块,再加上 L2R 模块已有的编码信息,来预测倒数第二个字;依此类推,直到出现了结束标记(上图中的E)。
数学描述
换句话说,每个模块预测每一个字时,除了用到模块内部的信息外,还用到另一模块已经编码好的信息序列,而这个“用”是通过 Attention 来实现的。用公式来说,假设当前情况下 L2R 模块要预测第 n 个字,以及 R2L 模块要预测倒数第 n 个字。假设经过若干层编码后,得到的 R2L 向量序列(对应图中左上方的第二行)为:
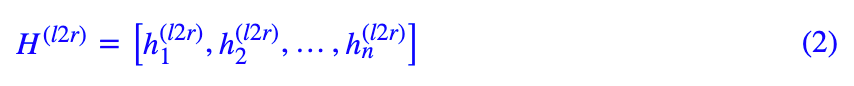
而 R2L 的向量序列(对应图中左下方的倒数第二行)为:
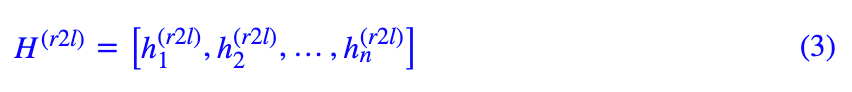
如果是单向解码的话,我们会用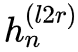 作为特征来预测第 n 个字,或者用
作为特征来预测第 n 个字,或者用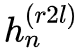 作为特征来预测倒数第 n 个字。
作为特征来预测倒数第 n 个字。
在双向解码机制下,我们以为 query,然后以![]() 为 key 和 value 来做一个 Attention,用 Attention 的输出作为特征来预测第 n 个字,这样在预测第 n 个字的时候,就可以提前“感知”到后面的字了。
为 key 和 value 来做一个 Attention,用 Attention 的输出作为特征来预测第 n 个字,这样在预测第 n 个字的时候,就可以提前“感知”到后面的字了。
同样地,我们以为 query,然后以![]() 为 key 和 value 来做一个 Attention,用 Attention 的输出作为特征来预测倒数第 n 个字,这样在预测倒数第 n 个字的时候,就可以提前“感知”到前面的字了。
为 key 和 value 来做一个 Attention,用 Attention 的输出作为特征来预测倒数第 n 个字,这样在预测倒数第 n 个字的时候,就可以提前“感知”到前面的字了。
上面示意图中,上面两层和下面两层之间的交互,就是指 Attention。在下面的代码中,用到的是最普通的乘性 Attention(参考一文读懂「Attention is All You Need」| 附代码实现)。
模型实现
上面就是双向解码的基本原理和做法。可以感觉到,这样一来,Seq2Seq 的 decoder 也变得对称起来了,这是一个很漂亮的特点。当然,为了完全实现这个模型,还需要思考一些问题:1. 怎么训练?2. 怎么预测?
训练方案
跟普通的 Seq2Seq 一样,基本的训练方案就是用所谓的 Teacher-Forcing 的方式来进行训练,即 L2R 方向在预测第 n 个字的时候,假设前 n−1 个字都是准确知道的,而 R2L 方向在预测倒数第 n 个字的时候,假设倒数第 n−1,n−2,…,1 个字都是准确知道的。最终的 loss 是两个方向的逐字交叉熵的平均。
不过这样的训练方案实在是无可奈何之举,后面我们会分析它信息泄漏的弊端。
双向束搜索
现在讨论预测过程。
如果是常规的单向解码的 Seq2Seq,我们会使用 beam search(束搜索)的算法,给出概率尽可能大的序列。所谓 beam search,指的是依次逐字解码,每次只保留概率最大的 topk 条“临时路径”,直到出现结束标记为止。
到了双向解码这里,情况变得复杂了一些。我们依然用 beam search 的思路,但是同时缓存两个方向的 topk 结果,也就是说,L2R 和 R2L 两个方向各存 topk 条临时路径。此外,由于双向解码时,L2R 的解码是要参考 R2L 已有的解码结果的,所以当我们要预测下一个字时,除了要枚举概率最高的 topk 个字、枚举 topk 条 L2R 的临时路径外,还要枚举 topk 条 R2L 的临时路径,所以一共要计算 topk3 那么多个组合。
而计算完成后,采用了一种最简单的思路:对每种“字 - L2R 临时路径”的得分在“R2L 临时路径”这一维度上做了平均,使得的分数变回 topk2个,作为每种“字 - L2R 临时路径”的得分,再从这 topk2 个组合中,选出分数最高的 topk 个。而 R2L 这边的解码,则要进行反向的、相同的处理。最后,如果 L2R 和 R2L 两个方向都解码出了完成的句子,那么就选择概率(得分)最高的那个。
这样的整个过程,我们称之为“双向束搜索(双向beam search)”。如果读者自己比较熟悉单向的 beam search,甚至自己都写过 beam search 的话,上述过程其实不难理解(看看代码就更容易懂了),它算是单向 beam search 自然延伸。
当然,如果对 beam search 本身不了解的话,看上述搜索的过程应该是云里雾里的。所以想要弄清楚原理的读者,应该要从常规的单向 beam search 出发,先把它弄懂了,然后再看上述解码过程的描述,最后再看看下面给出的参考代码,就容易弄懂了。
代码参考
下面是笔者给出了双向解码的参考实现,整体还是跟之前的玩转Keras之Seq2Seq自动生成标题一致,只是解码端从双向换成单向了:
注:测试环境还是跟之前差不多,大概是 Python 2.7 + Keras 2.2.4 + Tensorflow 1.8。用 Python 3.x 或者其他环境的朋友,如果你们能自己改,那就做相应的改动,如果你们自己不会改,那也请你们别来问我了,我实在没有空也没有义务帮你们跑通每一个环境。本文只讨论 Seq2Seq 技术相关的内容可否?
在这个实现里,我觉得有必要解释一下起始标记和结束标记的事情。在之前的单向解码的例子中,笔者是用 2 作为起始标记,用 3 作为结束标记。到了双向解码这里,一个很自然的问题就是:L2R 和 R2L 两个方向是不是应该要用两套起始和结束标记呢?
其实这个应该没有什么标准答案,我觉得不管是共用一套还是维护两套起止标记,结果可能都差不多。至于我在上面的参考代码中,使用的方案有点另类,但我认为比较符合直觉,具体是:依然是只用一套,但是在 L2R 方向中,用 2 作为起始标记、3 作为结束标记,而在 R2L 方向中,用 3 作为起始标记、2 作为结束标记。
思考分析
最后,我们进一步思考一下这种双向解码方案。尽管将解码过程对称化是一个很漂亮的特点,但也不代表它完全没有问题了,将它思考得更深入一些,有助于我们更好地理解和使用它。
1. 改进生成的原因
一个有意思的问题是:看上去双向解码确实能提高句子首尾的生成质量,但会不会同时降低中间部分的生成质量?
当然,理论上这是有可能的,但实际测试时不是很严重。一方面,seq2seq架构的信息编码和解码能力还是很强的,所以不会轻易损失信息;另一方面,我们自己去评估一个句子的质量的时候,往往会重点关注首尾部分,如果首尾部分都很合理,而中间部分不至于太糟糕的话,那么我们都认为它是一个合理的句子;反过来,如果首或尾不合理的话,我们会觉得这个句子很糟糕。这样一来,把句子首尾的生成质量提高了,整体的生成质量也就提高了。
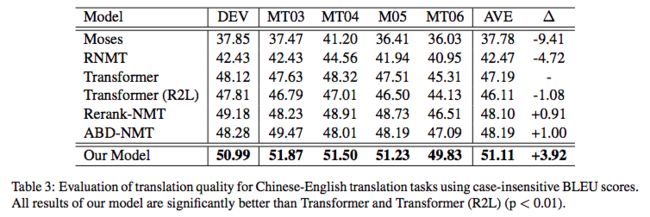
▲ 原论文中双向解码相对其它单向模型带来的提升
2. 对应不上概率模型
对于单向解码,我们有清晰的概率解释,即在估计条件概率 p(Y|X)(也就是 (1))。但是在双向解码的时候,我们发现压根儿不知道怎么对应上一个概率模型,换句话说,我们感觉我们是在算概率,感觉效果也有了,却不知道真正算得是啥,因为条件概率的条件依赖完全已经被打乱了。
当然,如果真的有实效的话,理论美感差点也无妨,我说的这一点只是理论审美的追求,大家见仁见智就好。
3. 信息提前泄漏
所谓信息泄漏,指的是本来作为预测目标的标签被用来做输入了,从而导致训练阶段的 loss 虚低(或者准确率虚高)。
由于在双向解码中,L2R 端的解码要去读取 R2L 端已有的向量序列,而在训练阶段,为了预测 R2L 端的第 n 个字,是需要传入前 n−1 个字的,这样一来,越解码到后面,信息泄漏就越严重。如下图所示:
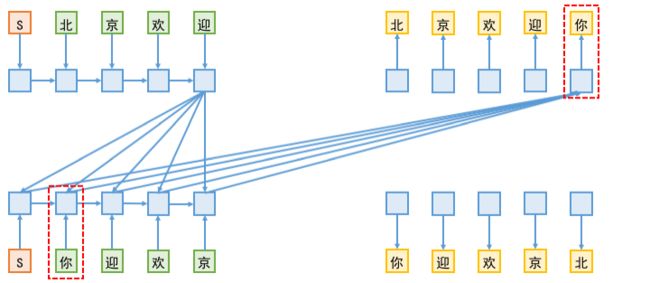
信息泄漏的一个表观现象是:训练到后期,双向解码中 L2R 和 R2L 两个方向的交叉熵之和,比单独训练单向解码模型时的单个交叉熵还要小,这并不是因为双向解码带来多大的拟合提升,而正是信息泄漏的体现。
既然训练过程中把信息泄漏了,那为什么这样的模型还有用呢?我想,大概的原因在文章一开头的表格中就给出了。还是刚才的例子,L2R 端在预测最后一个字“你”的时候,会用到了 R2L 端所有的已知信息;而 R2L 端是从右往左逐字解码的,按照文章一开头的表格的统计数据,我们不难想象到,对于 R2L 端来说,倒数第一个字的预测准确率应该是最高的。
这样一来,假设 R2L 的倒数第一个字真的能以很高的准确率预测成功的话,那信息泄漏也变成不泄漏了——因为信息泄漏是因为我们人为地传入了标签,但如果预测的结果本身就跟标签一致,那泄漏也不再是泄漏了。
当然,原论文还提供了一个策略来缓解这个泄漏问题,大概做法是先用上述方式训练一版模型,然后对于每个训练样本,用模型生成对应的预测结果(伪标签),接着再去训练模型,这一次训练模型是传入伪标签来预测正确标签,这样就尽可能地保持了训练和预测的一致性。
文章小结
本文介绍并实现了一种 Seq2Seq 的双向解码机制,它将整个解码过程对称化了,从而在一定程度上使得生成质量更高了。个人认为这种改进的尝试还是有一定的价值的,尤其是对于追求形式美的读者来说。所以就将其介绍一番。
除此之外,文章也分析了这种双向解码可能存在的问题,给出了笔者自己的看法。敬请各位读者多多交流指教。

点击以下标题查看作者其他文章:
变分自编码器VAE:原来是这么一回事 | 附源码
再谈变分自编码器VAE:从贝叶斯观点出发
变分自编码器VAE:这样做为什么能成?
简单修改,让GAN的判别器秒变编码器
深度学习中的互信息:无监督提取特征
全新视角:用变分推断统一理解生成模型
细水长flow之NICE:流模型的基本概念与实现
细水长flow之f-VAEs:Glow与VAEs的联姻
深度学习中的Lipschitz约束:泛化与生成模型
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 查看作者博客