Hinton机器学习与神经网络课程的第二章学习笔记
Hinton机器学习与神经网络课程的第二章学习笔记
该笔记为自己以后方便查阅,要是有大神感觉我的笔记有哪些地方记的有误差或者不对的话也欢迎指出
文章目录
- Hinton机器学习与神经网络课程的第二章学习笔记
-
- 1.神经网络架构介绍
-
- 1.1前馈神经网络
- 1.2循环神经网络
- 1.3双向对偶网络
- 2.感知器
- 3.感知器的几何空间解析
- 4.感知器的原理透析
- 5.感知器的局限性
1.神经网络架构介绍
神经网络的多种体系结构,体系结构为将神经元联系在一起的方法。
在应用中常见的体系结构类型为前馈神经网络,在前馈网络中,信息从输入单元层开始朝着一个方向传递,通过隐藏层直至输出层。
还有一种体系结构为递归神经网络,在这个网络中信息循环流动。这些网络可以长时间地记忆信息,并可以显示各种有意思的振荡,但是进行部分训练将会变得更加困难,因为相对于它们能够做的事情来说,他们自身要复杂的多。
介绍的最后一种体系结构为双向对偶结构,在这种结构中两个单元中的两个方向里的权重是相同的。
1.1前馈神经网络
前馈神经网络输入单元在倒数第一层,输出单元在顶部的最后一层和隐藏单元的一层或多层

如果隐藏单元超过一层,就称其为深度神经网络,这些网络在输入与输出之间计算出一系列的变换。因此在每一层,都会得到关于输出的新的表现,在这里,与前一层相似的东西将不会那么相似,或者与前一层不同的东西将会变得相似。
为了实现这种想法,我们需要将每层神经元得激活函数是前一层神经元输出值的非线性函数
1.2循环神经网络
该网络比前馈神经网络更加有力,循环神经网络的图结构中包含了一点的有向环,意思是如果你以一个节点或是神经元开始,然后按照箭头的指示进行下去,你可能会回到你开始的那个神经元。
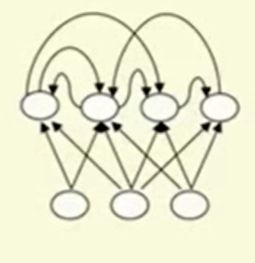
循环神经网络可能包涵非常复杂的参数动态变化,因此他们很难被训练。
本质上他们具有更好的人脑仿真模拟结构,含有多重隐藏层的循环神经网络是初始循环网络中的一种改进版,它的隐藏层可以将浅层网络中遗失的节点也连接起来。
循环网络是对时序数据建模的一种非常好的方法,这使我们拥有了隐藏单元之间的联系。而在每一个时刻,当时的隐藏单元的状态决定了在下一个时刻的隐藏单元的状态。
循环神经网络区别与前馈神经网络的一个方面是我们在每个时刻都使用相同的权值
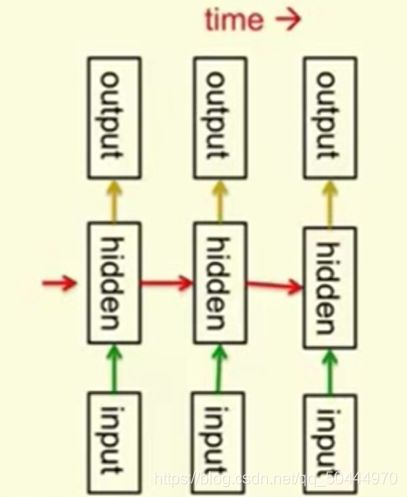
它们在每时获得输入并且提供输出,这些矩阵也是相同的。循环网络能够长时间地记住隐藏的信息。但是,训练它们使用这种能力是很困难的。不过近期有算法有能力可以训练它们了。
1.3双向对偶网络
该网络连接里再两个方向里单元之间的权重是相同的。相对于循环网络双向对偶网络要容易分析的多,主要因为是它们在特定任务上更容易添加约束条件, 而这是因为它们遵从一个能量函数。
2.感知器
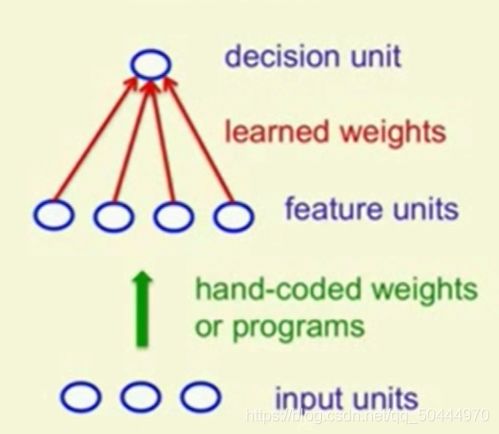
标准感知器被罗森布拉特命名为阿尔法感知器,由一些输入数据组成进而转化成未来的活动。但这个系统阶段不学习,一旦你掌握了活动的特点你就会学到一些权值,这样你就可以用这些特征激活值乘以权值,之后通过衡量乘积是否大于某个阈值来决定对应的这个样例是否为你感兴趣的
1969年,明斯基和佩伯特出版了一本书叫《感应器》,该数分析了感应器能做什么,也表明了它的局限性。许多人认为所有的神经网络模型都将无法摆脱这些局限性,并且从人工智能的角度来看就像明斯基和佩伯特之前说明的一样,神经网络系列对此毫无价值 ,因为他们无法应对很难的场景。尽管这个模型已经有了很强的学习算法,但是在很多任务上遇到瓶颈,不能通过学习过程来找到解决之道。对于此类问题来说,即使你在输入端加入很多手工先验证,却依然不能促进学习的提示,而且输出的结果还是会过于模糊。
感知机中的决策单元是一个二元阈值神经元。他们计算他们从其他神经元得到的输入的权值和他们添加一个偏置,以获得他们的总输入。如果总和超过零,他们就输出这个总和,否则就输出零

3.感知器的几何空间解析
空间的里一个维度对应感知器的一个权值,空间里的一个点代表所有权值的一个特别的装置,假设你已经排除了临界值。我们可以代表把每一个练习案例都当做一个在加权空间里经过原点的超平面,所有空间里的点对应着加权向量,练习案例对应的是空间。特别的练习案例和权值取决于超平面的一条边,这样就确保了能够获得训练样例的正确答案。

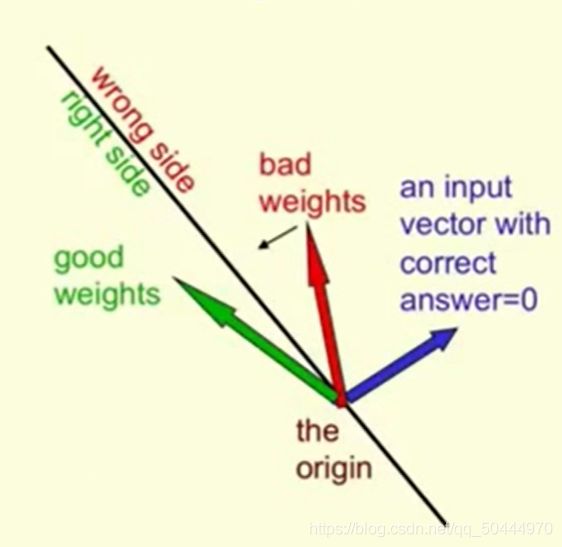
定义了一个空间,在这个2D的图片里这个空间只是一条穿过原点的黑色的线而且它与输入向量垂直。练习案例是蓝色向量表示的。
这个练习案例的分析:它的正确答案是1,对于这种类型的练习案例,加权向量需要在超平面的正确的一边。为了得到正确的答案,需要在超平面的同一边的是练习向量所指的方向,对于任何在超平面这边,像绿色向量这样的加权向量,它和输入向量所成的角度要小于90°,所以输入向量和加权向量的内积将是一个正数,由于我们已经减去了阈值,也就意味着输出结果的概率值可以直接表明这是一个正向样例。相反的,如果我们有一个加权向量,像图上红色的这个一样在平面错误的一侧,与输入向量所成的角就会大于90°。所以加权向量与输出向量的内积就为负数,我们得到的结果就小于零。因此感知器就会显示错误或者显示0。所以这是一个负样例。
总结:在平面的一侧,所有加权向量都会得到正确的结果,在平面的另一侧,所有可能的加权向量都会得到错误的答案。
现在将这两个练习案例放到一张加权空间的图片里(如下图)

现在可以看到任何可能的加权向量上都有一个锥平面,在锥平面里面的任意加权向量在这两个练习案例中都会得到正确答案。当然不会有像这样的代码出现,也不会有这样的加权向量在所有的练习案例中都得出正确答案。我们要思考得是一次只考虑一个练习案例并且以这样一种方式将加权向量移动到代码中得最后一行。如果得到了一个好的加权向量它对所有的练习案例都同样适用,这个向量在锥平面,如果你有另一个加权向量也在锤平面,而如果你取这两个加权向量的平均值,这个平均值也会在锥平面。意味着这个问题是一个凸优化问题。在机器学习的模型中假如你可以找到你一个凸优化学习问题,那么就意味着两个已知解的平均值本身也是一个解,这样就会大大的简化问题。
4.感知器的原理透析
学习一个输入向量通过学习过程获取指向特定输出方案的权值组合
我们试图通过可视化感知器学习过程中权值空间的变化去证明感知器模型总是会最终寻找到足以较好地拟合所有训练样例的正确参数结果如果这样的样例存在的话。所以我们假设对所有的培训案例都有正确的答案的例证存在,我们叫它可行向量。下图中绿色的标点就为可行向量。
所有从加权向量开始得到一些错误的练习案例,在图中显示的这个练习案例就是错的。这个想说明的是这个例证的观点是每次得到一个错误的案例,感知器都会通过更加接近可行向量的办法更新元素的加权向量。因此,我们可以从可行向量中表示元素的权重向量的平方距离作为输入向量沿线平方距离之和。定义的这个练习案例和另一平方距离垂直,垂直的平方距离不会改变而且沿线输入的向量的平方距离会变的更小,因此希望的要求是每次感受器出错,我们元素的加权向量会更加接近于所有可行向量现在基本上是对的,但是还有问题存在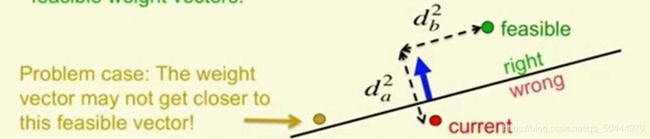
就比如上图的金色的可行向量只在平面右侧定义了一个案例而且元素向量在错误的一侧,而输入向量又特别大,所以当我们往加权向量上添加一个输入向量。但是实际上这样只会离金色的可行向量越来越远所以我们希望的假设并不会起作用,但是我们可以完善它就能正常运行。
接下来定义一个全能可行的加权向量,这个加权向量不仅在练习案例中不出错,而且通过最少一个一点大小的间距就能得到正确答案。
这个间距的长度,在这个练习案例中和输入向量长度一样所以我们取可行解的锥,而在里面我们有另一个锥形的全能可行的解决措施,这个措施纠正了所有错误,至少和输入向量的长度一样,现在我的的假设就成立了。现在我们可以断定,每次感知器出错的时候,所有可行的权向量的平方距离将至少减少更新向量的平方长度,也就是我们更新的内容。所以,我们可以得到一个非正式的关于集合证明草图。所以每次感受器出错元素加权向量从每一个全能的可行向量移动,缩小了它的平方距离,是通过最小电流输入向量的平方长度完成的。因此所有的全能的可行权重向量的平方距离都减少了平方长度,假设没有无限小的输入向量,就意味着在有限的错误之后,权向量必须位于可行域如果这个区域存在,它就不必依靠在全能可行的区域,但是至少要进入可行域来停止犯错。这就是一个非正式草图来证明感知器集合工作的过程。但是要注意的是这些都取决于那个假设,前提是我们假设有一个全能的可行加权向量,如果没有该假设,则全部证明就会垮塌。
5.感知器的局限性
感知器的局限性来自于你使用的各种特征,如果你使用了正确的特征,你可以做几乎所有事,如果你用了错误的特征,他们会极度限制于感知器的学习特征的运行。这就是感知器曾经坠入谷底的原因之一,而且它强调学习的难点是学习正确的特征,如果不学习特征也可以做很多事情。
假设我们有二进制输入向量,我们创建一个单独的特征单元,由其中一个二进制输入向量激活将需要成倍多特征单元,但是现在我们可以对二进制输入向量做任何可能的区分,所以对于二进制输入向量没有限制。这并不是解决问题的好方法,因为你需要大量的特征单元,而且它不会自己总结。一旦你决定了手工编码的特征,这是他们一直以来都坚持的对于感受器可以学习什么有很强的局限性。
分,所以对于二进制输入向量没有限制。这并不是解决问题的好方法,因为你需要大量的特征单元,而且它不会自己总结。一旦你决定了手工编码的特征,这是他们一直以来都坚持的对于感受器可以学习什么有很强的局限性。