20210930:Trick篇-Hessian-based Analysis of Large Batch Training andRobustness to Adversaries
论文:Hessian-based Analysis of Large Batch Training and Robustness to Adversaries
论文: https://arxiv.org/pdf/1802.08241.pdf
代码:https://github.com/amirgholami/hessianflow
Trick:
伯克利大学出品,神经网络可视化研究,理论较多,取其观点即可

要点记录:
1:开门见山:large_batchsize训练会导致精度损失
与下面两篇文章的结论是一致的
Accurate, large minibatch SGD: training imagenet in 1 hour.
On large-batch training for deep learning: Generalization gap and sharp minima.
-----------------------------------------------------------------------------------------------------------------
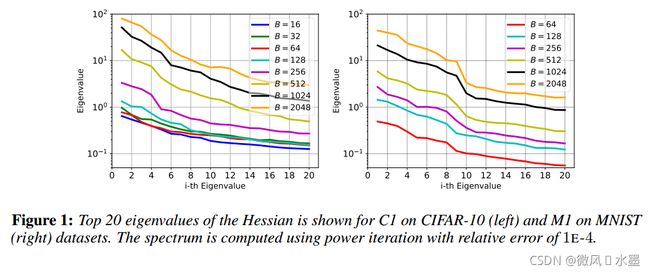 要点记录:
要点记录:
1.hessian 是迭代计算的,直到每个特征值的相对误差小于 1e-4。即随着批量大小的增加,hessian 的谱也随之增加,大批量训练的顶部特征值比小批量训练的顶部特征值相对较大。
我们知道,模型如果收敛到一个比较尖锐的极小值——模型会缺乏泛化能力。而模型收敛解的锐度就可以由 hessian 的谱得出。因此,上图看到的随着批量增大而增大的 hessian 谱在一定程度上解释了为什么大批量训练的模型泛化能力更差:因为训练处的模型收敛到了更尖锐的解。
-----------------------------------------------------------------------------------------------------------------
 要点记录:
要点记录:
2.这一点与我们在上一篇文章中观察到的现象相符合,batch_size越大,等高线图显示模型的极小值更深,其对应的误差率往往也越高。
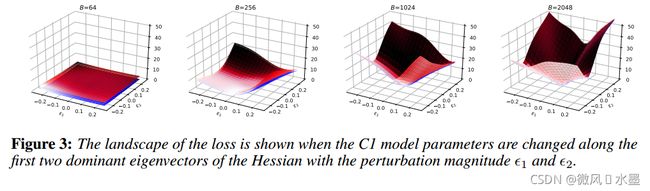
----------------------------------------------------------------------------------------------------------------- 
要点记录:
1.用以说明,不是batch_size越大越好。增加到一定程度后,精度反而会下降。
-----------------------------------------------------------------------------------------------------------------
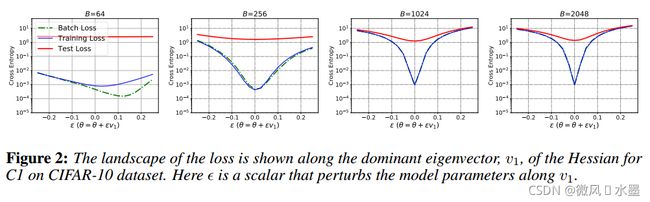

要点记录:
1.随着批量的增加,训练损失和测试损失的曲度都开始增加,更重要的是,当批量增加,差异更大。这代表了训练中的不一致性,因此即便大批量模型训练的损失很小,其在测试集上的损失仍然会很大。
-----------------------------------------------------------------------------------------------------------------

要点记录:
1.sharp mionima 有时候也是可以范化很好的,这个并不是绝对的。
-----------------------------------------------------------------------------------------------------------------

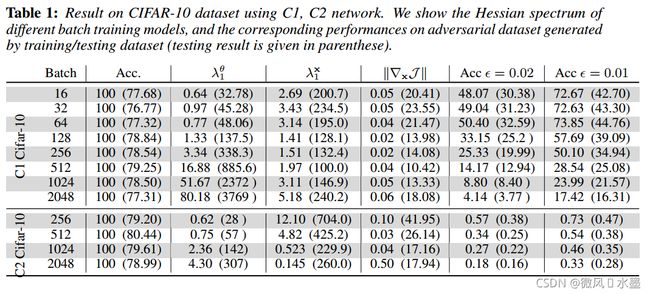
要点记录:
1.小批量训练的模型相比,以大批量训练的模型明显更容易被对抗性攻击成功。【这个图我没太看明白】