【OpenVINO】C#调用OpenVINO部署Al模型项目开发-6.C#实现OpenVINOTM方法的调用
6 C#实现OpenVINOTM方法的调用
6.1 新建C#项目
右击解决方案,添加->新建项目,选择添加C#控制台项目,项目框架根据电脑中的框架选择,此处使用的是.NET 5.0。
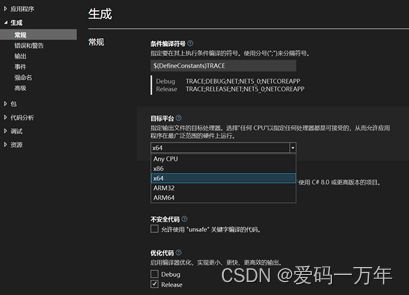
新建完成后,右击项目,选择属性,点击新页面中的生成,在常规下,将目标平台改为X64。具体操作如图1- 14所示。
6.2 添加OpenCVsharp
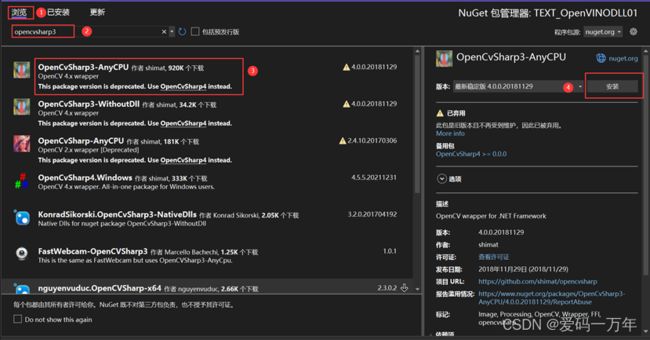
右击项目,选择管理NuGet程序包,在新页面中选择浏览,在搜索框中输入opencvsharp3,在搜索结果中,找到OpenCvSharp3-AnyCPU,然后右侧点击安装,具体操作步骤如图1- 15所示。
6.3 添加项目引用
上一步中我们将dll文件中的方法引入到C#中,并组建了Core类,在这一步中,我们主要通过调用Core类,进行Al模型的部署,所以需要引入上一步的项目。
右击当前项目,选择添加,选择项目引用,在出现的窗体中,选择上一步中创建的项目OpenVinoSharp,点击确定;然后在当前项目下,添加using OpenVinoSharp命名空间。具体操作如图1- 16所示。

6.4 编写代码测试花卉分类模型
在该项目中,我们提供了两种推理模型,此处我们以花卉分类模型为例,简介如何通过C#调用OpenVINOTM 进行Al模型的部署。
(1)引入相关变量
string device_name = "CPU";
string model_file = "E:/Text_Model/flowerclas/flower_rec.onnx";
string image_file = "E:/Text_dataset/flowers102/jpg/image_00001.jpg";
string input_node_name = "x";
string output_node_name = "softmax_1.tmp_0";
为了让大家更加清晰的看懂后续代码,在此处对引入的相关变量进行解释:
device_name:设备类型名称,可为CPU、GPU以及AUTO(均可);
model_file:模型地址,可以为onnx、pdmodel或者xml格式;
image_file:测试图片地址;
input_node_name:输入模型节点名,当多输入时,可以为数组;
output_node_name:输出模型节点名,当多输出时,可以为数组。
(2)初始化Core类
在此处我们直接调用Core类的构造函数,进行初始化:
Core ie = new Core(model_file_paddle, device_name);
(3)配置模型输入
花卉分类模型输入只有一个,即待分类花卉图片。如果我们调用的模型未指定输入大小,需要在输入数据前,调用模型输入数据形状设置方法,设置节点输入数据形状。图片数据为三维数组,再加一个batchsize,最终为四维数据,将形状数据放在数组中,调用set_input_sharp()方法:
ulong[] image_sharp = new ulong[] { 1, 3, 224, 224 };
ie.set_input_sharp(input_node_name, image_sharp);
对于图片数据,需要将其转为转为矩阵数据,在此处,我们可以直接使用opencvsharp中的编解码方法,将图片数据放置在byte数组中:
Mat image = new Mat(image_file);
byte[] image_data = new byte[2048 * 2048 * 3];
ulong image_size = new ulong();
image_data = image.ImEncode(".bmp");
image_size = Convert.ToUInt64(image_data.Length);
就最后调用Core类中的load _input_data()方法,将数据加载到推理网络中:
ie.load_input_data(input_node_name, image_data, image_size);
在配置完输入数据后,调用模型推理方法,对输入数据进行推理:
ie.infer();
接下来就是读取推理结果,对于模型的推理结果输出一般为数组数据,可以通过调用Core类中读取推理数据结果的方法,对与花卉分类模型的输出,其结果为长度为102的浮点型数据,所以直接调用read_inference_result方法读取即可:
float[] result = new float[102];
result = ie.read_infer_result(output_node_name, 102);
在读取推理数据时,我们一定要根据模型的书名读取正确的结果数据,因为如果超出实际输出长度,其结果数据会掺杂其他干扰数据。
最后一步就是处理输出数据。对于不同的推理模型,其结果处理方式是不同的,对于花卉分类模型,其输出为102种分类情况打分,因此,在处理数据时,需要找出得分最高的哪一类即可。在此处,我们提供了一个方法,该方法可以实现提取数组中前N个max数据的位置,通过调用该方法,我们可以获取分类结果中分数最高的几个结果,并将结果打印输出:
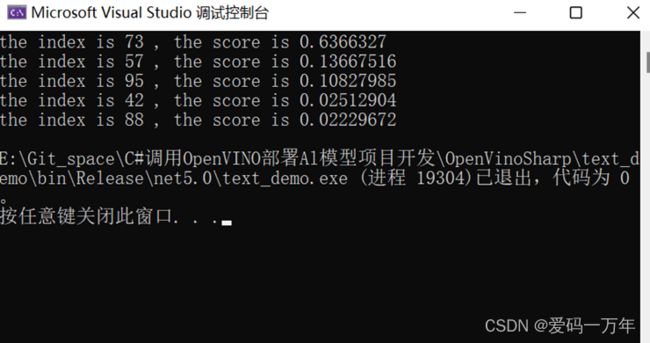
int[] index = find_array_max(result,5);
for (int i = 0; i < 5; i++){
Console.WriteLine("the index is {0} , the score is {1} ", index[i], result[index[i]]);
}
最终输出结果如图1- 17所示,该页面打印出来了推理结果预测分数最大的前五个分数和其对应的索引值,最后可以通过索引值查询flowers102_label_list.txt文件中对应的花卉名称。

6.5 编写代码测试车辆识别模型
对于车辆识别模型此处不再进行详细讲解,具体实现可以参考源码文件,此处只对一些不同点进行分析。
在配置输入时,除了需要配置图片数据输入,还需要配置图片长宽数据以及长宽缩放比例数据,在配置时,只需要将数据放置在数组中,通过调用load_input_data()方法实现,对于设置缩放比例数据输入,如下所示:
float scale_h = 608.00f / image.Height;
float scale_w = 608.00f / image.Width;
float[] scale_factor = new float[] { scale_h, scale_w };
ie.load_input_data(input_node_name[1], scale_factor);
对于该模型推理结果数据,总共有两个节点输出,一个是识别结果数量,一个为识别结果信息。对于识别结果数量,其数据类型为整形数据,对于单图片输入,只需要读取一位即可,利用该数据,确定识别结果信息长度。识别结果信息为6列N行数据,在数据读取时,我们将其转化为一维数据,所以在处理数据时,以6位数据为一组,进行处理。
识别结果信息数据中,第1位为识别标签,第2位为识别得分,第3位到第6位四个数据为位置矩形框对角点坐标,通过每6位读取一次数据,获取识别结果。在此处,我们提供了专门的结果处理方法,通过该方法们可以实现直接将结果绘制在原图片上:
image = draw_image_resule(image, resule_num[0], result, lable, 0.2f);
其中image为原图片,resule_num[0]为识别结果数量,result为识别结果数组,lable为结果标签,0.2f为评价得分下限。通过结果处理,将识别结果标注在图片中,并把识别结果以及得分情况打印在图片中,最终识别结果如图1- 18所示。