算法之美:排序
前言
前段时间,我的一位钟情.net的童鞋在编写一套“教务管理系统”的时候,遇到了一个问题。因为系统中包含学生的成绩排序,
而大学英语作为公共课有非常多人考试。这使得大学英语的成绩记录达到了二十多万行记录。排序起来非常耗时。整个系统还有
很多bug需要他处理,于是他就希望我能帮他解决这个问题。在写代码之前我先看了下.net的sort方法。msdn上写道“此方
法使用 QuickSort 算法。此实现执行不稳定排序;”。原来ms用的是快排!看来要想解决这个问题,一定不能用基于比较的
排序了。因为快排的平均时间复杂度已经达到了理论上限nlog(n)。通过分析待排数据,我发现这些数据有很多特点:
1.全部为整数(我们学校的考试成绩没有小数) 2.没有负数(成绩最低为0) 3.有范围(0 ~ 100)
想必排序学的不错的同学已经发现这些条件与计数排序对数据的要求一样了吧~。而计数排序的时间复杂度达到了惊人的
O(n),换言之,计数排序只需要扫描待排序列一次就可以完成排序了。用这种排序轻松的解决了童鞋的问题。
这个故事的寓意:
你要知道,算法真的很重要。按照需要选择适当的算法,这种能力是非常重要的,每个优秀的软件开发者都应该具备。并不需要
你能够对算法进行详细的数学分析,但是你必须能够理解这写分析。并不需要你发明新的算法,但是你要知道哪个算法可以解决
手头的问题。本文希望通过分析排序算法帮助你提高这种能力。当你具备这种能力后,你的软件开发工具箱中又多了一件软件开
发利器。
计数排序
想象一下,我们需要对一群孩子按照年龄的大小排序。已知孩子的年龄范围为1~20。我们在地上画20个圈代表1~20岁,让
孩子们选择符合自己年龄的圈站进去。当孩子站好后,排序就已经完成了。注意这个过程中并没有用两个孩子的年龄相互比较
。这种排序法就叫做计数排序。
算法分析
利用地址偏移来进行排序。排序字节串、宽字节串最快的排序算法。而且实现及其简单。
最好时间复杂度 O(n) 平均时间复杂度 O(n) 最坏时间复杂度 O(n) 稳定排序
优点
不需要比较函数。是对范围固定在[0,K)的整数排序的最佳选择。
缺点
需要一个size至少等于待排序数组取值范围的缓冲区。条件苛刻,不能用作通用算法。
算法实现
void countsort(int * arr, int n, int k)//排序arr中n个元素,范围是[0,K)
{
int i, idx = 0;
int *B = calloc(k, sizeof(int));
for(i = 0; i < n; i++)
B[arr[i]]++;
for(i = 0; i < k; i++)
while(B[i]-- > 0)
arr[idx++] = i;
free(B); }
计数排序在字节串排序中。表现也不错。
void countsort(BYTE *array, int length)
{
int t;
int i, z = 0;
BYTE min,max;
int *count;
min = max = array[0];
for(i=0; i<length; i++)
{
if(array[i] < min)
min = array[i];
else if(array[i] > max)
max = array[i];
}
count = (int*)malloc((max-min+1)*sizeof(int));
for(i=0; i<max-min+1; i++)
count[i] = 0;
for(i = 0; i < length; i++)
count[array[i]-min]++;
for(t = 0; t <= 255; t++)
for(i = 0; i < count[t-min]; i++)
array[z++] = (BYTE)t;
free(count);
}
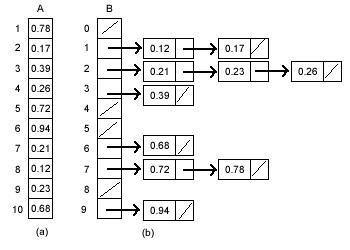
桶排序
给定n个元素的集合,桶排序构造了n个桶来切分输入集合因此同排序可以降低处理时额外空间的开销。
算法分析
想要使桶排序能够在最坏的情况下也能够以O(n)的时间复杂度进行排序,需要满足两个条件:
1.输入的数据要均匀的分布在一个给定的范围内。2.桶必须是有序的。
桶排序不适合排序随机字符串,但是在排序在区间[0,1)间的浮点数时,可以秒杀其他算法。
最好时间复杂度 O(n) 平均时间复杂度 O(n) 最坏时间复杂度 O(n) 稳定排序
优点
在[0,1)区间内排序浮点数的最佳算法。
缺点
需要额外的存储空间。
算法实现
//伪代码
const int nBuckets = (MAX / 10) + 1;
Bucket bucket [nBuckets];
for (i = 0; i < n; i++)
bucket [A[i] / 10].insert (A[i]);
for (i = 0; i < nBuckets; i++)
bucket [i].sort ();
for (i = 0; i < nBuckets; i++)
cout << bucket [i];
具体实现
#include <iostream.h>
class element
{
public:
int value;
element *next;
element()
{
value=NULL;
next=NULL;
}
};
class bucket
{
public:
element *firstElement;
bucket()
{
firstElement = NULL;
}
};
void main()
{
int lowend=0;
int highend=100;
int interval=10;
const int noBuckets=(highend-lowend)/interval;
bucket *buckets=new bucket[noBuckets];
bucket *temp;
for(int a=0;a<noBuckets;a++)
{
temp=new bucket;
buckets[a]=*temp;
}
int array[]={12,2,22,33,44,55,66,77,85,87,81,83,89,82,88,86,84,88,99};
for(int j=0;j<19;j++)
{
cout<<array[j]<<endl;
element *temp,*pre;
temp=buckets[array[j]/interval].firstElement;
if(temp==NULL)
{
temp=new element;
buckets[array[j]/interval].firstElement=temp;
temp->value=array[j];
}
else
{
pre=NULL;
while(temp!=NULL)
{
if(temp->value>array[j])
break;
pre=temp;
temp=temp->next;
}
if(temp->value>array[j])
{
if(pre==NULL)
{
element *firstNode;
firstNode=new element();
firstNode->value=array[j];
firstNode->next=temp;
buckets[array[j]/interval].firstElement=firstNode;
}
else
{
element *firstNode;
firstNode=new element();
firstNode->value=array[j];
firstNode->next=temp;
pre->next=firstNode;
}
}
else
{
temp=new element;
pre->next=temp;
temp->value=array[j];
}
}
}
for(int jk=0;jk<10;jk++)
{
element *temp;
temp= buckets[jk].firstElement;
while(temp!=NULL)
{
cout<<"*"<<temp->value<<endl;
temp=temp->next;
}
}
}
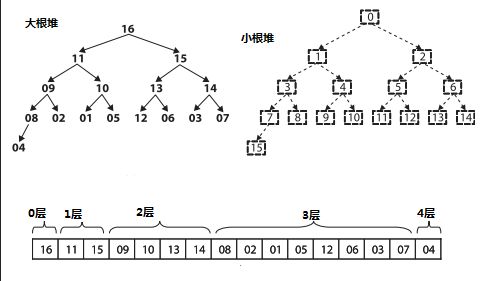
堆排序
在数组A中寻找最大的元素最少需要n-1次比较,但是我们希望能够最少化直接比较的元素。在一个比赛中,有64个队伍参加。
那么每次队伍之需要赢log(64) = 6次比赛就可以就可以拿到冠军的奖牌了。堆排序则说明了如何运用这种方法来排序元素。
算法分析
一个堆就是一颗二叉树。深度为k-1存在2^(k-1)个节点,节点是从左到右添加的。树中每个节点的值都大于或者等于任意
一个子节点的值。一个严格满足堆性质的结构,可以存储在数组中,而不损失任何数据。
最好时间复杂度 O(nlogn) 平均时间复杂度 O(nlogn) 最坏时间复杂度 O(nlogn) 非稳定排序
优点
可以快速的排序出前n大的数,求前n个大(小)数效率很高。
缺点
实现相对复杂
算法实现
#define MAX_HEAP_LEN 100
static int heap[MAX_HEAP_LEN];
static int heap_size = 0; // 堆的大小
static void swap(int* a, int* b)
{
int temp = 0;
temp = *b;
*b = *a;
*a = temp;
}
static void shift_up(int i)
{
int done = 0;
if( i == 0) return; //为根元素
while((i!=0)&&(!done))
{
if(heap[i] > heap[(i-1)/2])
{//如果当前值大于父亲节点,就交换
swap(&heap[i],&heap[(i-1)/2]);
}
else
{
done =1;
}
i = (i-1)/2;
}
}
static void shift_down(int i)
{
int done = 0;
if (2*i + 1> heap_size) return;
while((2*i+1 < heap_size)&&(!done))
{
i =2*i+1;
if ((i+1< heap_size) && (heap[i+1] > heap[i]))
{
i++;
}
if (heap[(i-1)/2] < heap[i])
{
swap(&heap[(i-1)/2], &heap[i]);
}
else
{
done = 1;
}
}
}
static void delete(int i)
{
int current = heap[i]; // 删除
int last = heap[heap_size - 1]; // 获取最后一个
heap_size--;
if (i == heap_size) return;
heap[i] = last; // 复制为最后一个元素,覆盖当前值
if(last >= current)
sift_up(i);
else
sift_down(i);
}
int delete_max()
{
int ret = heap[0];
delete(0);
return ret;
}
void insert(int new_data)
{
if(heap_size >= MAX_HEAP_LEN) return;
heap_size++;
heap[heap_size - 1] = new_data;
shift_up(heap_size - 1);
}
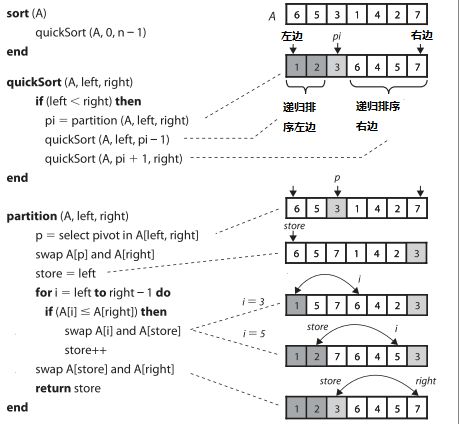
快速排序
在快速排序中,我们通过某些策略(有时随机,有时是最左边,有时是中间)来选择一个中间元素,这个元素将数组切分成两个
子数组。左边之数组的元素都小于或者等于中间元素,右边子数组的元素都大于或者等于中间爱你元素。然后每个子数组被递归
地排序。
算法分析
以平均性能来说,排序n个项目要O(nlogn)次比较。然而,在最坏的性能下,它需要O(n^2)次比较。一般来说,快速排序实际
上明显地比其他O(nlogn) 算法更快,因为它的内部循环可以在大部分的架构上很有效率地被实现出来。
最好时间复杂度 O(nlogn) 平均时间复杂度 O(nlogn) 最坏时间复杂度 O(n^2) 不稳定排序
优点
在平均情况下,快速排序确实名副其实,并且实现简单。
缺点
标准的递归快速排序,需要额外的空间。平均情况下需要O(logn)的字节空间,以及最坏情况下O(nlogn)的字节空间
算法实现
void swap(int *a, int *b)
{
int t=*a; *a=*b; *b=t;
}
void qsort(int arr[],int l,int r)
{
int i = l;
int j = r;
int key = arr[(i+j)/2];
while(i < j)
{
for(;(i < r)&&(arr[i] < key);i++);
for(;(j > l)&&(arr[j] > key);j--);
if (i <= j)
{
swap(&arr[i],&arr[j]);
i++;
j--;
}
}
if (i < r)
qsort(arr,i,r);
if (j > l)
qsort(arr,l,j);
}