Inpainting Transformer for Anomaly Detection阅读笔记
Inpainting Transformer for Anomaly Detection阅读笔记
Abstract
CV中的异常检测任务是识别偏离一系列正常图像的图像的任务。一种常见的方法是训练深度卷积自动编码器来修复图像的覆盖部分,并将输出与原始图像进行比较。通过仅在无异常样本上训练,假设模型不能正确重建异常区域。假设较远区域的信息是有益的,所以提出一种完全基于self-attention的方法来解决。提出修复变换器(InTra)用来修复大序列图像块中的损坏区域。在MVTec AD数据集上实现了SOTA结果。
1 Introduction
实际工业应用中,异常很少发生,缺乏足够的异常样本,并且异常有不确定的形状和问纹理,因此很难用监督方法来处理这个问题。无监督方法,试图模拟正常数据的分布。测试时,每个图像都有一个异常分数,衡量与正常样本的偏差,对于定位任务,类似的异常分数被分配到图像的patch或者单个像素。
常见方法:深度自编码器、生成模型(例如,VAE)和生成对抗网络(GAN),训练过程中,只对正常数据进行流行建模。通过使用输入图像和重建图像之间的差异来计算异常分数。基于的假设条件为:通过仅在正常图像上训练,模型将不能正确地重建异常图像,导致更高的异常分数。
缺点:卷积自编码器泛化能力强,异常部分也能够被很好的重构,从而导致假设失效。
最近提出通过输入部分图像,来作为图像修复问题来减轻这种影响[9, 10, 11, 12]。
[9]Detecting anomalous faces with ’no peeking’ autoencoders
[10] Anomaly detection using deep learning based image completion, (ICMLA), 2018
[11] Reconstruction by inpainting for visual anomaly detection
[12] Unsupervised region-based anomaly detection in brain MRI with adversarial image inpainting
缺点:只对部分邻域进行调节,小异常可以得到有效的覆盖,但有限的感受野,全卷积神经网络在建模数据时部分无效,所以对于较大异常区域覆盖时变得困难。
为了通过64个像素以外的信息影响一个像素,需要至少6层3×3卷积,其膨胀因子为2或等效物[13,14]。
一般的图像修复可以在模型中引入上下文注意力来解决。
异常检测中的修复,我们提出通过注意力结合来自已覆盖图像部分周围的大区域的信息来单独学习相关信息。
我们将异常检测作为一个patch-inpainting 问题,提出只使用Transformer来重建覆盖的patch。这种方法结合了更大的全局信息,不是简单的通过学习局部邻域信息来重建的,即使对于大面积异常区域,也可以有较高的异常分数。
主要贡献:
将异常检测建模为patch-sequence inpainting问题,使用由简单的多头自注意力模块组成的transformer网络来解决该问题。
建议一下两种方式来提高网络对于较困难数据的重建能力:1, 在transformer block中使用长残差连接。2, 计算self-attention时使用多层感知器对keys 和 queries进行降维。
通过加入位置embeddings,即使patch没有覆盖整个图像,也可以进行全局重建修复。
没有预训练,直接在MVTec数据集上进行训练,实现了SOTA的性能。模型参数55M。
2 Related Work
2.1 Anomaly Detection and Segmentation
异常检测,确定图像是否包含与预定义的标准不同的偏差;分割中,在像素级别上定位偏差。这两个任务中大致分为两种不同的方法:
Reconstruction based. 基于重建的模型只使用正常样本进行建模。
在训练期间将结构相似性指数度量(SSIM)集成到损失函数中这样的修改被用于通过产生更平滑的图像来提高重建质量
Embedding based
基于特征表示,可以使用正常样本的聚类或者最近邻算法。
2.2 Inpainting in Anomaly Detection
修复的目标是精确重建原始未覆盖的数据。
[11] Reconstruction by inpainting for visual anomaly detection 对于跨越大面积的异常现象仍然有问题,因为这些问题没有被充分掩盖掉。因此我们提出使用Transformer-based框架来提出按CNN,从而增加全局信息。
2.3 Transformers in Vision
ViT
3 Inpainting Transformer for Anomaly Detection
我们的方法是基于一个简单的Transformer blocks,它被用来训练基于相邻的patch修复 覆盖的图像patch。也是只在正常数据上训练,基于原始图像和通过修补所有补片获得的其重建的差异,为每个像素计算异常分数。
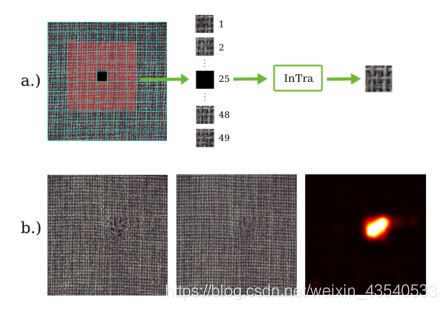
3.1 Embedding Patches and Positions
输入 X ∈ R H × W × C X\in R^{H\times W\times C} X∈RH×W×C, K K K为正方向patch的边长,然后 X X X被分割成 N × M N\times M N×M的扁平正方形网格
x p ( i , j ) ∈ R ( N × M ) × ( K 2 C ) x_p^{(i,j)}\in R^{(N\times M)\times(K^2C)} xp(i,j)∈R(N×M)×(K2C), i,j为第i行第j列中的patch。
我们的目标是在这个patch网格中选择一些边长为L的正方形子网格,并训练一个网络来基于子网格的其余patch重建子网格中的任何覆盖patch。
3.2 Multihead Feature Self-Attention
对于修复问题,可以使用MSA,在训练图像的patch非常相似到那不明显的情况下,q和k的点乘以及加权矩阵几乎一致,为了减轻这一点,我们提出在计算q和k的时候进行非线性降维,来替换原来(6)线性映射。
![]()
改进后,
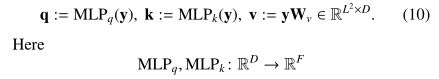
3.3 Network Architecture
网络模型由一个简单的n个transformer block组成。
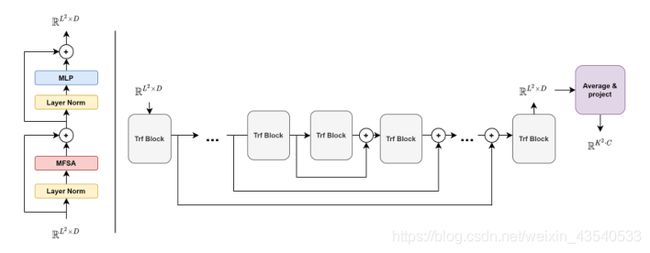
每个变压器模块的输入和输出是一个 R L 2 × D R^{L^2 \times D} RL2×D序列
为了获得修复后的patch,对最后一个transformer block的输出序列求平均,获得 R D R^D RD中的一个单个向量。最后通过一个可学习的放射变换被映射回展平的patches, R K 2 C R^{K^2 C} RK2C
同时加入二外的long residual connections,使整体重建的结构细节稍微多一点
3.4 Training
网络是通过从正常数据随机采样具有固定边长 L L L的成批的patch窗口来训练的。在每个窗口中选择一个随机的patch位置 ( t , u ) (t, u) (t,u),然后交给网络修复。
损失函数: L2损失, SSIM和GMS
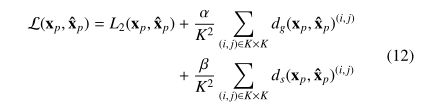
3.5 Inference and Anomaly Detection
推理过程分为两步:首先生成完整的修复图像,然后利用重建图像与原始图像的差异计算像素级异常图进行定位。异常图的最大像素值作为图像级检测的全局异常分数。
(没咋看懂)
4 Experiments
MVTec AD 数据集,标准的ROC AUC作为检测指标。
对于定位,使用像素级别的ROC AUC进行评估。数据集的每一个类都单独评估。
4.1 Implementation Details
从零开始对于每个类别的模型进行训练,采用相同的策略。从正常数据中随机选择10%(最多不超过20),并将它们用作控制重建质量的验证集。在每个时期,每个图像随机采样600个补丁窗口。为了扩大数据集,使用了随机旋转和翻转
Inpainting Transformer由13个blocks字组成,每个block由8特征注意力头组成。潜在维度设置为D=512, M L P q MLP_q MLPq和 M L P k MLP_k MLPk的输出维度为256,隐藏层的维度为1024。大约55M的可学习参数。
所有调整大小通过双线性插值来执行。
损失函数(12), α = β = 0.01 \alpha = \beta =0.01 α=β=0.01, Adam优化器,学习率为0.0001,batch size为256
Transformer网络的训练可能需要很长时间(在某些情况下超过500个epoch),这取决于所选择的分辨率、可用数据和重建难度。
4.2 Results and Discussion
与公开可用的最先进的结果比较,RIAD和我们一样的方法,也是基于修复重建的,并计算也是基于GMS的anomaly maps。
也与最近的方法进行了比较,如PaDiM和CutPaste。
我们注意到,PaDiM是基于使用额外训练数据的预处理神经网络,因此不能与我们的方法直接比较,但是提供了一个很好的参考,因为据我们所知,它是目前在检测和分割方面表现最好的模型。最近的工作CutPaste使用了一种特殊的数据扩充策略,以一种自我监督的方式训练一类分类器。CutPaste还提供了使用预训练表示法的结果,但是根据我们的训练程序,我们只关注结果,而没有额外的训练数据。还要注意的是,我们使用他们表现最好的单一模型进行公平的比较,而不是他们的整体。
结果:
异常检测(image level)
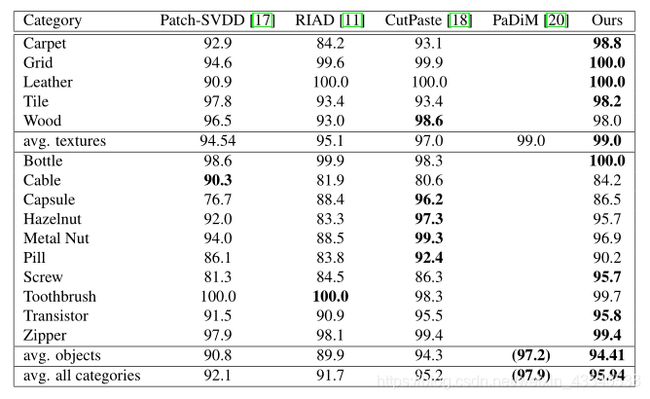
异常定位(pixel level)
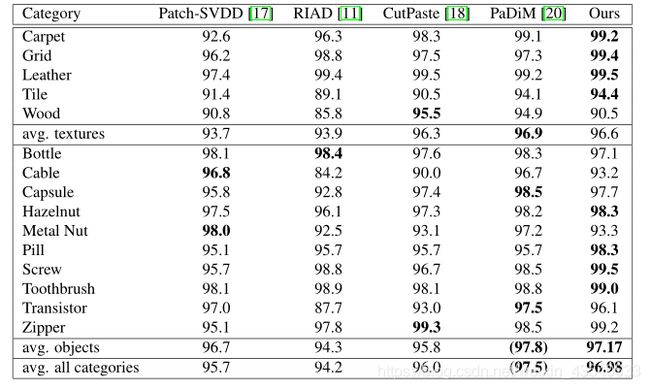
本文所提方法在结构化、对齐的数据(如牙刷、拉链和瓶子)上运行良好。
使用InTra,我们能够在MVTec AD基准上获得非常好的检测和定位性能,而无需额外的训练数据,同时在检测和分割方面超过了现有的方法。
4.3 Ablation Studies
4.3.1 Long residual connections
4.3.2 Feature Self-Attention
4.3.3 Patch Position Embedding
4.3.4 Patch Window Size
5 Conclusion
用于视觉异常检测的Transformer模型,该模型通过使用修复重建方法,输入patches,抛弃CNN,使用自注意力整合全局信息结合到重建中。