python大数据分析——属性规约
属性规约通过属性合并或者删除不相关的属性来减少数据维数,寻找出最小的属性子集并确保数据子集的概率分布尽可能地接近原来数据集的概率分布。
1.常用方法
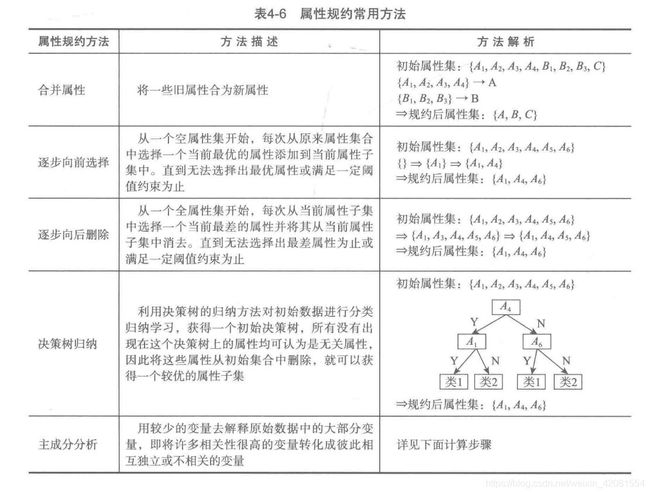
2.主成分分析:

3.代码实现
#-*- coding: utf-8 -*-
#主成分分析 降维
import pandas as pd
#参数初始化
inputfile = 'D:/Code/Need/principal_component.xls'
outputfile = 'D:/Code/Need/dimention_reducted.xls' #降维后的数据
data = pd.read_excel(inputfile, header = None) #读入数据
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(data)
pca.components_ #返回模型的各个特征向量
pca.explained_variance_ratio_ #返回各个成分各自的方差百分比
结果:
pca.components_
Out[2]:
array([[ 0.56788461, 0.2280431 , 0.23281436, 0.22427336, 0.3358618 ,
0.43679539, 0.03861081, 0.46466998],
[ 0.64801531, 0.24732373, -0.17085432, -0.2089819 , -0.36050922,
-0.55908747, 0.00186891, 0.05910423],
[-0.45139763, 0.23802089, -0.17685792, -0.11843804, -0.05173347,
-0.20091919, -0.00124421, 0.80699041],
[-0.19404741, 0.9021939 , -0.00730164, -0.01424541, 0.03106289,
0.12563004, 0.11152105, -0.3448924 ],
[-0.06133747, -0.03383817, 0.12652433, 0.64325682, -0.3896425 ,
-0.10681901, 0.63233277, 0.04720838],
[ 0.02579655, -0.06678747, 0.12816343, -0.57023937, -0.52642373,
0.52280144, 0.31167833, 0.0754221 ],
[-0.03800378, 0.09520111, 0.15593386, 0.34300352, -0.56640021,
0.18985251, -0.69902952, 0.04505823],
[-0.10147399, 0.03937889, 0.91023327, -0.18760016, 0.06193777,
-0.34598258, -0.02090066, 0.02137393]])
pca.explained_variance_ratio_
Out[3]:
array([7.74011263e-01, 1.56949443e-01, 4.27594216e-02, 2.40659228e-02,
1.50278048e-03, 4.10990447e-04, 2.07718405e-04, 9.24594471e-05])