传统机器学习模型如何做在线预测
摘要
虽然目前深度学习的热度远远高过传统的机器学习,但仍然有很多实际问题更适合用传统机器学习模型解决。如何将这些机器学习模型发布到生产环境做在线预测仍是一个很有意义的问题。常见的机器学习模型包括但不限于:
- 线性回归,Logistic 回归
- 决策树
- 随机森林
- SVM
- Boosting(AdaBoost,XGBoost)
- 隐式马尔可夫
本文我们用一个实际的例子介绍如何使用 ONNX 生态的解决方案将 scikit-learn 与 hmmlearn 训练的机器学习模型发布为高性能的在线预测服务。我们将逐步解决如下问题:
- 如何将 scikit-learn 训练的模型转换为 ONNX 模型
- 如何在 C++ 编写的服务中使用 ONNXRuntime 做模型预测
- 如何支持自定义模型的转换和预测
文中所引用的实际可运行的代码均在 onnx-ml-demo 代码仓库下,读者可将其 git clone 到本地以方便查阅。

在开始运行该仓库的代码前,请运行 pip install -r requirements.txt 安装必要的依赖。
背景
好车主互助 APP 有一个 “危险驾驶行为 AI 智能识别系统”。用户打开该功能后,APP 就会开始采集手机的 GPS 定位,陀螺仪,加速度计的读数等信息,并将这些数据上传到云端,运行在云端的危险行为识别服务会根据这些数据判断用户开车时做了哪些危险动作。撰写此文时,好车主互助可以识别急加速,急刹车,急转弯,超速等多种危险行为,目前我们也在开发新的算法来识别更多种类的危险驾驶行为,例如夜间行车,疲劳驾驶,开车时玩手机等行为。
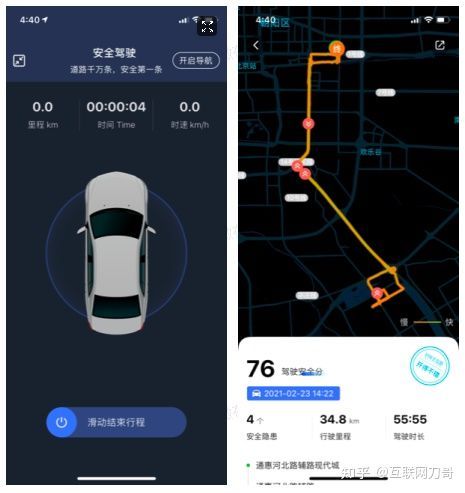
好车主互助 APP “危险驾驶行为 AI 智能识别系统” 功能截屏。左侧为行程采集界面,在该界面下 APP 会持续收集手机的传感器数据;右侧为滑动结束行程后的危险行为展示界面,图中展示的所有危险行为均由危险行为识别服务判定得出。
危险行为识别服务是一个用 C++ 编写的 gRPC 服务,里面实现了各种用于识别危险驾驶行为的算法,例如异常点过滤,滤波,平滑等。正在开发的开车玩手机行为识别采用了基于随机森林的分类和基于 HMM 的序列预测算法。在算法研发阶段我们用 scikit-learn 和 hmmlearn 完成了危险行为识别检测算法的调研和开发,算法的大致运行流程如下图所示:
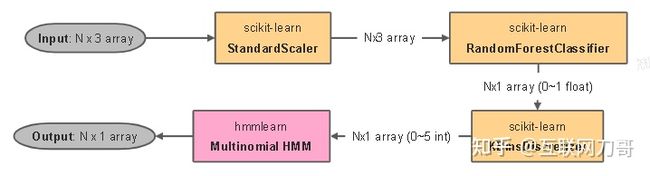
算法接受的输入是一个 N x 3 的 tensor,其中 N 为 APP 采集的传感器数据的个数,每个传感器数据包含 3 个算法关心的属性,例如加速度计的读数,陀螺仪的读数等。
- 使用 StandardScaler 对输入样本做标准化,使每一个样本 x[i, :] 的值都在 [0, 1] 区间内
- 用随机森林做 0-1 分类,得到 N 个 0-1 分类的类别 ID 以及类别的 probability
- 对 2 中得到的 propability 做离散化映射到 6 个整数(0 - 5),得到长度为 N 的整数序列
- 将 3 中得到的整数序列做 HMM 推断,得到 N 个 0 - 1 之间的整数,该步骤得到的就是对输入序列的标注:如果某个样本的最终推断值为 1,则认为用户在该样本对应的时间点在玩手机。
整个算法的训练和预测过程实现在 train/train.py 和 train/infer.py。我们事先准备了一些合成的训练数据 data/synthetic.pkl 来演示整个流程。
现在我们要把这个算法集成到危险行为识别服务中,可能的实现路径有:
- 把整个算法用 C++ 重新实现一遍
- 用 FastAPI/Flask/Tornado/etc. 将识别算法包装成一个子服务供危险行为识别服务调用
- 利用第三方 C++ 算法库实现 scikit-learn 和 hmmlearn 模型的预测
其中路径1工作量较大,将来如果要用新的机器学习算法替换旧算法(例如用 AdaBoost 替换 RandomForestClassifier)需要重新开发;路径2需要运维一个额外的 Python 服务,并且 RPC 的可用性和延迟都不可控,危险识别服务还需要考虑子服务不可用时的容错问题,这又引入了额外的复杂度。
路径3有多种实现方案,我们调研了 sklearn-porter,cPMML,ONNX 等多种方案。考虑到 ONNX 从成熟度,性能和可扩展性上都是比较好的选择,同时该方案可以兼容将来模型升级为基于深度学习的模型的情况,因此我们最终采用了基于 ONNX 的方案。
方法
什么是 ONNX
ONNX (Open Neural Network Exchange) 是一种用来表示深度学习模型的开放格式,自 2017 年推出以来逐渐被大多数主流机器学习框架支持。后来 ONNX 也在其规范中补充了对机器学习模型的支持 ONNX-ML,常用的机器学习包 scikit-learn 训练的大部分模型都可以通过 sklearn-onnx 转换为 ONNX 模型。ONNX 在其可交换的模型格式的基础上发展了一系列模型预测解决方案,可支持在 Intel/ARM CPU,CUDA 以及 Bitmain,OpenVINO 等边缘计算设备上使用 ONNX 模型运行深度学习预测。ONNXRuntime 就是其中一个支持多种平台的预测库,我们选用 ONNXRuntime 实现 x86_64 linux 服务器上的机器学习模型预测。
ONNX 模型
ONNX 模型就是一个计算图 (computation graph) 的描述。其实际的内部表示是一个 protobuf message,而 ONNX 模型文件就是将这个 protobuf message 序列化后直接存成的二进制文件。ONNX 的规范中包含了基本数据类型的定义,计算图的定义以及一些内建的算子的定义。开发自定义模型的 ONNX 转换器时可能需要查阅这部分规范。后面我们会简要介绍计算图的结构,以及如何查看 ONNX 模型的计算图。
训练模型
我们在代码库中附带了一组 Python 实现的模型训练和预测的代码,该代码中的预测流程和训练出的模型是我们今后讨论的基础。关于如何运行训练和预测脚本请参考 README.md 。models 目录下有我们提供的训练好的模型:
- scaler.pkl: scikit-learn 的 StandardScaler
- clf.pkl:scikit-learn 的 RandomForestClassifier 模型
- hmm.pkl:hmmlearn 的 MultinomialHMM 模型
下面我们讨论如何将这些模型转换为 ONNX 格式,以及如何在 ONNXRuntime 上运行预测。
Scikit-learn 模型的转换和预测
sklearn-onnx 模型转换
使用 sklearn-onnx 可以将 scikit-learn 训练的模型转换为 ONNX 模型。目前 sklearn-onnx 支持了 scikit-learn 的大部分模型,请参考 Supported scikit-learn Models 查看已支持的模型列表。转换已支持的模型只需要写几行代码。例如我们可以这样把 RandomForestClassifier 模型 clf.pkl 转换成 ONNX 格式:

- line 6 我们定义了 ONNX 模型输入的名称为 float_input,类型为 FloatTensorType(variable, 3)。我们限制了输入 tensor 的第二维的长度必须为 3,将来做模型预测时 ONNXRuntime 就可以直接拒绝类型和 shape 不合法的输入。
- line 7 调用了 convert_sklearn 完成了模型转换,onx 就是用来表示 ONNX 模型的 protobuf message 对象。
- line 8-9 将 ONNX 模型序列化并保存到文件 clf.onnx
使用 onnx 库可以加载 ONNX 模型,我们可以查看模型的 protobuf message 结构:

onnx 库提供了检查模型合法性的函数 onnx.checker.check_model,可以检查计算图模型结构中的一些问题,比如同一个名字在计算图中被定义多次,算子的输入类型不匹配,节点的顺序不符合拓扑序等。我们推荐在进行完 ONNX 模型构造或模型转换后运行一下 check_model 确保模型没有最基本的问题。
本小节的代码在 converter/convert_basic.py,运行 python converter/convert_basic.py models/clf.pkl models/clf.onnx 即可将 clf.pkl 转换为 clf.onnx。同理,StandardScaler 模型 scaler.pkl 也可以用该脚本转换为 ONNX 模型。
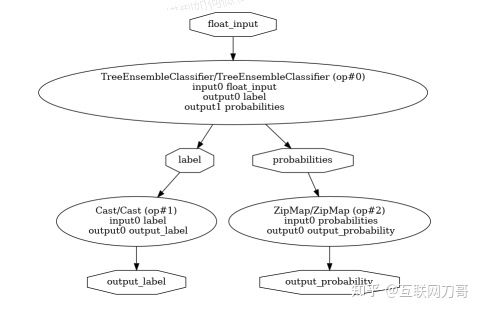
代码库中还包含了一个用于可视化 ONNX 模型的 converter/visualize.py,采用的方法取自 Display the ONNX Graph。RandomForestClassifier 的 ONNX 模型如下图所示:
也可以用 netron 查看 ONNX 的计算图结构,只需在页面上上传本地的 ONNX 模型文件即可。
我们注意到该模型有一个输入 float_input,经过 TreeEnsembleClassifier 后最终输出两个值:
- output_label:预测的类别 ID(0 或 1)。注意在输出节点之前有个 Cast,最终输出的是 Int32 类型的 tensor
- output_probability:每个类别的概率。该输出由 ZipMap 算子产生,其类型是 Sequence of Maps。后面讲到模型预测时会详细解释 output_probability 的结构。
ONNXRuntime 模型预测
ONNX Python 本身不带预测功能,运行预测需要额外的库。我们选择 ONNXRuntime 做模型预测。
Python
import onnxruntime as ort import numpy as np sess = ort.InferenceSession("clf.onnx") float_input = np.random.random((1000, 3)).astype(np.float32) res = sess.run(None, {"float_input": float_input})

- line 4 用模型文件 clf.onnx 创建了一个 ONNXRuntime session
- line 5 随机生成了一个 1000 x 3 的 float32 tensor 作为模型的输入
- line 6 调用 ONNXRuntime session 的 run 方法运行模型预测
预测的结果 res 是一个 list,里面包含模型的所有输出。我们知道 RandomForestClassifier 有两个输出:
- res[0] 为 output_label,是一个 1 x 1000 的 int64 array
- res[1] 为 output_probability,在 Python 中的类型是 list of dict。我们可以看一下 output_probability 的内容:

我们也可以只获取模型的某几个输出。调用 run 函数时显式指定要获取的输出的名称即可:

这样 res 即为长度为 1 的 list,里面唯一的元素即为 output_label 的值。
我们也提供了一个运行模型预测的 Python 脚本 converter/inference_basic.py,运行如下命令即可在随机生成的 5 x 3 的样本上运行预测,并且打印预测阶段的运行时长。后面我们会用该脚本比较 Python 和 C++ 的预测速度。

C++
我们已经在 Python 中尝试了用 ONNXRuntime 运行模型预测。由于在生产环境上要在一个 C++ 服务里运行模型预测,因此我们需要了解如何调用 ONNXRuntime 的 C++ API 运行预测。
准备环境
首先你需要安装 ONNXRuntime 的动态库和 headers。ONNXRuntime 的每一个版本发布时都会提供面向多种平台的预编译版本,用户可以在 https://github.com/microsoft/onnxruntime/releases 挑选合适的预编译版本。在撰写此文时 ONNXRuntime 的最新发布版本为 1.6.0,在 x86_64 linux 系统上执行如下命令即可完成安装:
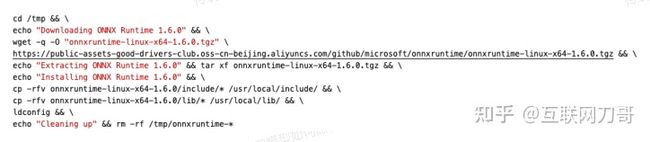
使用 ONNXRuntime C++ API
在撰写此文时 ONNXRuntime 还没有比较详细的 C++ API 文档,不过它的头文件写得比较清晰,我们可以查阅头文件 onnxruntime_cxx_api.h 中的类型定义,函数声明和注释学习如何使用 C++ API。此外官方也给出了一些示例,我们可以参考 CXX_Api_Sample.cpp 编写自己的模型预测代码。我们也提供了一份可以直接使用的源文件 cpp/infer_basic.cc。在 cpp 目录下运行 make 即可构建出可执行文件 infer_basic。运行 ./infer_basic /path/to/model.onnx N 即可在随机生成的样本上运行模型预测,其中 N 表示随机生成的输入为 N x 3 float tensor。
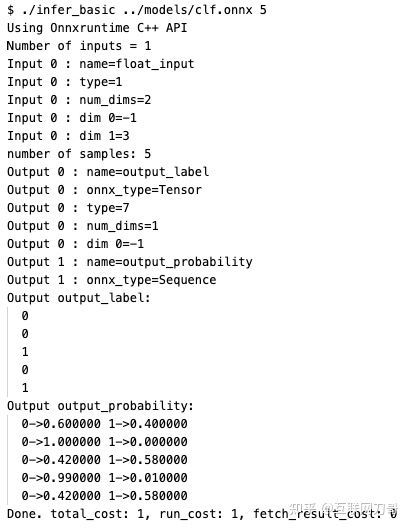
我们以随机森林模型的 ONNX 模型 clf.onnx 为例了运行 C++ 预测程序,模型的所有输出被打印到了 stdout。我们可以看到模型的两个输出 output_label 和 output_probability 的值。cpp/http://infer_basic.cc 的 line 189-252 实现了从 OrtValue 中提取不同类型的值。ONNX 中输入/输出值的类型有三种,详细介绍可以参考 Input/Output Data Types:
- Tensor:张量,可以认为类似于 numpy 的 ndarray。Tensor 中元素的标量类型有 float32, float64, int32, int64 等多种。例如前面的随机森林模型 clf.onnx 中的 float_input 和 output_label 就是 Tensor 类型的。
- Sequence[T]:序列类型,序列中元素的类型是相同的(homogeneous types)。比如 clf.onnx 的 output_probability 就是 Sequence[Map[...]] 类型的。
- Map[T0, T1]:映射类型。其中 T0 和 T1 是等长的 Tensor 类型。T0 为所有的 key,T1 为所有的值。T0 和 T1 中的元素有一一对应关系,形成 T0[k] -> T1[k] 的映射。我们在 Python 中使用 ONNXRuntime 预测得到的Map 已经被 Python 绑定层预处理成了 dict 类型。在 C++ 中我们得到的是两个 OrtTensor:T0 和 T1。
如果你想要在一个进程内创建多个 ONNXRuntime session(例如需要用多个模型运行预测),可以参考 C API 文档 中提到的方式令多个 session 共享内存池和线程池,或者参考我们给出的 cpp/infer_basic.cc 中 初始化 session 时指定的选项。
Sequence of Maps 的性能问题
我们尝试输入 100 万条数据到随机森林 ONNX 模型。由于结果集比较大,我们指定参数 q 不打印结果集:

可以看到总共耗时 4099 ms,预测阶段耗时 970 ms,读取输出数据耗时 3129。我们注意到大部分时间都花费在读取输出数据上。我们再运行一下 Python 的 ONNXRuntime 预测脚本对比一下耗时:
![]()
C++ 版本的速度相比 Python 版本慢了 3 倍。我们可以使用 perf 工具配合 FlameGraph 工具 查看下读取输出阶段的时间都花在什么地方,这里 有一份 svg 格式的 flamegraph 可供查看,点击图中的函数名可以查看其 sub callgraph。

我们发现 onnxruntime::ml::TreeEnsembleClassifier 占用了比较多的运行时间,这部分计算是在进行随机森林的预测。我们还注意到该函数不是在 main 里面执行的,这是因为 ONNXRuntime 中模型预测的计算是在独立的 worker 线程中进行的。main 里面耗时最多的函数是 Ort::Value::GetValue,里面的大部分时间都被 malloc 和 free 占用了(图中蓝色高亮的区域)。
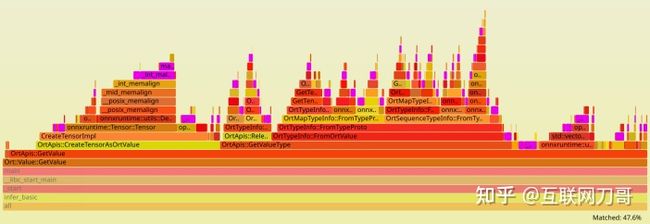
在读取 output_probability 时,我们遍历了一个长度为 100w 的 Sequence,对于 Sequence 的每个元素做了如下操作:
- 调用 GetValue 获取一个 Map (line 228)
- 对每个 Map 都调用两次 GetValue 获取 key 和 value (line 229-230)
整个过程合计进行了 300w 次 GetValue 操作,该操作所伴随的堆空间分配/去配占用了大部分运行时间。该问题可能是由于 C++ API 包装层实现性能不佳导致的。我们可以通过调整 ONNX 模型的结构避免这个问题。我们知道 output_probability 是 ZipMap 的输出,ZipMap 算子的作用是将一个 Tensor 变换为一个 Sequence of Maps。如果不进行这个 ZipMap 操作,直接拿到整个 Tensor 再自行处理性能可能会好很多。sklearn-onnx 提供了配置项让我们得到不带 ZipMap 的模型,具体做法可以参考 Probabilities as a Vector or as a ZipMap。我们在 converter/convert_basic.py 中也添加了这一选项,执行 convert_basic.py 时添加一个额外参数 no_zipmap 再次转换模型:
![]()
得到的 ONNX 模型的计算图如下所示,可以看到这次得到的模型的输出为 label 和 probabilities,没有 ZipMap 算子。

再用刚刚转换的模型重新运行一次预测,可发现读取输出阶段的耗时明显减少,只占预测总耗时的 1%。

自定义模型的转换和预测
下面我们将 hmm.pkl 模型转换为 ONNX 模型。首先尝试复用我们上一节用到的 conveter/convert_basic.py:
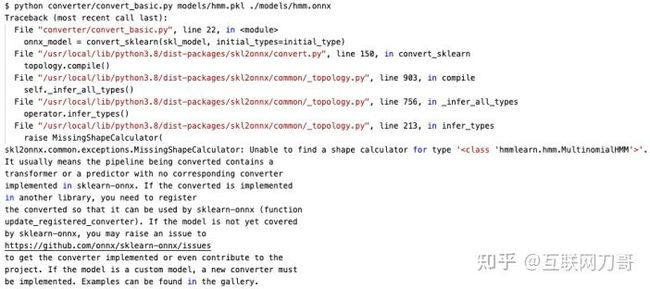
转换失败了。这是因为 sklearn-onnx 不支持 hmmlearn 模型 hmmlearn.hmm.MultinomialHMM 的转换。
撰写此文时还没有类似 hmmlearn-onnx 的项目可以直接使用,因此我们需要为 HMM 模型编写自定义的转换器。
Multinomial HMM 的预测过程
将模型转换为 ONNX 格式的过程就是把模型预测过程表示成 ONNX 计算图的过程。我们首先了解一下 Multinomial HMM 的预测过程是怎样的,下面我们以 hmmlearn 0.2.4 版本为例了解 hmmlearn 是如何实现 Multinomial HMM 预测的。
hmmlearn 中涉及 Multinomial HMM 预测的代码在 hmmlearn/base.py。我们使用的预测算法是默认的 Viterbi 算法,调用 hmm.predict 时运行的是 _BaseHMM._decode_viterbi ,里面调用了使用 Cython 编写的 Viterbi 算法的实现:lib/hmmlearn/_hmmc.pyx。我们把模型预测的这部分代码从整个 hmmlearn 框架中剥离出来,可以看到需要转换成 ONNX 模型的就是如下这 40 多行代码:

完整的代码在 converter/viterbi.py,我们可以简单地验证一下这个最小预测代码和 hmmlearn 的预测结果的等价性:

下面我们分析整个预测过程如何用 ONNX 计算图表达。
- line 34-36 对 HMM 模型的参数做了一些预计算,我们可以直接把预计算之后的值写入 ONNX 模型。
- line 29 定义的预测入口函数有四个参数,其中 log_emissionprob, log_startprob, log_transmat 都是模型的参数,X 是模型的输入。
- line 30 的 framelogprob 是以 X 为下标从 log_emisssionprob 中取了一个 slice,该操作可以用 ONNX 内建的 Gather 算子实现。
- line 32 调用的 _viterbi 函数中是一个 DP 的计算过程,用 ONNX 已有的算子的组合很难表达。我们决定自定义一个 Viterbi 算子实现这部分计算。
我们可以画一个图描述该算法对应的 ONNX 模型的形态,接下来我们开始按照这个图实现模型转换器。

直接使用 Python API 构建 ONNX 模型
这种方法相当于用很薄的封装层直接构造一个表示模型的 protobuf message,ONNX 的 Python API 文档中给出了一个利用 onnx.helper 构造模型的 示例。构造一个 Multinomial HMM 模型的完整代码见 converter/convert_hmm_naive.py。运行如下命令可以将 hmmlearn 模型转换为 ONNX 模型:
![]()
转换完成的 ONNX 模型结构如下,和我们前面绘制的图基本一致:
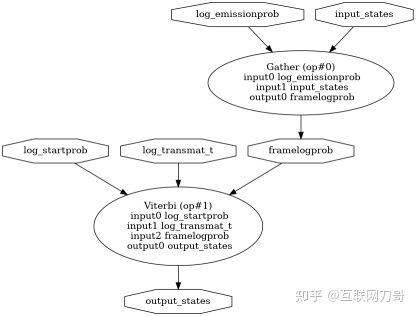
sklearn-onnx custom converter
除了直接用 Python API 之外,另一种更推荐的做法是把模型转换功能实现成 sklearn-onnx 的自定义转换器。这种方式的好处是我们可以把其他预测步骤和 HMM 预测串联起来,转换成一个大的多步骤的 ONNX 模型。
Multinomial HMM 模型的转换器代码见 converter/convert_hmm_skl2onnx.py,我们实现该转换器时主要参考了 sklearn-onnx Gallery 中的 这个 示例。运行如下命令可以将 hmmlearn 模型转换为 ONNX 模型:
![]()
ONNXRuntime custom operator
我们已经完成了 Multinomial HMM 模型的 ONNX 转换,但是该模型还无法直接用 ONNXRuntime 预测,因为ONNXRuntime 无法识别模型中新增的 Viberbi 算子。下面我们将 Viterbi 算子实现为 ONNXRuntime 的自定义算子(Custom Operator),从而支持 HMM 模型的预测。
我们把 Viterbi 算子实现在了 cpp/viterbi.cc 里,其主要逻辑和 Python 版本的 _viterbi 函数一致。在 cpp/infer_basic.cc line 77 我们将自定义的 Viterbi 算子注册到了 session 中,这样 ONNXRuntime 就可以在计算模型中的 Viterbi 算子时调起我们提供自定义算子。

我们将该算子编译为一个单独的 .so,接下来就可以在 Python 中加载这个 .so 运行 HMM 模型预测。在 Python 中使用自定义算子的代码见 converter/inference_hmm.py:

将整个 Pipeline 转换为 ONNX 模型
前面我们已经将两个 scikit-learn 模型和一个 HMM 模型转换成了 ONNX 模型,使用 ONNXRuntime 运行整个算法就比较简单了。我们可以编写一些 “胶水代码” 把这三个模型的预测过程串联起来。一种更优的方式是将整个算法流程都用 ONNX 的计算图表达,形成一个大的 ONNX 模型。这样做的好处有:
- 由于算法的逻辑都在 ONNX 模型中,我们可以写更少的 C++ 代码完成算法的集成。
- 算法变更后只需要更新 ONNX 模型的 converter,不需要变更 C++ 代码(前提是变更后的算法也可以用 ONNX 计算图表示出来)。
我们可以参考 sklearn-onnx Gallery 中的 这个 示例把整个预测流程串起来,完整的代码在 converter/convert_pipeline.py。执行如下命令即可将 StandardScaler, RamdomForestClassifier, MultinomialHMM 三个模型融合为一个 ONNX 模型:
![]()
最后我们用随机生成的样本尝试一下预测。我们无需修改 C++ 代码,只需替换模型路径即可运行完整的算法。

最终的 ONNX 模型的计算图如下所示。
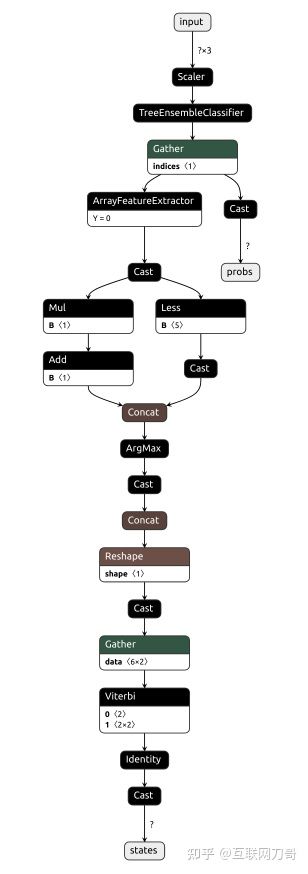
性能对比
ONNXRuntime 的模型预测性能是非常优异的。下面我们测试一下 ONNX 方案的性能以及相比原始预测代码的提速程度。如下测试结果均在 Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz * 4 CPU 的云服务器上得出。
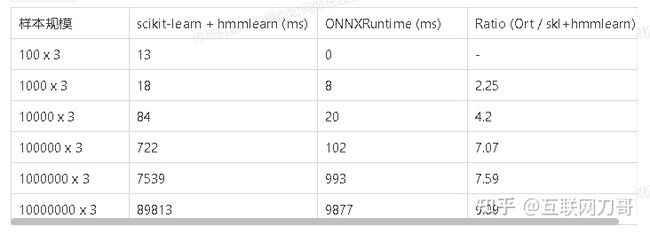
我们分别用 scikit-learn + hmmlearn 和 ONNXRuntime 在不同长度的样本上运行预测,测量运行的耗时。结果如下表。在一次性输入大量样本的情况下 ONNXRuntime 速度快 6 倍以上。
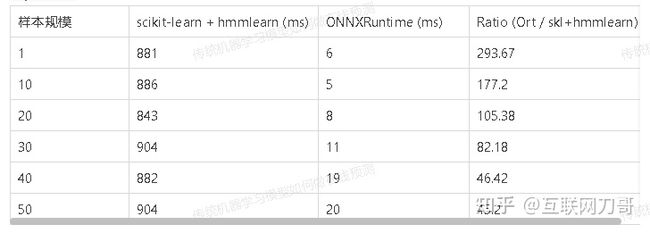
下面我们测试多次预测少量样本的情况。我们针对每个样本规模的样本运行 100 次预测,测量运行的总耗时。结果如下表。在输入少量样本的情况下 ONNXRuntime 的延迟要远低于 scikit-learn + hmmlearn 的延迟。
总结
我们使用 sklearn-onnx 完成了多步骤的机器学习模型到 ONNX 模型的转化,并使用 ONNXRuntime 实现了 ONNX 模型在 C++ 服务上的在线预测。我们给出了整个研发过程中的关键代码,希望本文能解决读者在部署机器学习模型的过程中遇到的问题。
参考资料
- ONNX: http://onnx.ai/
- ONNX Github: https://github.com/onnx/onnx
- ONNX Runtime C API: https://www.onnxruntime.ai/docs/reference/api/c-api.html
- ONNX Runtime Github: https://github.com/microsoft/onnxruntime
- sklearn-onnx: http://onnx.ai/sklearn-onnx/index.html
- hmmlearn: https://hmmlearn.readthedocs.io/en/latest/
- sklearn-porter: https://github.com/nok/sklearn-porter
- cPMML: https://amadeusitgroup.github.io/cPMML/
- flamegraph: https://github.com/brendangregg/FlameGraph