李宏毅--机器学习作业--1-Linear Regression:预测PM2.5
1-Linear Regression:预测PM2.5
1.作业目的
2.数据集描述
3.作业描述
4.完整代码
5.测试Python
6.运行源码
7.安装库语句
8.SYS安装教程
9.解决Non-UTF-8问题
注意:这篇博客的任何操作是在已经下载好Python的前提下,如果还没有下载Python,可以参考以下链接下载Python
https://blog.csdn.net/qq_39346534/article/details/106954662
1.作业目的:
根据前9个小时采集的台湾环境监测所得的数据,用线性回归预测第10个小时的PM2.5的数值
2. 数据集描述:
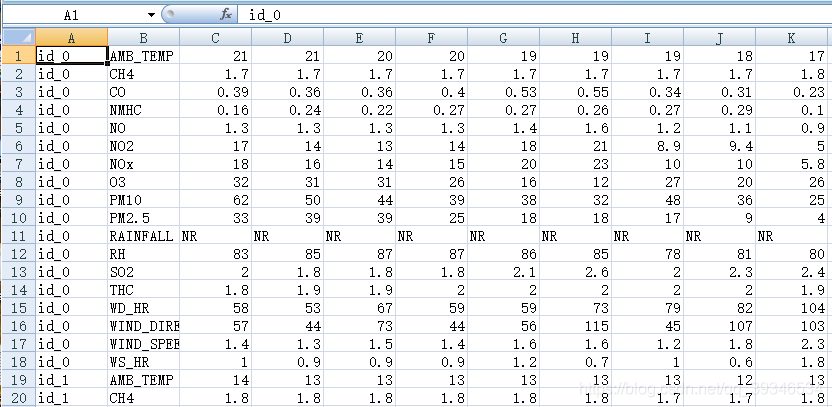
将数据分为train.csv和test.csv,其中train.csv是检测站每个月前20天的所有数据,而test.csv是从检测站剩余数据中取样出的部分数据。
train.csv如图所示:

test.csv如图所示:
3. 作业描述:
输入:前9个小时采集的台湾环境监测所得的数据,
输出:第10个小时的PM2.5的数值
工具:用线性回归预测
4. 完整代码:
.
这部分源码转载自
https://blog.csdn.net/iteapoy/article/details/105431738
# 导入相关库
import sys
import pandas as pd
import numpy as np
# 读入数据
data = pd.read_csv('./train.csv', encoding = 'big5')
# 数据预处理
data = data.iloc[:, 3:]
data[data == 'NR'] = 0
raw_data = data.to_numpy()
# 按月分割数据
month_data = {}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24 : (day + 1) * 24] = raw_data[18 * (20 * month + day) : 18 * (20 * month + day + 1), :]
month_data[month] = sample
# 分割x和y
x = np.empty([12 * 471, 18 * 9], dtype = float)
y = np.empty([12 * 471, 1], dtype = float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14:
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:,day * 24 + hour : day * 24 + hour + 9].reshape(1, -1) #vector dim:18*9 (9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] #value
print(x)
print(y)
# 对x标准化
mean_x = np.mean(x, axis = 0) #18 * 9
std_x = np.std(x, axis = 0) #18 * 9
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
# 训练模型并保存权重
dim = 18 * 9 + 1
w = np.zeros([dim, 1])
x2 = np.concatenate((np.ones([12 * 471, 1]), x), axis = 1).astype(float)
learning_rate = 2
iter_time = 10000
adagrad = np.zeros([dim, 1])
eps = 1e-7
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power(np.dot(x2, w) - y, 2))/471/12)#rmse
if(t%100==0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x2.transpose(), np.dot(x2, w) - y) #dim*1
adagrad += gradient ** 2
w = w - learning_rate * gradient / (np.sqrt(adagrad) + eps)
np.save('weight.npy', w)
# 导入测试数据test.csv
testdata = pd.read_csv('./test.csv', header = None, encoding = 'big5')
test_data = testdata.iloc[:, 2:]
test_data[test_data == 'NR'] = 0
test_data = test_data.to_numpy()
test_x = np.empty([240, 18*9], dtype = float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
# 对test的x进行预测,得到预测值ans_y
w = np.load('weight.npy')
ans_y = np.dot(test_x, w)
# 加一个预处理<0的都变成0
for i in range(240):
if(ans_y[i][0]<0):
ans_y[i][0]=0
else:
ans_y[i][0]=np.round(ans_y[i][0])
# 保存为csv文件,并提交到kaggle:https://www.kaggle.com/c/ml2020spring-hw1/submissions
import csv
with open('submit.csv', mode='w', newline='') as submit_file:
csv_writer = csv.writer(submit_file)
header = ['id', 'value']
print(header)
csv_writer.writerow(header)
for i in range(240):
row = ['id_' + str(i), ans_y[i][0]]
csv_writer.writerow(row)
print(row)
将源码复制在记事本上,并将文件的命名后缀为.py如图所示:

5. 测试python
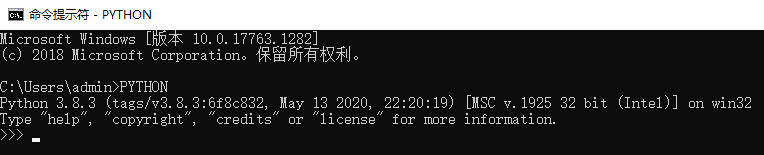
第一步:在电脑开始中搜索cmd,打开命令提示符,输入PYTHON,测试下载的Python是否可用,如图所示:
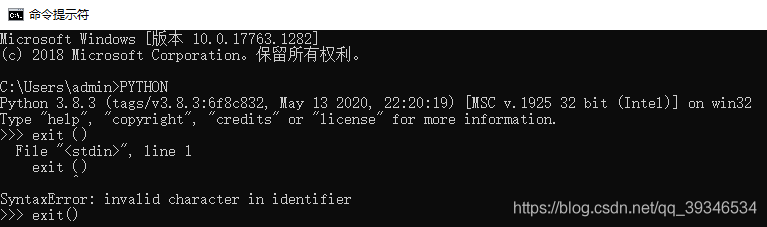
第二步:输入exit()退出,如图所示:
注意:输入的时候,符号是英文的,不然系统会认为是无效的
6. 运行源码:
第一步:利用cd命令符找到源码文件,如图所示:

第二步:输入python hw1.py运行源码,这里会出现各种问题,比如:没有安装各种库,SyntaxError等等,根据提示一个一个的解决。如图所示:
![]()
7.安装库语句:
安装库语句:pip install +库的名字
比如安装sys库:输入:pip install sys
8.SYS安装:
如果显示:
ERROR: Could not find a version that satisfies the requirement sys (from versions: none)
ERROR: No matching distribution found for sys
根据SYS安装教程,如下:
SYS安装教程
9. 解决Non-UTF-8问题:
如果显示如下错误:
File "hw1.py", line 1
SyntaxError: Non-UTF-8 code starting with '\xb5' in file hw1.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
可根据如下链接解决
https://editor.csdn.net/md/?not_checkout=1
再次运行源码,可得到预测值,如下:
