Python的数据结构、函数、文件
参考: 利用Python进行数据分析 Github
文章目录
- 数据结构和序列
-
- 元组
- 列表
- 序列函数
-
- enumerate
- sorted
- zipped
- reversed
- 字典
- 集合
- 列表、集合、字典推导式
- 函数
-
- 匿名函数
- 柯里化
- 生成器
- itertools模块
- 错误处理
- 文件和操作系统
-
- 文件读写
- StringIO
- 操作文件
数据结构和序列
元组
- 创建元组
t1 = 5,6,7
t2 = (5,6,7),(8,9)
t3 = tuple('Fuck you')
t4 = (1,[1,2])
#(5, 6, 7)
#((5, 6, 7), (8, 9))
#('F', 'u', 'c', 'k', ' ', 'y', 'o', 'u')
#(1,[1,2])
- 元组不可以修改,但元组中的列表部分是可以修改的
t4[1].append(233) #元组里的list可修改
#(1, [1, 2, 233])
- 串接和元组赋值
t5 = (1,2,3)+(4,5)
a,b,c,d,e = t5
#(1, 2, 3, 4, 5)
#1 2 3 4 5
*方法拆分元祖
a,b,*rest = 1,2,3,4,5
print(a,b,rest)
#1 2 [3, 4, 5]
count方法计数
列表
append()末尾添加元素insert(pos,val)插入元素pop(pos=end-1)删除指定位置元素remove(val)删除第一个相关值in和not in判断是否有元素extend(val)拼接.sort() 方法排序bisect 模块
bisect.bisect可以找到插入值后仍保证排序的位置,
bisect.insort是向这个位置插入值
import bisect
c = [1,2,2,3,4,7]
print(bisect.bisect(c,2)) # bisect.bisect找到插入后仍保证排序的位置,如插入2到pos 3 ,保证排序
print(bisect.bisect(c,5))
bisect.insort(c,5)
print(c)
#3
#5
#[1, 2, 2, 3, 4, 5, 7]
序列函数
enumerate
haha = ['fuck','me','baby']
gaga ={}
for i, value in enumerate(haha):
gaga[value] = i
print(gaga)
# {'fuck': 0, 'me': 1, 'baby': 2}
sorted
形成排序好的列表的副本
zipped
将多个序列形成一个元组列表,*zip解元组列表
s1 = ['foo','zoo','baz']
s2 = ['one','two','three']
zipped = list(zip(s1,s2))
print(zipped)
first,second = zip(*zipped)
print(first)
print(second)
#[('foo', 'one'), ('zoo', 'two'), ('baz', 'three')]
#('foo', 'zoo', 'baz')
#('one', 'two', 'three')
最常见用法
for i,(a,b) in enumerate(zip(s1,s2)):
print('{0}:{1} {2}'.format(i,a,b))
# 0:foo one
# 1:zoo two
# 2:baz three
reversed
字典
- 用序列函数创建字典
mapping = {}
for key, value in zip(range(5),reversed(range(5))):
mapping[key] = value
print(mapping)
mapping = dict(zip(range(5), reversed(range(5))))
# {0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
- 默认值
value = mapping.get(7,'no') #如果没有相关key,返回no
value2 = mapping.get(2,'no')
print(value)
print(value2)
# no
# 2
setdefault分类创建列表
words = ['apple','bat','atom','book','bar']
by_letter = {}
for word in words:
letter = word[0]
by_letter.setdefault(letter,[]).append(word) #如果letter不在by_letter,创建列表,然后添加值。
print(by_letter)
# {'a': ['apple', 'atom'], 'b': ['bat', 'book', 'bar']}
collections库 defaultdict
上面的化简版
from collections import defaultdict
by_letter = defaultdict(list)
for word in words:
by_letter[word[0]].append(word)
print(dict(by_letter))
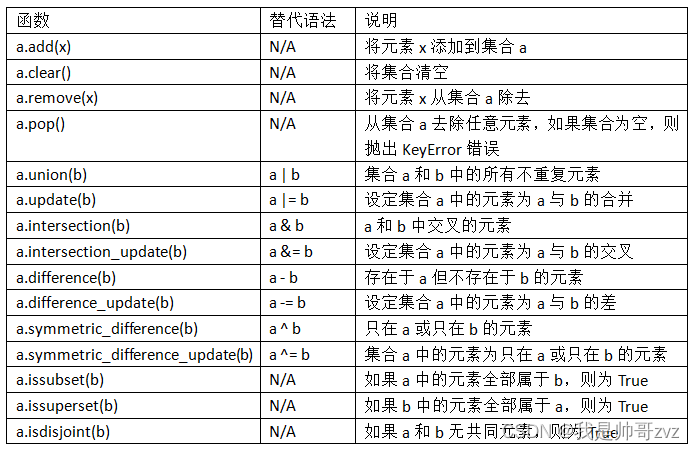
集合
set()- 集合没有重复,排序
a.union(b)a并ba|ba并ba.intersection(b)a交ba&ba交b- 常见函数
列表、集合、字典推导式
- 列表推导式
[expr for val in collection if condition] - 字典推导式
dict_comp = {key-expr : value-expr for value in collection if condition} - 集合推导式
set_comp = {expr for value in collection if condition}
words = ['a','b','cat','doggy','pig']
up = [word.upper() for word in words if len(word)>2]
print(up)
# ['CAT', 'DOGGY', 'PIG']
- 列表嵌套推导式
all_names = [['Jeff','Apple','Steven'],['Jack','Banana','Yellow']]
result = [name for names in all_names for name in names if name.count('e')>=2] #首先for names in all_names, 再 for name in names
print(result)
# ['Steven']
- 扁平化
flattened = [x for names in all_names for x in names]
print(flattened)
# ['Jeff', 'Apple', 'Steven', 'Jack', 'Banana', 'Yellow']
函数
匿名函数
lambda 函数
柯里化
从现有函数派生出新函数的技术
def add_number(x,y):
return x+y
add_five = lambda x : add_number(x,5)
print(add_five(4))
# 9
生成器
一般的函数执行之后只会返回单个值,而生成器则是以延迟的方式返回一个值序列,即每返回一个值之后暂停,直到下一个值被请求时再继续。要创建一个生成器,只需将函数中的return替换为yeild即可
def squares(n = 10):
print('generating squares from 1 to {}: '.format(n**2))
for i in range(1,n+1):
yield i**2
gen = squares()
#gen #直接调用会生成这个,因为没有调用元素 - 生成器推导式:把列表推导式两端的方括号改成圆括号
gen = (x**2 for x in range(1,11))
for x in gen:
print(x,end=' ')
itertools模块
import itertools
first_letter = lambda x: x[0]
names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven']
for letter, names in itertools.groupby(names, first_letter):
print(letter, list(names)) # names is a generator
#A ['Alan', 'Adam']
#W ['Wes', 'Will']
#A ['Albert']
#S ['Steven']

错误处理
- try-except-else-finally
try尝试处理的代码
except可能报错
else 是在try正确之后执行
finally 无论如何都会执行
文件和操作系统
文件读写
- 打开模式

- 常见方法

StringIO
内存中读写
from io import StringIO
f = StringIO()
f.write('hello')
f.write(' ')
f.write('Jeff')
print(f.getvalue())
g = StringIO('Hello\nI am Jeff\nHi')
while True:
s = g.readline()
if s == '':
break
print(s.strip())
#hello Jeff
#Hello
#I am Jeff
#Hi
操作文件
import osos.name操作系统类型os.environ环境变量os.path.abspath('.')查看当前目录绝对路径os.path.join('/Users/michael', 'testdir')拼接目录os.mkdir('/Users/michael/testdir')生成目录os.rmdir('/Users/michael/testdir')删除目录os.path.split('/Users/michael/testdir/file.txt')拆开最后级别目录os.path.splitext('/path/to/file.txt')拆开后缀os.rename('test.txt', 'test.py')重命名os.remove('test.py')删除文件- 筛选当前目录下所有目录或py文件
[x for x in os.listdir('.') if os.path.isdir(x)]
[x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']