机器学习:心血管疾病数据分析
2019-5-22
python3.6
所有包为5月15日之前的最新包
Pandas,seaborn 的一些图表操作
数据集特征
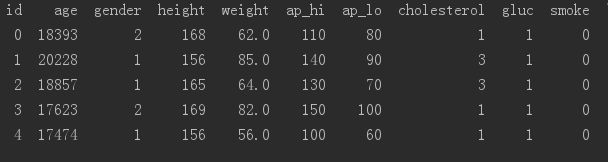

大概有8W条数据左右。
对表的操作以及解决的问题都在代码中进行了注释
主要的操作有,筛选数据,频率,百分比,平均数,中位数,数据清除,皮尔逊相关性系数矩阵,小提琴图,直方统计分布图等
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.ticker
from matplotlib import rcParams
import warnings
warnings.filterwarnings('ignore')
pd.set_option('expand_frame_repr', True) # true表示可以换行显示
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
pd.set_option('max_colwidth', 100)
sns.set()
sns.set_context(
"notebook",
font_scale=1.5,
rc={
"figure.figsize": (11, 8),
"axes.titlesize": 18
}
)
rcParams['figure.figsize'] = 11, 8
# https://labfile.oss.aliyuncs.com/courses/1283/telecom_churn.cs
df = pd.read_csv(
'D:/pycharm_pro/imageinfo/CVD_analysis/mlbootcamp5_train.csv', sep=';')
print(df.head())
# 数据集中有多少男性和女性?由于 gender 特征没有说明男女,你需要通过分析身高计算得出。
dup = df.groupby('gender').size()
bodyhigh = df.groupby('gender')['height'].mean()
# print(bodyhigh)
# print(dup)
# 数据集中男性和女性,哪个群体饮酒的频次更高?
rate = df.groupby('gender')['alco'].mean()
# print(rate)
# 数据集中男性和女性吸烟者所占百分比的差值是多少?
# loc函数:通过行索引 "Index" 中的具体值来取行数据(如取"Index"为"A"的行)
scale1 = df.groupby('gender')['smoke'].mean()
result = abs(100 * (round(scale1[1] - scale1[2], 2)))
# print(result)
# 数据集中吸烟者和非吸烟者的年龄中位数之间的差值(以月计)近似是多少?你需要尝试确定出数据集中 age 合理的表示单位。
# DataFrame.median(axis = None,skipna = None,level = None,numeric_only = None,** kwargs )[source]
# 返回请求轴的值的中值。
smoke_med = df.groupby('smoke')['age'].median()
diff_value = abs((smoke_med[0] - smoke_med[1]) / 365.25 * 12)
# print(diff_value)
# 计算 [60, 65)[60,65) 年龄区间下,较健康人群(胆固醇类别 1,收缩压低于 120)与高风险人群(胆固醇类别为 3,
# 收缩压 [160, 180)[160,180))各自心血管病患所占比例。并最终求得二者比例的近似倍数
age60 = 365.25 * 60
age65 = 365.25 * 65
lowerpress = df[(df['age'] >= age60) & (df['age'] <= age65) & (df['cholesterol'] == 1) & (df['ap_hi'] <= 120)]['cardio'].mean()
# print(lowerpress.size)
highpress = df[(df['age'] >= age60) & (df['age'] <= age65) & (df['cholesterol'] == 3) & (df['ap_hi'] <= 180) & (df['ap_hi'] >= 160)]['cardio'].mean()
# print(lowerpress)
# print(highpress)
# BMI 指数一般在 18.5 到 25 之间。BIM = 体重/身高的平方,判断线面是否正确
# [ A ] 数据集样本中 BMI 中位数在正常范围内。
# [ B ] 女性的平均 BMI 指数高于男性。
# [ C ] 健康人群的 BMI 平均高于患病人群。
# [ D ] 健康和不饮酒男性中,BMI 比健康不饮酒女性更接近正常值。
df['BMI'] = df['weight'] / ((df['height'] / 100) **2)
# print(df['IBM'].median())
gender_bmi = df.groupby('gender')['BMI'].mean()
# print(gender_bmi)
health_bmi = df.groupby(['gender', 'cardio'])['BMI'].mean()
# print(health_bmi)
# 问题:请按照以下列举的项目,过滤掉数据中统计有误的部分:
#
# 血压特征中,舒张压高于收缩压的样本。
# 身高特征中,低于 2.5% 分位数的样本。
# 身高特征中,高于 97.5% 分位数的样本。
# 体重特征中,低于 2.5% 分位数的样本。
# 体重特征中,高于 97.5% 分位数的样本。
# 清洗掉的数据占原数据总量的近似百分比?
filtered_df = df[(df['ap_lo'] <= df['ap_hi']) &
(df['height'] >= df['height'].quantile(0.025)) &
(df['height'] <= df['height'].quantile(0.975)) &
(df['weight'] >= df['weight'].quantile(0.025)) &
(df['weight'] <= df['weight'].quantile(0.975))]
1 - filtered_df.shape[0] / df.shape[0]
# print(filtered_df.head())
# 要更好地理解数据集特征,接下来使用过滤之后的数据创建特征之间相关系数的矩阵。
# 问题:使用 heatmap() 绘制特征之间的皮尔逊相关性系数矩阵。
# 问题:以下哪组特征与性别的相关性更强?
# [ A ] Cardio, Cholesterol
# [ B ] Height, Smoke
# [ C ] Smoke, Alco
# [ D ] Height, Weight
# 计算相关性系数矩阵
df = filtered_df.copy()
corr = df.corr(method='pearson') # 相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
# 创建一个 Mask 来隐藏相关矩阵的上三角形
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True # 令上三角矩阵等于True
# 绘制图像
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corr, mask=mask, vmax=1, center=0, annot=True, fmt='.1f', # heat是画皮尔逊相关性系数矩阵
square=True, linewidths=.5, cbar_kws={"shrink": .5})
# plt.show()
# 前面的探索中,我们知道性别对应 1 和 2,虽然不知道不同性别对应哪个值,但可以通过平均身高和体重来确定。
# 问题:绘制身高和性别之间的小提琴图 violinplot()。
# 这里建议通过 hue 参数按性别划分,并通过 scale 参数来计算性别对应的具体数量。为了便于你能正确绘制,这里给出一个 参考示例。
# 问题:绘制身高和性别之间的核密度图 kdeplot。
# 通过核密度图可以更清楚地看到性别之间的差异,但却无法得到每个性别对应的具体人数。
# 大多数情况下,皮尔逊相关性指数可以看出特征之间的相关程度。不过,这里我们进一步绘制 Spearman's rank correlation coefficient 斯皮尔曼等级相关系数对应的图像。它利用单调方程评价两个统计变量的相关性,是用于衡量两个变量的依赖性的非参数指标。
# 问题:使用 heatmap() 绘制特征之间的斯皮尔曼等级相关系数矩阵。
# 问题:下列那一组特征具有最强的 Spearman 相关性?
df_melt = pd.melt(frame=df, value_vars=['height'], id_vars=['gender'])
# pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)
# frame:要处理的数据集。
# id_vars:不需要被转换的列名。
# value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了。
# var_name和value_name是自定义设置对应的列名。
# col_level :如果列是MultiIndex,则使用此级别。
plt.figure(figsize=(12, 10))
# violinplot与boxplot扮演类似的角色,它显示了定量数据在一个(或多个)分类变量的多个层次上的分布,这些分布可以进行比较。不像箱形图中所有绘图组件都对应于实际数据点,小提琴绘图以基础分布的核密度估计为特征。
ax = sns.violinplot(
x='variable',
y='value',
hue='gender',
palette="muted",
split=True,
data=df_melt,
scale='count',
scale_hue=False
)
plt.show()
# 上面,我们已经计算过受访者的年龄。接下来,我们对其进行可视化。
#
# 问题:请使用 countplot() 绘制年龄分布计数图,横坐标为年龄,纵坐标为对应的人群数量。
#
# 问题:在哪个年龄下,心血管疾病患者人数首次超过无心血管疾病患者人数?
sns.countplot(x=(df['age'] / 365.25), hue='cardio', data=df)
# df[(df['age'].astype('int') >= age60) & (df['cholesterol'].astype('int') <= age65)].size()
# print('Dataset size: ', df.shape)
# print(df.head())
# df.melt() 是 df.pivot() 逆转操作函数
#
# 将列名转换为列数据(columns name → column values),重构DataFrame
#
# 如果说 df.pivot() 将长数据集转换成宽数据集,df.melt() 则是将宽数据集变成长数据集
#
# melt() 既是顶级类函数也是实例对象函数,作为类函数出现时,需要指明 DataFrame 的名称
# df_uniques = pd.melt(frame=df, value_vars=['gender', 'cholesterol',
# 'gluc', 'smoke', 'alco',
# 'active', 'cardio'])
# df_uniques = pd.DataFrame(df_uniques.groupby(['variable',
# 'value'])['value'].count()) \
# .sort_index(level=[0, 1]) \
# .rename(columns={'value': 'count'}) \
# .reset_index()
#
# sns.catplot(x='variable', y='count', hue='value',
# data=df_uniques, kind='bar', height=12)
#
# df_uniques = pd.melt(frame=df, value_vars=['gender', 'cholesterol',
# 'gluc', 'smoke', 'alco',
# 'active'], id_vars=['cardio'])
# df_uniques = pd.DataFrame(df_uniques.groupby(['variable', 'value',
# 'cardio'])['value'].count()) \
# .sort_index(level=[0, 1]) \
# .rename(columns={'value': 'count'}) \
# .reset_index()
#
# sns.catplot(x='variable', y='count', hue='value',
# col='cardio', data=df_uniques, kind='bar', height=9)
# plt.show()