深度学习入门笔记之LeNet-5网络
一、基本简介
LeNet5可以说是最早的卷积神经网络了,它发表于1998年。LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。论文原文地址http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf。
二、LeNet网络的基本结构
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
这7层网络的结构为 :
输入 → 卷积 → 池化 → 卷积 → 池化 → 卷积(全连接) → 全连接 → 输出。

各层参数详解:
1、INPUT层-输入层
首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。
注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
输入图片:32321
卷积核大小:55
卷积核种类:6
输出featuremap大小:2828 【(32-5+1)=28】
输出【神经元数量】:28286
可训练参数:(55+1) * 6(每个滤波器55=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(55+1)62828=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 55 的卷积核),得到6个C1特征图(6个大小为2828的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为55,总共就有6(55+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1的输出,C1输出的每个像素都与输入图像中的55个像素和1个bias有连接【每个像素都是经过一个55的卷积和一个偏置项计算所得到的】,所以总共有2628286=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(下采样层)
输入:28286
采样区域:22,长和宽的步长都是2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。最后将结果做一次映射通过sigmoid函数
采样种类:6
输出featureMap大小:1414(28/2)
本层的输出矩阵大小【神经元数量】:14146
可训练参数:26(和的权+偏置)
连接数:(22+1)614*14
S2中每个特征图的大小是C1中特征图大小的1/2。
详细说明:第一次卷积之后紧接着就是池化运算,使用 22核 进行池化,于是得到了S2,6个1414的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。
4、C3层-卷积层
输入:S2中所有6个或者几个特征map组合 【全部的输入14146,但卷积核并不是和所有的输入进行卷积,而是根据下图,进行的一个组合】 这属于LeNet的一个创新点吧
卷积核大小:55
卷积核种类:16
输出featureMap大小:1010 (14-5+1)=10
本层的输出矩阵大小【神经元数量】:101016
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合。
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则可训练参数为:6*(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516
连接数:10101516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 55. 我们知道S2 有6个 1414 的特征图,怎么从6 个特征图得到 16个特征图了【并不是通常的,卷积核5516与全部的输入14146进行卷积求和加上偏置项,而是卷积核5516与部分输入的组合进行卷积求和加上偏置项】? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:

C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为55,所以总共有6(355+1)+6*(455+1)+3*(455+1)+1*(655+1)=1516个参数。而图像大小为1010,所以共有151600个连接。
C3与S2中前3个图相连的卷积结构如下图所示:

上图对应的参数为 355+1,一共进行6次卷积得到6个特征图,所以有6(355+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(下采样层)
输入:1010
采样区域:22
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:55(10/2)
神经元数量:5516=400
可训练参数:216=32(和的权+偏置)
连接数:16*(2*2+1)55=2000
S4中每个特征图的大小是C3中特征图大小的1/2。
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:55
卷积核种类:120
输出featureMap大小:11(5-5+1)
本层的输出矩阵大小【神经元数量】:11120
可训练参数/连接:120*(1655+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。
7、F6层-全连接层
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。【也有说此处用的激活函数为双曲正切函数】
可训练参数:84*(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:

上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。

上图是LeNet-5识别数字3的过程
三 代码实现(Pytorch实现)
1 Anaconda安装使用_虚拟python环境创建_pytorch安装及测试_Pycharm安装。
注:Anaconda 是一个python的发行版,包括了python和很多常见的软件库, 和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易。所以装了anaconda就不需要装python了!!!
(1)Anaconda3安装
官网下载Anaconda3:https://www.anaconda.com/distribution/,选择下载最新版python 3.9的。安装路径选择默认路径:C:\ProgramData\Anaconda3。

安装步骤:next->I agree->All users->默认安装路径->next->添加环境变量(这步建议勾选)->python3.9勾选了(这步是允许其他程序软件检测到Anaconda作为基本的python在这个系统中)->install->next->finished. 如果没有勾选自动添加环境变量,要手动添加,具体查找网上。
这是安装完成后的环境变量。

Anaconda安装后测试:
(1)开始菜单里面Anaconda3里面点击Anaconda Prompt后进入命令操作界面:输入python --version 可以查看当前Anaconda安装默认的python版本,输入python可以进入python命令行进行操作,并且按cotrol+z或者输入exit()退出python命令行。(或者Win+R 调出运行对话框,输入 cmd 回车,输入 python,如果出现python版本信息,表明安装成功。)
(2)使用快捷键Win+R,输入"cmd",点击确认进入"命令提示符",输入conda --version,显示conda版本号即为安装成功。
(2)搭建虚拟python环境。
以每一个新项目,单独新建一个环境开发,项目自己互不影响,项目所用到的库都是每一个环境中单独拥有的。
安装完成后(此时电脑已经自动搭建了python环境),找到 Anaconda Navigator的图标并点击打开。选择Environments。会发现上面有一个root(其他的都是自己建的),这个就是系统默认的python环境——我们不用它。
我们自己创建一个新环境:第一步点击Environment,第二步点击Creat,接着就会弹框。写一个你的环境名称,你的python版本;填写完后点击create,开始创建。创建的时间也有点慢。等待创建完之后,此时我们所需要的单独项目的python开发环境已经具备了。
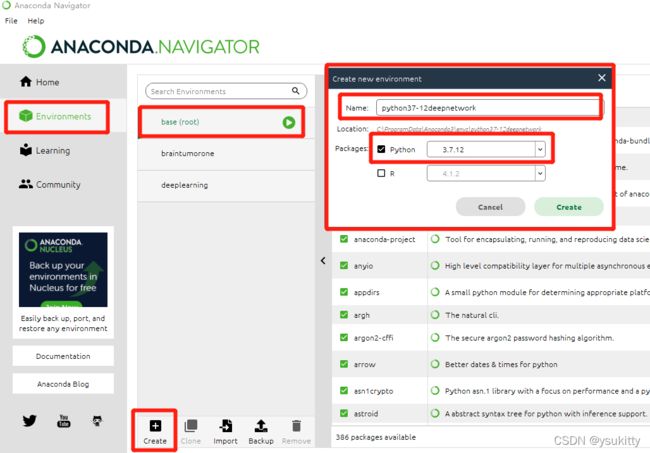
(3)我们再回到刚刚安装anaconda的路径:C:\ProgramData\Anaconda3下,找到名为 envs文件夹并点开。发现此时里面已经有了我们刚刚创建的那个新环境:python37-12deepnetwork。

点开新的环境:找到里面名为:Scripts的文件夹,此时复制这个文件夹的路径。我的路径为:C:\ProgramData\Anaconda3\envs\python37-12deepnetwork\Scripts(这个时候我们需要重新配置我们新建的这个新的开发环境)
接着右击 此电脑–属性–高级系统设置–环境变量,打开Path—点击新建,将刚刚复制的Scripts的路径复制进去。然后点击所有的确定–确定–确定。。。。这样新的环境已经配置好了!!

以管理员身份打开Anaconda Prompt,激活python37-12deepnetwork环境:
activate python37-12deepnetwork
退出:
conda deactivate

(3)安装Pytorch。
官网下载PyTorch:https://pytorch.org/。激活python37-12deepnetwork环境,在这个环境下输入命令:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
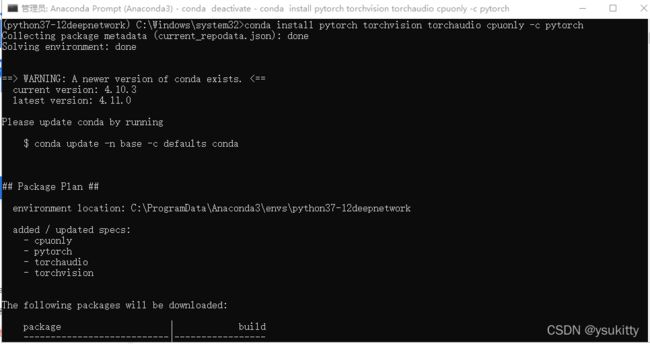

测试是否安装成功:
(1)激活环境python37-12deepnetwork:
activate python37-12deepnetwork
(2)进入python:python
(3)测试numpy:import numpy
(4)测试pytorch:
import torch
import torchvision
print(torch.version)
(5)如果成功打印,测试成功,使用exit()退出python
(6)关闭虚拟环境:
conda deactivate

(4)安装pycharm。
我的pycharm之前就安装好了,所以我直接进行后面的设置。设置的细节部分这里忽略了,可以参考https://zhuanlan.zhihu.com/p/35255076。
新建项目,Interpreter选择existing Interpreter,这里填写的是python环境中python.exe文件地址,点击那个齿轮按钮,添加一个新的路径地址,找到刚刚新建的python环境我的是( C:\ProgramData\Anaconda3\envs\python37-12deepnetwork) 中的python.exe文件,双击选中它。 然后点击右下方 create。创建完毕!
新建的工程如下:

这时候你只需要 鼠标选中deepnetwork,然后右击选中new->python file,新建一个py文件即可进行开发。
备注
(1)github上有无数开源代码,可以对感兴趣的项目直接进行搜索,然后对项目clone(需安装git)或直接download,也可以fork到自己的仓库(然后使用git pull到本地),当自己脑子短路或者什么的上去找找灵感吧。
(2)在跑别人的项目时如果遇到相应module缺失的情况,打开Pytorch Anaconda虚拟环境用conda或pip安装即可解决。(建议优先使用conda,conda会分析依赖包,会将依赖包一同安装)
(3)如果需要使用本虚拟环境在Notebook中跑项目,进入工作目录激活虚拟环境,输入Jupyter Notebook运行即可。
(4)如果需要使用本虚拟环境在Pycharm进行项目开发,将设置里的Project Interpreter改为相应Anaconda文件目录下的Pytorch虚拟环境中的python.exe文件即可。(如:D:\Anaconda3\envs\pytorch\python.exe)
2 在Pytorch的官网搜索某一个函数。
3 使用Pytorch的官方文档。
左边的列是Pytorch API的主的目录,点击某个模块,右边的列是属于这个模块的详细的方法。

4 注释model.py。
在文件中,ctrl+鼠标左键可以找到函数的定义,比如F.relu。
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)#
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
import torch
input1=torch.rand([32,3,32,32])#随机生成图像数据,数据的维度分别对应[batch,Channel,Height,Weight]
model=LeNet()#实例化模型
print(model)
output=model(input1)#输入数据,前向传播。可以在forward函数中随机设置一个断点,看调试的过程
代码最后面的一段,可以测试一下搭建的模型。

5 注释train.py函数。
(1)下载CIFAR10的数据集(设置download为True,会自动下载数据集,下载完再设置为False即可)
CIFAR10数据集是一个很经典的图像分类数据集,由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集,一共包含 10 个类别的 RGB 彩色图片。
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
下载的数据集放在当前目录的data文件夹里(’./data’); train=True表示会导入CIFAR10的训练集的样本,有50000张训练样本。
(2)transform=transform对图像进行预处理的函数。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
通过transforms.Compose这个函数将所使用的的预处理方法打包成一个整体,这里两个预处理方法,一个是ToTensor(),convert a PIL image or numpy ndarray to tensor,也就是将HWC转换为CHW,将值得范围从[0,255]转换为[0,1];transforms.Normalize标准化函数。
torchvision.datasets.里面有很多数据集,可以看一下。也就是Pytorch给我们准备了很多的数据集,大家可以下载使用。
注:Pytorch Tensor的通道排序:[batch,channel,height,width]
(3)把训练集导入进来,分成一个批次一个批次的。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
batch_size=36 每一批随机拿出36张图片,进行训练;shuffle=True表示对数据集是否要进行打乱,就是batch里面的数据是不是随机提出来的;num_workers=0载入数据的线程数,在linux系统或者ubuntun系统下这个参数可以定义,但在windows系统下,这个参数只能定义为0。
(4)接下来按照同样的方法导入验证集。
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
train=False,设置为False,所以导入的是验证集,验证集有10000张图片,batch_size=5000设置为5000,去测试验证集的准确率。
(5)迭代器。
val_data_iter = iter(val_loader)
val_image, val_label = val_data_iter.next()
val_data_iter = iter(val_loader),将val_loader转化为一个可迭代的迭代器;val_image, val_label = val_data_iter.next(),next()方法可以获取到一批图像,图像和图像对应的标签值。
(6)接下来把标签导入classes。
这是一个元组类型,值是不可以改变的。它对应的标签,index0对应的就是plane,index1对应的就是汽车, 依此类推。

(7)接下来我们看一下导入的图片。
先将batch_size改为4,如果是5000张肯定看不了的。(val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0))
运行下面的代码就可以看到验证集里面的图片。 看完之后,可以把下面的代码删掉了。
import matplotlib.pyplot as plt #绘制图像的包
import numpy as np
def imshow(img):
# unnormalize 对图像进行反标准化处理:前面对图像进行了预处理,
# 标准化transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
#这里进行反标准化
#标准化是 output=(input-0.5)/0.5 反标准化就是input=output*0.5+0.5=output/2+0.5
# 值得范围是[0,1] 但不影响显示图像
img=img/2+0.5
#现在图像的格式为 C*H*W,将图像转换为numpy格式 也就是H*W*C
npimg=img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
#print labels
print(''.join('%5s' % classes[val_label[j]] for j in range(4)))
#show images
imshow(torchvision.utils.make_grid(val_image))
(8)接下来,实例化LeNet。
net = LeNet()#实例化
loss_function = nn.CrossEntropyLoss()#定义损失函数 已经包含了softmax函数,所以不需要网络的输出包含softmax函数
# 定义优化器,传入的第一个参数就是所需要训练的参数。将所有可训练的参数都进行训练,lr是学习率
optimizer = optim.Adam(net.parameters(), lr=0.001)
(9)接下来是训练过程。
for epoch in range(5): # loop over the dataset multiple times #训练集迭代5次
running_loss = 0.0 #变量,累加在训练过程中的损失
for step, data in enumerate(train_loader, start=0):#通过这个循环,遍历我们的训练集样本
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data #将得到的数据分离出图像和图像对应的标签
# zero the parameter gradients
# 历史损失梯度清0,如果不清除历史梯度,就会对计算的历史梯度进行累加,
# 通过这个特性你能够变相实现一个很大batch数值的训练。
# 默认batch_size越大训练效果越好,但受硬件条件限制,比如内存不足,可能没办法实现一个很大batch_size的训练
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)#前向传播
loss = loss_function(outputs, labels)#计算损失,第一个参数是网络输出预测的值,第二个参数是图像的真实标签
loss.backward()#反向传播
optimizer.step()#参数更新
# print statistics
#接下来是打印的过程
running_loss += loss.item()#累加损失值
if step % 500 == 499: # print every 500 mini-batches#每隔500步,打印一次信息
# with是上下文管理器
#with torch.no_grad() 在接下来的过程当中,不要计算每个节点的误差损失梯度
#在预测或者测试的过程中,都要把这个函数给带上
#属于这个函数的范围内,都不会计算误差梯度
with torch.no_grad():
outputs = net(val_image) # [batch, 10]#正向传播
# 寻找输出最大的index在什么位置
#也可以理解为网络预测最可能是哪个类别的。dim=1在维度1上寻找最大值。因为第0个维度对应的是batch。我们
#需要在输出的10个节点中寻找最大的值
#[1]表示只需要他的index即索引就可以了,并不需要知道他的最大值是多少
#predict_y 为预测的最大的那个值所对应的标签类别
predict_y = torch.max(outputs, dim=1)[1]
#将预测的标签类别与真实的标签类别进行比较torch.eq(predict_y, val_label),相同会返回1,不相同会返回0
#再通过求和函数sum(),能求得在本次验证中,预测对了多少个样本;.item()拿到数值
#val_label.size(0)验证样本的数目
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
#打印验证过程中的信息:epoch训练迭代到多少轮;step某一轮的多少步;
#running_loss / 500 训练500步中的平均训练误差;accuracy验证样本的准确度
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0#清0,然后进行下500次的迭代
print('Finished Training')
#保存模型,将网络的所有参数进行保存
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
enumerate这个函数不仅可以返回每一批的数据data,而且还会返回这一批的data所对应的步数,也就是index,这里给出的start=0,也就是说从0开始。
训练完会生成一个Lenet.pth的文件,这是训练完后生成的一个模型权重的文件。
7注释predict.py 函数。
可以在网上随便下载一张图片,放在当前文件夹下。(与predict.py文件放在一起)
predict.py是调用模型权重进行预测的一个脚本。
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),#下载的图片大小不一定是32*32的
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth')) #载入刚刚保存的权重文件
im = Image.open('1.jpg')#导入图片 [H,W,C]
im = transform(im) # [C, H, W]#对图片进行预处理
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]#按照Pytorch Tensor的要求,增加一个维度
with torch.no_grad():#不需要求损失梯度
outputs = net(im)#把图片传入网络中
predict = torch.max(outputs, dim=1)[1].numpy()#寻找输出中最大值所对应的index
print(classes[int(predict)])#将index传入到classes
if __name__ == '__main__':
main()
这里也可以改为用softmax函数,去预测输出的概率。
#接上
with torch.no_grad():#不需要求损失梯度
outputs = net(im)#把图片传入网络中
predict = torch.softmax(outputs, dim=1)#softmax是对第一个维度,也就是channel进行操作
print(predict)#softmax输出的是属于各个类别的概率
#接下
以上代码可以自行测试。
8 运行程序的目录

通过代码下载的CIFAR10的数据集如下所示
四、问题
1 激活函数在代码里是怎么用到的?
![]()
2 运行程序时缺少matplotlib。所以下面安装一下matplotlib包。
(1)首先进入指定环境。以管理员身份打开Anaconda Prompt,激活python37-12deepnetwork环境:
activate python37-12deepnetwork
退出:
conda deactivate
(2)执行
conda install matplotlib
执行出错,
(3)在安装matplotlib的时候,需要很多辅助包,如果有一个叫qt的包出了问题。可以执行
set PATH=%PATH%;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;
然后继续执行
conda install matplotlib
qt包的问题就没有了。
(3)安装成功

3 网上随便下的猫和狗的图片,分别被识别成了狗和鸟,正确率有待提高。