一文看懂variant convolutions
一文GET各种CONVs
- 1. 普通卷积
- 2.转置卷积transposed convolution
- 3. Dilated convolution空洞卷积
-
- 3.1 基本原理
- 3.2 使用pytorch进行简单验证
- 4. depthwise separable convolution深度可分离卷积
-
- 4.1 depthwise separable convolution介绍
- 4.2 为什么depthwise separable convolution可以减少计算量
- 5. Causal convolutions及 dilated causal convolutions(空洞因果卷积)
-
- 5.1 Causal convolutions(因果卷积)
- 5.2 dilated causal convolutions(空洞因果卷积)
- 参考文献
本文希望尽量以图说话,简明扼要地分享干货。
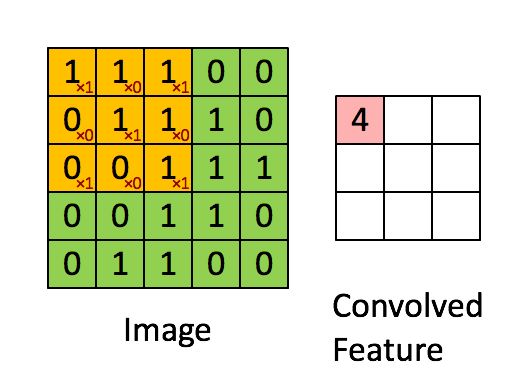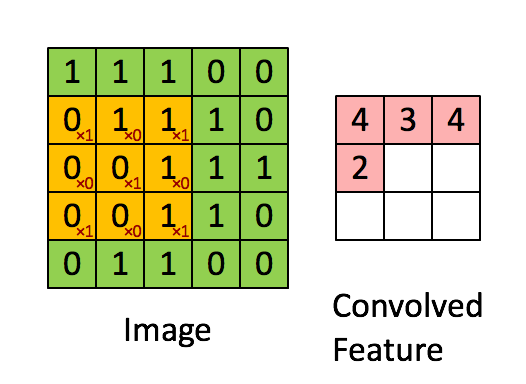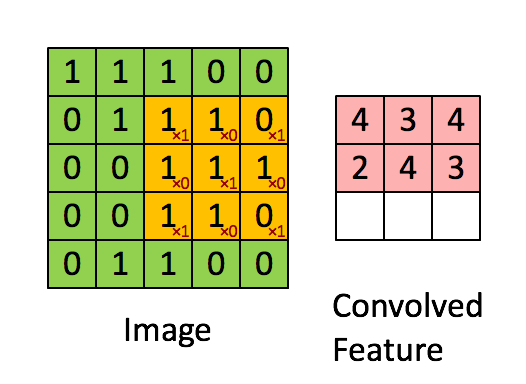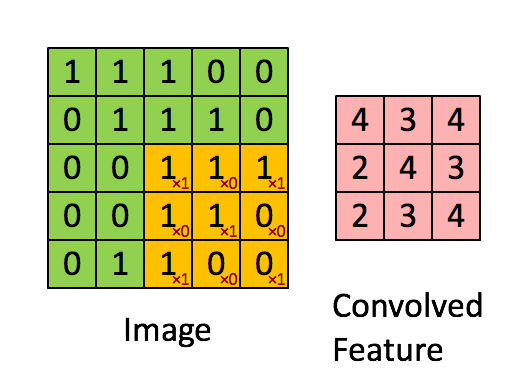
1. 普通卷积
下图是一张比较经典的展示。其计算公式为:
其中k为kernel的尺寸,p为padding的大小,s为步长的大小。
O = i − k + 2 p s + 1 \qquad\qquad O= \cfrac{{i - k + 2p}}{s} + 1 O=si−k+2p+1

2.转置卷积transposed convolution
又名逆卷积/deconvolution。
下图把转置卷积计算过程写的很清楚,让我们很直观就可以了解转置卷积。
其计算公式: O = s ∗ ( i − 1 ) + k − 2 ∗ p O = s*(i - 1) + k - 2*p O=s∗(i−1)+k−2∗p
则输入图片尺寸: i = O − k + 2 ∗ p s + 1 i=\cfrac{O-k+2*p}{s}+1 i=sO−k+2∗p+1
容易看出从运算角度普通卷积和转置卷积互为逆运算。

下图相当于把上图过程总结了下。
Dive into Deep Learning 中的描述也很不错:
图13.10.1是一个kernel为2,padding为0,stride为1的转置卷积:
 图13.10.2是一个kernel为2,padding为0,stride为2的转置卷积:
图13.10.2是一个kernel为2,padding为0,stride为2的转置卷积:

下图是不记得从哪剽来的,kernel为4,stride为3的转置卷积:
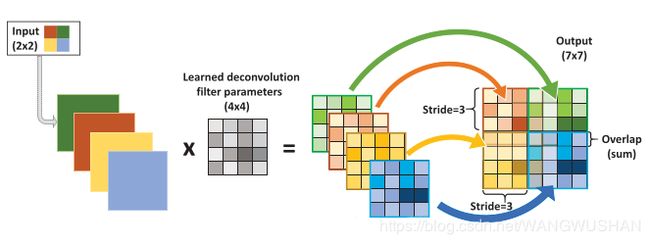
3. Dilated convolution空洞卷积
3.1 基本原理
首先需要清楚的是所谓dilated指的是对卷积核的操作。
这样可以在参数数量不变的同时,具有更大的感受野。

此图来自于dilated conv原paper。可以简单理解为通过dilated,产生了新的kernel,再用这个kernel去做普通卷积。
需要说明的是:pytorch的实现与上图是有所不同的。
pytorch实现具体计算过程可以参考:https://blog.csdn.net/zw__chen/article/details/85007519。如下图:

3.2 使用pytorch进行简单验证
本人也使用了pytorch进行了验证。
这里使用3*3的卷积,weight设置为1,bias设置为0。
import torch
x=torch.arange(1,26).reshape((1,1,5,5)).type(torch.float)
rate=2
m=torch.nn.Conv2d(1,1,3,1,padding=rate,dilation=rate)
m.weight.data.fill_(1)
m.bias.data.fill_(0)
with torch.no_grad():
y=m(x)
#out:y
tensor([[[[ 28., 32., 48., 32., 36.],
[ 48., 52., 78., 52., 56.],
[ 72., 78., 117., 78., 84.],
[ 48., 52., 78., 52., 56.],
[ 68., 72., 108., 72., 76.]]]])
这个结果具体是如何算出来的呢?
我们使用torch.nn.functional实现pad==2。
import torch.nn.functional as F
x=torch.arange(1,26).reshape((1,1,5,5))
p2d = (2, 2, 2, 2)
x1=F.pad(x, p2d, "constant", 0)
在画图工具中圈出针对第一个位置dilated conv的作用像素,
1+3+11+13=28。
其他就不再一一验证了。

具体实现公式如下:
dilated后的kernel_size:(d-1)*(k+1)+k。膨胀系数为d。
膨胀卷积输出图像尺寸计算公式:
O = i + 2 p − k − ( k − 1 ) ∗ ( d − 1 ) s + 1 \qquad\qquad O= \cfrac{{i + 2p- k - (k - 1)*(d - 1)}}{s} + 1 O=si+2p−k−(k−1)∗(d−1)+1
或(相当于在普通卷积基础上增加了一项):
O = i − k + 2 p − ( k − 1 ) ∗ ( d − 1 ) s + 1 \qquad\qquad O= \cfrac{{i - k + 2p - (k - 1)*(d - 1)}}{s} + 1 O=si−k+2p−(k−1)∗(d−1)+1

4. depthwise separable convolution深度可分离卷积
4.1 depthwise separable convolution介绍
depthwise separable convolution深度可分离卷积在论文MobileNets: Efficient Convolutional Neural Networks for Mobile Vision中有详细的介绍。
它可以通过降低计算量来实现轻量化的网络结构。
depthwise separable convolution由两部分卷积组成:
depthwise convolution 以及 1 ∗ 1 {\rm{1*1}} 1∗1convolution/pointwise convolution。
其实呢,这种卷积可以说是分组卷积分组数=channel数时的特殊情况。
有意思的是,分组卷积最初的应用Alexnet并不是为了刻意减少计算量,而是解决单块GPU计算能力不足的情况,当然,那时它也尚未拥有分组卷积的“学名”。

可以看出,它的实现原理非常简单,先在每个输入channel进行depthwise convolution,再在channel方向上进行1*1 convolution来进行combination。
4.2 为什么depthwise separable convolution可以减少计算量
如输入一个feature map F,其大小为: D F ∗ D F ∗ M D_F *D_F*M DF∗DF∗M,要使其生成 D F ∗ D F ∗ N D_F *D_F*N DF∗DF∗N的特征图, M , N M,N M,N分别为输入、输出特征图的channel数,则卷积核的大小为:
D K ∗ D K ∗ M ∗ N ( s t r i d e = 1 , p a d d i n g = ′ S A M E ′ ) \qquad\qquad D_K *D_K *M*N(stride=1,padding='SAME') DK∗DK∗M∗N(stride=1,padding=′SAME′)。
此卷积的计算量:
D K ∗ D K ∗ M ∗ N ∗ D F ∗ D F \qquad\qquad D_K *D_K *M*N*D_F *D_F DK∗DK∗M∗N∗DF∗DF.
如果采用深度可分离卷积呢,分成两部分来计算:
-
depthwise convolution
卷积核大小为: D K ∗ D K ∗ M D_K *D_K *M DK∗DK∗M
注意:每个channel对应一个卷积核,而不是所有channel都采用同样的卷积核
计算量为: D K ∗ D K ∗ M ∗ D F ∗ D F D_K *D_K *M*D_F *D_F DK∗DK∗M∗DF∗DF -
pointwise convolution
计算量为: 1 ∗ 1 ∗ M ∗ N ∗ D F ∗ D F 1*1*M*N*D_F *D_F 1∗1∗M∗N∗DF∗DF
因此,depthwise separable convolution与常规卷积计算量的比值为:
D K ∗ D K ∗ M ∗ D F ∗ D F + M ∗ N ∗ D F ∗ D F D K ∗ D K ∗ M ∗ N ∗ D F ∗ D F = 1 N + 1 D K 2 \qquad\qquad \cfrac{D_K *D_K *M*D_F *D_F+M*N*D_F *D_F}{D_K *D_K *M*N*D_F *D_F}= \cfrac{1}{N} + \cfrac{1}{{D_K}^2} DK∗DK∗M∗N∗DF∗DFDK∗DK∗M∗DF∗DF+M∗N∗DF∗DF=N1+DK21
当channel数,如数十/上百层时, 1 N \frac{1}{N} N1部分可以忽略;若K=3,即采用 3 ∗ 3 {\rm{3*3}} 3∗3卷积时,结果约为 1 8 ∼ 1 9 \cfrac{1}{8}\sim\cfrac{1}{9} 81∼91,也就是说深度可分离卷积计算量会减少到常规卷积的 1 8 ∼ 1 9 \cfrac{1}{8}\sim\cfrac{1}{9} 81∼91。
5. Causal convolutions及 dilated causal convolutions(空洞因果卷积)
该卷积来自wavenet。
5.1 Causal convolutions(因果卷积)

何为causal(因果),即前因后果。论文中也给了解释,从上图看,t时刻预测的 p ( x t + 1 ∣ x 1 , x 2 , . . . , x t ) p(x_{t+1}|x_1,x_2,...,x_t) p(xt+1∣x1,x2,...,xt),不依赖于 x t + 1 , x t + 2 , . . . , x T x_{t+1},x_{t+2},...,x_T xt+1,xt+2,...,xT。
5.2 dilated causal convolutions(空洞因果卷积)
为了能更好处理时序信息,达到甚至超越RNN/LSTM,通过多层空洞卷积来指数型地增加感受野。

参考文献
[1] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
[2] Dive into Deep Learning
[3] wavenet