Java项目笔记
目录
- 一、交流平台
-
- 第一章
-
- 1.开发社区首页
- 第二章
-
- 2.发送邮件功能
- 3.回话管理
- 4.检查登录状态
- 5.开发登录退出功能
- 6.生成验证码
- 7.显示登录信息(拦截器)
- 8.用户注册功能
- 9.账号设置
- 第三章
-
- 10.过滤敏感词
- 11.发布帖子
- 12.事务管理
- 13.添加评论
- 14.发送列表
- 第四章
-
- 15. redis
- 16. 点赞
- 17. 关注、取消关注
- 18. 关注列表、粉丝列表
- 19.我收到的赞
- 20.优化登录模块
- 第五章
-
- 21. kafka启动
- 21. kafka
- 22. kafka应用实例
- 23. 发送系统通知
- 24. 显示系统通知
- 25. 阻塞队列
- 第六章
-
- 26.es启动
- 26.es入门
- 27.spring整合es
- 28.开发社区搜索功能
- 第七章
-
- 29.初识Security
- 30.讲文件上传至云服务器
- 31.权限控制
- 32.任务执行和调度
- 33.生成长图
- 34.网站数据统计
- 35.优化网站的统计
- 36.置顶,加精,删除
- 37.单元测试
- 38.项目总结
- 面试题
-
- 1.介绍⼀下你的项⽬是在做⼀件什么事情?有什么样的主要功能?项⽬的主要架构是什么样的,为什么要做这样的⼀个项目。
- 2.权限管理是如何做的,怎么保证的每个账号的安全性?为什么考虑使⽤Spring Security,是怎么做权限管理的,讲⼀下这部分的⼯作。怎么进⾏的合法性检测,都有哪些种是不合法的,了解信息加密的⽅式吗?
- 10、你⽤到了Cookie,那cookie和session之间有什么差别?ThreadLocal有什么作⽤,内部是怎么实现的(第二章有)
- 项目部署
-
- 1.租阿里云服务器
- 2.安装putty
- 3.安装需要的环境
- 4.上传本地文件
- 5.解压上传的压缩包
- 思维导图
一、交流平台
第一章
1.开发社区首页
一、新建了三个类:
1.DiscussPost:用户的帖子。
属性: id(自动生成主键),用户 id(外键连接 user 表),帖子的主题 ,帖子内容,帖子类型(普通,置顶),帖子状态(正常,精华,拉黑),帖子的创建时间 ,评论数量, 帖子分数(给帖子排名,按热度)。
2.Page:为了分页。
属性:有当前页码,显示上限,数据总数(用于计算总页数),查询路径(用于复用分页链接),拥有获取当前页起始行、总页数、获取下面页码的起始页码和结束页码方法。
3.User:用户类。
Service: 通过 user id 得到 user 对象。
二、Controller 层
处理网页的查询请求可以通过注解注入 DiscussPost Service 来解决,但 DiscussPost Service 只能返回 DiscussPost 列表,但列表中没有 user 属性,只有 user id(我们一般看到的讨论网页是能看到 user 的) 所以我们还需要注入 UserService 来得到 user 对象,将 user和 discussPost 通过list
为了分页:在模板中配置相对应的方法 首页(末页)路径、第几页 达到首页之后上
一页的按钮不可点(末页同理) 显示的页码范围。
第二章
2.发送邮件功能
①在新浪中将想要作为发送方的邮箱设置 SMTP 服务为开启,通过 Maven 导入 springboot mail
的 jar 包,在配置文件中配置域名、端口、发送邮件的账号、密码等,通过 JavaMailSender发送邮件。
②为了能够将发送邮件的逻辑复用,创建 MailClient(因为要调用新浪的服务,所以我们是客户端)类来封装 JavaMailSender(有两种方法:发送邮件主体,创造邮件主体),先通过 JavaMailSender 来创建空的邮件主体之后用 spring 提供的 MimeMessageHelper 帮助类来丰富我们的邮件主体(发件人(配置文件中配置好了),收件人(方法中传入的参数),主题(方法中传入的参数),内容(方法中传入的参数)),之后再通过 JavaMailSender 的 send 方法发送邮件。
③使用 Thymeleaf 发送 html 文件:先创建 Thymeleaf 模板,将 model 和模板给模板引擎生成网
页(字符串类型),赋给发送邮件的内容参数。
Thymeleaf是一个现代服务器端Java模板引擎,适用于Web和独立环境,能够处理HTML,XML,JavaScript,CSS甚至纯文本。
Thymeleaf的主要目标是提供一种优雅且高度可维护的模板创建方式。为实现这一目标,它以自然模板的概念为基础,将其逻辑注入模板文件,其方式不会影响模板被用作设计原型。这改善了设计沟通,缩小了设计和开发团队之间的差距。
3.回话管理
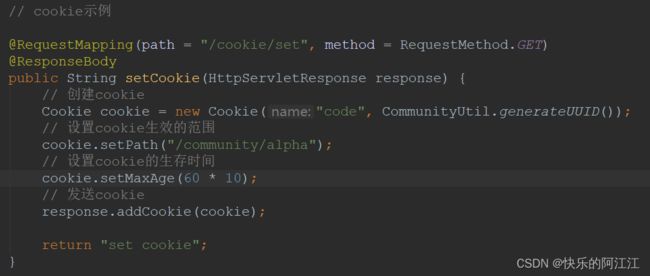
Http 的两个成功执行的请求之间是没有关系的,需要通过 cookie 来解决问题,使得请求能共享相同的上下文信息,达成相同的状态。
cookie 是服务器发送到浏览器,并保存在浏览器端
的一小块数据,浏览器下次访问该服务器时,会自动携带块该数据,将其发送给服务器,一
个 cookie 只能保存一组 key,value,上图的四步为通常的 cookie 设置,最后的返回值是返回
给浏览器的字符串,非网址,是乱写的。

获得 cookie,注意 cookie 在@RequestMapping 中传入给了服务器,可以在响应体中通过@CookieValue(key 值) String code 来获得 cookie 中的某一值,全部获得 cookie 的话是个
数组。
Session - 是 JavaEE 的标准,用于在服务端记录客户端信息。 - 数据存放在服务端更加安
全,但是也会增加服务端的内存压力。
传 cookie 是为了能够查找到对应的session。

Session 是和 model 等类型一样,一经声明 spring mvc 自动注入
2.为何用 cookie 不用 session?
当浏览器发出请求,传给 nginx 代理,经过负载均衡,可能第一次的请求发给了服务器 1,服务器 1 存储了一份 session 返给浏览器一个 cookie(session id),之后第二次浏览器发出请求,经过反向代理可能给服务器 3 发送了此 cookie,但服务器 3 没有对应的 session,会新建一个 session,则此 session 和第一次的请求数据创建的 session 不一样,会造成数据错误,可以通过设置负载均衡的分配策略,一种是粘性 session,只要是同一个浏览器 ip 就固定的分配给同一个服务器处理,但这样就会很难保证服务器的负载是均衡的,负载不均衡,性能不好;
第二种策略是同步 session,当一个服务器创建了 session 后,会同步给每个服务器,首先一台服务器同步给其他很多服务器,会影响性能,而且服务器和服务器之间会产生耦合,产生关联,会影响部署;
第三种方案是共享 session,单独有一个服务器,专门存放 session,当需要获得 session 时,都去找此服务器,但这样如果这个服务器挂掉了,其他服务器没法工作,违背了分布式的初衷:解决性能瓶颈,如果将此服务器搞一个集群,那和方案二没有区别,仍然需要共享;目前主流方案是能将数据存放到 cookie 里就放到 cookie 里,敏感数据比如密码之类的,就放到 nosql 数据库里(关系型数据库会把数据存放到硬盘里,速度慢)
4.检查登录状态
用户如果知道功能路径可以通过超路径访问,但如果是一个需要登陆才能访问的路径,但你直接通过超访问路径访问的话,可能会造成问题,下面的例子是围绕未登录但直接访问账号设置功能来讨论。
自定义注解:
(1)常见的元注解:
@Target:声明自定义的注解可以写在哪个位置,作用在哪个类型上(定义在类、方法、属
性上)
@Retention:声明自定义注解保留的时间(有效的时间:编译时有效,运行时有效)
@Document:生成文档时是否将自定义注解也带上。
@Inherited:用于继承,子类继承一个父类,父类有自定义注解,子类是否要将注解继承。
(2)如何读取注解:
Method.getDeclaredAnnotations() 通过反射 Method 类型对象调用这个方法获取这个方法上所有的注解。Method.getAnnotation(Class annotationClass)尝试获取 annotation(注解)Class 类型的注解。
创建注解

作用域在方法上,有效的时间是程序运行时。

在想要拦截的方法上加上此注解。
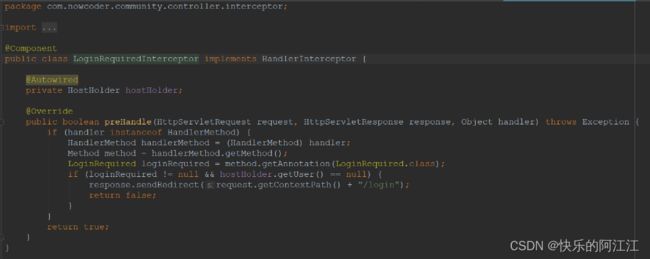
定义拦截器,因为只需要拦截方法,所以先判断 handler 是否是拦截方法类型,从拦截方法中获取方法,通过反射得到方法的此注解类型的注解,判断只要拥有此注解的且 user 为空(还未登录)则返回登录页面,return false 不继续往下执行。

拦截器的使用范围,不拦截一些静态的东西,不用管拦截范围,按默认全局就可以,因为在定义拦截器的时候已经拥有了相关的逻辑,也可以像第一个拦截器定义域一样,添加定义域不按默认值,但这样的话太麻烦,因为可能有好多路径都需要添加,一个一个麻烦。
5.开发登录退出功能
1.访问登录页面:点击顶部区域内的链接,打开登录页面。
2.登录:验证账号、密码、验证码,成功时,生成登录凭证,发送给客户端,失败时,跳转回登录页,登录有一个登录凭证表,首先创建一个登录凭证实体类,在 dao 层创建用于与登录凭证表相连接的接口 , 通过注解来实现与 登 录 凭 证 表 连 接 ,如下图所 示

在 service 层,创建方法,返回值为 map 用于判断用户在传递过来的账号、密码是否正确、以及记住我选项(对应登录凭证表的存活时间):空值处理、验证账号、验证状态、验证密码(注意与 user 表中的保存密码不同,还需要加盐、加密才可以与数据库中的密码相同),通过 dao 生成登录凭证在 controller 层,检查验证码,通过 service 层来检查用户账号和密码,不正确返回登录页面,正确返回主页,且通过 cookie 把登录凭证里的 ticket 返给客户端。
3.退出:将登录凭证修改为失效状态,跳转至网站首页在 service 层通过 dao 层中的 updateStatus 方法将凭证改为失效状态,controller 层通过service 更改凭证,重定向到登录页面。
6.生成验证码
Kaptcha:现成的验证码工具
导入 jar 包,编写 Kaptcha 配置类,生成随机字符、生成图片。
导入 jar 包:从 maven 中导入 jar 包,编写 Kaptcha 配置类:因为 sring 没有整合 kaptcha,所以我们需要创建一个配置类(颜色字体 长 宽 高 , 有 哪 些 随 机 字 符 , 一 个 验 证 码 有 几 个 字 符 ), 去 整 合kaptcha。

主要看 properties

生成验证码:先生成文本,再将文本变成图片;因为此次请求只是将验证码图片传给页面,但当你点击登录时,会将此次的验证码文本与登录时输入的验证码文本作比较,所以两次请求有关联,是一次会话,且是敏感信息,要通过 session 来完成会话;之后要将图片输出给浏览器,首先声明你回应的类型是什么,之后开启输出流,将图片输出出去,spring mvc 会自动关闭输出流。
Ps:只要响应体不是字符串或网址,则方法返回空值,且将响应体当做参数传入方法中,进行操作
Ps:注意在模板中将验证码的路径改下,改成你验证码中的请求路径。
7.显示登录信息(拦截器)
在网页头部因为每个请求都需要判断显示的按钮(首页、登录、注册、消息、个人头像、),反 复 实 现 所 以 用 拦 截 器 处 理 , 逻 辑 如 下 图 所 示。
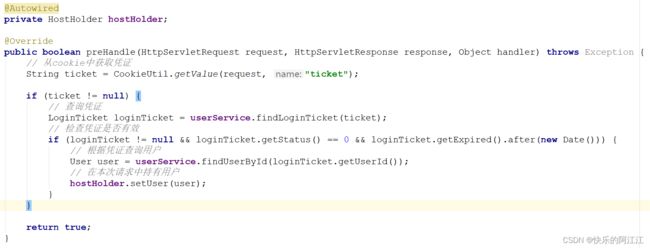
在请求给 controller 之前先拦截一次,获取请求的持有对象(因为 controller 层也可能会用到):通过 cookie 得到 ticket,之后用 ticket 通过登录表得到 userID,将这个 id 传给 ThrendLocal对 象 ( 为 了 防 止 线 程 冲 突 , 因 为 浏览 器 和 服 务 器 是 多 对 一 的 关 系 )。

在模板引擎之前再拦截一次,在 ThrendLocal中获取 user 对象传给 model在模板引擎之后拦截一次,将 ThrendLocal中的对象清理掉,减少内存。
8.用户注册功能
Ps:CommunityUtil 是自己写的类拥有生成随机字符串的方法(封装了 uuid)以及 MD5 加密方法。
可以将用户注册功能分为三个请求,访问注册页面,提交注册数据,激活注册账号(按请求来开发用户注册功能)
1.访问注册页面:在 controller 层编写响应方法,返回注册页面路径。
2.提交注册数据:通过 maven 导入 commons lang 的 jar 包,为了判断常用的数据是否空值,在UserService 层中编写一个注册方法,传入的参数类型为 user,返回值为 map 因为可能是某一字段不能为空,账号已存在等等信息。
首先对空值处理,判断 user 是否为 null,是的话抛出异常,在判断 user 里的属性是否为空,若为空将错误信息 put(key=“usernamemsg”,value=“账号不能为空” 等映射)进返回的 map 中,直接 ruturn map,若上述错误都没有判断 username、Email 是否重复,若重复 return,都没有问题,将用户设置的密码进行加密(通过 CommunityUtil设置 salt 与用户密码拼接在一起之后传入给 CommunityUtil 的加密方法)覆盖用户密码,将一些用户没有编写的属性赋值(type、status 等),赋给用户一个随机头像(应该传入路径参数,共有 1000 个随机头像,大体的路径相同,只有一个数字不同可以通过 random 随机生成),用 insertUser 方法导入数据库中,给用户发邮件方法(让其激活),将context(对应 email 以及对应的网址(域名+项目访问路径+项目下激活的访问功能路径+用户 id+激活码))和网站模板传给模板引擎,调用发送邮件方法传入用户邮箱,主题为激活账号,内容为模板引擎生成的网站,在 LoginController 层的注册方法中首先得到 userservice 的注册方法返回的 map,如果 map 为空说明成功注册,返回一个说明注册已成功,且过几秒会跳转到首页的网站模板路径(其中要将动态值(mas:注册成功,我们已经向您的邮箱发送了一封邮件,请尽快激活;跳转的网页目标:首页路径)加入进模板),如果失败在 model 中分别添加用户名,密码,邮件等的错误信息 return 注册网站的路径,其中当返回注册页面时,想要保存上次的填写信息(错误的信息),可以在模板中设置一个判断,比如返回上次的用户名填写信息,先判断 user 是否为空,若不为空则填入 nsername,错误时有 is-invalid 标志。
3.激活注册账号:不用编写 dao 层,已经在数据库中有了,只是没有激活,在 UserService 层:
编写激活方法(参数为 userId,激活码 code),通过 userId 查到 user 对象,判断 user 对象的状态(status)若为 1 则说明已经激活过,返回 2 为重复激活,如果激活码与传入激活码一样则先将用户状态改为 1,返回 0 成功激活,否则(激活码不对)返回 1 激活失败,在LoginController 层处理请求,路径为网址,方法参数为 model,userId(通过@PathVariable 得到路径中对应的 userId 值(被{}括住,且名字相同),code 值(激活码,获取方法同上)),返回的是跳转模板的路径,调用 service 的激活方法赋给 result,判断 result 的值,若激活成功,要将动态值(mas:激活成功,您的账号已经可以正常使用;跳转的网页目标:登陆页面路径)加入进 model,若重复激活,将动态值 mas:无效操作,该账号已经激活过了;跳转的网页目标:登陆页面路径加入进 model,若激活失败,将动态值(mas:激活失败,您提供的激活码不正确;跳转的网页目标:首页路径)加入进 model。
9.账号设置
开发步骤:访问账号设置页面、上传头像、获取头像。
1.上传头像:通过 MultipartFile 来处理获得用户上传数据,判断是否为空等,在 controller 层来处理,调用 service 层来 update 用户(通过 ThreadLocal 借助 cookie 来获得具体是哪一个用户)的头像地址(web 访问路径,非本地访问地址)(经过随机处理更改后的文件名称,用subString 来获取文件后缀,拼接文件名称)
2.获取头像:在 controller 层,通过请求路径可以得到用户头像的文件名称,获得服务器存放
地址,通过字节输入流得到图片文件,字节输出流输出。
第三章
10.过滤敏感词

和算法相关,创建一个敏感词树(多叉),将每个敏感词的第一个字符(不重复)记入根节点的子节点 ,敏感词最后一个字符记上标记,在检查敏感词时,一个指针指向敏感词字符查到的位置,两个指针指向字符串(需要过滤敏感词的文本),一个指向敏感词头部(不是就往后移动一位),一个指向需要匹配的字符。

11.发布帖子
通过异步请求 AJAX(不刷新页面、局部刷新得到想要得到的东西,和消息队列中的异步不太 一 样 ) 来 发 送 帖 子 , 如 下 图 所示。

主页没有刷新,但在主页的基础上,加了一个发布的页面,这个功能可以通过 jQuery 来实现,那在 response 中就不能返回一个页面了,否则会跳转,jQuery 在前端,也需要一些信息传入,但不能和模板中传入 model 来实现,所以可以通过 json 来做信息传入,在 response 中返回一个 jQuery 可以解析成 json 对象的字符串(前面在 response 中只返回了字符串(应该,没回去验证),感觉 response中只能返回字符串(可以代表 html 页面)),取出相应的值。

2.导入 fastjson jar 包

获得 json 字符串方法,传入编码(404 类似),提示信息(成功与否),业务数据在 dao 层插入帖子接口,链接数据库,写 sql 语句在 service 层判断帖子若为空抛出异常,运用 spring 工具 HtmlUtils 转义主题和内容(防止有标签等,执行了标签(语句)),过滤敏感词(主题)(内容)
在 controller 层首先获得当前用户(ThreadLocal),如果为空则 return 一个 jQuery 可以将其转换为 json 的字符串,其余 语句都差不多。

12.事务管理

乐观锁:先运行相应的代码,在提交前判断是否在这个期间版本号更新过,若更新则取消本次的更新 spring 引以为傲的地方,任何数据库都可以用这套事务管理,不管是关系型还是非关系型。


通过注解,声明事务,spring 通过@Transactional(隔离级别,传播方式)来实现方法的事务,将一整个方法作为一个事务,事务传播方式是在 a事务调用 b 事务的情况下引出的理念,由于最后一行代码运行错误,所以事务回滚。
通过编程管理事务:

通 过 transactionTemplate 对 象 来 实 现 , spring 自 动 装 配.

直接注入就可以,通过前两行设置隔离级别和传播机制,在 execute 方法中传入TransactionCallback接口类型对象,其中接口中的 doInTransactioon 方法是需要添加进事务的代码,如下图:

13.添加评论
在添加评论时,需要向评论表中添加一个评论数据,而帖子表还有一个评论数量的属性,在添加评论时要更新对应帖子对象的此属性,两者应一同完成,所以用事务写在一起。
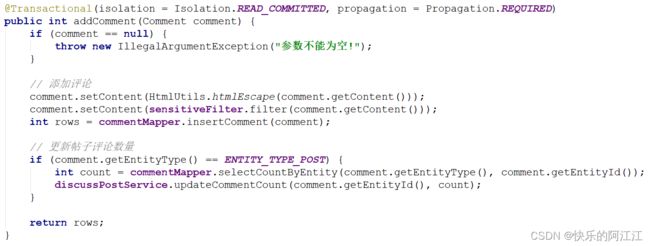
14.发送列表
Dao 层

传入集合 mybatis 的操作:

Service 层

Controller 层:返回 json 格式,因为要异步

第四章
15. redis
redis 的事务不会像关系型数据库那样执行,关系型数据库是要么都执行,要么都不执行,而 redis 的事务是在启用事务以后,在执行 redis 命令时不会立刻执行,会将其加到一个队列里,当提交事务时,会将这个队列传给 redis 命令一起执行,再将执行结果返回,你的命令相当于读取已提交,你读未提交的数据是不行的,在事务中所有命令运行时读取的参数都是事务开始之前的。

运行结果:

和 mysql 的编程式事务相似,都是通过实现接口的内部类实现,但 redis 在里面标注了事务开始行(multi)和事务结束行(exec)。
16. 点赞
因为可能同时有很多人给同一个人点 赞,所对性能要求较高 ,用redis来存储。

Service 层


第三个方法是为了在帖子详情页里判断按钮的显示状态,若点赞 1 则显示已赞,若未赞 0则显示赞,点赞是在帖子详情页里点击赞/已赞按钮的动作,传入给 redis 的值为 set 格式,因为可能后期我们需要查询都有哪些用户给此贴点过赞 ,查询数量在主页和帖子详情页里都有用到,在主页浏览时显示每一个帖子的已赞数量,在帖子详情页里的点赞按钮包括点赞数量。
由于点赞的操作在帖子详情页里只是点赞按钮这块局部刷新,所以我们在 controller 层编写响应体时返回 json 格式的字符串,将点赞的数量和状态传入 map 中,将 map 转为 json 格式的字符串。

如何获得到参数:网页通过调用 JavaScript 方法

由于在主页显示每个帖子的点赞数量是直接在返回的网页上显示的,所以我们在主页的控制层调用点赞的服务层,获取点赞数量,传给 model 使其在网页上显示,(注意:主页不能点赞,只能查看赞的数量)。
帖子的控制层:帖子的点赞数量与上述同理,且要多给 model 传入一个点赞状态,评论(评论是列表,列表通过 map 记录着每个评论的 userID 和内容)的点赞数量,同理,但是要将其传入给 map 中而不是 model,因为评论列表会传给 model,回复列表同理。
17. 关注、取消关注

右边蓝色按钮,关注 ta 是个异步请求,在 controller 层要返回 json 格式,关注 ta 是双向的,点击关注,需要对关注了加一,被关注的关注者减一,由于关注的操作也是很频繁,对性能的要求高,所以用 redis,在 redis 中关注了和关注者分别是两个键,为了以后的操作用 zset存储,其中分数为当前时间(关注时间),便于排序,所以在 service 层关注:关注加一,被关注的关注者加一,用事务写在一起,为了解耦,在 controller 层的 json 只传出状态码和是否关注的信息,对于有多少暂不处理,另在 service 写一个方法查询关注数量和关注者数量将其传入给 controller,controller 中加入 model,使其显示课程中关注方法和取消关注方法写了两个,在前端通过按钮状态(关注 ta/已关注)来调用我的想法是和点赞的逻辑差不多在 service 层写关注方法时,先判断此用户在不在关注列表中,若在就是取消关注的编码,若不在就是关注的编码,前端在获取 json 对象后,判断是关注 1,还是取消关注 0,在给页面传入相应的按钮(可能课程是为了体验下两种方法?)
18. 关注列表、粉丝列表
需要开发的功能:

点击关注了几人能返回一个页面,页面有关注的列表,像下图

要实现分页功能,此页面的动态有“关注的人”和“关注他的人” (可以通过请求路径获取),下边的粉丝列表(通过路径获取到该用户的 id,通过 id 在 redis 里通过 key 查询此用户的粉丝 zset),粉丝列表要有每个粉丝的 user 对象,关注时间(zset 的分数是通过关注时间算的,可以用分数来获取),关注/取消关注的按钮实现(上一节已实现具体查看关注、取消关注的文档),这些是要在点击关注几人都通过 moddle 传入给模板的(除关注按钮外)。
Service 层:查询某用户关注的人(查询某用户的粉丝同理)首先通过 redis 的 key 获取到该用户的关注的人的 set 集合(redis 实现了 set 接口但并不是无序,又进行了相应的处理),因为要分页(一般分页方法的返回值为 list),所以获取的范围
为当前页面起始的第一个数据,和最后一个数据,由于页面要关注时间、关注的用户所以将其传入 map 中,将 map 加入列表。

Controller 层:
为了防止恶意攻击,首先要判断当前路径的用户 id 是否存在(调用 user 表获取此用户),若不是,抛出异常;调用 service 层的上面的方法,将用户的 id,页面的起始行,截止行传入,为了复用路径要将页面的路径传入给页面,以及总行数和限制数,至于是第几页这个在前端会传入过来,改变 page 对象的 current,你当前可能是查看其它用户的关注列表,如果你也想关注这个用户关注的人,是通过按钮来实现的,这就需要判断你是否已经关注过,所以要将列表中的 map 继续添加一个是否关注信息(便于按钮显示关注 TA/已关注)


关于疑惑????
总感觉课程讲错了,判断是否关注不应该是判断当前用户是否关注么,但课程里是判断访问的用户是否关注,那你当前用户访问一个用户关注列表,按照课程逻辑,你的按钮永远是已关注的状态,但你当前用户是否关注是不知道的,感觉应该改一下。
19.我收到的赞
一种方式是可以通过需要查找的 id 的帖子,将他全部的帖子获得的赞加一起,比较麻烦,另一种是新建一个 redis 的 key,每点一次赞,这个 key 对应的 value 就加一在 service 层,给帖子点赞和用户获得的赞的数量加一应加在一个事务里,在获取点赞的被赞者,可以通过帖子的 id 去数据库获取到被赞者的 id,因为你点赞一定要有点赞人,点赞
的帖子类型,帖子 id,但去数据库查的话,会降低性能,不如直接通过详情页面传过来。
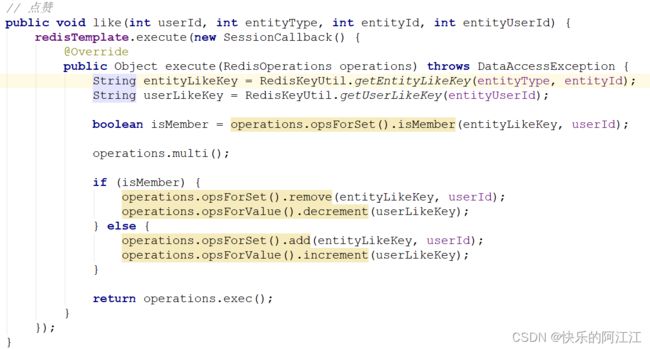
如果赞过就讲此用户 id移出 set,用户获得的赞减一;不在就将用户 id add 进 set,用户获得的赞加一。

通过点击头像查询个人主页,为防止有人恶意攻击,传递一个没有的用户,需要先判断用户是否为空,若为空,抛出异常。
20.优化登录模块

上面的一些难懂地方的解释:将验证码存入缓存,在检查时不用查询本地 session,直接查询缓存,和缓存中的数据能对应,就通过;在网页头部每次请求都会查询用户的登录凭证,已显示用户登录后的网页头部,或没登录的头部,访问频率非常高;处理每次请求,只要是用到的用户都会存入缓存中,可能是方便点击用户头像来得到用户页面信息,但我觉得只用将自己登陆的用户存入缓存中就好了,因为可能更改头像等自己的用户信息,以及很多其他对自身的操作,你改不了别人的,将其他用到的用户放入缓存就有点多此一举了,因为其他
用户的访问没那么频繁,存入缓存也需要访问数据库,从数据库中取,还要写入缓存,更加耗时(个人理解,那要是这样就不用对 user 类更改操作方法等,只需在 hostLocal 中封装一下,每次调用先查询,没有就写入缓存)
课程中的具体操作:
验证码:

先设置 redis 中的 key,验证码将各个用户的区别开,但由于还未登陆,不能用用户的 id 区分,可以设置一个 owner 字符串,在获取验证码时,随机生成一个 owner 字符串,将其通过 cookie 传入给用户浏览器端,当你点击登录需要验证验证码是否正确时,将 cookie 传给服务端。
Controller 层,在获取验证码时的更改:

通过 uuid 工具类生成随机字符串KaptchaOwner,传给 cookie,设置 cookie 的有效范围为项目内有效,60s,将验证码传入 redis 中。
检查验证码操作:
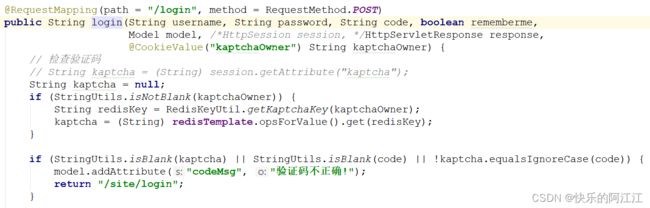
首先判断当前验证码 kaptachaOwner 的 key 对应的 value 是否为空,因为你的 key 是通过他来算的,他又是通过 cookie 来传入,若时间过期就直接返回验证码不正确(验证码的时间限制),之后在判断验证码是否正确。
使用 redis 存储登录凭证(登录凭证不删除,因为后期可能统计,比如一年你登录了多少天等):
设置 key 对应的名称:

UserService 层生成登录凭证:

实体类不用改,只是在加入的时候,不再传给数据库了,传给 redis,也是对应的 string 类型的,因为 redis 会将其自动转化为 json 格式。

比如在更改登录状态时,取出 key 对应的 value 可以强转缓存用户数据:也是 string 格式,同上,在获取时可以强转为对应的类型(删除删的是 key)。

数据变更时先删除缓存,在将缓存初始化比如查询方法:

先从缓存中取,没有在初始化更新的时候只需删除缓存即可,在查询的时候才可能会写入缓存(对应的 key 未找到)如下图,先更改,再删除。

第五章
21. kafka启动
先进入
D:\work\kafka_2.12-2.2.0
目录
启动 zookeeper:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
启动kafka:
bin\windows\kafka-server-start.bat config\server.properties
新建topic(区域)
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic testkafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
查看对应主机的topic
kafka-topics.bat --list --bootstrap-server localhost:9092
进入生产者,准备生成消息
kafka-console-producer.bat --broker-list localhost:9092 --topic test
进入消费者,准备消费消息
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
21. kafka

高吞吐量:能处理 tb级别的海量数据,是他的能力。
消息持久化,将消息传入硬盘里,硬盘便宜,空间大,处理海量数据的前提(要先有海量数据)虽在硬盘中,但并不是说在硬盘的读取就一点慢了,kafka 的硬盘读取仍然很快,他是通过硬盘的顺序读取,而非随机读取,随机慢,但顺序读取甚至能快过内存,这两点保证了高吞吐量,海量数据,速度快
高可靠:通过分布式保证。
高扩展:集群不够了,加一台服务器。
Broker:一个服务器成为一个 broker。
Zookeeper:用于管理集群,单独按一个 zookeeper 或 kafka 内置里也有。
Topic:主题,消息队列的实现方式有两种:一种是点对点,阻塞队列就是点对点,每个数据被一个消费者消费;发布订阅模式:生产者将消息放到每一个位置,可以有很多消费者同时订阅消息,这个消息可以被多个消费者读到(同时或先后),kafka 用的第二种发布订阅消息,生产者将消息发送到的位置就是 topic。
Partition:分区,对主题的位置分区,增强并发和服务器处理,又将主题分区,可以采用多线程的方式,同时向多个分区写数据,增强并发能力,每个分区按从前往后向里追加写入数据。
Offset:消息在分区内的索引副本,因为 kafka 是分布式消息引擎,为了让数据更可靠,将数据存放多份。
Leader Replica:主副本,能力较强,当你从分区读数据时,主副本可以做出响应。
Follower Replica:从副本,只用来存放数据,当主副本挂掉,集群会从 从副本中选一个作为 leader。

22. kafka应用实例


第一个类是生产者,第二个是消费者,消费者被动的接收名为 test 的消息。
测试:

在接收消息的时候有延迟,所以要阻塞一会。
23. 发送系统通知
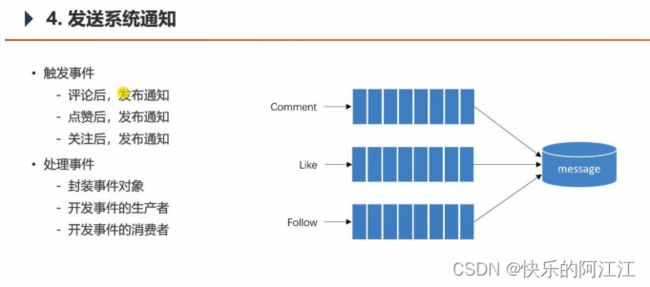
发布通知将消息添加到 message 表(两用户之间消息对话的那个表)里,消费事件的处理方式是将事件放到数据库。

创建事件类:

其中 set 方法的返回值改为 this 对象,这样可以一直 set,比如 setId().setTopic()事件生产者类:其中发送事件发送的是事件对象(将其转为 json 格式的字符串发送)

事件消费者类:由于点赞、关注、回复的消息处理差不多。

所以将评论、点赞、关注通过一个方法处理事件。

事件的处理就是将此事件传给数据库,其中内容是 json 字符串因为后续显示还要处理评论的 controller 层。

在评论后触发事件,发送消息给消费者,消费者添加数据库。
为什么要用消息队列:
在触发事件之后,此方法就可继续向下执行,消费者会新建一个线程进行操作,可以提高性能,处理效率高(异步)当此贴是个热帖时:评论的人非常高,你可以消息队列攒着慢慢处理(削峰)调用生产者的 send 不用注入消息表的 service,消费者调用就可以,比如点赞、评论、关注
如果不用消息队列则每个对应的 controller 都要注入消息表的 service,但用了消息队列,只用消费者类里注入消息表的 service 就可以(解耦)。
24. 显示系统通知
要实现两个页面。
1.第一个页面:
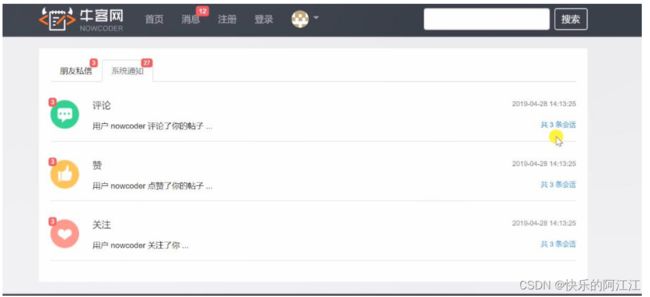
第二个页面:点击上个页面后进入的相应页面,有三个,但在消息控制层都是都是同一个实现方法.

(通过路径将其类型传入进来,根据类型)

首先第一个页面:通过点击消息进入,get 请求,需要传给 model 的有评论、关注、点赞的最新消息,每个主题共有多少消息,以及这三个主题的未读消息数量(页面头部的未读消息通过拦截器处理,具体逻辑在最后),在消息的 dao 层需要新加查询方法:相应的主题的最新的数据、相应的主题列中 state 等于未读的状态总数(state 在列表中通过数字存储),以及不传入主题,返回总未读消息:对应的 xml 具体实现。

Controller 层通过调用 service 层的方法得到对应主题最新的消息
由于在消息表中,这类的消息都是通过消息队列传进来的,它对应的内容都是 json 格式字符串,且内容在存入数据库时,会将其进行转义(语法啥的不执行,变成字符串,但这个字符 串 是 将 原 内 容 中 可 能 执 行 的 方 法 改 为 其 他 的 字 符。所以需要进行反转义,再将其从 json 格式的字符串变为相应的 map 对象(消息队列传入时是将内容变为 map 后改为 json),将同一个消息以及其中通过内容的 map 的得到的 entityType、entityId等传入给同一个 map(新的),将此 map 传给 model。

其余两个和他操作差不多,但最后的传给 model 的变量名不同(比如下面的查询点赞类通知),且都写在一个响应中,因为你返回的页面点赞评论关注都需要这几个数据,

2.第二个页面:
查询某个主题所包含的通知列表

Controller:点击评论、点赞、关注得到相应的详情数据页面,是三个请求,但我们可以在编写的时候将路径改为动态的,通过前端传过来 topic,在查询时查询相应的主题就可以。
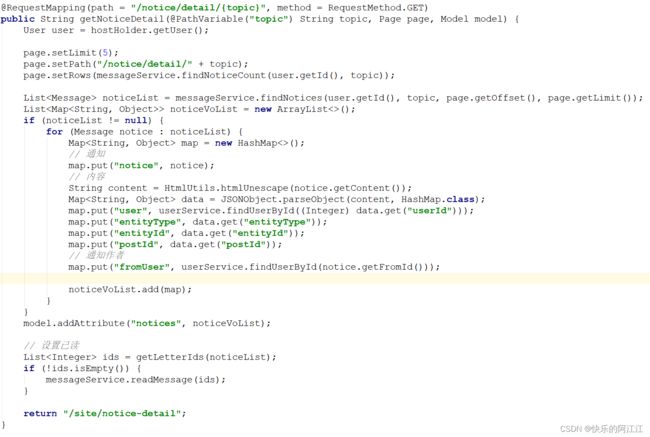
在将内容传给模板后,把数据通过消息服务层改变状态为已读。
25. 阻塞队列

生产者与消费者线程共用一个阻塞队列,若没有阻塞队列的话,生产者可能会不管消费者的消费能力,一直生产,但消费者消费不了这么多,生产者会占用资源;也有可能消费者会不管生产者的生产能力,一直消费,但取到的东西都是 null,也会占用资源
下图中两个线程共用一个 BlockingQueue,通过 queue.put()和 queue.take()来生产和消费,将相应资源从阻塞队列中加入或取出。



第六章
26.es启动
打开文件D:\work\elasticsearch-6.4.3\bin
启动 elasticsearch.bat
26.es入门
要想搜索数据,先在数据库中存一份。
索引:对应数据库中的一个库。
类型:对应一张表。
文档:对应数据库表中的一行(通常 json 格式)(6.0 规定为固定的名字_doc)。
字段:表中的一列(json 格式中的每一个属性)。
6.0 以后废弃了类型的概念,用索引来代替。
节点:集群中的一台服务器。
分片:将一个索引拆分成多个分片存储,提高其并发能力。
副本:分片的备份,提高可用性。
在用搜索引擎搜索时,会先将搜索的内容进行分词,将一句话拆成多个独立的单词,通过搜索独立单词后的数据,合并后返回给客户端,搜索分词通过 git 下载因为 es 支持用 http 请求访问,所以我们可以通过网页来添加数据(比较方便)现成的哇网页:https://www.getpostman.com
通过命令行来访问 es:分别是获取健康状况、查看节点、查询索引、创建索引名为 test,删除索引。
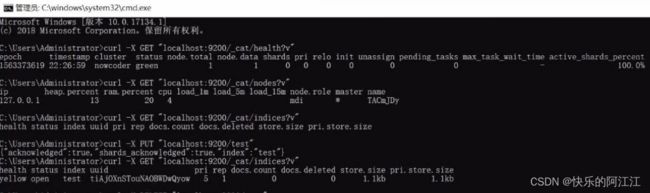
向索引中添加数据:提交数据用 put 请求,put 后边的 url 格式为服务器地址/索引名称/文档。
名称/数据 id,在下边的框中写请求体,将要添加的数据用 json 格式写入,如果用命令行来添加数据会很麻烦。

数据库也可以提供搜索,但是他是通过特定的列来查找,可用户在搜索时输入的可不是你这某个列所包含的,输入的东西可能包含多个列也可能是一个,要通过分词全文匹配,这是数据库不能实现的,而搜索引擎可以搜索示例:
在一个字段(title)中搜索
![]()
不在一个字段中搜索:
则需要在请求体中输入需要查询的内容,以及查询的字段,选择 json 格式,比如下图,在 get请求中的 url 中输入输入器地址,索引以及明确是 search,在请求体中输入要查询内容:互联网,以及查询的字段:title、content。
![]()
27.spring整合es
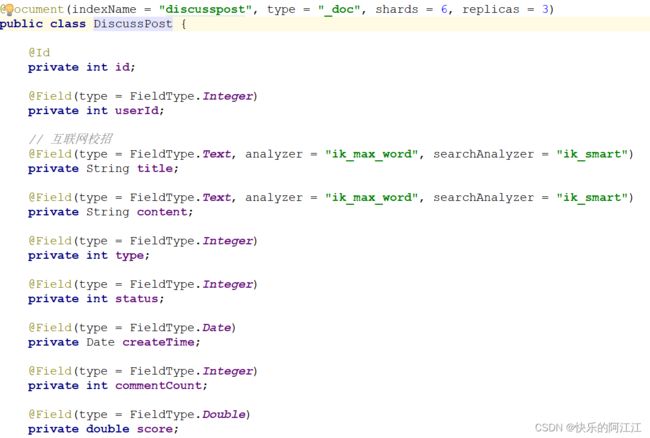
导入 maven 依赖

直接在实体类中通过注解来确定索引,类型,分片个数,副本个数,在每一个属性上添加字段注解,其中在搜索时可能搜索一部分的字段,要加上分词,分别是存入数据时的分词(尽可能分的细一些)和搜索时的分词(选择智能的那个)
Dao 层:继承父接口 EsRepository 接口,其中父接口已经事先定义好了增删改查功能,后面泛型是你存入库中的数据类型和主键,spring 会自动实现。

在向 es 中存入数据时,要先通过数据库取出数据(查询),之后通过 es 的 dao 层的 save 方法向 es 添加数据(可以一次加一条,也可以一次加多条)
这个例子中实际上在加入时是没有 discusspost 索引的,是在有数据加入时,自动创建的此索引。

![]()
这个意思是查询 userid 为 101 的数据,从第 0 条开始,共查询 100 条,返回的应该是个 list列表(我记着是)对 es 中的数据更改:先更改数据库中相应帖子的内容,在将此帖子加入到 es 的库中,覆盖上一次的

搜索 es 中的数据:
首先定义搜索查询返回的格式 SearchQuery: 对查询哪些字段(title、content)的哪一个分词(互联网寒冬)进行的设置?查询后的结果根据哪些字段如何进行排序(帖子类型,加精所对应的分数,创建时间(全是倒叙),越先运行,排序的优先级越高)?查询的分页从第几页开始,一页有多少数据(第零页,十条)?在哪个字段的分词处设置高亮?(也就是给查询的分词前后设置标签)

查询后返回的是分页的数据,这个类型是 spring 自身的,不是自己写的,这个 page 里面存了多个帖子实体,可以看成一个集合,输出(sout)的是共有多少数据匹配,共有多少页,当前是第几页,每页最多显示多少数据,输出每一个数据。

但这样获取到的 page 数据对象,是没有添加过高亮的数据,还是原始的,通过下面方法可以获得到调过高亮后的数据:



上面第一个:可以访问到es,但操作繁琐,目前只有调试高亮时用到。
上面第二个:可以访问到es,操作简单,大多数都用的他(dicusspost继承的他),但只能返回维挑高亮前的数据。
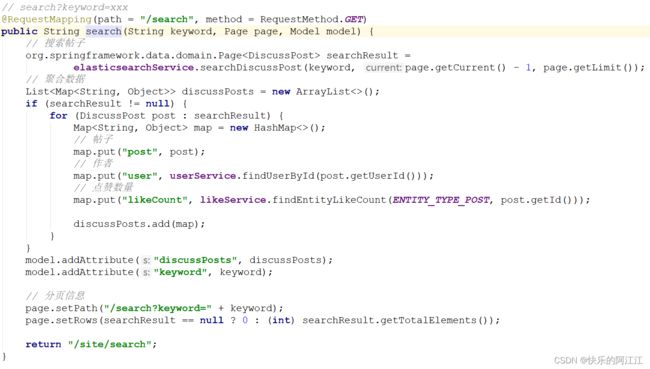
28.开发社区搜索功能

搜索的服务层(dao 层上节课已经实现是通过继承 esRepository 接口):
增删方法:

搜索方法(和上节课的搜索实现代码几乎相同,只不过将上节课的互联网寒冬全部改为keyword 参数,其余不变):


发布事件:发表帖子后会先上传给数据库,之后需要将此帖子的数据加到 es 中,否则搜索不到(不传给 es 的话只能从主页中一页一页查),这里通过消息队列将帖子异步给 es,提高效率,直接用以前的 event 类就好(刚开始还想着为什么不再另创建一个新的事件类型,旧的事件类型只有一些类型和 id,es 也得不到帖子,原来消费消息时直接用帖子的服务层通过帖子 id 就能得到完整的帖子)

给帖子添加评论也要触发发帖事件,因为发布评论后,评论的数量变了,在页面搜索时,得
到相应的帖子会显示评论数量,而这个相应的帖子是你通过 es 查出来的,所以添加评论 es
中相应的帖子也要更改
消费事件:
先通过帖子服务层从数据库中获取,之后通过 es 服务层把数据传给 es


显示结果:
由于搜索帖子属于 get 请求所以想要获得 keyword(搜索的关键字),只能通过路径或者说下图中的第一行那种路径后面带?号的方式获取,这里选择带?号,页面显示中需要帖子、点赞数量,帖子的作者三个对象(因为帖子中只有帖子的主题、内容、创建时间、作者 id 等信息,并没有点赞数量,点赞数量在缓存中,不能通过帖子获取,而搜索时要显示点赞数量,而且还要返回作者的头像,所以也要帖子的作者对象)
将搜索的关键词传给模板可能是想在搜索完后的搜索框中显示上次搜索的关键词。
第七章
29.初识Security
对系统提供安全性的保障,主要是管理系统用户的权限,管理权限主要(核心)从两方面入手认证和授权,认证:判断用户是否登录,如果未登录不可能去访问私信,发帖等功能(相当于以前的登录表单(cookis、threadlocal 那个));授权:认证后的进一步判断,判断是否有访问此功能的权限,比如给帖子的加精、置顶等,这些都需要高级别的权限(管理员、版主),授权主要为了判断当前用户是否有访问这个功能的权限,这些都可以通过 security 来实现。

Spring security 底层的大概机制:spring MVC 会将请求统一在 dispatcherServlet 进行处理,之后将请求传给控制器,可能会有拦截器进行拦截,dispatcherServlet 实现了 javaEE 的 servlet接口,filter 过滤器会拦截对 servlet 的请求,security 的底层会利用 filter 来实现系统安全,权限控制的判断时机较为靠前,在请求还未到 dispatcherServlet 。
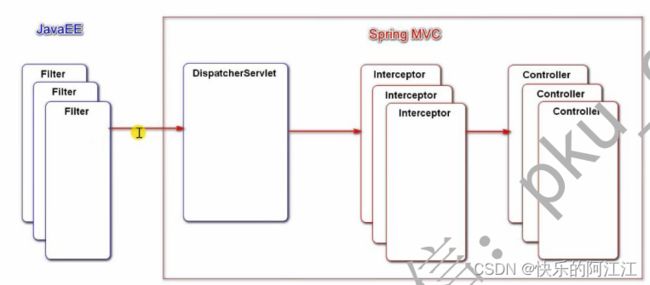
User 实体类要实现 userDetails 接口,实现接口中的方法:账号是否过期、账号是否锁定、凭证未过期、账号是否可用、获取用户权限(返回的是权限集合,一个元素是一个权限)

Userservice 实现 userDetailsService 接口,实现方法:根据用户名查用户配置 security 配置类(security 不需要每个功能都去实现一遍,直接在配置类中实现即可):要继承 webSecurityConfigurerAdapter,需要注入 userServiceDetails 的实现类,因为其底层需要首先需要重写的方法是拦截忽略哪些路径,视频中忽略了静态资源下的路径。

认证:supports 是为了判断支持哪种类型的认证,因为可能是微信二维码那种类型,咱们的是输入账号密码类型。

授权逻辑(感觉一个逻辑是一个 filter):
登陆的逻辑:
登录页面也是一种授权,授权你可以访问登录后的网站信息,首先要获取到登录的路径(request),之后才能通过认证的想过逻辑判断是否给你授权,所以还需要写成功的逻辑和失败的逻辑(配置器),成功后重定向到首页路径,让你访问首页;失败则回到登录页面,但想要把本次的错误信息也给到登录页面,就不能重定向了,因为你重定向后相当于
是一个新的请求,但你的错误信息是在本次请求逻辑中的,下次请求是得不到的,需要传参,所以需要通过转发请求给登录页面路径
退出的逻辑:
直接在成功的配置器中重定向到首页。授权配置:获取私信的路径,之后设置普通用户和管理员可以访问获取管理(置顶、加精)的路径,设置管理员可以访问(若通过则可以去访问这个路径,进入到控制层相应的返回体中)权限不匹配的返回路径(需要在控制层另外设置返回体)
因为 security 在用户登录验证的 filter 中没有处理验证码的 filter,所以要新增一个 filter,通过 if 来控制拦截请求的范围,如果验证码错误直接 return,如果通过或者不是登陆请求,继续执行下一步操作(可能传给另一个 filter 也可能是 servlet。

在控制层:
认证成功后会将结果(账户名、密码)通过 SecurityContextHolder 存入 SecurityContext中,想要获取直接调用就可以例如:登陆请求(security 已经判断过用户名密码是否正确,不用像以前一样再判断一遍账户密码,直接获取就好)

30.讲文件上传至云服务器

选用免费的七牛云服务器,从 maven 中导入七牛云的包
AK:标识用户身份(使用者才有权限往云服务器中存入数据),SK:为数据内容加密将头像上传至云服务器(客户端上传):需要将上传凭证传给表单,使用户在表单上点击提交时可以将相应的数据传给七牛云云服务器,其中设置响应信息可以设置为网页也可以设置为 json 字符串,一般选用字符串,因为这个是七牛云给返回的,如果选择返回网页的话,
太乱了,会让客户感觉到,一会是我们自己的网站,一会又是七牛云的,不太好,响应信息的意思是你提交成功后,给你返回的提示。

更新头像路径:在用户上传了新的头像后,需要将此用户的头像路径更改,更改的路径为你云服务器的路径+文件名称。
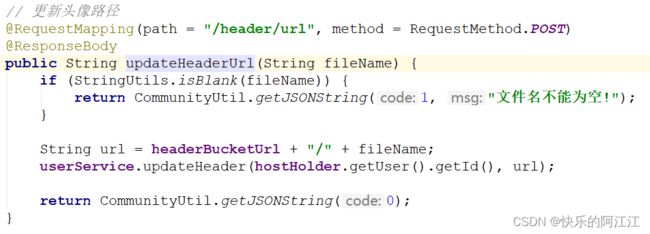
注意:前面只是说了给表单一个上传凭证和更新头像路径,那上传头像的操作在哪呢?这在后端是没有的,需要在前端的 js(首先在提交表单时将头像上传至云服务器,之后调用controller 层的更新头像路径方法,再刷新网站,使得新的头像能被显示出来)里设置。
分享(服务端直传):我们在将分享的图片存入本地时,用的是消息队列来处理生成需要分享的图片,上传至云服务器同样用消息队列,而且仍然需要上节课的 wk 工具在本地生成一个需要分享的图片,之后将这个图片再去传给云服务器,需要注意的点是,在用 wk 生成图片时,我们是调用底层系统令启线程来执行的 wk 命令生成分享图片,现在需要在 wk 生成分享图片后,将这个图片传给云服务器,在服务器直传时,不能像客户端上传一样,通过前端给云服务器上传而是需要在后端手动处理,那现在就有一个问题,不能知道什么时候这个线程执行完毕生成分享图片,所以需要启动一个定时任务来将这个分享的图片传给云服务器,定时查看这个线程是否执行完毕,如果执行完毕则将生成的图片传给云服务器,这里的定时任务没有用 quartz 而是用的 spring 的定时任务线程池,这是因为消息队列消费者在运行的时候已经确保了同一事件只能有一个服务器来访问,拥有有抢占机制,不会造成多台服务器去消费一个事件,执行同一件事情,而造成问题,而且你如果用 quartz 的话,在配置好之后,过了对应的延迟时间,就会立即执行,那你现在如果还没有需要将分享图片上传值云服务器的需求,也是问题,在启动上传至云服务器的线程时,如果上传云服务器失败不能一直让这个线程执行着,所以在上传云服务器三次未成功(可能是网络原因,也可能是云服务器的原因),或者超过了 30s(几乎和生成分享图片的线程一起执行,但分享图片的线程执行完毕(生成了图片)用不到 3s,所以时间是足够的,剩余的时间是为了防止上传至云服务器失败,让其多上传几次,而且上传也需要时间,这些总的加起来 30s 够用)就让这个线程停止运行,停止运行用了线程的future.cancel 方法。
判断线程是否停止(略):上传服务器三次未成功(每失败一次则对应的参数加一),超过30s(在线程启动时通过参数将现在时间记录,每运行一次线程则判断一次,当前时间与该参数的差值)
将图片上传至云服务器:处理响应结果就是或许到响应信息.

获取分享图片看上一个总结.
31.权限控制

在 security 的配置类中设置授权,三个方法分别是:设置需要授权的路径、访问所需要的身份、其他路径不需要授权的统一设置。
下图都在SecurityConfig中。

权限不够时的处理:如果访问一个功能,权限不足,不能直接就是无法访问,也需要处理,在没有登录时,首先需要判断你所访问的功能是需要异步返回 json 字符串还是页面,要对应上,若是异步,则返回一个 json 字符串状态码为 403,错误信息是你还没有登录;若是需要返回页面,则返回到登录页面,让其登录(将以前的用拦截器检查是否登录改为了用security 检查)

若权限不足,比如你普通用户访问了管理员才能访问的功能,同样也需要判断返回的格式是json 还是页面,若为 json 则返回 403 状态码,信息为你没有访问此功能的权限,若为页面则返回一个 404 页面。


Security 底层默认会拦截退出请求,直接进行退出,而不走我们自己写的退出代码,因为security 是通过 filter 进行拦截的,拦截较为靠前,security 默认的退出路径为/logout,可以给 security 传一个假的退出路径,这样就不会拦截我们的退出请求。

我们绕过了 security 的认证,但 security 的认证会将信息(用户、权限等等)传给 securityContent对象,供 security 使用,我们想用 security 来授权就需要知道每个用户的权限是什么,所以需要给 security 传入用户的权限首先需要在 userService 中写一个查询用户权限的方法,而且需要符合 security 的格式,将其所拥有的权限加入到集合中。
下图在userService 。

在检查登录凭证的拦截器(intercepter)中通过调用 userService 的查询权限方法将权限传给security(请求结束和退出程序后将其清理掉,节省空间)
下图在LoginTicketInterceptor文件

csrf 攻击:在 post 请求时服务器给客户端一个表单,供其填写数据写入服务器,但 cookies在用户端并不安全,可能会被非法网站窃取到,之后通过这个 cookie 提交数据给服务器,如果涉及到金额问题,甚至有可能将钱划走(网上购买物品时,非法获取到 cookie,去买自己商铺的商品???这样是两个表单,一个是你要买的物品付款表单,一个是非法的物品购买表单,tocken 不同,非法的失败(不知道这样理解对不对)),所以 security 在给你表单的时候还会给你一个 tocken,每个表单都不一样,在提交时会判断 cookie 和 tocken,若不符合,则判断为 csrf 攻击,提交失败(但 security 只能在非异步请求,在返回网页时自动传一个 tocken,异步时需要咱们自己处理,前端模板上编写逻辑加入 tocken )

32.任务执行和调度

对于非定时任务,使用 jdk 的普通线程池和 spring 的普通线程池都行,但如果是定时任务,最好使用 Spring Quartz 工具来调用定时任务(也是一个线程池),因为在分布式的环境下,对于非定时任务,应该是在控制器里的,你通过负载均衡去调用这个执行这个任务,只有一个服务器执行,而定时任务,到达设置好的间隔时间,会自动执行,那在分布式的环境下,你执行的任务就重复了(服务器 1 和服务器 2 一块执行 scheduler),可能造成一定的问题,比如清理临时文件,重复的清理就会造成问题。

可以通过 quartz 来确保只有一个定时任务来执行,quartz 在执行定时任务时,会从数据库中取得所需要的任务类型,名称,以及状态等等信息,当一个线程去数据库中取得相应的定时任务信息时,会先判断状态是否为运行状态,若为运行状态,说明已经有线程在执行这个任务了,则此线程就不去处理这个任务。

Jdk 线程池:


initialDelay:线程池延时时间(在程序启动后,等待相应的时间才会执行任务)period:间隔,定时任务线程池在启动后自动执行。

Spring:配置线程参数,

(线程池创建完毕,以后就是调用这个线程池)


Spring 的定时任务线程池,在传入任务时,第二个参数不是延迟时间,改为执行的启动时间。

Spring 的线程配置类:

Spring 执行任务的方便之处:在实现 bean 注解的类里,在任意的方法上加上@Async 注解后,此方法就相当于一个任务,在调用该方法时spring 会将其通过多线程的方式启用,按照在配置文件中配置的线程池大小非定时任务:在实现 bean 注解的类里,任意方法上标注。
@Scheduled 注解,此方法就相当于一个定时任务,不用外界调用,只要有程序启动,自动执行。


非定时任务:在实现 bean 注解的类里,任意方法上标注@Scheduled 注解,此方法就相当于一个定时任务,不用外界调用,只要有程序启动,自动执行。
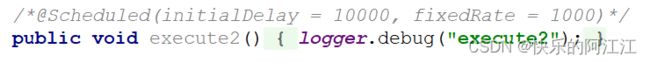
Quartz 分布式定时任务:通过 maven 导入 spring boot quarz 的包,quarz 的每一个定时任务所对应的主要的数据库表:job(所定义的任务)、JobDetail(job 的必要描述以及相关参数配置)、Trigger(触发器 job什么时候运行、以什么样的频率反复运行),第一次运行相应的任务时,quearz 会从配置的信息中读取到数据库中(立刻、自动),之后每次运行从数据库中取得相应的信息。
定时任务的逻辑:

配置 JobDetail 和 Trigger(在配置类中配置):
jobDetail 的相关配置(按顺序):任务所从属于哪一类(bean 的类型)、任务的名字、任务所在的组别、任务是否长久保存、任务是否可恢复trigger 的参数最好于对应的 jobdetail 一致,因为在有多个定时任务时,trigger 在传参时会去找与参数名一致的 jobDetail,Trigger 的相关配置:对哪个 jobDetail 进行的配置、trigger 的名字、trigger 的组名、执行频率(间隔时间)、存储 trigger 状态的对象配置完成后,在运行程序时自动执行。

删除 quartz 任务(将数据库中对应的几个表一同删除):传入的参数为任务名与任务所在的组名。

33.生成长图
分享时生成图片,相当于对整个网页截图。
通过 wkhtmltopdf 工具来实现 将对应的网站生成图片的命令 wkhtmltoimage+域名+生成图片的位置。
![]()
由于将网站生成图片所产生的图片太大,浪费空间,所以在中间加一个—quality 75 参数,意思是要存放图片的质量为原图片的 75%。

前面是在 cmd 中操作的步骤,在 java 中是:通过 Runtime.getRuntime.exec(cmd)来实现,其中下图的 cmd 字符串是在 cmd 运行这个命令时,也就是上图的执行命令敲的代码,将他以字符串的形式敲入 exec(string)的参数中,他会以并发的方式在本地的操作系统中执行这个命令。

在实际的应用中需要将上面的一些目前固定的参数写入配置文件中,以便于以后更改更改,比如在 wkhtmltoimage 中的 wkhtmltoimage 命令在哪个地方,以及生成图片的路径(和上图对着看)
为了防止存放图片的目录没有创建需要在配置类中编写,因为配置类加了@configuration 的注解会在服务启动的时候,会先加载,所以我们在配置类中创建这个目录,还需要在创建目录的方法上加@postConstruct 注解,表示初始化,这样配置类在实例化的时候会自动调用这个方法(wkImageStorage 是我们配置的图片存放目录)

由于生成图片的时间比较长,所以我们采用异步的方式,加入到消息队列中,客户端发送分享请求,随机生成文件名,发送事件给消息队列,由于没有实体类所以不传入 entity,而且在 event 中 date 是 map 格式的数据,所以传入多个值,将生成图片所需要的的 url,文件名字,以及文件格式加入 date 中,生成的图片保存在我们服务端中,不保存在客户端,我们将生成的图片在本机的路径保存下来,而且客户想要访问这个图片还需要先定位到我们的域名,将这些拼在一起,传给 json 字符串,这个请求不用返回一个网页,只需要返回体中给客户返回一个路径就好,让客户复制这个路径,去浏览器访问,得到图片。

客户在发送请求得到的效果是这样的:需要复制这个路径,继续发送请求,查看图片。

消费分享事件:


客户在获取到 json 字符串之后,想要获取图片,发送的请求:由于这个返回体是图片,不是网站也不是 json,所以需要直接调用 response。

34.网站数据统计

统计网站的独立访客与日活跃用户(本项目一天访问过一次就算),这两个感觉像是同一个意思,但独立访客只要是访问过本网站就算,包括游客访问(所以不能通过 userId 来统计数据需要通过 ip 地址),而日活跃用户只统计注册登录的用户(用 userId 来统计),所以还是有点区别,而且你的日活跃用户改下逻辑(访问过多次才算活跃用户,或特定页面),就和 uv有很大的区别了,统计 uv 时只用统计大概就好,不用过于精准,所以采用 HyperLogLog(当网站访问量大时,可以节省空间),而日活跃用户需要精准一些(感觉是便于以后奖励客户,活跃度达到一定程度就有奖励,不精准的话可能把某些活跃用户落下,造成客户缺失),用Bitmap(userId 为 Bitmap 的索引位,例如 userId 为 101,则在第 101 为设置为 true)
因为这些都是通过 redis 来操作的,所以不用写 dao 层,直接去配置对应的 key:
单日的 uv 为 uv:date 区间的 uv 为 uv:dateStart:dateEnd
单日的 dau 为 uv:date 区间 uv:dateStart:dateEnd
Service 层:
将指定的 ip 记入 uv,首先获取到当前日期对应的 key,之后将

只用范围查询,想要查询一天可以在起始日期和终止日期写成同一天,而且也没有必要再编写一个查询一天的方法,太麻烦(在前端页面还要在设计一个查询一天的表单,控制层还要再加一个查询一天的请求处理,服务层还需要编写查询一天的方法)
统计指定日期范围内的 nv:由于在合并数据时,需要传入合并数据后数据对应的 key,以及需要合并数据的 key,而合并数据的 key 是通过日期存的,我们像上节课一样,挨个传入过于麻烦(而且还要通过给起始日期加 1 来获得之后的日期,已经有循环了),所以肯定是循环遍历加入到集合中(我想的是加入到数组,长度为最后一天-起始天+1,但日期类型的加减没想出来,因为直接转为 int 的话数据太大了,浪费性能,集合不用涉及到长度问题),视频中通过 calender.gerTime().after(end)(如果 calender 日期大于 end 则为 true)来控制循环,注意在合并数据时,不能传入集合类型的 key 团体,方法规定必须是数组,所以需要转换一下,最后返回 redisKey 的 size,HyperLogLog 的 size 方法返回的是 long 类型。

将指定用户记入 Dau 和 uv 逻辑一样。
统计范围内的 dau:前半部分与 uv 一样,也是将 key 存入集合中,便于后面的操作,因为统计范围内的 dau 的话需要进行 or 运算,只要这个范围内有一天达到了活跃标准,就算 是 活 跃 用 户 , 在 进 行 or 运 算 时 也 需 要 将 每 一 个 需 要 运 算 的 key 传 入 进去。

或运算后返回的是 long 类型的数据。

因为记录 uv 和 dau 在每次请求都需要访问(HyperLogLog 有去重,Bitmap 的对应位设置为 true,重复设置也没关系),所以要将这两个方法加入到拦截器中编写 uv 和 dau 对应的拦截器。

配置拦截器:设置静态资源不用拦截。
![]()
Controller 层:
统计页面:由于只能管理员来访问,所以不用在页面另外设置统计的按钮,直接让管理员通过搜索 url 来实现。

统计网站 uv:当管理员在网面选择起始日期与截至日期后,将请求传给服务器(post),传过来的日期其实是字符串,还需要转换成为日期类型,通过@DateTimeFormat 注解可以实现,最后返回可以返回模板页面,也可以将请求转发给统计页面的请求。

统计活跃用户:

因为此功能只能管理员来访问,所以要在 security 的配置中将这些请求路径设置为管理员权限。感觉这些思路要先主要绕着 dao、service、controller 来思考,如果需要其他的东西再去调用其他配件,不能刚开始就思考来用到什么配件,想不全也费尽,不如等用到了再去调用。
35.优化网站的统计

在存储登录凭证时,不能选用本地缓存,因为假如你在本地缓存中存储了登录凭证,第一次登陆账号时,可能将登录凭证存给了服务器 1,但可能下一次访问请求,就是去服务器 2 访问的,服务器 2 的本地缓存里是没有你这个登录凭证的(可以想想以前课程中将登录凭证存给 redis,登录凭证只在 redis 中存储,不存储在数据库中),而且他也不会去访问数据库,那你这次的请求就直接被拦截器给拦截了,重定向到了登录页面本地缓存比分布式缓存的好处是,直接部署在本机上,速度快,因为分布式缓存,是存储在其他计算机上的,所以需要额外的网络开销,比本地缓存慢,但分布式缓存可以解决咱们上一条说的问题多台服务器访问数据(redis 包括服务器 1 存数据,服务器 2 访问数据):

一个服务器的数据访问顺序:首先访问本地缓存,如果没有就访问分布式缓存,还没有就访问数据库,app 访问数据库得到数据之后,会将数据传给 redis,再将数据传给本地缓存,以供下一次访问方便。分布式缓存比本地缓存的第二个好处:本地缓存占用的是服务器的空间,不能太大,比较小,所以存不下太多数据,可能你存了一个数据后,又因为空间的问题把前面的某一个数据给挤出去了(取决于你的淘汰策略,可能是存放时间,可能是使用率),这时候如果需要挤出去的这个数据就需要去 redis 中取,因为 redis 中的空间足够存下。

对主页中热门的帖子排名页进行优化:
通过存放在本地缓存优化,因为热门帖子和客户无关,每个客户看到的都是一样的(是同一个数据),你这次访问了热门帖子主页后,下次请求在同一台服务器上,就算是不同客户访问同一台服务器也能得到正确的响应,如果访问到了其他的服务器在这台服务器再存一次数据就好,本地缓存的空间够,使得性能更好;这不像是登录凭证,不同的用户去访问同一台服务器,所需要的数据不是同一个,本地缓存存不下所有用户的登录凭证。
对于为什么不将按时间顺序的主页存放在本地缓存中:因为变化的频率太快了,随时都有客户可能发布新的帖子,不固定,而热门帖子是通过定时任务,经过一定的时间间隔之后,计算分数,重新排序,在一定的时间之内(项目中设置为两个小时算一次)保持稳定不变的项目中使用的是 caffeine 当做本地缓存,可以通过 spring 整合,但不建议用 spring 整合本地缓存的工具,因为 spring 整合之后是通过一个缓存管理器去整合所有的缓存(疑问:通过依赖注入?可以设置不同的创建模式使得每次注入的都不是同一个 bean 对象啊),统一设置过期时间、缓存大小,不太合适,因为我们本地缓存不止有热门帖子,每一个缓存由于缓存的业务不同,管理缓存的逻辑也有差别。
由于缓存列表缓存的热门帖子页,每个帖子在计算分数之前都有可能改变点赞数量等内容,所以我们设置缓存的有效时间为 3 分钟,过了三分钟则清除掉这个缓存。缓存一般是在 service 层设置:将热门帖子和总行数加入缓存,由于在查询的时候,页面的最下边页码的最后一个是总页码,需要总行数这个参数,所以想要性能更好的热门帖子列表,还需要将总行数加入本地缓存中。
声明帖子列表缓存以及帖子总行数缓存:caffeine 有两种核心接口来实现缓存,这里用的是LoadingCache,通过同步的方式,有多个线程同时访问缓存里的数据,如果缓存中的数据没有,会先让线程等待,等到从数据库中得到这个数据后,再让线程执行 (好像取数据也是同步的?)

创建帖子列表本地缓存(postListCache):由于帖子列表的本地缓存只用创建一次,所以我们可以在创建 sevice 对象时,直接创建(init)帖子列表缓存,设置帖子列表缓存的最大容量(不止要将热帖的第一页加入到本地缓存中,其他的页也要加入进去),设置帖子缓存的过期时间,build 方法是解决怎么在数据库中查数据,数据的来源是哪,由于我们在存入数据时的 key 是 offset:limit,所以需要先将其分开,才能调用 dao 层的查询方法,来获取到数据库中的帖子列表。

创建帖子总行数缓存(postRowsCache):

在查询帖子列表,如果是 userid=0(查询全部用户的帖子),ordermode=1(按照热门顺序排)则返回缓存中的热门帖子数据,在调用本地缓存的 get 方法时,如果没有这个数据,本地缓存缓存热门帖子的对象会去调用数据库得到这个数据。

在调用总行数时,先查缓存中的帖子总行数:

36.置顶,加精,删除

首先在帖子的 dao 层加上更新帖子类型和状态的方法(删除时只是更改数据库中帖子的状态为拉黑)对应的 sql 语句

控制层的置顶:首先更改帖子状态为置顶,之后更改搜索引擎 es 中相应帖子的数据,通过消息队列触发发帖事件,将原帖子数据覆盖,因为置顶是个异步请求,不用返回一个页面,所以返回一个 json 字符串,状态码为零,表示置顶成功。
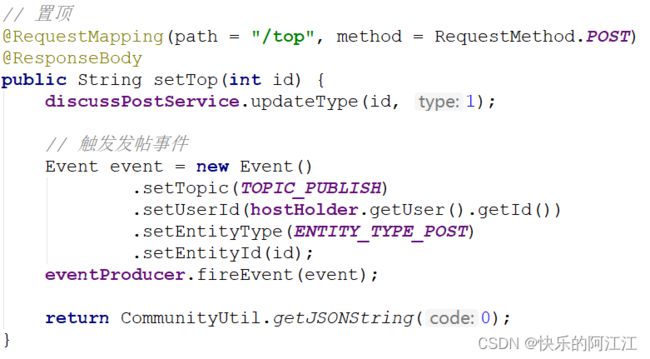
加精:与上面一个意思。

删除:触发删帖事件,在数据库中将帖子状态改为拉黑就可以了,但在 es 的库中,需要删除这个帖子对象,不让他搜索到,而且在搜索引擎中加一个搜不到的数据也没用,浪费空间。

消息队列中的消费删帖事件:触发事件时,将帖子的 id 传过来,首先判断传的对象是否为空,格式是否正确,之后通过 id 将 es 中的数据删除。

在 security 的配置文件中将置顶和加精的请求路径(antMatchers 方法)设置为版主(hasAnyAuthority 方法)可以访问,删除请求路径设置为管理员可以访问。
37.单元测试

两个每次执行一个类时只执行一次的方法:beforeClass 在类启动时执行;afterClass 在类结束时执行。

两个每次执行一个方法时都会执行一次的数据:before 在方法被执行前执行;after 在方法被执行完后执行。

测试:用的是 assert 断言类做测试(判断是否为空、两个数值是否相等)

总结:明明可以在@test 注解的方法中创建帖子,之后再调用相应的方法,为什么还要用@before@after 注解:为了下次测试方便,不用这两个注解的话,测试 test1 和 test2 需要创建两个测试用例(在一个 test 里只能测试一个方法,否则出错了不能知道是哪一个出错),用@before@after 注解可以产生只用编写一次代码,多次调用的效果,在执行 test1 方法之前,会先执行@before 创建一个测试用例,在test1 方法执行完毕后会调用@after 更改相应帖子的状态,从而达成删除的效果(删除的意义是为了防止在真正项目部署后,用户在浏览页面时,有垃圾信息(测试的帖子)),在 test2 执行时,也会和 test1 一样,执行方法前调用 before,执行方法后调用 after。
38.项目总结

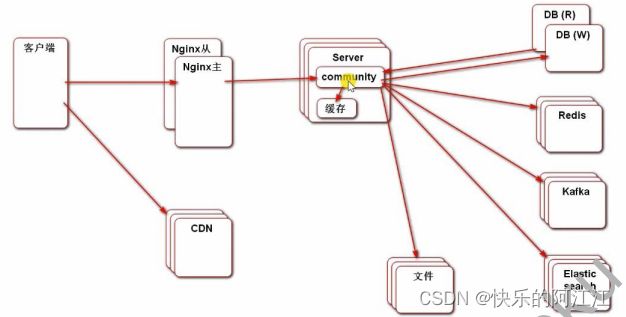
蓝色底纹是用到的技术栈,橙色是相关的功能,带下划线或者@符号的是重点在部署时的位置,其中 cdn(缓存服务)是静态资源,不和动态资源放一起,这样可以提高性能,而且静态资源放一起托付给相关的缓存服务,这个缓存服务是由其他公司来构建的,这个缓存服务由于构建的公司在全国各地都有服务器,当客户发出请求需要静态资源时,直接从距离最近的服务器上获取,速度更快,文件是咱们的七牛云服务器。
面试题
1.介绍⼀下你的项⽬是在做⼀件什么事情?有什么样的主要功能?项⽬的主要架构是什么样的,为什么要做这样的⼀个项目。
答:这是一个技术论坛的项目,主要功能有用户的登录与退出,帖子的增删改查,点赞评论关注置顶,根据热度将帖子排序,系统通知,并且还可以搜索帖子,也做了敏感词的过滤。主要就是这些功能。用到的技术栈主要有spring boot ,redis ,kafka, mysql,mybatis , Elasticsearch 等。因为我想做一个技术论坛,让大家能在我这里分享一些自己学到的技术,或者说学习的心得,相互交流共同进步。
2.权限管理是如何做的,怎么保证的每个账号的安全性?为什么考虑使⽤Spring Security,是怎么做权限管理的,讲⼀下这部分的⼯作。怎么进⾏的合法性检测,都有哪些种是不合法的,了解信息加密的⽅式吗?
答:
10、你⽤到了Cookie,那cookie和session之间有什么差别?ThreadLocal有什么作⽤,内部是怎么实现的(第二章有)
cookie和session都是用来让浏览器记住该用户身份信息的会话方式。
Session与Cookie的区别在于Session是记录在服务端的,而Cookie是记录在客户端的。
cookie:当浏览器访问服务器的时候,服务器在响应的时候会发送给浏览器一个cookie对象,浏览器就会在响应的头里有一个参数,再将cookie对象存在本地。再下一次请求的时候,在请求的头里会带着cookie去访问服务器,服务器就能通过这个cookie识别到身份信息。
扩展:cookie是存在客户端的,安全程度不一定有服务器高,所以不能存太过敏感的数据,比如密码。并且cookie每次发送到服务器,会影响性能。
session:当服务器响应网页的时候,服务器会在服务器的内存当中为该浏览器分配一个内存空间,这块内存空间就叫做session,只允许session专属于它对应的浏览器访问。
很多场景的cookie,session等数据隔离都是通过ThreadLocal去做实现的
ThreadLocal数据隔离的真相,每个线程Thread都维护了自己的threadLocals变量,所以在每个线程创建ThreadLocal的时候,实际上数据是存在自己线程Thread的threadLocals变量里面的,别人没办法拿到,从而实现了隔离。
项目部署
1.租阿里云服务器
注意点:首先修改好密码否则putty登不上去,图中的配置需要一致

2.安装putty
配置putty,输入公网ip,connection的0改成10.
获取root最高权限

3.安装需要的环境
在官网找到对应的网址,复制下来,点击右键粘贴。
安装指令:以maven为例,其他类似
wget -i -c https://dlcdn.apache.org/maven/mavee-maven-3.8.5-bin.tar.gz

4.上传本地文件
进入cmd,进入到需要上传的文件的路径。
下面是把community-init-sql.zip上传到test。
C:\Users\江如光\Desktop\项目资料\第1章 初识Spring Boot,开发社区首页\第一章素材和源码\素材>pscp community-init-sql.zip root@47.110.232.101:/root/test
5.解压上传的压缩包
先在本地库找到uzip工具,然后安装

1.安装JRE:使用yum本地命令安装
2.安装maven,配置maven的路径确保可以直接调用,更改maven的配置为阿里云镜像。
3.安装mysql,centos要对应版本,只要安装mysql-sever(服务器)。使用命令启动mysq服务。使用默认密码登录mysql,修改mysql的密码。导入sql文件,要先解压。
4.安装redis:使用yum本地命令安装,版本低但也够用,启动redis服务。
5.安装Kafka:先解压,先启动Zookeper,再启动Kafka。防止关闭窗口就停止,两个都使用后台启动方式。
6.安装elasticsearch:先解压,分词插件也要解压。更改elasticsearch配置文件:集群名字一致,数据路径和kafka保持一致,日志文件更改到需要的位置。更改elasticsearch占用jvm内存的空间,因为默认占用1g,比较大,改成512m。启动elasticsearch服务,由于不能使用root用户启动,需要使用普通用户启动。
7.安装wkhtmltopdf:使用yum本地命令安装。
8.安装虚拟机:使用yum本地命令安装,因为Linux没有界面,所以需要虚拟机,才能使用功能7生成图片。
9.安装tomcat:先解压再安装,配置tomcat的路径确保可以直接调用。启动tomcat。
10.安装nginx:nginx代理tomcat,使用yum本地命令安装,启动前需要先配置,在配置文件配置真实的服务器,再配置虚拟服务器(80端口,用户通过这个访问)。启动nginx服务。
11.部署我们的代码:写好部署专门使用的配置文件application,先压缩项目文件,然后上传解压。使用maven编译,把编译好的文件(war包)部署到tomcat的webapp里面。部署好就可以启动tomcat。
备注:内置tomcat是项目打包成jar包,外置tomcat是打包成war包。
思维导图
技术分布思维导图