Bert简介以及Huggingface-transformers使用总结
目录
- 一、 Bert模型简介
-
- 1. bert预训练过程
- 2. bert输入
- 二、Huggingface-transformers笔记
-
- 1. 安装配置
- 2. 如何使用
-
- 项目组件
- 3、数据处理Tips
-
- 1. Torch.utils模块
-
- 参考文章
一、 Bert模型简介
2018年Bert模型被谷歌提出,它在NLP的11项任务中取得了state of the art 的结果。Bert模型是由很多层Transformer结构堆叠而成,和Attention模型一样,Transformer模型中也采用了 encoer-decoder 架构。但其结构相比于Attention更加复杂,论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
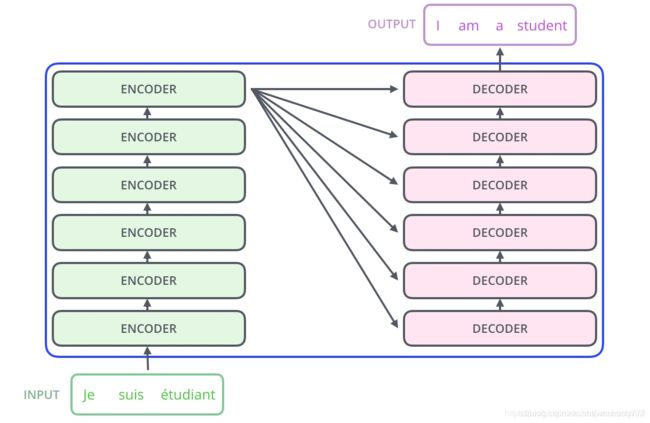
每一个encoder和decoder的内部简版结构如下图:
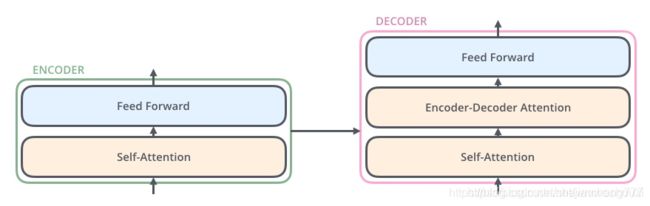
对于encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义;decoder也包含encoder提到的两层网络,但是在这两层中间还有一层attention层,帮助当前节点获取到当前需要关注的重点内容。
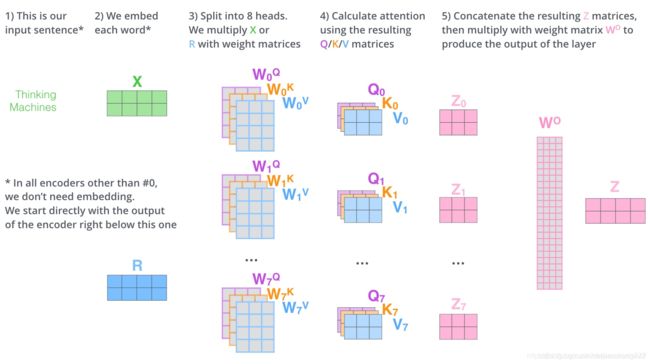
对于self-attention,主要涉及三个矩阵的运算,其中这三个矩阵均由初始embedding矩阵经过线性变换而得,计算方式如下图所示,这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。其实scaled dot-product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大。

在《Attention is all you need》论文中,提出了一种“multi-headed attention",即初始化多组Q、K、V矩阵,注意此处用于线性变换的参数W也都不一样,类似于CNN中的多核,目的是去捕捉更丰富的特征/信息;在bert-base中采用12层transformer,12头注意力,输出的hidden size为768维。下面以transformer中多头注意力计算为例,具体过程如下图:
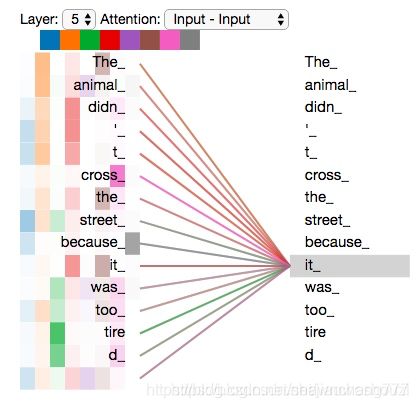
"multi-headed attention"的不同之处在于进行了h次计算而不仅仅算一次,论文中说到这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息;从attention的可视化图中的确验证了这一想法(这里不同颜色代表attention不同头的结果,颜色越深attention值越大)。
1. bert预训练过程
BERT的预训练阶段包括两个任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
- MLM的原理类似于我们常用的word2vec中CBOW方法,会选取语料中所有词的15%进行随机mask,论文中表示是受到完型填空任务的启发;具体地,80%的时间是采用[mask];10%的时间是随机取一个词来代替mask的词;10%的时间保持不变;
至于为何选用15%这一比例,可以参考 超细节的BERT/Transformer知识点 ;其实不难发现,15%这一比例在我们对神经网络层进行dropout时也经常使用。 - NSP是专门为像 QA 这种需要理解两个句子之间关系的任务提出的,具体训练过程是一半的句子 B 是句子 A 的下一句,一半的句子 B 不是句子 A的下一句,预测句子 B 是不是 句子 A 的下一句。
2. bert输入
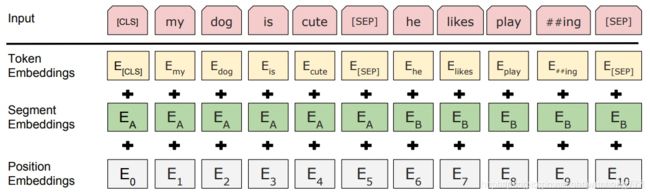
bert模型的输入可以是一个句子或者句子对,代码层面来说,就是输入了句子或者句子对对应的3个向量。它们分别是token embedding,segment embedding和position embedding,具体的含义:
-
token embedding:句子的词向量
-
segment embedding:表示句子属于上下句的哪句
-
position embedding:位置向量,指明token在句中的位置。
关于position embedding这里有两种求法,一种是有相应的三角函数公式得出的,这种是绝对向量;还有一种是学习得到的,这种是相对向量。具体形式如下:
二、Huggingface-transformers笔记
transformers提供用于自然语言理解(NLU)和自然语言生成(NLG)的BERT家族通用结构(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet等),包含超过32种、涵盖100多种语言的预训练模型。同时提供TensorFlow 2.0和PyTorch之间的高互通性。
1. 安装配置
项目地址:https://github.com/huggingface/transformers
项目安装只需使用pip命令,具体细节可参考Installation
pip install transformers
下面以笔者常用的pytorch为例,演示使用方法,包括自己遇到的问题以及使用体会。
2. 如何使用
使用transformers前需保证当前环境下pytorch版本>=1.1.0;以下代码均在pytorch== 1.2.0,transformers==4.1.1环境下运行成功。
项目组件
pytorch版本bert预训练模型文件主要由三部分组成,建议可以官方模型库手动先下载到本地方便调用:
- 配置文件 —— config.json
- 模型文件 —— *.bin
- 词表文件 —— vocab.txt

三个文件分别由 BertConfig、BertModel、BertTokenizer调用。接下来分别进行说明:
1、BertConfig 是一个配置类,存放了BertModel配置,控制模型的名称、隐藏层宽度和深度、激活函数的类别等。将Config类导出时文件格式为 json格式,具体地,打开config.json文件如下图:

举例来说:
- vocab_size:字典大小,默认21128
- hidden_size:Encoder 和 Pooler 隐藏层输出维度,默认768
- num_hidden_layers:Encoder 的隐藏层数,默认12
- num_attention_heads:每个 Encoder 中 attention 层的 head 数,默认12
加载config代码如下:
from transformers import BertConfig
model_name = 'bert-base-chinese' # bert版本名称
model_path = 'D:/Transformers-Bert/bert-base-chinese/' # 用户下载的预训练bert文件存放地址
config_path = 'D:/Transformers-Bert/bert-base-chinese/config.json' # 用户下载的预训练bert文件config.json存放地址
# 载入config 文件可以采取三种方式:bert名称、bert文件夹地址、config文件地址
# config = BertConfig.from_pretrained(model_name) # 这个方法会自动从官方的s3数据库下载模型配置、参数等信息(代码中已配置好位置)
# config = BertConfig.from_pretrained(model_path)
config = BertConfig.from_pretrained(config_path)
2、BertTokenizer 定义一个将纯文本转换为编码的类。注意,Tokenizer并不涉及将词转化为词向量的过程,仅仅是将纯文本分词,添加[MASK]标记、[SEP]、[CLS]标记,并转换为字典索引。
利用分词器进行编码:
- encode仅返回input_ids
- encode_plus返回所有编码信息,包括:
-input_ids:是单词在词典中的编码
-token_type_ids:区分两个句子的编码(上句全为0,下句全为1)
-attention_mask:指定对哪些词进行self-Attention操作
3、BertModel
实现了基本的Bert模型,从构造函数可以看到用到了embeddings,encoder和pooler。
3、数据处理Tips
1. Torch.utils模块
在进行数据导入模型阶段,我们通常会见到DataLoader()方法,最近接触的一个项目里,该函数的一个参数引起我的好奇,下面我们看下这段代码:
train_iter = data.DataLoader(dataset=dataset,
batch_size=hp.batch_size,
shuffle=True,
num_workers=0,
collate_fn=Trainpad)
其中collate_fn参数可以提供用户自定义方法,可以用于设定取mini_batch中max_seq以方便进行padding操作。
本文将持续更新,欢迎提出建议与指点。
参考文章
一文读懂BERT(原理篇)
HuggingFace-Transformers系列的介绍以及在下游任务中的使用
Pytorch-Transformers——部分源码解读及相关说明(一)
bert模型简介、transformers中bert模型源码阅读、分类任务实战和难点总结