搜索引擎ES--IK分词器
目录
集成IK分词器
扩展词典使用
停用词典使用
同义词典使用
集成IK分词器
概要:IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。新版本的IKAnalyzer3.0发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
3.0特性:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
IK分词器有两种分词模式:ik_max_word 和 ik_smart 模式。
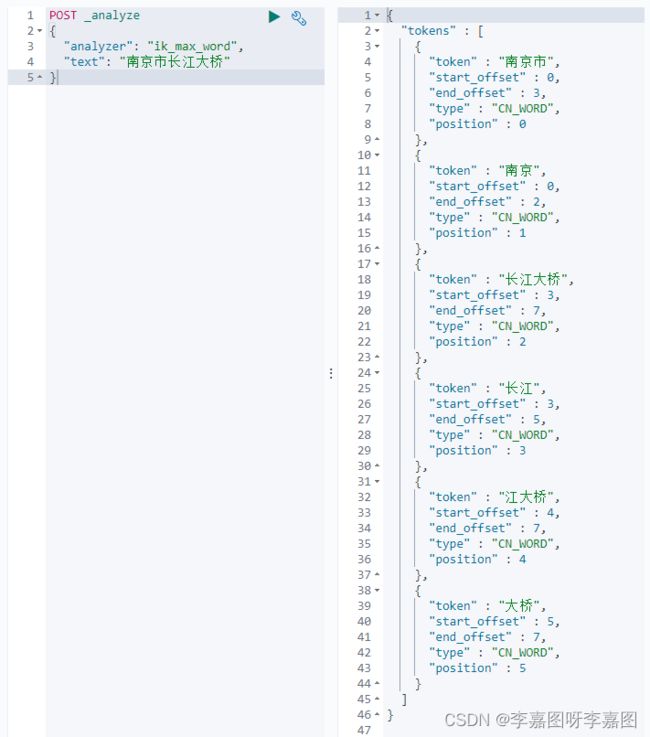
1)ik_max_word(常用模式)
将文本做最细粒度拆分
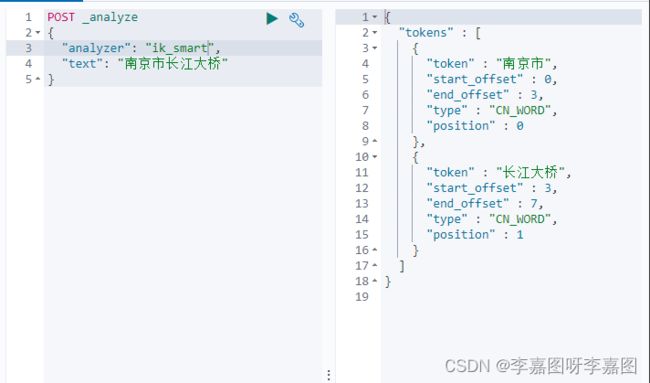
2)ik_smart
将文本做最粗粒度拆分
使用 ik_max_word 结果:
使用 ik_smart 结果:
扩展词典使用
扩展词的使用场景:就是不想让哪些词分开,例如:南京市长江大桥 使用 ik_max_wrod 分出来的 江大桥 并没有意义
通过使用 自定义扩展词库 来将不需要分的词进行处理
1).进入到ik分词器的安装目录下的config目录下,新增自定义词典
vim ext_dict.dic
输入:江大桥
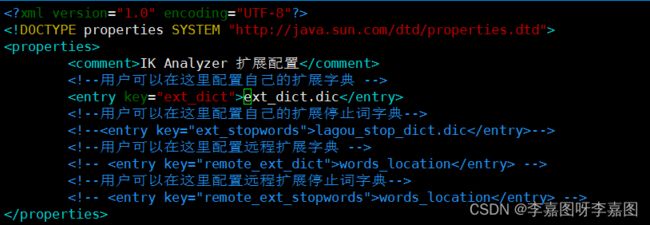
2). 把自定义的扩展词文件添加到IKAnalyzer.cfg.xml中
vim IKAnalyzer.cfg.xml
3)重启Elasticsearch
停用词典使用
有些词在文本中出现的频率非常高,但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小
1)进入到ik分词器的安装目录下的config目录下, 新增自定义词典
vim stop_dict.dic
输入
的 了 啊
2)将我们自定义的停用词典文件添加到IKAnalyzer.cfg.xml配置中
3)重启Elasticsearch
同义词典使用
有很多相同意思的词,我们称之为同义词,比如“番茄”和“西红柿”,“馒头”和“馍”等。在搜索的时候,我们输入的可能是“番茄”,但是应该把含有“西红柿”的数据一起查询出来,这种情况叫做同义词查询。
注意:扩展词和停用词是在索引的时候使用,而同义词是检索时候使用。
配置IK同义词
Elasticsearch 自带一个名为 synonym 的同义词 filter。为了能让 IK 和 synonym 同时工作,我们需要定义新的 analyzer,用 IK 做 tokenizer,synonym 做 filter。听上去很复杂,实际上要做的只是加一段配置。
1)创建/config/analysis-ik/synonym.txt 文件,输入一些同义词并存为 utf-8 格式。例如
china,中国
2)创建索引时,使用同义词配置,示例模板如下
PUT /ik_index
{
"settings": {
"analysis": {
"filter": {
"word_sync": {
"type": "synonym",
"synonyms_path": "analysis-ik/synonym.txt"
}
},
"analyzer": {
"ik_sync_max_word": {
"filter": [
"word_sync"
],
"type": "custom",
"tokenizer": "ik_max_word"
},
"ik_sync_smart": {
"filter": [
"word_sync"
],
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_sync_smart",
"search_analyzer": "ik_sync_smart"
}
}
}
}以上配置定义了 ik_sync_max_word 和 ik_sync_smart 这两个新的 analyzer,对应 IK 的 ik_max_word 和 ik_smart 两种分词策略。ik_sync_max_word 和 ik_sync_smart 都会使用 synonym filter 实现同义词转换
3)到此,索引创建模板中同义词配置完成,搜索时指定分词为 ik_sync_max_word 或ik_sync_smart。
案例:
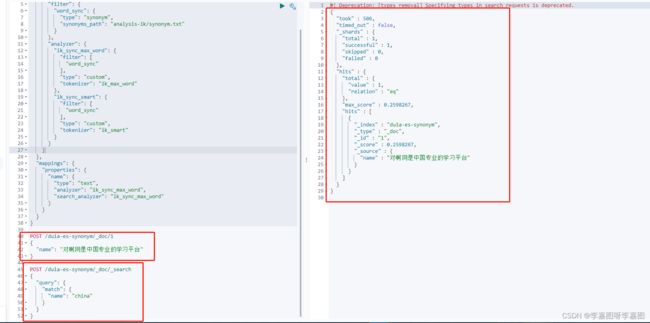
PUT /duia-es-synonym
{
"settings": {
"analysis": {
"filter": {
"word_sync": {
"type": "synonym",
"synonyms_path": "analysis-ik/synonym.txt"
}
},
"analyzer": {
"ik_sync_max_word": {
"filter": [
"word_sync"
],
"type": "custom",
"tokenizer": "ik_max_word"
},
"ik_sync_smart": {
"filter": [
"word_sync"
],
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_sync_max_word",
"search_analyzer": "ik_sync_max_word"
}
}
}
}插入一条数据
POST /duia-es-synonym/_doc/1
{
"name": "对啊网是中国专业的学习平台"
}使用同义词“china”进行搜索