WWW 2021|多元知识图谱的自动化稀疏张量分解建模

©PaperWeekly 原创 · 作者|邸世民
学校|香港科技大学博士生
研究方向|神经结构搜索、知识图谱嵌入

简介
近年来,不同的嵌入(Embedding)模型被提出用以解决多元关系数据(N-ary Relational Data)上的任务 [1,2]。在这些模型中,张量分解模型(Tensor Decomposition Model)由于其对关系表征能力的理论保证使其在各大基准数据集上取得了领先的效果。然而,当前的张量分解模型还存在着不能很好的处理数据稀疏和过参数化的问题。
针对张量模型的俩个问题,本文提出了一种,在给定多元关系数据集上,自动化搜索稀疏张量分解模型的算法 S2S。在链路预测(Link Prediction)任务上,S2S 显示其不仅缓解了张量分解模型的数据稀疏问题,同时降低了模型所需的复杂度,从而获得优异的效果和效率。
本文作为 AutoSF [3] / GETD [4] 的延续工作,首先将 AutoSF 的评分函数(Scoring Function)搜索从知识图谱(Knowledge Graph)扩展到多元关系数据上,并对搜索算法进行了改进,从而减少搜索时间。另外,本文延续 GETD 模型降维的思想,进一步解决张量分解模型的过参数化问题。

论文标题:
Searching to Sparsify Tensor Decomposition for N-ary relational data
论文作者:
邸世民、姚权铭、陈雷

背景介绍
多元关系数据,又称知识库(Knowledge Bases),已经促进了一系列的下游应用,如语义搜索、问答系统、推荐系统。在多元关系数据中,每个 n 元事实是由一个关系和 n 个实体构成的,其形表示为(关系,实体 1,…,实体 n)。
值得注意的是,近年广受研究关注的知识图谱其实是一种特别的二元关系数据,其只包含着二元事实,即为三元组形式(关系,头实体,尾实体)。然而,研究更广泛的多元关系数据,可以进一步帮助人们探索和组织人类知识。
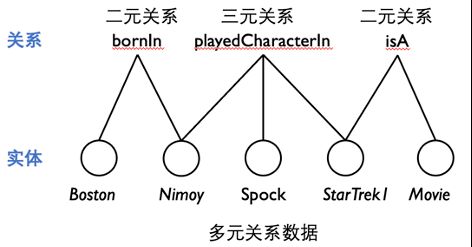
由于多元关系数据集高度不全,补全多元关系数据成为一个关键的任务。为了量化地验证一个给定 n 元事实是否真实存在,嵌入模型提出将关系和实体映射到低维向量空间,再借助评分函数来量化计算 n 元事实的合理性。目前,学术界提出许多在多元关系数据上的嵌入模型。
例如,平移距离模型(Translational Distance Models)m-TransH [1] 提出扩展一个在二元关系数据上知名的模型 TransH。然而,TransH 的表征能力不强,在其上拓展的工作在多元关系数据上的表现欠佳。
另外,NaLP [2]、HINGE [5] 等神经网络模型(Neural Network Models)受到深度学习模型的启发,相继提出不同的网络架构用以学习嵌入。但它们都引入了大量的模型参数,但介于没有很好的正则化方法,使其实证效果并不理想。张量分解模型提出将用一个(n+1)维度的张量 X 来表示 n 元的事实集合,然后再利用 Tucker 张量分解方法将张量 X 分解成为关系和实体的嵌入。
在目前的嵌入模型中,张量分解由于其对表征能力的理论保证,使其实证效果最好。现有的张量分解模型仍然存在两个问题。
第一,由于多元关系数据非常稀疏,嵌入模型往往难以训练和学习。但是现有的张量分解模型只能从具有一个特定元数的事实中学习。这会导致数据稀疏问题在张量分解模型中更加严重。
第二,现有的张量分解模型通过保持一个过度参数化的核心张量来实现表达能力。这种过度参数化的表达不仅使得模型效率低下,而且训练起来也很困难。

本次工作的方法
为了缓解数据稀疏的问题,本文提出分割嵌入和在不同的元数关系数据中共享不同的嵌入片段。如下图所示,S2S 将每个嵌入向量分割成三份,然后在计算一个二元事实的评分时,其只会用其前俩份的嵌入片段(Embedding Segment)。
在计算三元事实时,前三份的嵌入片段将会被纳入计算。这种基于片段的嵌入共享可以使嵌入模型在学习高元事实时利用低元事实的信息,同时也保留了一部分高元的特定信息。

另外,如下图所示,本文观测到现有张量模型(如 DistMult [6]、ComplEx [7]、SimplE [8])在二元关系数据中存在着结构稀疏模式。然而在二元情况下,这些具有结构稀疏约束的张量分解模型具有较好的表达能力和较好的实证性能。这个发现启发本文作者,在学习多元关系数据时,一个需求大量参数的核心张量可能不是必要的。
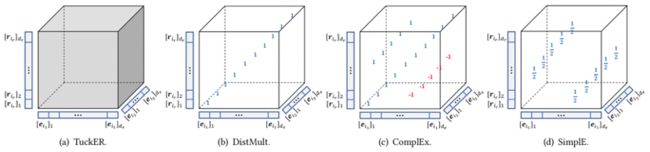
因此,本文提出对张量分解模型的密集核心张量进行稀疏化,从而避免过度参数化。如下图所示,本文定义了一个包含三种操作的集合,1 表示嵌入片段存在正相关性、-1 表示负相关性、以及 0 表示无关。通过约束模型进行选取这些操作来实现结构的稀疏化。
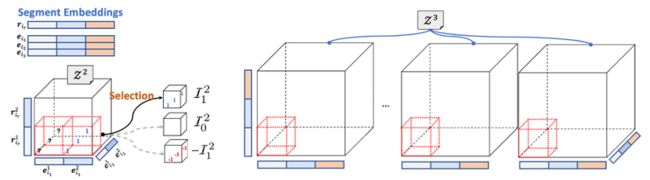
受到神经结构搜索(Neural Architecture Search)的启发,S2S 提出针对不同的多元关系数据进行自动化搜索,来获取实证效果较高的稀疏化张量分解模型。本文将稀疏化的核心张量视为随机变量,建立起一个针对稀疏核心张量的概率分布模型,通过不断的采样和迭代更新概率分布,从而获取一个效果较高的模型。

实验结果
本文分别在固定元(二元、三元、四元)关系数据以及混合元关系数据上进行了链路预测的对比实验。
4.1 验证S2S在固定元关系数据上的效果和效率
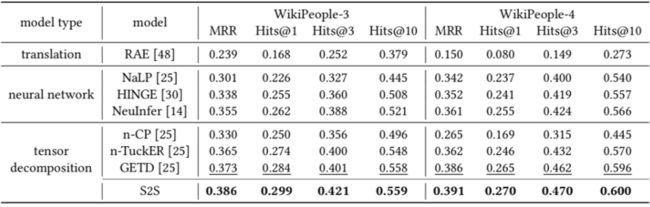
在下表我们可以观察到张量分解模型(n-CP [9]、n-TuckER [10]、GETD [4] 和 S2S)在固定元关系数据上(WikiPeople-3、WikiPeople-4、JF17K-3、JF17K-4)通常比其他模型具有更好的性能。这主要是因为张量分解模型具有很强的表征能力。
然后,尽管 n-CP 在张量分解模型中要求最低的模型复杂度,但它并没有像其他张量分解模型那样实现高性能。这是因为 n-CP 没有引入一个核心张量使得嵌入能够共享领域知识。
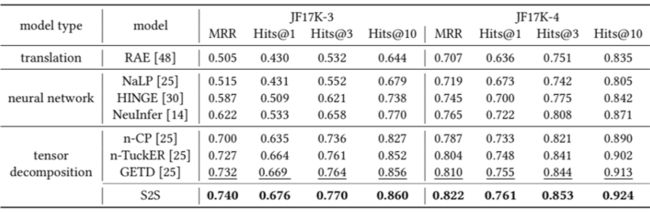
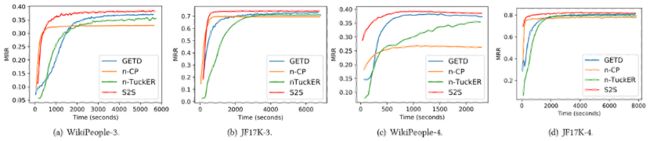
如下图,本文还绘制了在张量分解模型在多元关系数据上的学习曲线。可以观察到,其搜索到的稀疏张量分解模型收敛速度比其他具有核心张量的模型(n-Tucker 和 GETD)更快。这是因为稀疏化后的核心张量所需的模型参数较少。
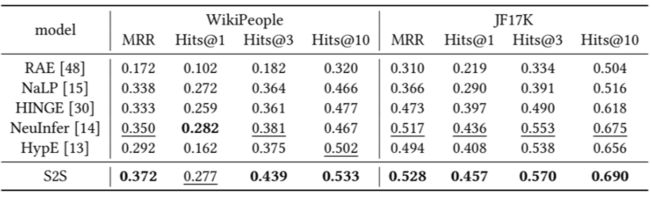
4.2 验证S2S在混合元关系数据上的效果和效率
本文同时也对比了混合元学习的工作。如下表所示,S2S 在混合元关系数据集(WikiPeople 和 JF17K)上也取得了优异的实证性能。
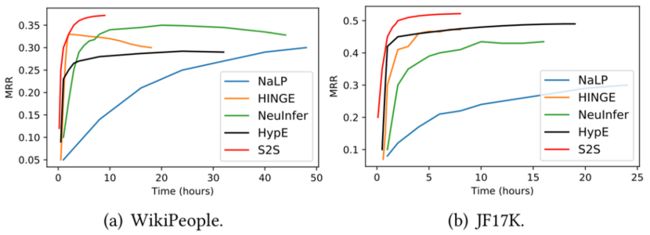
在对比 S2S 和其他混合元学习嵌入模型的学习曲线后,可以看到S2S取得了相当快速的收敛速度。
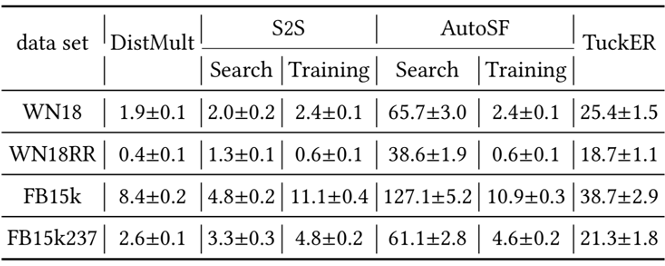
4.3 验证S2S的搜索效率
如下表所示,S2S 对比其和一个在二元数据上搜索办法 AutoSF 的搜索时长,可以明显看 S2S 的搜索从效率上来看是十分快速的。
4.4 验证关键设计
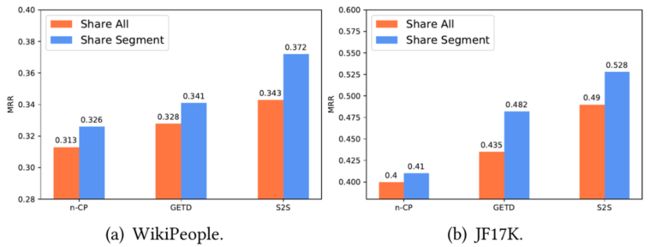
本文随后将共享嵌入的机制引入不同的张量分解模型中。如下图所示,张量分解模型在引入该机制后都有不同的程度的提升。这验证了其共享嵌入的设计思想。
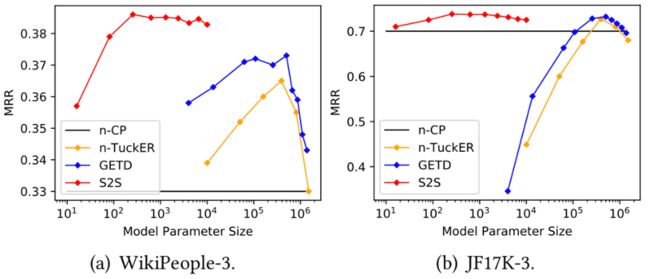
另外,S2S 对比了一下张量分解模型的参数大小和效果比较。如下图所示, S2S 通过需要少量参数,可以实现卓越的性能。并且随着模型参数的增加,其性能也没有很大的变化。相反,GETD 和 n-TuckER 需要更大的参数来实现高性能。而模型参数的设置会导致性能上的显著差异。

本组其它关联工作
如简介所述,本文是 AutoSF [3] 和 GETD [4] 的延续工作。另外,以下本组的其他工作也与本文相关联。
Interstellar: Searching Recurrent Architecture for Knowledge Graph Embedding. NeurIPS 2020. (Interstellar)
Efficient Relation-aware Scoring Function Search for Knowledge Graph Embedding. ICDE 2021. (ERAS)
Role-Aware Modeling for N-ary Relational Knowledge Bases. WWW 2021. (RAM)
Search to aggregate neighborhood for graph neural network. ICDE 2021. (SANE)
其中,Interstellar 提出一种搜索周期性结构的算法,用以捕捉二元关系数据集中存在的关系路径;ERAS 针对二元关系数据提出一种关系感知的评分函数快速搜索算法;RAM 针对多元关系数据提出一种角色感知的建模方式;SANE 提出一种聚集领域的图神经网络(Graph Neural Network)架构搜索算法,有被应用到二元或者多元关系数据的潜在可能。

未来工作
对于未来的工作,一个值得尝试的方向,是用利用一个更自然的方式,多关系超图(Multi-relational Hypergraph),来对多元关系数据进行建模,并应用图神经网络搜索算法进行搜索合适的图神经网络架构。
另一个方向是利用多元关系数据来提升工业应用的效果。例如,当前在双元关系数据上的链路预测任务已经被应用于推荐系统 [11] 。由于本文提供了一种处理多元关系数据的轻量级方法,我们可以利用存储知识更为丰富的多元关系数据集来进一步提高这些应用的性能。
参考文献
[1] On the representation and embedding of knowledge bases beyond binary relations. IJCAI 2016.
[2] Link prediction on n-ary relational data. WWW 2019.
[3] AutoSF: Searching scoring functions for knowledge graph embedding. ICDE 2020.
[4] Generalizing Tensor Decomposition for N-ary Relational Knowledge Bases. WWW 2020.
[5] Beyond triplets: hyper-relational knowledge graph embedding for link prediction. WWW 2020.
[6] Embedding entities and relations for learning and inference in knowledge bases. ICLR 2015.
[7] Knowledge graph completion via complex tensor factorization. JMLR 2017.
[8] Simple embedding for link prediction in knowledge graphs. NIPS 2018.
[9] Canonical tensor decomposition for knowledge base completion. ICML 2018.
[10] TuckER: Tensor Factorization for Knowledge Graph Completion. EMNLP 2019.
[11] Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. WWW 2019.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
