- Android 应用权限管理详解
文章目录1.权限类型2.权限请求机制3.权限组和分级4.权限管理的演进5.权限监控和SELinux强制访问控制6.应用权限审核和GooglePlayProtect7.开发者最佳实践8.用户权限管理9.Android应用沙箱模型10.ScopedStorage(分区存储)11.背景位置权限(BackgroundLocationAccess)12.权限回收和自动清理13.权限请求的用户体验设计14.G
- Hive使用必知必会系列
王知无(import_bigdata)
Hive系统性学习专栏hivebigdatahdfs
一、Hive的几种数据模型内部表(Table将数据保存到Hive自己的数据仓库目录中:/usr/hive/warehouse)外部表(ExternalTable相对于内部表,数据不在自己的数据仓库中,只保存数据的元信息)分区表(PartitionTable将数据按照设定的条件分开存储,提高查询效率,分区----->目录)桶表(BucketTable本质上也是一种分区表,类似hash分区桶---->
- 基于javaweb和MySQL的笔记管理系统
俺是答案
笔记intellij-ideamysql
要求1.用户1.注册和登入。2.用户可以发布,删除,修改自己的笔记。详细要求:发布笔记时,笔记要有专属的区域,比如这个笔记是文学。区的设置自己定义,大概六个区域就可以了。3.用户可以在首页查看所有的笔记,以及对应分区的笔记。4.允许用户修改自己的信息。5.用户可以收藏,评论,点赞他人的笔记。6.用户可以在用户中心查询自己发布的笔记,评论的笔记,点赞的笔记。详细要求:用户查询笔记时可以点击进去看到详
- Linux 逻辑卷管理实例详解
ORA_无花果
osLinux逻辑卷管理lvm实例详解linux
Linux逻辑卷管理(LVM)LVM(LogicalVolumeManager,逻辑卷管理器)是一种把硬盘空间划分成“弹性”逻辑卷的方法。这里的“弹性”体现在硬盘不必重新分区也能够被简单地重新划分大小。需要强调说明的是,LVM是Linux操作系统中一个磁盘管理子系统,而不是文件系统!1、LVM基本概念一般来说,一个分区大小是固定的。如果一个分区上没有空间时,我们只能重新分区以扩大相应分区的大小(这
- 【20年架构师韩艳威整理】CentOS Stream10磁盘管理第4章
韩公子的Linux大集市
Bash入门centoslinux运维
文章目录优化细化1:磁盘识别与扫描(增强版)优化细化2:GPT分区高级操作优化细化3:文件系统优化参数优化细化4:LVM元数据管理优化细化5:LVM高级扩容技巧优化细化6:LVM快照管理优化细化7:LVM精简配置优化细化8:故障处理与恢复优化细化9:性能监控与调优优化细化10:安全与权限管理终极操作对比表:普通分区vsLVM灾难恢复检查清单以下是对CentOSStream10中BashShell磁
- 【20年架构师韩艳威整理】CentOS Stream10磁盘管理第1章
韩公子的Linux大集市
Bash入门centoslinux运维
文章目录一、普通分区管理1.查看磁盘信息2.创建新分区3.格式化分区4.挂载分区5.卸载分区二、LVM分区管理1.LVM基本概念2.创建LVM3.扩展LVM4.缩减LVM(谨慎操作)5.删除LVM三、实用监控命令1.磁盘使用情况2.LVM状态监控3.磁盘健康状态四、实用技巧1.永久设备名(使用UUID挂载)2.创建交换分区3.修复文件系统五、注意事项在CentOSStream10中使用BashSh
- kafka的ISR机制详解
inori1256
kafka分布式
Kafka的ISR机制ISR(In-SyncReplicas同步副本集)机制是一种用于确保数据可靠性和一致性的重要机制。一、ISR的定义ISR是指与Kafka分区中的Leader副本保持同步的Follower副本集合。这些副本已经复制了Leader副本的所有数据,并且它们的落后时间在一定范围内,因此被认为是可靠的、可以用于故障转移和数据恢复的副本。二、ISR的作用数据复制:当消息被写入Kafka的
- 2023-09-25 封地/封国
美元微笑了
当上了大夫,就有封田/封地;有了封田/封地,田地上的民众就归家族私有;家族门下的民众越多,其家族私有武装也就越强大。在新政下,只要卿族家里人丁兴旺,就必然会走向强大。古代帝王的后裔、以及立功的将士,让他们在地方作“诸侯”,分区管理,辅佐周王,被封的“诸侯”在“封国”内继续分封,通过这种逐级分封,下级对上级承担缴纳贡物,军事保卫,服从命令等义务。公元前497年,因为在对卫国进贡的500户平民的安置问
- Hbase基础语法
flyair_China
hbase数据库大数据
HBase作为分布式列式数据库,其语法和预分区策略是优化性能的关键。以下综合语法详解与预分区设计指南:一、HBase核心语法分类1.DDL操作(表结构管理)创建表语法:create'表名',{NAME⇒'列族1',VERSIONS⇒n},{NAME⇒'列族2',VERSIONS⇒n}示例:创建user表,含info(保留3版本)和data(保留1版本)列族:create'user',{NAME⇒'
- 教室分区----第九届创新年会6
卌行
今天除了嗓子与咳嗽,身体终于不再痛了。我这只早羊开始照顾起了家里的晚羊们,主要是儿子做的饭真不好吃,他自己都笑称自己昨天炒的番茄蛋太难吃了。为了让大家有力量抵抗,吃的营养上还是得跟上。屋外的灿烂冬阳也正预示着好的日子快来了吧。今天选择了《教学与评价主题峰会》。主持人是我看到的创新年会最朴实的主持人,没有正装,没有以为的高大上。但当他的录像讲座中,终于穿上了西装。开篇的虚构视频太好玩了。精准分析学情
- 深入理解 eMMC RPMB 与 OP-TEE 在 Linux 系统中的应用开发
CheungChunChiu
linux运维服务器androidop-tee
可信执行环境(TEE)和安全存储机制在现代嵌入式系统和ARM平台中日益重要。尤其是在RK3588等SoC上,eMMC的RPMB区域和OP-TEE的结合,成为构建安全可信机制的核心基础。本篇文章将系统性地介绍相关原理、工具链、开发结构与实际使用案例。什么是RPMB?为什么重要?RPMB(ReplayProtectedMemoryBlock)是eMMC或UFS存储中的一个专用硬件分区,特点如下:✅不可
- kafka的消息存储机制和查询机制
不辉放弃
kafka大数据开发数据库pyspark
Kafka作为高性能的分布式消息队列,其消息存储机制和查询机制是保证高吞吐、低延迟的核心。以下从存储机制和查询机制两方面详细讲解,包含核心原理、关键组件及工作流程。一、Kafka消息存储机制Kafka的消息存储机制围绕高可用、高吞吐、可扩展设计,核心是通过分区、副本、日志分段和索引实现高效存储与管理。1.基本组织单位:主题(Topic)与分区(Partition)主题(Topic):消息的逻辑容器
- 数据写入因为汉字引发的异常
qq_40841339
sparkhadoophivehivehadoop数据仓库
spark数据写hive表,发生查询分区异常问题异常:251071241926.49ERRORHive:MelaException(message.Exceptionthrownwhenexeculingquey.SELECTDISTINCT‘orgapache.hadop.hivemelastore.modelMpartionAs"NUCLEUSTYPE,AONCREATETIME,AO.LAS
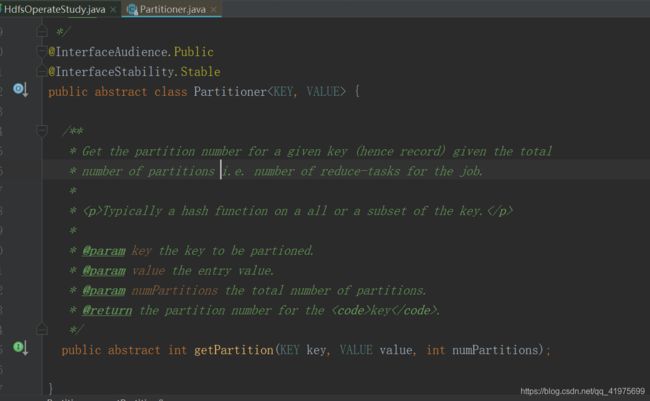
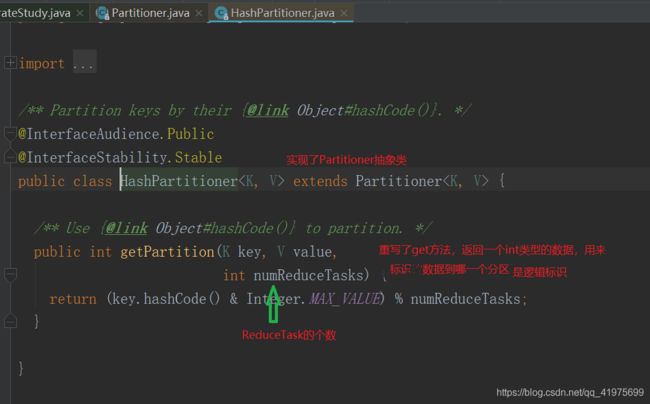
- Hadoop中MapReduce和Yarn相关内容详解
接上一章写的HDFS说,Hadoop是一个适合海量数据的分布式存储和分布式计算的一个平台,上一章介绍了分布式存储,这一章介绍一下分布式计算——MapReduce。一、MapReduce设计理念map——>映射Reduce——>归纳mapreduce是一种必须构建在hadoop之上的大数据离线计算框架。因为mapreduce是给予磁盘IO来计算存储文件的,所以它具有一定的延时性,因此一般用来处理离线
- 阿里云MaxCompute SQL与Apache Hive区别面面观
大模型大数据攻城狮
阿里云odpssql物化maxcomputeudf开发sql语法
目录1.引爆开场:MaxCompute和Hive,谁才是大数据SQL的王者?2.架构大比拼:从Hadoop到Serverless的进化之路Hive的架构:老派但经典MaxCompute的架构:云原生新贵3.SQL语法的微妙差异:90%相似,10%决定胜负建表语句分区与分桶函数与UDF4.执行引擎的较量:MapReducevs飞天引擎Hive的MapReduce执行流程MaxCompute的飞天引擎
- 一文说清楚Hive
Hive作为ApacheHadoop生态的核心数据仓库工具,其设计初衷是为熟悉SQL的用户提供大规模数据离线处理能力。以下从底层计算框架、优点、场景、注意事项及实践案例五个维度展开说明。一、Hive底层分布式计算框架对比Hive本身不直接执行计算,而是将HQL转换为底层计算引擎的任务。目前支持的主流引擎及其特点如下:计算引擎核心原理优点缺点适用场景MapReduce基于“Map→Shuffle→R
- 第四篇:深入探讨Kafka消费者的架构和原理
Gemini技术窝
kafka架构java后端中间件
大家好!今天我们要深入探讨Kafka消费者的架构和原理。Kafka消费者是从Kafka集群中读取消息的客户端应用,其设计和实现直接影响消息处理的效率和可靠性。本文将介绍Kafka消费者和消费者组的原理和作用,使用示例代码和源码剖析消费者的参数和功能,并详细介绍Kafka消费者如何订阅主题和分区。希望通过这篇文章,你能全面理解Kafka消费者的工作机制。准备好了吗?让我们开始吧!文章目录一、Kafk
- Kafka消费者负载均衡策略
⼀个消费者组中的⼀个分⽚对应⼀个消费者成员,他能保证每个消费者成员都能访问,如果组中成员太多会有空闲的成员Kafka消费者负载均衡策略详解从分区分配算法到Rebalance机制,全面解析Kafka如何实现消费者间的负载均衡,并提供调优建议和问题解决方案。1.核心概念术语作用类比ConsumerGroup共享消费任务的消费者组外卖骑手团队PartitionTopic的物理分片配送区域划分Rebala
- kafka的消费者负载均衡机制
不辉放弃
kafka负载均衡分布式数据库
Kafka的消费者负载均衡机制是保证消息高效消费的核心设计,通过将分区合理分配给消费者组内的消费者,实现并行处理和负载均衡。以下从核心概念、分配策略、重平衡机制等方面详细讲解。一、核心概念理解消费者负载均衡前,需明确三个关键概念:消费者组(ConsumerGroup)多个消费者组成的逻辑组,共同消费一个或多个主题的消息。组内消费者共享一个group.id标识,Kafka通过该标识区分不同消费组。分
- 【Python高阶开发】2. Dask分布式加速实战:TB级生产日志分析效率提升指南
摘要:随着工业4.0的深入推进,工业生产日志数据量呈指数级增长,某汽车制造厂日均产生2TB生产日志,传统单机Pandas处理面临内存不足、耗时过长、资源利用率低三大瓶颈。本文基于Dask分布式计算框架,构建工业级日志分析解决方案,通过“集群部署-高效加载-数据处理-性能优化”四步法,实现日志分析效率5倍提升。详细阐述Dask核心原理(任务调度、延迟计算、数据分区),对比单机与分布式架构差异,提供从
- Linux 挂载机制全解析:mount 命令详解与实战案例
Stay Passion
linux运维服务器
前言在Linux中,一切皆是文件,包括硬件设备、网络接口、以及其他外部存储设备。而要访问这些设备,首先需要把它们挂载到文件系统中。这就离不开一个关键命令:mount。本篇文章,我们将深入讲解:挂载机制的原理mount命令的详细语法常见挂载场景及实战案例自动挂载与卸载操作1️⃣挂载机制的基本概念✅1.1什么是挂载?挂载(mount)是把一个设备(如硬盘分区、光盘、U盘等)关联到Linux文件系统的某
- PE系统制作和安装详细教程【Windows系统安装】
IT技术视界9
软件大全windows
WindowsPE(预安装环境)是一种轻量级操作系统,专门用于为Windows安装做准备。它能在无操作系统的计算机上启动,并提供多种系统维护功能,包括:清除顽固病毒、修复磁盘引导分区、进行硬盘分区、执行数据备份以及安装操作系统等。软件下载说明[名称]:PE系统[大小]:207.2MB[语言]:简体中文[备注]:若下载链接失效,请评论区留言资源下载链接:PE系统制作和安装详细教程【Windows系统
- 深度学习篇---剪裁&缩放
Atticus-Orion
图像处理篇程序代码篇深度学习篇人工智能图像处理剪裁缩放
在深度学习中,图像数据集的剪裁(Cropping)和缩放(Scaling/Resizing)是预处理阶段的核心操作,其核心目的是将原始图像转换为符合模型输入要求的统一尺寸,同时保留关键特征、去除冗余信息,最终提升模型的训练效率与泛化能力。以下从原理、常见方法、在深度学习中的作用及影响三个维度详细介绍。一、图像剪裁(Cropping)的原理剪裁是指从原始图像中截取部分区域(子图像)的操作,本质是通过
- 大脑各脑区功能解析:从痛觉处理到动作执行的协作机制
大脑作为人体最复杂的神经中枢,其各脑区的协同运作支撑着我们日常的感知、思考、行动等所有生命活动。但多数时候,我们对这种“理所当然”的运作习以为常,却忽略了其背后精密的神经机制。本文将通过三个常见场景——痛觉处理、记忆形成、动作执行,拆解大脑各分区的功能分工与协作逻辑,帮助理解脑区如何配合完成具体任务。一、大脑核心分区的基础功能范畴在解析具体场景前,先明确几个关键脑区的核心功能:脊髓:感觉信号的初步
- 2025 年国人友好神刊盘点:20 本审稿快、分区高的 SCI 期刊,速抢发文先机!
医工交叉实验工坊
学习科技
前言:2024影响因子发布,这些期刊暴涨!科睿唯安最新发布的2024年影响因子(2025年公布)显示,多本TOP期刊影响因子迎来大幅上涨!尤其是对国人友好的期刊,因审稿效率高、版面费亲民、国人发文占比超40%,成为科研人员投稿热门。本文精选20本潜力神刊,涵盖Cell子刊、顶流期刊、黑马期刊、性价比之王及新晋分区TOP,附完整的影响因子、中科院分区、审稿周期、收稿方向攻略,助你抢占发文先机!一、第
- ZYNQ Petalinux系统FLASH固化终极指南:创新多分区与双系统切换实战
芯作者
fpga开发
传统固化教程千篇一律?本文将带你突破固化瓶颈,实现QSPIFLASH多镜像分区与动态启动管理,让嵌入式系统部署更灵活、维护更高效!一、为何需要FLASH固化?痛点与价值在ZYNQ开发中,我们常面临这样的困境:SD卡启动不稳定:物理接触易松动,工业环境不可靠部署效率低下:每次更新需手动更换SD卡启动速度瓶颈:SD卡初始化拖慢系统上电时间维护成本高:现场设备升级困难FLASH固化方案核心价值:启动时间
- oracle 分区表 变大,Oracle11G新特性:分区表分区默认segment大小64k变为8M
阳光下的少年
oracle分区表变大
Oracle11G新特性:分区表分区默认segment大小64k变为8M2017-02-08在oracle11.2创建分区表,每个分区默认大小为8M,是由_partition_large_extents参数控制,可以算是11.2.0.2开始的一个新特性,为了减少extent数量,提高分区表性能,而设置的一个参数,默认为true,即分区表的每个extent为8M,和oracle10g相比,会导致同样
- OceanBase数据库
躲在没风的地方
数据库oceanbaselinux
OceanBase数据库1默认表和分区表建立表时默认不是分区表,需要在建表语句中通过特定语法设置才能创建分区表,以下是创建不同类型分区表的方式:分区表是一种将大表的数据按照一定规则划分成多个更小、更容易管理的数据子集(即分区)的技术。1.1分区的目的和优势提高查询性能:当查询只涉及表中的部分数据时,通过分区可以快速定位到相关分区,避免扫描整个大表。例如,一张存储了多年销售记录的表,按年份进行分区后
- Kafka分区副本分配规则
罗纳尔光
Kafkakafkajava分区副本机架扩缩分区
Kafka分区副本分配规则文章目录Kafka分区副本分配规则1、前言2、自动分配a.无机架方式分配b.有机架方式分配(1)机架介绍(2)有机架方式分配的目的(3)分配规则c.问题3、指定分配规则分配参考文献1、前言 我们在创建topic或者是新增分区时,如果不指定分区副本的分配方式,Kafka会自动帮我们分配,那Kafka是如何帮我们分配的呢?我们如果指定分区副本的分配方式,Kafka会做哪些事情
- 解锁Hive:高效数据查找的秘密武器
YangRyeon
hivehadoop数据仓库
Hive是什么?Hive是基于Hadoop的一个数据仓库工具,它能够进行数据提取、转化和加载操作,为存储、查询和分析Hadoop中的大规模数据提供了有效的机制。Hive能将结构化的数据文件映射为一张数据库表,让用户可以通过熟悉的SQL查询功能来处理数据。其内部机制是将SQL语句巧妙地转变成MapReduce任务来执行,大大降低了开发的难度和复杂性。例如,在面对海量的用户行为日志数据时,Hive就能
- [星球大战]阿纳金的背叛
comsci
本来杰迪圣殿的长老是不同意让阿纳金接受训练的.........
但是由于政治原因,长老会妥协了...这给邪恶的力量带来了机会
所以......现代的地球联邦接受了这个教训...绝对不让某些年轻人进入学院
- 看懂它,你就可以任性的玩耍了!
aijuans
JavaScript
javascript作为前端开发的标配技能,如果不掌握好它的三大特点:1.原型 2.作用域 3. 闭包 ,又怎么可以说你学好了这门语言呢?如果标配的技能都没有撑握好,怎么可以任性的玩耍呢?怎么验证自己学好了以上三个基本点呢,我找到一段不错的代码,稍加改动,如果能够读懂它,那么你就可以任性了。
function jClass(b
- Java常用工具包 Jodd
Kai_Ge
javajodd
Jodd 是一个开源的 Java 工具集, 包含一些实用的工具类和小型框架。简单,却很强大! 写道 Jodd = Tools + IoC + MVC + DB + AOP + TX + JSON + HTML < 1.5 Mb
Jodd 被分成众多模块,按需选择,其中
工具类模块有:
jodd-core &nb
- SpringMvc下载
120153216
springMVC
@RequestMapping(value = WebUrlConstant.DOWNLOAD)
public void download(HttpServletRequest request,HttpServletResponse response,String fileName) {
OutputStream os = null;
InputStream is = null;
- Python 标准异常总结
2002wmj
python
Python标准异常总结
AssertionError 断言语句(assert)失败 AttributeError 尝试访问未知的对象属性 EOFError 用户输入文件末尾标志EOF(Ctrl+d) FloatingPointError 浮点计算错误 GeneratorExit generator.close()方法被调用的时候 ImportError 导入模块失
- SQL函数返回临时表结构的数据用于查询
357029540
SQL Server
这两天在做一个查询的SQL,这个SQL的一个条件是通过游标实现另外两张表查询出一个多条数据,这些数据都是INT类型,然后用IN条件进行查询,并且查询这两张表需要通过外部传入参数才能查询出所需数据,于是想到了用SQL函数返回值,并且也这样做了,由于是返回多条数据,所以把查询出来的INT类型值都拼接为了字符串,这时就遇到问题了,在查询SQL中因为条件是INT值,SQL函数的CAST和CONVERST都
- java 时间格式化 | 比较大小| 时区 个人笔记
7454103
javaeclipsetomcatcMyEclipse
个人总结! 不当之处多多包含!
引用 1.0 如何设置 tomcat 的时区:
位置:(catalina.bat---JAVA_OPTS 下面加上)
set JAVA_OPT
- 时间获取Clander的用法
adminjun
Clander时间
/**
* 得到几天前的时间
* @param d
* @param day
* @return
*/
public static Date getDateBefore(Date d,int day){
Calend
- JVM初探与设置
aijuans
java
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台
- SQL中ON和WHERE的区别
avords
SQL中ON和WHERE的区别
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。 www.2cto.com 在使用left jion时,on和where条件的区别如下: 1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
- 说说自信
houxinyou
工作生活
自信的来源分为两种,一种是源于实力,一种源于头脑.实力是一个综合的评定,有自身的能力,能利用的资源等.比如我想去月亮上,要身体素质过硬,还要有飞船等等一系列的东西.这些都属于实力的一部分.而头脑不同,只要你头脑够简单就可以了!同样要上月亮上,你想,我一跳,1米,我多跳几下,跳个几年,应该就到了!什么?你说我会往下掉?你笨呀你!找个东西踩一下不就行了吗?
无论工作还
- WEBLOGIC事务超时设置
bijian1013
weblogicjta事务超时
系统中统计数据,由于调用统计过程,执行时间超过了weblogic设置的时间,提示如下错误:
统计数据出错!
原因:The transaction is no longer active - status: 'Rolling Back. [Reason=weblogic.transaction.internal
- 两年已过去,再看该如何快速融入新团队
bingyingao
java互联网融入架构新团队
偶得的空闲,翻到了两年前的帖子
该如何快速融入一个新团队,有所感触,就记下来,为下一个两年后的今天做参考。
时隔两年半之后的今天,再来看当初的这个博客,别有一番滋味。而我已经于今年三月份离开了当初所在的团队,加入另外的一个项目组,2011年的这篇博客之后的时光,我很好的融入了那个团队,而直到现在和同事们关系都特别好。大家在短短一年半的时间离一起经历了一
- 【Spark七十七】Spark分析Nginx和Apache的access.log
bit1129
apache
Spark分析Nginx和Apache的access.log,第一个问题是要对Nginx和Apache的access.log文件进行按行解析,按行解析就的方法是正则表达式:
Nginx的access.log解析正则表达式
val PATTERN = """([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\&q
- Erlang patch
bookjovi
erlang
Totally five patchs committed to erlang otp, just small patchs.
IMO, erlang really is a interesting programming language, I really like its concurrency feature.
but the functional programming style
- log4j日志路径中加入日期
bro_feng
javalog4j
要用log4j使用记录日志,日志路径有每日的日期,文件大小5M新增文件。
实现方式
log4j:
<appender name="serviceLog"
class="org.apache.log4j.RollingFileAppender">
<param name="Encoding" v
- 读《研磨设计模式》-代码笔记-桥接模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 个人觉得关于桥接模式的例子,蜡笔和毛笔这个例子是最贴切的:http://www.cnblogs.com/zhenyulu/articles/67016.html
* 笔和颜色是可分离的,蜡笔把两者耦合在一起了:一支蜡笔只有一种
- windows7下SVN和Eclipse插件安装
chenyu19891124
eclipse插件
今天花了一天时间弄SVN和Eclipse插件的安装,今天弄好了。svn插件和Eclipse整合有两种方式,一种是直接下载插件包,二种是通过Eclipse在线更新。由于之前Eclipse版本和svn插件版本有差别,始终是没装上。最后在网上找到了适合的版本。所用的环境系统:windows7JDK:1.7svn插件包版本:1.8.16Eclipse:3.7.2工具下载地址:Eclipse下在地址:htt
- [转帖]工作流引擎设计思路
comsci
设计模式工作应用服务器workflow企业应用
作为国内的同行,我非常希望在流程设计方面和大家交流,刚发现篇好文(那么好的文章,现在才发现,可惜),关于流程设计的一些原理,个人觉得本文站得高,看得远,比俺的文章有深度,转载如下
=================================================================================
自开博以来不断有朋友来探讨工作流引擎该如何
- Linux 查看内存,CPU及硬盘大小的方法
daizj
linuxcpu内存硬盘大小
一、查看CPU信息的命令
[root@R4 ~]# cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
model name : Intel(R) Xeon(R) CPU X5450 @ 3.00GHz
model name :
- linux 踢出在线用户
dongwei_6688
linux
两个步骤:
1.用w命令找到要踢出的用户,比如下面:
[root@localhost ~]# w
18:16:55 up 39 days, 8:27, 3 users, load average: 0.03, 0.03, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
- 放手吧,就像不曾拥有过一样
dcj3sjt126com
内容提要:
静悠悠编著的《放手吧就像不曾拥有过一样》集结“全球华语世界最舒缓心灵”的精华故事,触碰生命最深层次的感动,献给全世界亿万读者。《放手吧就像不曾拥有过一样》的作者衷心地祝愿每一位读者都给自己一个重新出发的理由,将那些令你痛苦的、扛起的、背负的,一并都放下吧!把憔悴的面容换做一种清淡的微笑,把沉重的步伐调节成春天五线谱上的音符,让自己踏着轻快的节奏,在人生的海面上悠然漂荡,享受宁静与
- php二进制安全的含义
dcj3sjt126com
PHP
PHP里,有string的概念。
string里,每个字符的大小为byte(与PHP相比,Java的每个字符为Character,是UTF8字符,C语言的每个字符可以在编译时选择)。
byte里,有ASCII代码的字符,例如ABC,123,abc,也有一些特殊字符,例如回车,退格之类的。
特殊字符很多是不能显示的。或者说,他们的显示方式没有标准,例如编码65到哪儿都是字母A,编码97到哪儿都是字符
- Linux下禁用T440s,X240的一体化触摸板(touchpad)
gashero
linuxThinkPad触摸板
自打1月买了Thinkpad T440s就一直很火大,其中最让人恼火的莫过于触摸板。
Thinkpad的经典就包括用了小红点(TrackPoint)。但是小红点只能定位,还是需要鼠标的左右键的。但是自打T440s等开始启用了一体化触摸板,不再有实体的按键了。问题是要是好用也行。
实际使用中,触摸板一堆问题,比如定位有抖动,以及按键时会有飘逸。这就导致了单击经常就
- graph_dfs
hcx2013
Graph
package edu.xidian.graph;
class MyStack {
private final int SIZE = 20;
private int[] st;
private int top;
public MyStack() {
st = new int[SIZE];
top = -1;
}
public void push(i
- Spring4.1新特性——Spring核心部分及其他
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- 配置HiveServer2的安全策略之自定义用户名密码验证
liyonghui160com
具体从网上看
http://doc.mapr.com/display/MapR/Using+HiveServer2#UsingHiveServer2-ConfiguringCustomAuthentication
LDAP Authentication using OpenLDAP
Setting
- 一位30多的程序员生涯经验总结
pda158
编程工作生活咨询
1.客户在接触到产品之后,才会真正明白自己的需求。
这是我在我的第一份工作上面学来的。只有当我们给客户展示产品的时候,他们才会意识到哪些是必须的。给出一个功能性原型设计远远比一张长长的文字表格要好。 2.只要有充足的时间,所有安全防御系统都将失败。
安全防御现如今是全世界都在关注的大课题、大挑战。我们必须时时刻刻积极完善它,因为黑客只要有一次成功,就可以彻底打败你。 3.
- 分布式web服务架构的演变
自由的奴隶
linuxWeb应用服务器互联网
最开始,由于某些想法,于是在互联网上搭建了一个网站,这个时候甚至有可能主机都是租借的,但由于这篇文章我们只关注架构的演变历程,因此就假设这个时候已经是托管了一台主机,并且有一定的带宽了,这个时候由于网站具备了一定的特色,吸引了部分人访问,逐渐你发现系统的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据库和应用互相影响,应用出问题了,数据库也很容易出现问题,而数据库出问题的时候,应用也容易
- 初探Druid连接池之二——慢SQL日志记录
xingsan_zhang
日志连接池druid慢SQL
由于工作原因,这里先不说连接数据库部分的配置,后面会补上,直接进入慢SQL日志记录。
1.applicationContext.xml中增加如下配置:
<bean abstract="true" id="mysql_database" class="com.alibaba.druid.pool.DruidDataSourc