2022.11.27 第九次周报
文章目录
- 前言
- 一、论文阅读《Sequence to Sequence Learning with Neural Networks》
-
- 主要内容
- 模型结构
-
- 反转源句 Reversing the Source Sentences
- 实验
-
- 编码 encode
- 解码 decode
- 结果
- 论文总结
- 二、循环神经网络RNN公式推导
-
- RNN模型
- 前向计算
- 反向传播
-
- 误差项的计算
- 权重梯度的计算
- 三、LSTM学习
-
- 1.LSTM是什么
- 2.单元结构
- 3.每个结构的公式
- 总结
前言
this week,I read a paper on Long Short-Term Memory. In this paper, author presented a general end-to-end approach to sequence learning that used a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector. At the same time,mathematical expressions of RNN and the backpropagation problem were derived. I also learned the basic structure and mathematical formulas of LSTM。
本周,我看了关于LSTM的论文,文中的方法是使用多层长短期记忆(LSTM)将输入序列映射到一个固定维度的向量,然后再使用另一个深度长短期记忆(LSTM)从该向量解码目标序列。我还学习了RNN的数学推导和LSTM的结构。
一、论文阅读《Sequence to Sequence Learning with Neural Networks》
《Sequence to Sequence Learning with Neural Networks》是谷歌2014年发表的一篇神作(引用量上千),提出了sequence to sequence model,使用了LSTM模型。
主要内容
本文提出了一个端到端的方法(end-to-end)用于处理序列到序列的任务,利用多层的LSTM将input sequence 映射到一个固定维度的向量,使用另一个LSTM从这个向量解码出target sequence。sequence指的是由多个单词构成的序列/句子。本文提出的模型能够处理长句子;能够学习对单词次序敏感且相对于主动、被动语态不敏感的单词和句子表示。

我们的模型读取输入句子“ABC”并生成“WXYZ”作为输出句子。模型在输出句末令牌后停止进行预测。注意,LSTM反向读取输入语句,因为这样做会在数据中引入许多短期依赖性,从而使优化问题更加容易。
同时,LSTM的一个有用的特性是它学会将一个可变长度的输入句子映射到一个固定维的向量表示。鉴于译文往往是对源句的转述,翻译目标鼓励LSTM找到表达其意思的句子表示,因为意思相近的句子彼此接近,而不同的两个句子的意思会很远。一个定性的评价支持这一主张,表明我们的模型意识到词序,并对主动和被动语态相当不变。
模型结构
模型目标:

在这个方程中,每一个p(yt|v, y1,…, yt−1)的分布用对词汇表中所有单词的softmax表示。注意,我们要求每个句子以一个特殊的句末符号“”结束,这使模型能够定义所有可能长度的序列上的分布。总体方案如图1所示,所示的LSTM计算“A”、“B”、“C”、“EOS”的表示,然后使用该表示计算“W”、“X”、“Y”、“Z”、“EOS”的概率。
目的:找到概率最大的output sequence
反转源句 Reversing the Source Sentences
虽然LSTM能够解决长期依赖的问题,但我们发现,当源句颠倒(目标句没有颠倒)时,LSTM的学习效果更好。
但是作者对这一现象没有一个完整的解释,他们解释道:相信这是由于数据集引入了许多短期依赖性造成的。通常情况下,当我们将源句与目标句连接时,源句中的每个词都与目标句中相应的词有一定的距离。因此,该问题具有很大的“最小时滞”[17]。把源句中的单词倒过来,源语和目的语中对应单词之间的平均距离是不变的。然而,源语言的前几个单词现在非常接近目标语言的前几个单词,因此问题的最小时滞大大减少了。因此,反向传播可以更容易地在源句和目标句之间“建立通信”,进而大幅提高总体性能。
实验
任务描述:将英语翻译成法语
数据集:12M句子,输入词典(英文)160,000个词;输出词典(法语)80,000个词;不包含在词典中的词用UNK表示,映射到embedding中是一个确定的的向量。
编码 encode
实验的核心是在许多句子对上训练一个大而深的LSTM,通过最大化以下训练目标函数来训练这个网络,其中概率p是给定源句子S得到正确翻译T

S是训练集,训练完成后,根据模型找出最可能的翻译作为结果

解码 decode
我们使用一个简单的从左到右波束搜索解码器来搜索最可能的翻译,该解码器保持少量的B个部分假设,其中部分假设是某个翻译的前缀。在每个时间步中,我们用词汇表中的每一个可能的词扩展梁中的每个部分假设。这大大增加了假设的数量,因此根据模型的对数概率,我们丢弃了除B最有可能的假设之外的所有假设。只要“”符号被添加到一个假设之后,它就会从波束中移除,并被添加到完整假设集中。本文采用beam size = 2,即,每次都会选择概率最大的两个序列作为下一个时间步长的输入。
结果
本文采取了衡量指标BLEU,BLEU采用一种N-gram的匹配规则,比较模型预测的译文和参考译文之间的n组词的相似的占比。n=1,表示每次取1个单词进行两个译文之间的比较。

1.该模型对长句的翻译表现较好:左边的图显示了我们的系统的性能作为句子长度的函数,其中x轴对应于按长度排序的测试句子,并由实际的序列长度标记。小于35个单词的句子没有退化,最长的句子只有轻微退化。右边的图显示了LSTM在含有越来越多稀有词的句子上的表现,其中x轴对应于根据“平均词频排名”排序的测试句子。

模型能够捕获句子中次序的改变,如主语和宾语调换位置:图中显示了对图中短语进行处理后得到的LSTM隐藏状态的二维PCA投影。其中短语是按意义聚类的。模型的一个吸引人的特性是它能够将单词序列转换为一个固定维度的向量。
论文总结
作者实际使用的模型与LSTM有以下三方面的不同:
(1)使用了2个不同的LSTM,一个用于input sequence,一个用于output sequence,有助于训练多种语言对:输入是一种语言类型,输出可以是第二种,第三种等语言类型,这样训练得到的encoder部分可以和不同种类的decoder拼接,实现不同的任务;
(2)深层的LSTM的表现显著优于浅层LSTM,本文选用了4层的LSTM;
(3)模型采用逆序的方式输入input sequence,举例来说,不是把句子a,b,c映射为句子α,β,γ,而是把c,b,a映射为α,β,γ。这样做使得a非常靠近α,b非常靠近β,以此SGD就很容易在输入和输出之间"建立通信",这种简单的数据转换大大提高了LSTM的性能。
二、循环神经网络RNN公式推导
经过上周对RNN模型的了解,如今已经基本弄懂模型的构造了,所以本周开始学习RNN模型的公式推导。
RNN模型
在传统的神经网络中,主要包含输入层、隐藏层、输出层三个部分。在RNN神经网络中,也是如此,但不同的是在隐藏层中对了一个循环结构,其基本的图示如下:

这里激活函数用到的是tanh函数,在其他RNN模型中也有relu和sigmoid函数的,其中relu函数效果最好。
隐藏层展开之后的图像:

只要输入元素X足够多,循环可以一直进行下去,并且前面提取到的特征会一直对后面的特征提取的结果产生影响。
前向计算
用这张图做例子,进行演算:
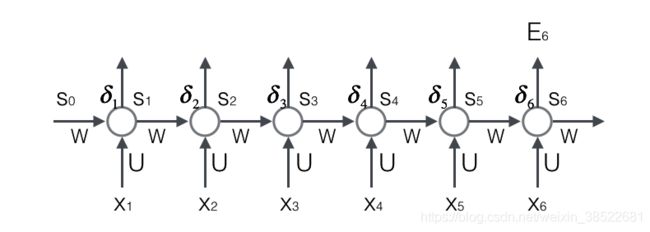
其输出的结果: St=f(UXt+WSt-1)(这里为了直观,省去了截距b)
上面的St、Xt、St-1都是向量,用黑体字母表示;而U、V是矩阵,用大写字母表示。向量的下标表示时刻,例如,St表示在t时刻向量s的值。
我们假设输入向量x的维度是m,输出向量s的维度是n,则矩阵U的维度是n × m ,矩阵W的维度是n × n 。下面是上式展开成矩阵的样子,看起来更直观一些:

在这里我们用手写体字母表示向量的一个元素,它的下标表示它是这个向量的第几个元素,它的上标表示第几个时刻。例如,
Sjt 表示向量s的第j个元素在t时刻的值。
Uji表示输入层第i个神经元到循环层第j个神经元的权重。
Wjt表示循环层第t-1时刻的第i个神经元到循环层第t个时刻的第j个神经元的权重。
反向传播
循环神经网络的训练算法:BPTT
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的两个步骤:
1.反向计算每个神经元的误差项δj值,它是误差函数E对神经元j的加权输入netj的偏导数;
2.计算每个权重的梯度。
误差项的计算
BTPP算法将第l层t时刻的误差项值δjl沿两个方向传播,一个方向是其传递到上一层网络,得到δjl-1 ,这部分只和权重矩阵U有关;另一个是方向是将其沿时间线传递到初始时刻t1 ,得到δjl ,这部分只和权重矩阵W有关。
我们用向量nett表示神经元在t时刻的加权输入:

接着把两项相乘:

循环层将误差项反向传递到上一层网络,因为没有涉及到上一个时刻的输出,所以与普通的全连接层是完全一样的。

权重梯度的计算
现在,我们终于来到了BPTT算法的最后一步:计算每个权重的梯度。
前提还是在这条公式的基础上:nett=UXt+WSt-1
首先,我们计算误差函数E对权重矩阵W的梯度:

这就是计算循环层权重矩阵W的梯度公式。
然后计算权重U,同权重矩阵W类似,我们可以得到权重矩阵U的计算方法。

最终的梯度∇ UE是各个时刻的梯度之和。
当然还有截距b,也是求导之后对所有时刻的求和,但这里就不再介绍了。
三、LSTM学习
RNN是想把所有的信息都记住,包括有用的和没用的信息。于是产生很多的冗余。于是人们想出了LSTM,设计一个记忆细胞,具备选择性记忆的功能,可以选择记忆有用的信息,过滤掉噪音信息,减轻记忆负担。
同时,RNN存在梯度爆炸和梯度消失的现象,梯度消失不是指后面时刻参数更新的时候梯度为0,而是后面时刻的梯度更新的时候,前面更远时刻的序列对参数更新不起作用,梯度被近距离梯度主导,所以说RNN无法捕捉长期依赖。LSTM也对此进行了改良。
1.LSTM是什么
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
有这样的:

也有这样的:

当然,虽然图像表示不一样,但核心万变不离其中,三个输入,三个门(遗忘门,更新门,输出门),三个输出。
2.单元结构
输入:和RNN不同,LSTM有三个输入,一个是当前序列的输入Xt,一个是上一个单元的输出,本单元的输入ht-1,另一个是上一个单元保留的内容Ct-1。
门:遗忘门:遗忘门经过计算后是一串0或1的序列,用于保留或是遗忘部分上一单元的保留的内容Ct-1。
更新门:接受本单元的序列和上一单元的输出,整合更新,然后添加到要输出的本单元的内容Ct中。
输出门:接受本单元的序列和上一单元的输出,再和Ct整合,得到最后的输出ht。
输出:三个输出,一个是本单元的输出,下一单元的输入ht,一个是本单元要保留的内容Ct,还有一个是本单元的最终输出,在Ct的基础上在调整,计算出Yt。
3.每个结构的公式

最后是LSTM如何缓解梯段消失问题,有点复杂。下周再学。
总结
本周学习了关于使用LSTM的一篇论文,他是把LSTM模型引入了机器翻译中,并且提出了把原句翻转的方法,但是也没用给出为什么,不过的确提高看准确度。这个思想可以学习一下–翻转原句。本周还学习了RNN正反向的数学公式的推导,和LSTM模型的结构。