论文笔记:Exploring Pre-trained Language Models for Event Extraction and Generation
作者:陈宇飞
单位:燕山大学
论文地址:https://www.aclweb.org/anthology/P19-1522/
目录
- 一、摘要
- 二、引言
- 三、相关工作
- 四、模型
-
- 4.1 触发词抽取模型
- 4.2 元素抽取模型
- 4.3 元素跨度的确定
- 五、训练数据的生成
-
- 5.1 预处理
- 5.2 事件生成
- 5.3 评分
- 六、实验结果
一、摘要
传统的事件抽取(EE)任务目前有两个主要问题,一是事件抽取本身的困难,还有就是不足的训练数据阻碍了学习过程。所以,本文的主要工作分为两部分,首先是提出了一个事件提取模型PLMEE,来解决角色重叠问题,然后还提出一种通过编辑原型自动生成标记数据的方法。
二、引言
在一个句子中一个元素可能扮演两个或者多个角色,这就是角色重叠问题。例如,”The explosion killed the bomber and three shoppers”,killed会触发Attack事件,而论元“bomber”会同时扮演袭击者和受害者两个角色,这就出现了角色重叠问题。而在现今的研究中,很少有人注意到这一点,绝大多数现有的模型,在进行分类时如果成功预测出了元素对应了多个角色中的一个,就认为分类正确。所以本文提出了一种有效的机制来解决这个问题。
另一个问题是现有的事件抽取任务都是通过大量的有标注的数据来进行有监督学习的,在本文中提出使用预训练模型,试图利用从大规模语料库中学习到的知识来生成事件。本文提出的基于预训练模型的框架,包括一个事件抽取模型作为框架的基线和一个标记事件的生成方法。其中事件抽取模型由一个触发词抽取模型和一个元素抽取模型组成,元素抽取模型引用触发词抽取模型的结果进行推理。此外,根据角色的重要性重新加权损失函数来提高元素抽取模型的性能。
三、相关工作
事件抽取现在主要分成两类:句子级和文档级的。本文主要研究句子级的事件抽取。句子级可以细分为基于特征的和基于神经网络的。
事件生成通常使用Freebase、Frame-Net、WordNet等外部资源生成事件,丰富训练数据。此外还有基于一个强大的远距离监督假设来标注无监督语料库中的事件,这种强假设规定若两个实体在外部知识库中存在某种关系,则认为所有提及这两个实体的句子,句子中的这两个实体也存在这种关系。基于这种强假设,在无监督的语料上进行事件的标注。但实际上共现的实体不一定就会有这种关系。
现在流行的预训练模型:ELMO、LSTM、GPT、BERT。
四、模型
模型分为两部分:(1)触发词抽取模型;(2)元素抽取模型。

4.1 触发词抽取模型
在Bert预训练模型的基础上添加一个多分类器。模型的输入是Bert的三种原始输入类型。在大多数情况下,触发词是短语,所以本文将共享相同预测标签的连续令牌视为一个完整的触发词。使用交叉熵损失函数用于微调。
4.2 元素抽取模型
元素抽取所面临的三大问题:元素对触发词的依赖性、元素多为长名词短语、角色重叠问题。为了解决后两个问题,本文在Bert上加了多组二元分类器,每组分类器为一个角色提供服务,以确定扮演它的所有元素的span(每个跨度包括开始和结束)。由于预测与角色分离,一个元素可以扮演多个角色,一个标记可以属于不同的元素。因此,角色重叠问题也可以得到解决。
4.3 元素跨度的确定
在PLMEE模型中,一个token t 被预测为角色r的元素的start的概率为:

在PLMEE模型中,一个token t 被预测为角色r的元素的end的概率为:
![]()
其中 W W W是各个分类器的权重,权重不共享, B B B为Bert的embedding。
对于每个角色 r r r,我们可以根据 P s r P_s^r Psr和 P e r P_e^r Per得到两个列表 B s r B_s^r Bsr和 B e r B_e^r Ber(分别为0和1)。它们分别表示句子中的一个标记是扮演角色 r r r的一个元素的开始还是结束。如下所示的算法1用于检测每个token,来决定扮演角色r的所有元素的spans:

算法1包含一个有限状态机,根据 B s r B_s^r Bsr和 B e r B_e^r Ber从一个状态变为另一个状态,其中包含三种状态:(1)既没有检测出start,也没有检测出end;(2)只检测出了start;(3)既检测到了start,也检测到了end。规定在预测的时候如果出现在预测某个词为开始后,在没有出现结束预测时,又出现了一个开始的预测,则按照预测的概率大小来选择开始。
五、训练数据的生成
基于预训练模型,生成数量可控的标注样本作为额外的训练语料,它包括:数据预处理、事件生成和评分。
在进行事件生成的时候,采用元素替换的时候,替换之后的语义相似度使用余弦相似度的方法来衡量,使用ELMO来做嵌入。
5.1 预处理
本文采用Bert作为目标模型来重写adjunct tokens,并使用Bert的masked语言模型任务在ACE2005数据集上进行微调。
5.2 事件生成
为了生成事件,本文首先用那些扮演相同角色的相似元素替换原型中的元素。然后用经过微调的Bert来重写adjunct tokens。
使用余弦相似度来衡量两个元素的相似度。由于ELMO处理OOV问题的能力,我们使用它来嵌入元素:

其中a是元素,E是ELMO嵌入。我们选择前10%最相似的元素作为候选,并对它们的相似度使用 s o f t m a x softmax softmax运算来分配概率。
5.3 评分
理论上事件是可以无限生成的,但是有的事件往往对提取模型是没有价值的,甚至会影响模型的性能。所以,本文提出了两种评估质量的方法。
(1)困惑度(PPL):
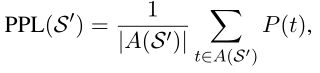
其中A是 S ‘ S^‘ S‘中被重写的adjunct tokens的集合。
(2)距离使用余玄相似度:
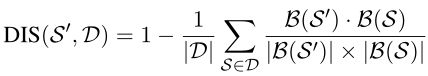
高质量的事件应该具有较低的困惑度和较大的距离。
六、实验结果
