TensorFlow2+OpenCV实现人像采集与识别
TensorFlow2+OpenCV实现人像采集与识别
- 前言
- 1、图像检测和采集
- 2、图像预处理
- 3、网络搭建和模型训练
- 4、人脸图像匹配与识别
前言
本设计用python语言实现,这里罗列一下整个项目所需要的包(仅供参考)
h5py==2.9.0
Keras==2.3.1
scipy==1.5.2
numpy==1.19.5
scikit-learn==0.24.1
tensorflow==2.1.0
opencv-python==4.5.1.48
人脸识别四个步骤,分别为人脸图像检测和采集,图像预处理,网络搭建和模型训练,人脸图像匹配与识别。
1、检测一张图片中的所有人脸,初次使用需要采集人脸图像保存到本地供模型训练时使用。
2、对于采集的每一张人脸图像,其大小一般都不相同,需要对其处理成相同大小,并对每一张图片进行标注。
3、本项目使用卷积神经网络训练模型,所以首先搭建好网络框架,并使用预先处理好的数据训练模型。
4、输入一张人脸图像,使用训练好的模型识别图像中的人是谁。
1、图像检测和采集
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉和机器学习软件库,用C++语言编写,它提供了很多图像处理和计算机视觉方面的通用算法,本项目中人脸图像的检测和采集都是通过OpenCV实现的,但是这里你并不需要特意去学习OpenCV(其实我会的也不多☺),只需要调用其中的API函数就可以了。
首先是采集人脸图像构成数据集,建立pic_capture.py文件:
import cv2
def face_pic_capture(window_name, camera_id, catch_pic_num, path_name):
CreateFolder(path_name) #[1]
cv2.namedWindow(window_name)
image_set = cv2.VideoCapture(camera_id) #[2]
classifier = cv2.CascadeClassifier(r"D:\anaconda3\envs\tensorflow\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml") #[3]
num = 1 #用于对每张图片命名
while image_set.isOpened(): #[4]
flag, frame = image_set.read() #[5]
if not flag:
break
image_grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faceRect = classifier.detectMultiScale(image_grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32)) #[6]
if len(faceRect) > 0: # 大于0则检测到人脸
for facet in faceRect: #[7]
x, y, w, h = facet
if w > 100:
img_name = '{}/{}.jpg'.format(path_name, num)
image = frame[y - 10: y + h + 10, x - 5: x + w + 5]
cv2.imwrite(img_name, image) #检测到有人脸的图像帧保存到本地
cv2.rectangle(frame, (x - 5, y - 10), (x + w + 5, y + h + 10), (0, 0, 255), 3) #[8]
font = cv2.FONT_HERSHEY_SIMPLEX
# 显示当前保存了多少张图片,
cv2.putText(frame, "num:{}".format(num), (x + 30, y - 15), font, 1, (0, 250, 250), 4) #[9]
num += 1
if num > catch_pic_num:
break
if num > catch_pic_num:
break
# 显示图像,按"Q"键中断采集过程
cv2.imshow(window_name, frame)
if cv2.waitKey(200) & 0xFF == ord('q'):
break
# 释放摄像头并关闭销毁所有窗口
image_set.release()
cv2.destroyAllWindows()
首先导入opencv模块,cv2中的”2”并不表示OpenCV的版本号。我们知道,OpenCV是基于C/C++的,”cv”和”cv2”表示的是底层CAPI和C++API的区别,”cv2”表示使用的是C++API。
在函数定义中,括号内参数window_name, camera_id, catch_pic_num, path_name分别表示窗口名字,摄像头系列号,采集照片数量和图片存储路径,可以根据自己需要进行修改。咱们这里为了精度高一点,选择捕捉1000张脸部照片。由于精度的问题,在程序运行的过程中常常会采集到非脸部的照片,所以catch_pic_num设置比预期大些,从而清洗掉非脸部照片后数据集不至于太少。另外,在这里不只是采集一个人的人脸图片,所以将不同的人照片单独存储在一个文件夹下,不可弄混。数据保存结果截图如下:


[1] CreateFolder()函数用于检测传递过来的文件路径是否存在,如果路径不存在就创建该路径。
[2] cv2.VideoCapture()是OpenCV的一个API,参数camera_id为0,表示打开笔记本的内置摄像头,如果是视频文件路径则打开本地视频,有的设为1表示打开外接摄像头。
[3] cv2.CascadeClassifier是Opencv中做人脸检测的时候的一个级联分类器,找到这个路径并且复制到程序中(最好使用绝对路径),这个东西的作用主要是实现对人脸识别的功能,该路径下还有其他功能的haarcascades API:
人脸检测器(默认):haarcascade_frontalface_default.xml
人脸检测器(快速Harr):haarcascade_frontalface_alt2.xml
人脸检测器(侧视):haarcascade_profileface.xml
眼部检测器(左眼):haarcascade_lefteye_2splits.xml
眼部检测器(右眼):haarcascade_righteye_2splits.xml
嘴部检测器:haarcascade_mcs_mouth.xml
鼻子检测器:haarcascade_mcs_nose.xml
身体检测器:haarcascade_fullbody.xml
人脸检测器(快速LBP):lbpcascade_frontalface.xml
[4] image_set.isOpened():判断视频对象是否成功读取,成功读取视频对象返回True。
[5] flag, frame = image_set.read():按帧读取视频,返回值flag是布尔型,正确读取则返回True,读取失败或读取视频结尾则会返回False;frame为每一帧的图像,为三维矩阵、BGR格式。
[6] classifier.detectMultiScale()是OpenCV2中的人脸检测函数,并将人脸用vector保存各个人脸的坐标、大小(用矩形表示),函数由分类器对象调用。
函数原型:
void detectMultiScale(
> const Mat& image,
> CV_OUT vector<Rect>& objects,
> double scaleFactor = 1.1,
> int minNeighbors = 3,
> int flags = 0,
> Size minSize = Size(),
> Size maxSize = Size()
> );
函数介绍:
参数1:image—输入图片,一般转换为灰度图像加快检测速度;
参数2:objects—被检测物体的矩形框向量组;
参数3:scaleFactor—图像缩放比例,表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1,即每次搜索窗口依次扩大10%。
参数4:minNeighbors—表示构成检测目标的相邻矩形的最小个数,默认为3(每一个特征匹配到的区域都是一个矩形框,只有多个矩形框同时存在的时候,才认为是匹配成功)。
参数5:flags—要么使用默认值0,要么取如下这些值:
1:CASCADE_DO_CANNY_PRUNING,利用canny边缘检测来排除一些边缘很少或者很多的图像区域
2:CASCADE_SCALE_IMAGE,正常比例检测
4:CASCADE_FIND_BIGGEST_OBJECT,只检测最大的物体
8:CASCADE_DO_ROUGH_SEARCH,初略的检测
参数6/7:minSize和maxSize用来限制得到的目标区域的范围。
[7] 对同一个画面有可能出现多张人脸,所以这里用一个for循环将所有检测到的人脸都读取出来,然后返回检测到的每张人脸在图像中的起始坐标(左上角,x、y)以及长、宽(h、w)。
[8] cv2.rectangle()完成画框的工作,这里外扩了几个像素以框出比人脸稍大一点的区域。函数的最后两个参数一个用于指定矩形边框的颜色,一个用于指定矩形边框线条的粗细程度。
[9] cv2.putText(image, text, (5,50 ), cv2.FONT_HERSHEY_SIMPLEX, 0.75,(0, 0, 255), 2)各参数依次表示:输出图片,要添加的文字,文本左上角坐标,字体类型,字体大小,字体颜色,字体粗细。
运行结果:

到此,顺利检测到视频中的人脸,并构建了数据集,接下来开始对图像进行预处理!
2、图像预处理
这一部分代码实现将数据集内的图像裁剪成相同大小,并对每张图像标注。首先建立一个python文件,命名data_process.py:
- 定义一个risize_image()函数裁剪图像:
def resize_image(image, height=IMAGE_SIZE, width=IMAGE_SIZE):
top, bottom, left, right = (0, 0, 0, 0) # 初始化图像尺寸
h, w, _ = image.shape
longer_edge = max(h, w)
#计算短边需要增加多上像素宽度使其与长边等长
if h < longer_edge:
dh = longer_edge - h
top = dh // 2
bottom = dh - top
elif w < longer_edge:
dw = longer_edge - w
left = dw // 2
right = dw - left
else:
pass
adjusted_image = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=[120, 120, 220]) #[1]
return cv2.resize(adjusted_image, (height, width))
IMAGE_SIZE是预先设置的图像像素大小,可以自行更改。
[1] cv2.copyMakeBorder()函数用于给图片添加边界,就像一个相框一样的东西。
cv2.copyMakeBorder(src,top, bottom, left, right ,borderType,value)
参数解释:
src:源图像
top,bottem,left,right:分别表示四个边界方向上扩充像素数
borderType:边界的类型有以下几种:
BORDER_REFLICATE
BORDER_REFLECT
BORDER_REFLECT_101
BORDER_WRAP
BORDER_CONSTANT
value:边界类型为cv.BORDER_CONSTANT时的边界框颜色
resize_image()函数先判断图片是不是正方形,如果不是则增加短边的长度使之变成正方形。这样再调用cv2.resize()函数就可以实现等比例缩放了,只有缩放之前图像为正方形才能确保图像不失真。例如:

这样明显不是正方形,程序运行之后要达到下图效果。
- 接下来对图像进行标注,对每一张图像设置一个标签
def read_path(path_name, h=IMAGE_SIZE, w=IMAGE_SIZE):
for dir_item in os.listdir(path_name):
# 从初始路径开始叠加,合并成可识别的操作路径
full_path = os.path.abspath(os.path.join(path_name, dir_item))
if os.path.isdir(full_path): # 如果是文件夹,继续递归调用
read_path(full_path, h, w)
else:
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, h, w)
images.append(image)
labels.append(path_name)
return images, labels
# 为每一类数据赋予唯一的标签值
def label_id(label, users, user_num):
for i in range(user_num):
if label.endswith(users[i]):
return i
# 从指定位置读数据
def load_dataset(path_name):
users = os.listdir(path_name) # 返回指定的文件夹包含的文件或文件夹的名字的列表
user_num = len(users)
Image, Label = read_path(path_name)
images_np = np.array(Image)
labels_np = np.array([label_id(label, users, user_num) for label in Label]) #[2]
return images_np, labels_np
[2] 这里每个图像数据集唯一的对应一个人,直接使用文件夹名称作为标签,简单方便,即上面将不同的人的图像集分别放置的目的。
3、网络搭建和模型训练
这里建立了一个包含4个卷积层的神经网络(CNN),程序利用这个网络训练我的人脸识别模型,并将最终训练结果保存到本地硬盘。如果对卷积神经网络不清楚建议自行百度!
新建一个python文件,命名为:face_train。添加如下代码:
class Model:
def __init__(self):
self.model = None
def build_model(self, n):
self.model = Sequential([
# Conv-Conv-Pooling_1 32个3x3卷积核
layers.Conv2D(32, kernel_size=3, padding='same', activation='relu'),
layers.Conv2D(32, kernel_size=3, padding='same', activation='relu'),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Dropout(rate=0.2),
# Conv-Conv-Pooling_2 64个3x3卷积核
layers.Conv2D(64, kernel_size=3, padding='same', activation='relu'),
layers.Conv2D(64, kernel_size=3, padding='same', activation='relu'),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
layers.Dropout(rate=0.3),
layers.Flatten(),
layers.Dense(256, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dropout(rate=0.5),
layers.Dense(n, activation='softmax')
])
self.model.build(input_shape=[None, 64, 64, n])
print(self.model.summary())
通过model.summary()输出模型各层的参数状况如下:
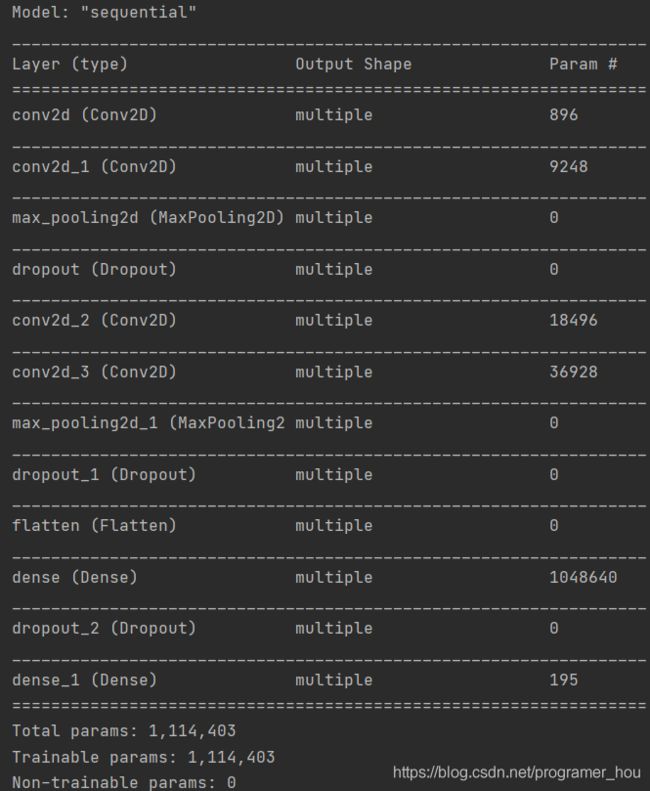 通过这些参数,可以看到模型各个层的组成(dense表示全连接层),param表示每层的参数个数。
通过这些参数,可以看到模型各个层的组成(dense表示全连接层),param表示每层的参数个数。
搭建好了网络模型,下面就要训练了,但是在这之前还要对前面的数据做一些处理,因为TensorFlow处理的是Tensor(张量),所以需要将前面的RGB格式的图像转换成张量格式。
images, labels = load_dataset(self.path_name) # 加载数据集
train_images, test_images, train_labels, test_labels = train_test_split(images, labels, test_size=0.25, random_state=random.randint(0, 100)) #[1]
train_images = tf.cast(train_images, dtype=tf.float32) / 255. # 归一化
test_images = tf.cast(test_images, dtype=tf.float32) / 255.
train_labels = tf.one_hot(tf.cast(train_labels, dtype=tf.int32), depth=self.user_num) # 设置标签为one_hot格式
test_labels = tf.one_hot(tf.cast(test_labels, dtype=tf.int32), depth=self.user_num)
[1] train_test_split()函数用来随机划分样本数据为训练集和测试集,也可以人为的切片划分。
train_data:待划分样本数据集
train_target:待划分样本数据的标签
test_size:测试数据占样本数据的比例,若整数则样本数量
random_state:随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样
#训练模型,添加train_net函数:
def train_net(self, datasets, batch_size, n_epoch):
# momentum:动量参数;decay:每次更新后的学习率衰减值; nesterov:布尔值,确定是否使用nesterov动量
self.model.compile( optimizer=optimizers.SGD(lr=0.01, momentum=0.9, decay=1e-6,nesterov=True),
loss=losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
self.model.fit(datasets.train_images,
datasets.train_labels,
batch_size=batch_size,
epochs=n_epoch,
verbose=1, # 日志显示,0:不在标准输出流输出日志信息,1:输出进度条记录,2:每个epoch输出一行记录
validation_split=0.2,
# validation_data=(datasets.valid_images, datasets.valid_labels),
shuffle=True)
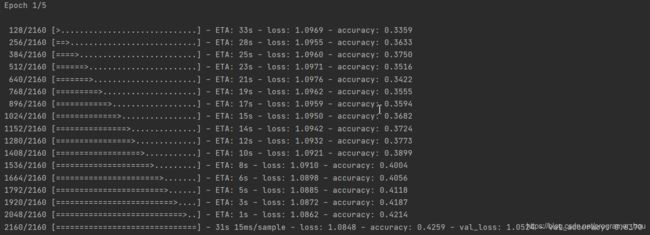 训练过程如上图,由于我提供的数据集比较简单,很容易就能达到很高的精度,所以只设置了5个epoch。
训练过程如上图,由于我提供的数据集比较简单,很容易就能达到很高的精度,所以只设置了5个epoch。
接下来把训练好的模型参数保存,供下次直接使用,在文件下定义save_model函数:
def save_model(self, file_path=MODEL_PATH):
self.model.save(file_path)
# self.model.save_weights(r'..\model\weights.ckpt') #[2]
print('saved weights!')
[2] 这里提供了两种模型保存方式,model.save_weights()方法保存与加载网络的方式最为轻量级,但文件中仅保存参数张量的数值,没有其他额外的结构参数。需要使用相同的网络结构才能够恢复网络状态,一般在拥有网络源文件的情况下使用。
最后再通过模型的evaluate()方法评估网络性能:
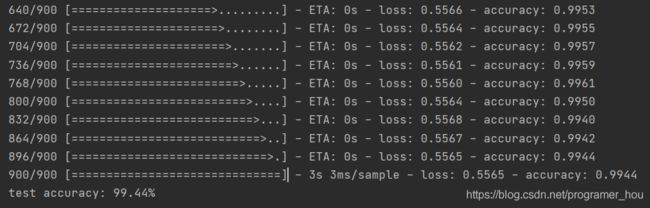
可以看到,数据验证的准确率达到了99.44%,结果较为理想。到这里,我们最重要的训练数据也完成了,加下来就是验证我们训练数据的效果的时候了。
4、人脸图像匹配与识别
新建python文件,命名:face_recognition.py:
首先,定义一个开关SWITCH,每次程序运行时检查SWITCH状态,SWITCH=0表示识别人脸状态,SWITCH=1表示有新用户加入,调用enter_new_user()函数采集新用户图像集并重新训练模型。
if SWITCH == 1:
enter_new_user(data_path) # enter_new_user()函数在pic_capture文件内定义
train(data_path)
接下来加载训练好的模型,打开电脑摄像头识别人脸。
model.load_model(file_path=r'../face_recognition/model/train_model.h5')
images = cv2.VideoCapture(0) # 打开摄像头
while True:
flag, frame = images.read()
if flag:
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
continue
#使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(r"D:\anaconda3\envs\tensorflow\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml")
# 利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
image = frame[x - 5: x + w + 5, y - 10: y + h + 10]
faceID = model.face_predict(image, 64, 64) #[1]
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), (0, 255, 255), thickness=2)
for i in range(len(os.listdir(data_path))):
if i == faceID:
cv2.putText(frame, os.listdir(data_path)[i],(x + 30, y + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 255), 2)
print("Welcome, Mr." + os.listdir(data_path)[i])
break
else:
print("Unrecognized, please try again!\n")
continue
# break
cv2.imshow("who am I", frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
images.release()
cv2.destroyAllWindows()
[1] 将检测到的人脸图像送到face_predict函数,预测这张脸是谁。model提供的predict函数返回一个n列的数组,n是用户个数,数组的每个值是一个小数,表示预测为每个人的概率,tf.argmax()选取概率值最大的那个人作为预测结果。
此外,只有当max(result[0]) >= 0.9时认为预测的结果是可靠的,否则拒绝,在一定程度上保证的预测的精度。
def face_predict(self, image, height, width):
image = resize_image(image)
image = image.reshape((1, height, width, 3))
image = tf.cast(image, dtype=tf.float32) / 255.
# 给出输入属于各个类别的概率
result = self.model.predict(image) # 返回一个n行k列的数组,[i][j]是模型预测第i个预测样本为标签j的概率,每一行概率和为1
print('result:', result)
if max(result[0]) >= 0.9:
return tf.argmax(result, axis=1)
else:
return -1
最终结果如下图:
到这里,人脸识别大功告成!
完整代码下载☞https://github.com/weich-hou/face-recognition