Java中间件-Elasticsearch
Elasticsearch 是一个非常强大的搜索引擎。它目前被广泛地使用于各个 IT 公司。Elasticsearch 是由 Elastic 公司创建。它的代码位于 GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine。目前,Elasticsearch 是一个免费及开放(free and open)的项目。同时,Elastic 公司也拥有 Logstash 及 Kibana 开源项目。这个三个项目组合在一起,就形成了 ELK 软件栈。他们三个共同形成了一个强大的生态圈。简单地说,Logstash 负责数据的采集,处理(丰富数据,数据转换等),Kibana 负责数据展示,分析,管理,监督及应用。Elasticsearch 处于最核心的位置,它可以帮我们对数据进行快速地搜索及分析。
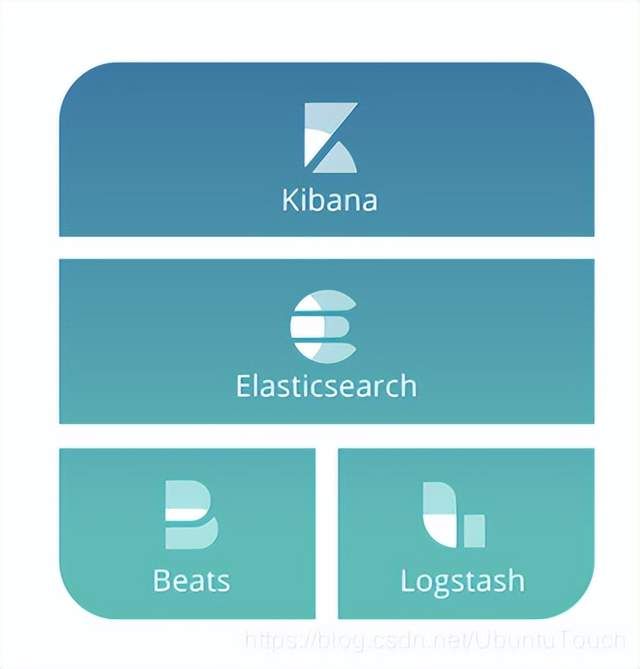
事实上 Elasticsearch 的完整栈有如下的几个:
Beats
Elasticsearch
Kibana
Logstash
Beats 是一些轻量级可以允许在客户端服务器中的代理。它并不需要部署到我们的 Elastic 云中。它可以帮我们收集所有需要的事件。如果把 Beats 也纳入到我的架构中,那么 Elastic 的栈可以表述为:
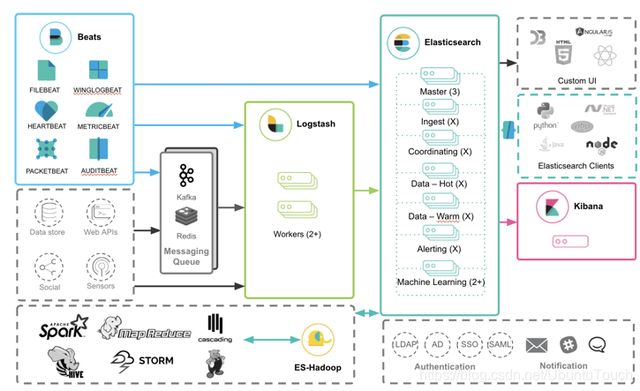
在 Elastic 公司,我们称上面的技术栈为 Elastic Stack。
Elastic Stack 简介及安装
在全世界范围内有非常多的公司在使用 Elastic Stack。它们分布在不同的领域:
你可以在 Elastic 的官方地址找到更多的关于客户的信息。
在今天的这篇文章中,我来简单地介绍一下什么是 Elasticsearch。
Elastic is a Search Company
Elastic 产品生态
Elastic 围绕 Elasticsearch 已经建立了许多成熟的方案。更多详情请参阅我们的官方网站 Free and Open Search: The Creators of Elasticsearch, ELK & Kibana | Elastic。
Elasticsearch
简单地说, Elaaticsearch 是一个分布式的使用 REST 接口的搜索引擎。它的产品可以在Elasticsearch: The Official Distributed Search & Analytics Engine | Elastic 进行下载。Elasticsearch 是一个分布式的基于 REST 接口的为云而设计的搜索引擎,它的功能包括:
Elasticsearch是一个基于 Apache Lucene (TM)的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。在 1999 年,Doug Cutting 创建了一个叫做 Lucene 的开源项目:
一个完全用 Java 编写的搜索引擎库
截止2005年,是一个顶级的 Apache 开源项目
提供强大的全文搜索功能
但是,Lucene 只是一个库。Lucene 本身并不提供高可用性及分布式部署。想要发挥其强大的作用,你需使用 Java 并要将其集成到你的应用中。Lucene 非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
在 2004 年, Shay Banon,也就是现在 Elastic 的 CEO,开发了一个叫做 Compass 的开源项目:
构建于 Lucence 之上
目的是使得 Lucene 搜索更容易集成到 Java 应用中去
可扩展性变得尤为重要
在 2010 年,Shay 完全重新编写了 Compass 以实现如下的两个目的:
从一开始设计之初,分布式部署贯穿整个设计
可方便地使用其它的语言进行对接使用

Shay 最终把这个项目称之为 Elasticsearch,并于当年10月发布与 github 上。如果你对 Elasticsearch 的历史更感兴趣的话,请阅读另外一篇我同事写的文章 “Elasticsearch 的前世今生”。
Elasticsearch 也是使用 Java 编写并使用 Lucene 来建立索引并实现搜索功能,但是它的目的是通过简单连贯的 RESTful API 让全文搜索变得简单并隐藏 Lucene 的复杂性。
不过,Elasticsearch 不仅仅是 Lucene 和全文搜索引擎,它还提供:
分布式的实时文件存储,每个字段都被索引并可被搜索
实时分析的分布式搜索引擎
可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据
而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。上手 Elasticsearch 非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。Elasticsearch 在 Elastic V2 及 SSPL 下许可使用,可以免费下载、使用和修改。 随着知识的积累,你可以根据不同的问题领域定制 Elasticsearch 的高级特性,这一切都是可配置的,并且配置非常灵活。
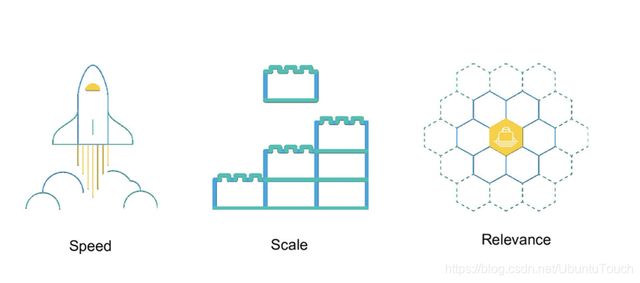
Elasticsearch 的特点是它提供了一个极速的搜索体验。这源于它的高速(speed)。相比较其它的一些大数据引擎,Elasticsearch 可以实现秒级的搜索,但是对于它们来说,可能需要数小时或更长才能完成。Elasticsearch 的 cluster 是一种分布式的部署,极易扩展(scale)。这样很容易使它处理 petabytes 的数据库容量。最重要的是 Elasticsearch 是它搜索的结果可以按照分数进行排序,它能提供我们最相关的搜索结果(relevance)。我们可以依据自己的业务场景有正对性地进行 relevance 定制。
分布式及高可用性的搜素引擎
- 每个索引(index)都使用可配置数量的分片进行完全分片
- 每个分片都可以有一个或多个副本
- 在任何副本分片上可执行读取/搜索操作
多租户
- 支持多个索引
- 索引级别配置(分片数,索引存储,......)
各种API
- HTTP RESTful API
- Native Java API
- 所有 API 都执行自动节点操作重新路由

面向文档
无需前期定义 schema (文档结构)
可以定义 schema 以定制索引过程
可靠,异步写入,可实现长期持续性
(近)实时搜索
建在 Lucene 之上
每个分片都是一个功能齐全的 Lucene 索引
Lucene 的所有功能都可以通过简单的配置/插件轻松暴露出来
每次操作一致性
单文档级操作具有原子性,一致性,隔离性和持久性。
入门指南
首先,不要恐慌。 获得 Elasticsearch 的全部内容需要5分钟。
前提要求
你需要在你的电脑上安装最新的 Java(在最新的版本中,Java 可以不用安装,因为在安装包中已经含有 Java 的安装包)。你可查看 setup 链接得到更多的信息。
安装
你可以到链接 Download 里去下载 Elasticsearch 最新的发布版。可以参考文档 “Elastic:开发者上手指南” 来安装 Elasticsearch
在 Unix/Linux上运行 bin/elasticsearch,或在 Windows 上运行 bin\elasticsearch.bat
运行 curl -X GET http://localhost:9200。你在 Windows 上可以安装 cygwin 来运行 curl 指令
运行更多的服务器...