【自动驾驶】《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation》论文阅读笔记
论文地址:https://arxiv.org/pdf/2205.13542.pdf https://arxiv.org/pdf/2205.13542.pdf
https://arxiv.org/pdf/2205.13542.pdf
代码地址:GitHub - mit-han-lab/bevfusion: BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View RepresentationBEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation - GitHub - mit-han-lab/bevfusion: BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation https://github.com/mit-han-lab/bevfusion
https://github.com/mit-han-lab/bevfusion
1.摘要
多传感器融合对于准确和可靠的自动驾驶系统至关重要。最近的方法是基于点级融合:用相机的特征来增强LiDAR的点云。然而,相机到激光雷达的投影丢掉了相机特征的语义密度,阻碍了这种方法的有效性,特别是对于面向语义的任务(如三维场景分割)。
在本文中,我们用BEVFusion打破了这一根深蒂固的惯例,BEVFusion是一个高效和通用的多任务多传感器融合框架。它将多模态特征统一在共享的鸟瞰图(BEV)表示空间中,这很好地保留了几何和语义信息。为了实现这一目标,我们通过优化鸟瞰图池,诊断并解除了视图转换中的关键效率瓶颈,将延迟减少了40倍以上。BEVFusion从根本上是任务无关的,几乎不需要改变架构就能无缝支持不同的3D感知任务。它确立了nuScenes的新技术水平,在3D物体检测上实现了1.3%的mAP和NDS,在BEV地图分割上实现了13.6%的mIoU,计算成本降低1.9倍。
2.介绍
自动驾驶场景需要各种各样的传感器,比如说谷歌Waymo自动驾驶公司,用到了26个camera,6个radar,5个LiDAR。camer可以捕捉到丰富的语义信息,LiDARs可以获得精确的空间位置信息,radar能进行瞬时速度估计。
camera信息主要在可视平面上,LiDAR则在3D平面上。两者存在一定的差异,所以作者想到要将两者统一到一个平面上。

图a,这种LiDAR-to-camera的投影引入了 严重的几何失真。
图b,只有5%的相机特征会被匹配到LiDAR点上,而其他的都会被放弃。
图c,提出BEVFusion,在一个共享的鸟瞰图中统一多模式特征(BEV),同时保持几何结构和语义密度;且支持大部分的3D感知任务。

BEVFusion拥有比单独用camera或者LiDARs更高的精度,以及更小的计算量,更快的速度。
3.相关工作
基于LiDAR的3D感知、基于camera的3D感知、多传感器的融合,以及多任务的学习。
4.本文方法
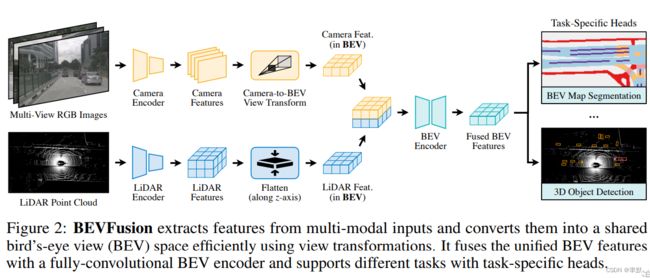
BEVFusion提供了不同的传感器的输入接口,可以通过编码器提取传感器输入的特征,并将它们转到BEV的空间上,再通过BEV Encoder统一BEV特征。
4.1 统一的表征
找到一个共享的表示法是至关重要的,这样(1)所有的传感器特征都可以很容易地转换为它,而没有信息损失;(2)它适合于不同类型的任务。本文采用的是BEV作为融合时的统一表示。
4.2 camera-to-BEV的高效转换
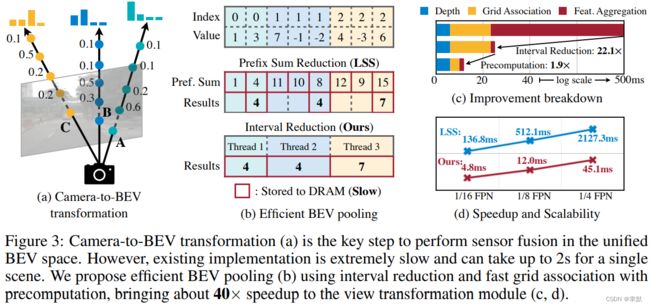
预测每个像素的离散深度分布,然后,将每个特征像素沿相机射线分散到D个离散点,并通过其相应的深度概率对相关特征进行重新划分。生成的三维camera特征点云size NHWD。N是camera的个数。
BEV pooling将所有的特征拉平。通过precomputation and interval reduction提升BEV pooling的计算效率。
precomputation:我们预先计算每个点的三维坐标和BEV网格索引。我们还根据网格索引对所有的点进行排序,并记录每个点的等级。在推理过程中,我们只需要根据预先计算的等级对所有特征点进行重新排序。这种缓存机制可以将网格关联的延迟从17ms减少到4ms。
Interval Reduction:为了加速特征聚合,我们实现了一个专门的GPU内核,直接在BEV网格上进行并行处理:我们为每个网格分配了一个GPU线程,计算其区间和并将结果写回去。这个内核消除了输出之间的依赖性(因此不需要多级树的减少),避免了将部分和写入DRAM,将特征聚合的延迟从500ms减少到2ms。
4.3 全卷积融合
a convolution-based BEV encoder (with a few residual blocks) to compensate for such local misalignments.
通过基于卷积的BEV编码器,来补偿camera与LiDAR BEV空间不匹配。
4.4 多任务HEAD
为了适应不同的感知任务,BEV feature map可以接多种任务的HEAD。
检测:a class-specific center heatmap head
分割:as multiple binary semantic segmentation, one for each class.focal loss进行优化。
5.实验
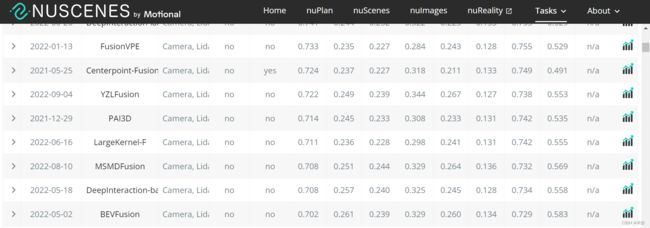
BEV 3D检测任务:

https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any


6.分析
消融实验,具体看论文吧。

7.结论
(1)BEVFusion统一camera与LiDAR到BEV空间;
(2)并且能够适用于一些其他的3D感知任务的接入;
(3)进行了40x的加速优化,能够更容易的部署到实际生产环境。