数据仓库中基本概念
一、数据仓库
数据仓库(Data Warehouse)是一个面向主题的、集成的、稳定的且随时间变化的数据集合,用于 支持管理人员的决策
- 面向主题 主题就是类型的意思。 传统数据库主要是为应用程序进行数据处理,未必会按照同一主题存储数据; 数据仓库侧重于数据分析工作,是按照主题存储的。
- 集成 传统数据库通常与某些特定的应用相关,数据库之间相互独立。而数据仓库中的数据是在对原有分散 的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致 性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。
- 稳定 稳定说的是相对稳定 传统数据库中的数据通常实时更新,数据根据需要及时发生变化。数据仓库的数据主要供企业决策分 析使用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期 保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、 刷新。
- 变化 这里的变化说的是反映历史变化 传统数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含历史信息,它里面记 录了企业从过去某一时间点(如开始应用数据仓库的时间)到目前的各个阶段的信息,通过这些信息, 可以对企业的发展历程和未来趋势做出分析和预测。
二、数据库和数据仓库区别
数据库:传统的关系型数据库主要应用在基本的事务处理,例如银行交易之类的场景 数据库支持增删改查这些常见的操作。
数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对数据库而言,数据仓库分析的数据规模要大得多。但是数据仓库只支持查询操作,不支持修改和删除
三、OLTP和OLAP的区别
OLTP(Online transaction processing)::操作型处理,称为联机事务处理,也可以称为面向交易的 处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为 关心操作的响应时间、数据的安全性、完整性等问题
OLAP(Online analytical processing):分析型处理,称为联机分析处理,一般针对某些主题历史数 据进行分析,支持管理决策,OLAP侧重于分析
四、事实表、维度表
事实表是指保存了大量业务数据的表,或者说保存了一些真实的行为数据的表,例如:销售商品所产生的订单数据
维度其实指的就是一个对象的属性或者特征,例如:时间维度,地理区域维度,年龄维度
五、数据库三范式
第一范式(1NF):数据库表的每一列都是不可分割的原子数据项
如下的地址字段显然是不符合第一范式的,因为这里面的地址信息是可以拆分为省份+城市+街道 信息的

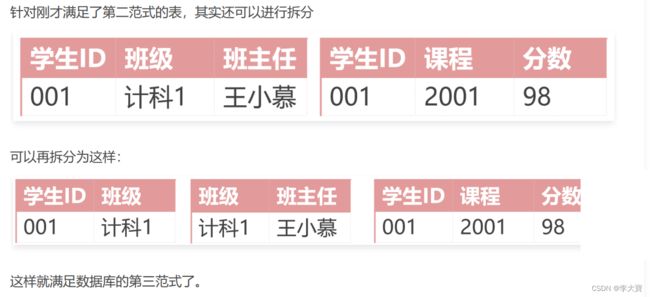
第二范式(2NF): 数据库表中每一列都和主键相关,不能只和主键的某一部分相关(针对联合主键而言) 也就是说一个表中只能保存一种类型的数据,不可以把多种类型数据保存在同一张表中
比如:这个表里面除了存储的有学生的班级信息,还有学生的考试成绩信息 根据我们刚才的分析,它是满足第一范式的,但是违背了第二范式,数据库表中的每一列并不是都和主键 相关 所以我们为了让这个表满足第二范式,可以这样拆分: 拆成两个表,一个表里面保存学生的班级信息,一个表里面保存学生的考试成绩信息

第三范式(3NF): 要求一个数据库表中不包含已在其它表中包含的非主键字段,就是说,表中的某些字段信息,如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键 join就用外键join)。
六、星型模型和雪花模型
星型模型和雪花模型主要区别就是对维度表的拆分, 对于雪花模型,维度表的设计更加规范,一般符合3NF; 而星型模型,一般采用降维的操作,利用冗余来避免模型过于复杂,提高易用性和分析效
星型模型如下图
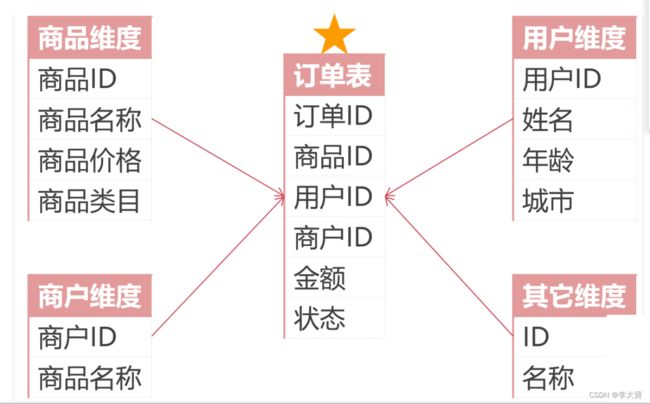
这里面的中间的订单表是事实表,外面的四个是维度表。
雪花模型如下:
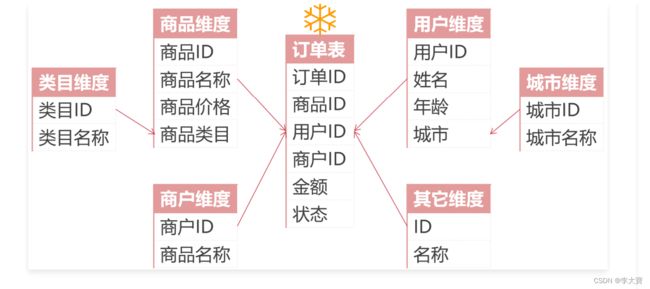
- 冗余:雪花模型符合业务逻辑设计,采用3NF设计,有效降低数据冗余;星型模型的维度表设计不符合 3NF,反规范化,维度表之间不会直接相关,牺牲部分存储空间
- 性能:雪花模型由于存在维度间的关联,采用3NF降低冗余,通常在使用过程中,需要连接更多的维度 表,导致性能偏低;星型模型违反三范式,采用降维的操作将维度整合,以存储空间为代价有效降低维度 表连接数,性能比雪花模型高
在实际工作中我们多采用星型模型,因为数据仓库主要是侧重于做数据分析,对数据的查询性能要求比较 高,所以星型模型是比较好的选择,在实际工工作中我们会尽可能的多构建一些宽表,提前把多种有关联 的维度整合到一张表中,后期使用时就不需要多表关联了,比较方便,并且性能也高。
七、数据仓库分层
数据仓库在构建过程中通常都需要进行分层处理。业务不同,分层的技术处理手段也不同。对数据进行分 层的一个主要原因就是希望在管理数据的时候,能对数据有一个更加清晰的掌控 详细来讲,主要有下面几个原因:
- 1. 清晰的数据结构:每一个分层的数据都有它的作用域,这样我们在使用表的时候能更方便地定位和理 解。
- 2. 数据血缘追踪:简单来讲可以这样理解,我们最终给业务方呈现的是一个能直接使用的业务表,但是 它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危 害范围,分层之后就很好定位问题,以及可以清晰的知道它的危害范围。
- 3. 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少重复计算。
- 4. 把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单 和容易理解。而且便于维护数据的准确性, 当数据出现问题之后,可以不用修复所有的数据,只需 要从有问题的步骤开始修复。
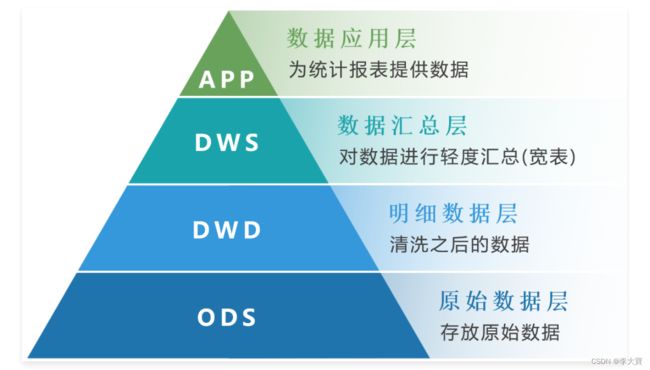
数据仓库一般会分为4层
- ODS层:原始数据层,数据源中的数据,采集过来之后,原样保存。
- DWD层:明细数据层:这一层是对ODS层的数据进行清洗,解决一些数据质量问题和数据的完整度 问题。
- DWS层:这一层是对DWD层的数据进行轻度聚合汇总,生成一系列的中间表,提升公共指标的复用 性,减少重复加工,并且构建出来一些宽表,用于提供后续的业务查询。
- APP层:根据业务需要,由前面三层的数据统计而出的结果,可以直接提供查询展现,一般会把APP 层的数据导出到MySQL中供线上系统使用,提供报表展示、数据监控及其它功能。也有公司把这层 称为DM层。虽然名字不一样,但是性质是一样的。
 八、针对DWD层在对数据进行清洗的时候,一般需要遵循以下原则
八、针对DWD层在对数据进行清洗的时候,一般需要遵循以下原则
1. 数据唯一性校验(通过数据采集工具采集的数据会存在重复的可能性)
2. 数据完整性校验(采集的数据中可能会出现缺失字段的情况,针对缺失字段的数据建议直接丢掉,如 果可以确定是哪一列缺失也可以进行补全,可以用同一列上的前一个数据来填补或者同一列上的后一 个数据来填补)
3. 数据合法性校验-1(针对数字列中出现了null、或者-之类的异常值,全部替换为一个特殊值,例如0或 者-1,这个需要根据具体的业务场景而定)
4. 数据合法性校验-2(针对部分字段需要校验数据的合法性,例如:用户的年龄,不能是负数)
九、拉链表
拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓 拉链,就是记录历史。记录 一个事物从开始,一直到当前状态的所有历史变化的信息。