分布式定时任务框架说明
分布式定时任务框架说明
- 分布式定时任务框架说明
-
- Quartz
-
- 概念
- 架构
- 组件
- springboot集成方式
-
- 使用内存
- 使用数据库
- TBSchedule:
- elastic-job
-
- 概念
- 架构
- 组件
- 执行流程
- 特性
- satum
- xxl-job
-
- 概念
- 特性
- 架构
- 组件
- 使用
分布式定时任务框架说明
Quartz
概念
-
Quartz:Java事实上的定时任务标准。但Quartz关注点在于定时任务而非数据,并无一套根据数据处理而定制化的流程。虽然Quartz可以基于数据库实现作业的高可用,但缺少分布式并行调度的功能
优缺点:
-
调用API的的方式操作任务,不人性化;
-
需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
-
调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况加,此时调度系统的性能将大大受限于业务;
-
Quartz关注点在于定时任务而非数据,并无一套根据数据处理而定制化的流程。虽然Quartz可以基于数据库实现作业的高可用,但缺少分布式并行调度的功能。
-
架构
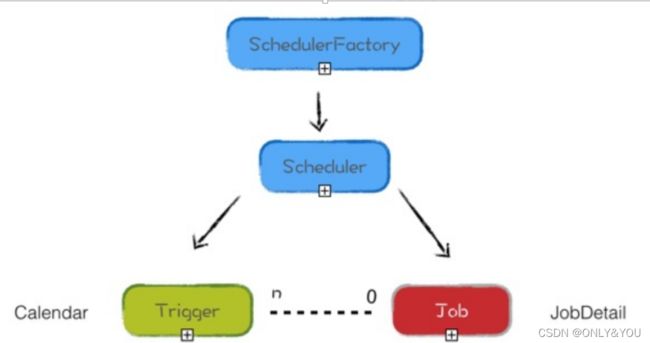
组件
-
Job和JobDetail
- Job是Quartz中的一个接口,接口下只有execute方法,在这个方法中编写业务逻辑。
- JobDetail用来绑定Job,为Job实例提供许多属性:name、group、jobClass、jobDataMap
- JobDetail绑定指定的Job,每次Scheduler调度执行一个Job的时候,首先会拿到对应的Job,然后创建该Job实例,再去执行Job中的execute()的内容,任务执行结束后,关联的Job对象实例会被释放,且会被JVM GC清除。
- JobDetail定义的是任务数据,而真正的执行逻辑是在Job中。这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,Sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
-
Trigger
Trigger是Quartz的触发器,会去通知Scheduler何时去执行对应Job。- SimpleTrigger
SimpleTrigger可以实现在一个指定时间段内执行一次作业任务或一个时间段内多次执行作业任务。例如,指定时间触发,每隔10秒执行一次,重复10次:
trigger = newTrigger() .withIdentity("trigger3", "group1") .startAt(myTimeToStartFiring) // if a start time is not given (if this line were omitted), "now" is implied .withSchedule(simpleSchedule() .withIntervalInSeconds(10) .withRepeatCount(10)) // note that 10 repeats will give a total of 11 firings .forJob(myJob) // identify job with handle to its JobDetail itself .build();- CronTrigger
CronTrigger功能非常强大,是基于日历的作业调度,而SimpleTrigger是精准指定间隔,所以相比SimpleTrigger,CroTrigger更加常用
- SimpleTrigger
-
Scheduler
与调度程序交互的主要API。
Scheduler的生命期,从SchedulerFactory创建它时开始,到Scheduler调用shutdown()方法时结束;Scheduler被创建后,可以增加、删除和列举Job和Trigger,以及执行其它与调度相关的操作(如暂停Trigger)。但是,Scheduler只有在调用start()方法后,才会真正地触发trigger(即执行job),使用Scheduler之前,需要实例化。
public class MyScheduler2 {
public static void main(String[] args) throws SchedulerException, InterruptedException {
// 1、创建调度器Scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
// 2、创建JobDetail实例,并与PrintWordsJob类绑定(Job执行内容)
JobDetail jobDetail = JobBuilder.newJob(PrintWordsJob.class)
.usingJobData("jobDetail1", "这个Job用来测试的")
.withIdentity("job1", "group1").build();
// 3、构建Trigger实例,每隔1s执行一次
Date startDate = new Date();
startDate.setTime(startDate.getTime() + 5000);
Date endDate = new Date();
endDate.setTime(startDate.getTime() + 5000);
CronTrigger cronTrigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "triggerGroup1")
.usingJobData("trigger1", "这是jobDetail1的trigger")
.startNow()//立即生效
.startAt(startDate)
.endAt(endDate)
.withSchedule(CronScheduleBuilder.cronSchedule("* 30 10 ? * 2-6 2018"))
.build();
//4、执行
scheduler.scheduleJob(jobDetail, cronTrigger);
System.out.println("--------scheduler start ! ------------");
scheduler.start();
System.out.println("--------scheduler shutdown ! ------------");
}
}
springboot集成方式
pom中引入依赖来使用
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-quartzartifactId>
dependency>
Quartz持久化配置提供了两种存储器:
| 类型 | 优点 | 缺点 |
|---|---|---|
| RAMJobStore | 不要外部数据库,配置容易,运行速度快 | 因为调度程序信息是存储在被分配给 JVM 的内存里面,所以,当应用程序停止运行时,所有调度信息将被丢失。另外因为存储到JVM内存里面,所以可以存储多少个 Job 和 Trigger 将会受到限制 |
| JDBC 作业存储 | 支持集群,因为所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务 | 运行速度的快慢取决与连接数据库的快慢 |
使用内存
spring:
datasource:
quartz:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/quartz?serverTimezone=GMT%2B8
username: root
password: 123456
# Quartz 的配置,对应 QuartzProperties 配置类
quartz:
job-store-type: jdbc # 使用数据库存储
scheduler-name: hyhScheduler # 相同 Scheduler 名字的节点,形成一个 Quartz 集群
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
jdbc:
initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。
properties: # 添加 Quartz Scheduler 附加属性
org:
quartz:
# JobStore 相关配置
jobStore:
dataSource: quartzDataSource # 使用的数据源
class: org.quartz.impl.jdbcjobstore.JobStoreTX # JobStore 实现类
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_ # Quartz 表前缀
isClustered: true # 是集群模式
clusterCheckinInterval: 1000
useProperties: false
threadPool:
threadCount: 25 # 线程池大小。默认为 10 。
threadPriority: 5 # 线程优先级
class: org.quartz.simpl.SimpleThreadPool # 线程池类型
使用数据库
quartz中有sql脚本创建数据库,支持多种数据库,以mysql为例
spring:
datasource:
quartz:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/quartz?serverTimezone=GMT%2B8
username: root
password: 123456
# Quartz 的配置,对应 QuartzProperties 配置类
quartz:
job-store-type: jdbc # 使用数据库存储
scheduler-name: hyhScheduler # 相同 Scheduler 名字的节点,形成一个 Quartz 集群
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
jdbc:
initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。
properties: # 添加 Quartz Scheduler 附加属性
org:
quartz:
# JobStore 相关配置
jobStore:
dataSource: quartzDataSource # 使用的数据源
class: org.quartz.impl.jdbcjobstore.JobStoreTX # JobStore 实现类
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_ # Quartz 表前缀
isClustered: true # 是集群模式
clusterCheckinInterval: 1000
useProperties: false
threadPool:
threadCount: 25 # 线程池大小。默认为 10 。
threadPriority: 5 # 线程优先级
class: org.quartz.simpl.SimpleThreadPool # 线程池类型
TBSchedule:
- 阿里早期开源的分布式任务调度系统。代码略陈旧,使用timer而非线程池执行任务调度。众所周知,timer在处理异常状况时是有缺陷的。而且TBSchedule作业类型较为单一,只能是获取/处理数据一种模式。还有就是文档缺失比较严重
elastic-job
概念
- 当当开发的弹性分布式任务调度系统,功能丰富强大,采用zookeeper实现分布式协调,实现任务高可用以及分片,目前是版本2.15,并且可以支持云开发
- E-Job 关注的是数据,增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源。但是学习成本相对高些,推荐在“数据量庞大,且部署服务器数量较多”时使用
架构
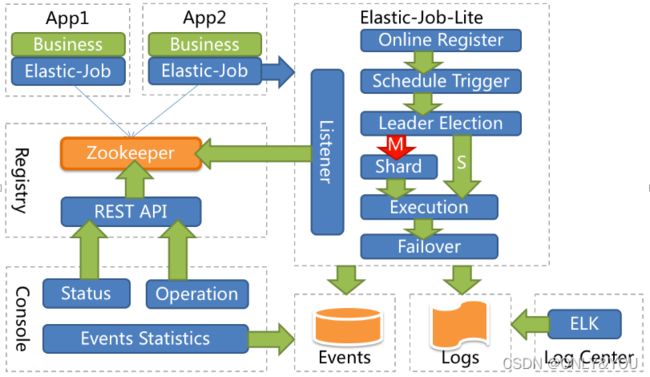
组件
- App:内部包含任务执行业务逻辑和Elastic-Job-Lite组件
- Registry**:**以Zookeeper作为Elastic-Job的注册中心组件,存储了执行任务的相关信息
- Console**:**Elastic-Job运维平台
执行流程
- app启动时,在其内嵌的Elastic-Job-Lite组件向Zookeeper注册该实例的信息。
- 触发选举从众多实例中选举出一个Leader,让其执行任务
- 当到达定时任务执行时间时,
Elastic-Job-Lite组件调用由应用程序实现的任务业务逻辑
特性
- 集群部署 : 重写Quartz基于数据库的分布式功能,改用Zookeeper实现注册中心
作业注册中心:基于Zookeeper和其客户端Curator实现的全局作业注册控制中心。用于注册,控制和协调分布式作业执行。
- 多节点部署时,将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job将在保留本次任务执行不变的情况下,下次任务开始前触发任务重分片。
- 日志可追溯:可通过事件订阅的方式处理调度过程的重要事件,用于查询、统计和监控。Elastic-Job目前提供了基于关系型数据库两种事件订阅方式记录事件。
- 监控告警:通过事件订阅方式可自行实现
作业运行状态监控、监听作业服务器存活、监听近期数据处理成功、数据流类型作业(可通过监听近期数据处理成功数判断作业流量是否正常,如果小于作业正常处理的阀值,可选择报警。)、监听近期数据处理失败(可通过监听近期数据处理失败数判断作业处理结果,如果大于0,可选择报警。)
- 弹性扩容缩容:通过zk实现各服务的注册、控制及协调;
- 并行调度:采用任务分片方式实现。将一个任务拆分为n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。
- 高可用:调度器的高可用是通过运行几个指向同一个ZooKeeper集群的Elastic-Job-Cloud-Scheduler实例来实现的。ZooKeeper用于在当前主Elastic-Job-Cloud-Scheduler实例失败的情况下执行领导者选举。通过至少两个调度器实例来构成集群,集群中只有一个调度器实例提供服务,其他实例处于”待命”状态。当该实例失败时,集群会选举剩余实例中的一个来继续提供服务。
- 失败处理:弹性扩容缩容在下次作业运行前重分片,但本次作业执行的过程中,下线的服务器所分配的作业将不会重新被分配。失效转移功能可以在本次作业运行中用空闲服务器抓取孤儿作业分片执行。同样失效转移功能也会牺牲部分性能。
- 动态分片:支持多种分片策略,可自定义分片策略
默认包含三种分片策略:基于平均分配算法的分片策略、 作业名的哈希值奇偶数决定IP升降序算法的分片策略、根据作业名的哈希值对Job实例列表进行轮转的分片策略,支持自定义分片策略
elastic-job的分片是通过zookeeper来实现的。分片的分片由主节点分配,如下三种情况都会触发主节点上的分片算法执行:
a、新的Job实例加入集群
b、现有的Job实例下线(如果下线的是leader节点,那么先选举然后触发分片算法的执行)
c、主节点选举”
satum
- Saturn:是唯品会自主研发的分布式的定时任务的调度平台,基于当当的elastic-job 版本1开发,并且可以很好的部署到docker容器上。
xxl-job
概念
- xxl-job: 是大众点评员工徐雪里于2015年发布的分布式任务调度平台,是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
- X-Job 侧重的业务实现的简单和管理的方便,学习成本简单,失败策略和路由策略丰富。推荐使用在“用户基数相对少,服务器数量在一定范围内”的情景下使用
特性
- 集群部署 : 集群部署唯一要求为:保证每个集群节点配置(db和登陆账号等)保持一致。调度中心通过db配置区分不同集群。
执行器支持集群部署,提升调度系统可用性,同时提升任务处理能力。集群部署唯一要求为:保证集群中每个执行器的配置项 “xxl.job.admin.addresses/调度中心地址” 保持一致,执行器根据该配置进行执行器自动注册等操作。
- 多节点部署时,使用Quartz基于数据库的分布式功能实现任务不能重复执行
- 日志可追溯:有日志查询界面
- 监控告警:调度失败时,将会触发失败报警,如发送报警邮件。
任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔
- 弹性扩容缩容:使用Quartz基于数据库的分布式功能,服务器超出一定数量会给数据库造成一定的压力;
- 并行调度:调度系统多线程(默认10个线程)触发调度运行,确保调度精确执行,不被堵塞。
- 高可用:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
- 失败处理:调度失败时的处理策略,策略包括:失败告警(默认)、失败重试;
- 动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时传递分片参数;可根据分片参数开发分片任务;
架构
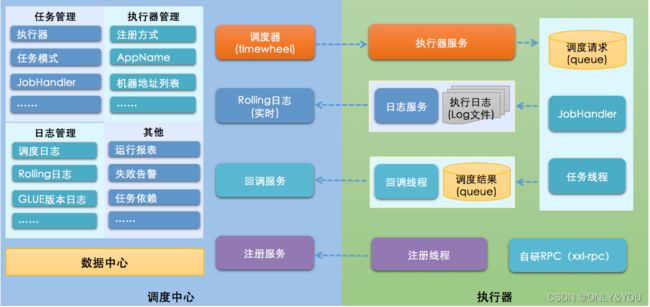
组件
xxl-job-admin:调度中心
管理调度信息,按照调度配置发出调度请求,自身不承担业务代码
可视化,动态进行任务创建,更新,删除,GLUE开发和任务报警
xxl-job-core:公共依赖
xxl-job-executor-samples:
接收调度请求并执行任务逻辑
与调度中心解耦
执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;
使用
- 先编译xxl-job-core,再编译xxl-job-admin
- 部署xxl-job-admin
- 部署执行器xxl-job-executor-sample-springboot,一个执行器可以创建多个任务
- bean模式自定义方法定时任务
@XxlJob("myJobHandler")
public void myJobHandler() throws InterruptedException {
XxlJobHelper.log("hello znbase");
DateFormat dateFormat = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
Date date = new Date();
System.out.println(dateFormat.format(date));
for(int i =0;i<5;i++){
XxlJobHelper.log("times:"+i);
System.out.println("hello znbase" +i);
TimeUnit.SECONDS.sleep(1);
}
}
在admin界面注册任务
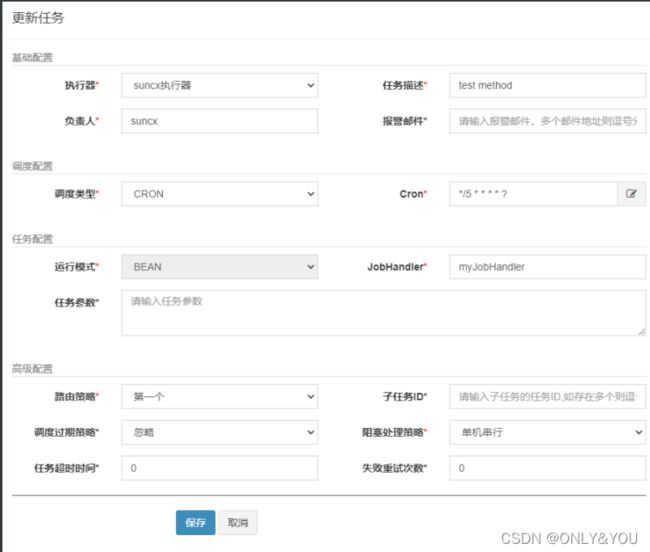
任务调度中心
参照资料:
聊一聊分布式定时任务框架选型