自组网训练生成模型并推理模型完整流程,代码展示LeNet -> AlexNet -> VGGNet -> InceptionNet -> ResNet优化过程
项目简介
本项目基于20种蝴蝶分类基础上做一个深入浅出的代码理解,及其对数据预处理,自定义数据读取器Reader(Dataset),及其输出final.pdparams,final.pdopt模型,利用20分类的蝴蝶数据集,自组网,输入网络结构,训练出模型并保存。观察从LeNet -> AlexNet -> VGGNet -> InceptionNet -> ResNet优化过程,以及用自己的组的网输出的模型进行推理与部署到手机端,实现飞桨框架深度学习模型的落地。
- 模型训练:LeNet -> AlexNet -> VGGNet -> InceptionNet -> ResNet (MyNet)
- 模型转换:Paddle-Lite (可以参考这个项目的部署部分)
- Android开发环境:Android Studio on Ubuntu 18.04 64-bit
- 移动端设备:安卓9.0以上的手机设备
关于本项目
本项目适合入门级同学用来加深卷积网络模型的印象,加深对模型的理解,可以自己动手组网,生成属于自己的网络模型,褪去慢慢对套件的使用。对项目还存在的改进空间,,希望大家多交流观点、介绍经验,共同学习进步,可以互相关注♥。个人主页
推荐视频
飞桨领航团图像分类零基础训练
实验结果对比
每个网络模型,使用的参数如下:
loss函数: CrossEntropyLoss 交叉熵损失函数
优化器: AdamW
学习率: 3e-4
batch : 16
轮数 : 10轮

1、解压数据集
#部分代码展示
!cd data &&\
unzip -oq data98281/Butterfly20_test.zip &&\
unzip -oq data98281/Butterfly20.zip &&\
rm -r __MACOSX
数据集展示及其变换后数据展示

2、提取数据集关键信息
保存每个样本的读取路径、标签
import os
import random
data_list = [] #用个列表保存每个样本的读取路径、标签
#由于属种名称本身是字符串,而输入模型的是数字。需要构造一个字典,把某个数字代表该属种名称。键是属种名称,值是整数。
label_list=[]
with open("/home/aistudio/data/species.txt") as f:
for line in f:
a,b = line.strip("\n").split(" ")
label_list.append([b, int(a)-1])
label_dic = dict(label_list)
# print(label_dic)
# 获取Butterfly20目录下的所有子目录名称,保存进一个列表之中
class_list = os.listdir("/home/aistudio/data/Butterfly20")
class_list.remove('.DS_Store') #删掉列表中名为.DS_Store的元素,因为.DS_Store并没有样本。
for each in class_list:
for f in os.listdir("/home/aistudio/data/Butterfly20/"+each):
data_list.append(["/home/aistudio/data/Butterfly20/"+each+'/'+f,label_dic[each]])
#按文件顺序读取,可能造成很多属种图片存在序列相关,用random.shuffle方法把样本顺序彻底打乱。
random.shuffle(data_list)
#打印前十个,可以看出data_list列表中的每个元素是[样本读取路径, 样本标签]。
print(data_list[0:10])
#打印样本数量,一共有1866个样本。
print("样本数量是:{}".format(len(data_list)))
3、定义数据预处理函数及其自定义数据读取器
- 数据预处理函数 preprocess(img)
- 自定义数据读取器Reader(Dataset)
#以下代码用于构造读取器与数据预处理
#首先需要导入相关的模块
import paddle
from paddle.vision.transforms import Compose, ColorJitter, Resize,Transpose, Normalize
import numpy as np
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.io import Dataset
import paddle.fluid as fluid
#自定义的数据预处理函数,输入原始图像,输出处理后的图像,可以借用paddle.vision.transforms的数据处理功能
"""
tips:图像处理不是加的越多越好,要观察数据集加适合的才能更好的提升acc精度,可以自己尝试去掉
"""
def preprocess(img):
transform = Compose([
Resize(size=(224, 224)), # 把数据长宽像素调成224*224
T.RandomHorizontalFlip(224), # 随机水平
T.RandomVerticalFlip(224), # 随机垂直翻转
T.RandomRotation(224), #图像随机旋转
T.RandomResizedCrop(224), #图像随机裁剪
T.BrightnessTransform(0.15), #调整图像的亮度
T.ColorJitter(0.4,0.4,0.4,0.4), #随机调整图像的亮度,对比度,饱和度和色调。
T.RandomVerticalFlip(224), #基于概率来执行图片的垂直翻转
Transpose(), #原始数据形状维度是HWC格式,经过Transpose,转换为CHW格式
Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], to_rgb=True), #标准化
])
img = transform(img).astype("float32")
return img
#自定义数据读取器
class Reader(Dataset):
def __init__(self, data, is_val=False):
super().__init__()
#在初始化阶段,把数据集划分训练集和测试集。由于在读取前样本已经被打乱顺序,取20%的样本作为测试集,80%的样本作为训练集。
self.samples = data[-int(len(data)*0.2):] if is_val else data[:-int(len(data)*0.2)]
def __getitem__(self, idx):
#处理图像
img_path = self.samples[idx][0] #得到某样本的路径
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
#处理标签
label = self.samples[idx][1] #得到某样本的标签
label = np.array([label], dtype="int64") #把标签数据类型转成int64
return img, label
def __len__(self):
#返回每个Epoch中图片数量
return len(self.samples)
#生成训练数据集实例
train_dataset = Reader(data_list, is_val=False)
#生成测试数据集实例
eval_dataset = Reader(data_list, is_val=True)
#打印一个训练样本
print(train_dataset[1136][0].shape)
# print(train_dataset[1136][1])
#定义输入
input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img")
label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64", name="label")
#定义训练模型所需要的相同函数
def train_process(name, model):
model = paddle.Model(model,inputs=input_define,labels=label_define) #用Paddle.Model()对模型进行封装
optimizer = paddle.optimizer.AdamW(learning_rate=3e-4, parameters=model.parameters(),weight_decay=2e-4)
model.prepare(optimizer=optimizer, #指定优化器
loss=paddle.nn.CrossEntropyLoss(), #指定损失函数
metrics=paddle.metric.Accuracy()) #指定评估方法
callback=paddle.callbacks.VisualDL(log_dir='{}/visualdl_log_dir'.format(name)) #本地
return model,callback
4、卷积网络优化历程
LeNet -> AlexNet -> VGGNet -> InceptionNet -> ResNet
1998 2012 2014 2014 2015
- LeNet: Yann LeCun于1998年提出,卷积网络开篇之作,共享卷积核,减少网络参数。 5层
- AlexNet: 使用relu激活函数;提升训练速度;使用Dropout,缓解过拟合。 8层
- VGGNet: 小尺寸卷积核减少参数;网络结构规整;适合并行加速。 16/19层
- Inception Net: 一层内使用不同尺寸;卷积核提升感知力;使用批标准化;缓解梯度消失。 22层
- ResNet: 层间残差信息跳连,引入前方信息;缓解模型退化,使得神经网络加深成为可能。
4.1 LeNet
LeNet是最早的卷积神经网络之一。1998年,Yann LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如 图1 所示,这里展示的是用于MNIST手写体数字识别任务中的LeNet-5模型:

图1:LeNet模型网络结构示意图
-
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用Sigmoid),图像尺寸从28减小到24。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到12。
-
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到8,经过池化后变成4。
-
第三模块:包含4×4的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别的类别数是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
层数流程图:

"""
num_channels (int) - 输入图像的通道数。
num_filters (int) - 滤波器的个数,和输出特征图个数相同。
filter_size (int|tuple) - 滤波器大小。如果 filter_size 是一个元组,则必须包含两个整型数,分别表示滤波器高度和宽度。否则,表示滤波器高度和宽度均为 filter_size 。
stride (int|tuple, 可选) - 步长大小。如果 stride 为元组,则必须包含两个整型数,分别表示垂直和水平滑动步长。否则,表示垂直和水平滑动步长均为 stride 。默认值:1。
padding (int|tuple, 可选) - 填充大小。如果 padding 为元组,则必须包含两个整型数,分别表示竖直和水平边界填充大小。否则,表示竖直和水平边界填充大小均为 padding 。默认值:0。
"""
class LeNet(nn.Layer):
def __init__(self, num_classes=20):
super(LeNet,self).__init__()
self.num_classes = num_classes
self.features=nn.Sequential(
nn.Conv2D(
3, 64, 3, stride=1, padding=1), # 可以设置为 padding = "valid"
nn.Sigmoid(),
nn.MaxPool2D(2, 2),
nn.Conv2D(
64, 128, 5, stride=1, padding=0),
nn.Sigmoid(),
nn.MaxPool2D(2, 2)
)
if num_classes > 0:
self.fc = nn.Sequential(
nn.Linear(373248,512), #输入为计算所得,对应着上面链接的卷积层输出维度
nn.Linear(512,224),
nn.Linear(224,num_classes)
)
#前向传播
def forward(self,inputs):
x = self.features(inputs)
if self.num_classes > 0:
x = paddle.flatten(x,1)
x = self.fc(x)
return x
#生成网络模型实例
model = LeNet()
params_info = paddle.summary(model, (1, 3, 224, 224))
print(params_info) #打印网络结构
model,callback=train_process(name='LeNet', model=model)
#开始训练
model.fit(train_data=train_dataset, #训练数据集
eval_data=eval_dataset, #测试数据集
batch_size=16, #一个批次的样本数量
epochs=10, #迭代轮次
callbacks=callback,
save_dir="/home/aistudio/LeNet", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=2, #设定每隔多少个epoch保存模型参数及优化器参数
log_freq=20 #打印日志的频率
)
4.2 AlexNet
不过呢LeNet更大的数据集上表现却并不好。自从1998年LeNet问世以来,接下来十几年的时间里,神经网络并没有在计算机视觉领域取得很好的结果,反而一度被其它算法所超越。原因主要有两方面,一是神经网络的计算比较复杂,对当时计算机的算力来说,训练神经网络是件非常耗时的事情;另一方面,当时还没有专门针对神经网络做算法和训练技巧的优化,神经网络的收敛是件非常困难的事情。随着技术的进步和发展,计算机的算力越来越强大,尤其是在GPU并行计算能力的推动下,复杂神经网络的计算也变得更加容易实施。另一方面,互联网上涌现出越来越多的数据,极大的丰富了数据库。同时也有越来越多的研究人员开始专门针对神经网络做算法和模型的优化,Alex Krizhevsky等人提出的AlexNet以很大优势获得了2012年ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
-
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
-
使用Dropout抑制过拟合。
-
使用ReLU激活函数减少梯度消失现象。
层数流程图:

# AlexNet模型代码
class AlexNet(paddle.nn.Layer):
def __init__(self,num_classes=20):
super(AlexNet,self).__init__()
self.num_classes = num_classes
# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征
# 与LeNet不同的是激活函数换成了‘relu’
self.features=nn.Sequential(
nn.Conv2D(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=5),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2,stride=2),
nn.Conv2D(in_channels=96,out_channels=256,kernel_size=5,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2,stride=2),
nn.Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.MaxPool2D(kernel_size=2,stride=2)
)
if num_classes > 0:
self.fc=nn.Sequential(
nn.Linear(in_features=12544,out_features=4096),
nn.Dropout (0.5),
nn.Linear(in_features=4096,out_features=4096),
nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=num_classes)
)
def forward(self,inputs):
x = self.features(inputs)
if self.num_classes > 0:
x = paddle.flatten(x,1)
x = self.fc(x)
return x
#生成网络模型实例
model = AlexNet()
params_info = paddle.summary(model, (1, 3, 224, 224))
print(params_info) #打印网络结构
model,callback=train_process(name='AlexNet', model=model)
model.fit(train_data=train_dataset, #训练数据集
eval_data=eval_dataset, #测试数据集
batch_size=16, #一个批次的样本数量
epochs=10, #迭代轮次
callbacks=callback,
save_dir="/home/aistudio/AlexNet", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=2, #设定每隔多少个epoch保存模型参数及优化器参数
log_freq=20 #打印日志的频率
)
4.3 VGG
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和池化层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层3×3卷积层,可以得到感受野为5的特征图,而比使用5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。
Tips:原文使用LRN(local response normalization)局部响应标准化,本课程使用BN(Batch Normalization)替代。
层数流程图:
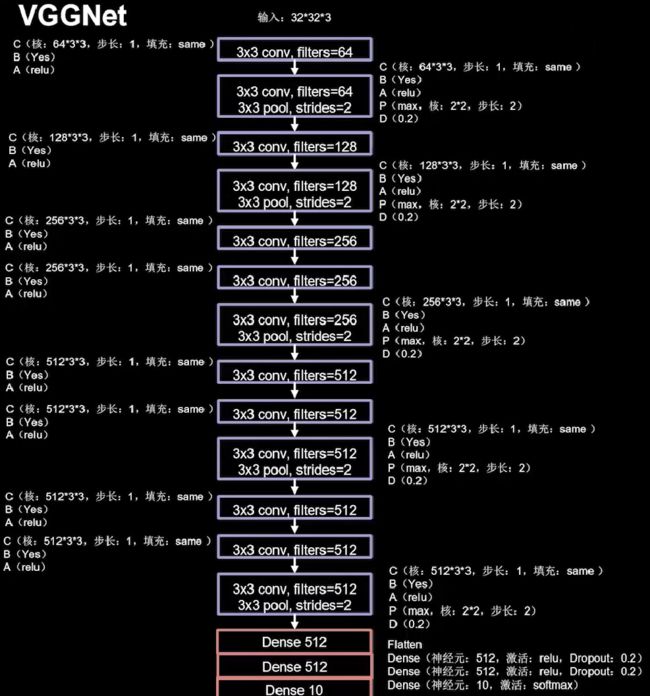
# VGG模型代码
class VGG(paddle.nn.Layer):
def __init__(self,num_classes=20):
super(VGG,self).__init__()
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2D(3,64,3,stride=1,padding="same"),
nn.BatchNorm(64,act="relu"),
nn.ReLU(),
nn.Conv2D(64,64,3,stride=1,padding="same"), # 执行C B A P D, C->卷积层 、B->归一化层 、A->激活(Activation)函数层 、P-> 池化层 、D-> 裁剪(丢弃)层
nn.BatchNorm(64,act="relu"),
nn.ReLU(),
nn.MaxPool2D(2,2),
nn.Dropout(0.5),
nn.Conv2D(64,128,3,stride=1,padding="same"),
nn.BatchNorm(128,act="relu"),
nn.ReLU(),
nn.Conv2D(128,128,3,stride=1,padding="same"),
nn.BatchNorm(128,act="relu"),
nn.ReLU(),
nn.MaxPool2D(2,2),
nn.Dropout(0.5),
nn.Conv2D(128,256,3,stride=1,padding="same"),
nn.BatchNorm(256,act="relu"),
nn.ReLU(),
nn.Conv2D(256,256,3,stride=1,padding="same"),
nn.BatchNorm(256,act="relu"),
nn.ReLU(),
nn.Conv2D(256,256,3,stride=1,padding="same"),
nn.BatchNorm(256,act="relu"),
nn.ReLU(),
nn.MaxPool2D(2,2),
nn.Dropout(0.5),
nn.Conv2D(256,512,3,stride=1,padding="same"),
nn.BatchNorm(512,act="relu"),
nn.ReLU(),
nn.Conv2D(512,512,3,stride=1,padding="same"),
nn.BatchNorm(512,act="relu"),
nn.ReLU(),
nn.Conv2D(512,512,3,stride=1,padding="same"),
nn.BatchNorm(512,act="relu"),
nn.ReLU(),
nn.MaxPool2D(2,2),
nn.Dropout(0.5),
nn.Conv2D(512,512,3,stride=1,padding="same"),
nn.BatchNorm(512,act="relu"),
nn.ReLU(),
nn.Conv2D(512,512,3,stride=1,padding="same"),
nn.BatchNorm(512,act="relu"),
nn.ReLU(),
nn.Conv2D(512,512,3,stride=1,padding="same"),
nn.BatchNorm(512,act="relu"),
nn.ReLU(),
nn.MaxPool2D(2,2),
nn.Dropout(0.5)
)
if num_classes > 0:
self.fc=nn.Sequential(
nn.Linear(in_features=25088,out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(in_features=4096,out_features=num_classes),
# nn.Softmax()
)
def forward(self,inputs):
x = self.features(inputs)
if self.num_classes > 0:
x = paddle.flatten(x,1)
x = self.fc(x)
return x
#生成网络模型实例
model = VGG()
params_info = paddle.summary(model, (1, 3, 224, 224))
print(params_info) #打印网络结构
model,callback=train_process(name='VGG', model=model)
model.fit(train_data=train_dataset, #训练数据集
eval_data=eval_dataset, #测试数据集
batch_size=16, #一个批次的样本数量
epochs=10, #迭代轮次
callbacks=callback,
save_dir="/home/aistudio/VGG", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=2, #设定每隔多少个epoch保存模型参数及优化器参数
log_freq=20 #打印日志的频率
)
4.4GooLeNet
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征;而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。
小Tips:
- Google的研究人员为了向LeNet致敬,特地将模型命名为GoogLeNet。
- Inception一词来源于电影《盗梦空间》(Inception)。
图4(a) 是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征,从而达到捕捉不同尺度信息的效果。Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。为了减小参数量,Inception模块使用了图(b)中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图(b)中所示的结构。下面这段程序是Inception块的具体实现方式,可以对照图(b)和代码一起阅读。

GoogLeNet的架构,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
- 第一模块使用一个64通道的7 × 7卷积层。
- 第二模块使用2个卷积层:首先是64通道的1 × 1卷积层,然后是将通道增大3倍的3 × 3卷积层。
- 第三模块串联2个完整的Inception块。
- 第四模块串联了5个Inception块。
- 第五模块串联了2 个Inception块。
- 第五模块的后面紧跟输出层,使用全局平均池化层来将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。

# 定义Inception块
class Inception(paddle.nn.Layer):
def __init__(self, c0, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__()
'''
Inception模块的实现代码,
c1,图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数
c2,图(b)中第二条支路卷积的输出通道数,数据类型是tuple或list,
其中c2[0]是1x1卷积的输出通道数,c2[1]是3x3
c3,图(b)中第三条支路卷积的输出通道数,数据类型是tuple或list,
其中c3[0]是1x1卷积的输出通道数,c3[1]是3x3
c4,图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数
'''
self.p1_1 = nn.Conv2D(c0,c1,kernel_size=1,stride=1) #图4(b) 中的最顶上的一条支线
self.p2_1 = nn.Conv2D(c0,c2[0],kernel_size=1,stride=1)
self.p2_2 = nn.Conv2D(c2[0],c2[1],kernel_size=3,padding=1,stride=1) #第二条支线
self.p3_1 = nn.Conv2D(c0,c3[0],kernel_size=1,stride=1)
self.p3_2 = nn.Conv2D(c3[0],c3[1],kernel_size=5,padding=2,stride=1) #第三条支线
self.p4_1 = nn.MaxPool2D(kernel_size=3,padding=1 ,stride=1)
self.p4_2 = nn.Conv2D(c0,c4,kernel_size=1,stride=1) #第四条支线
# # 新加一层batchnorm稳定收敛
# self.batchnorm = paddle.nn.BatchNorm2D(c1+c2[1]+c3[1]+c4)
def forward(self,x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2( F.relu(self.p2_1(x)) ))
p3 = F.relu(self.p3_2( F.relu(self.p3_1(x)) ))
p4 = F.relu(self.p4_2( self.p4_1(x) ))
return paddle.concat([p1,p2,p3,p4], axis=1)
# GoogLeNet模型代码
class GoogLeNet(paddle.nn.Layer):
def __init__(self,num_classes=20):
super(GoogLeNet,self).__init__()
self.num_classes = num_classes
self.features = nn.Sequential(
# GoogLeNet包含五个模块,每个模块后面紧跟一个池化层
# 第一个模块包含1个卷积层,池化,BatchNorm代替图中LRN
nn.Conv2D(in_channels=3,out_channels=64,kernel_size=7,padding=3,stride=2),
nn.MaxPool2D(kernel_size=3,stride=2,padding=1),
nn.BatchNorm(64,act="relu"),
# 第二个模块包含2个卷积层,池化,BatchNorm代替图中LRN
nn.Conv2D(in_channels=64,out_channels=64,kernel_size=1,stride=1),
nn.Conv2D(in_channels=64,out_channels=192,kernel_size=3,padding=1,stride=1),
nn.BatchNorm(192,act="relu"),
nn.MaxPool2D(kernel_size=3,stride=2,padding=1),
# 第三个模块包含2个Inception块
Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2D(kernel_size=3,stride=2,padding=1),
# 第四个模块包含5个Inception块
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2D(kernel_size=3,stride=2,padding=1),
# 第五个模块包含2个Inception块
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
# 全局池化,用的是global_pooling,不需要设置pool_stride
nn.AdaptiveAvgPool2D(output_size=1),
)
self.fc = nn.Sequential(
nn.Linear(in_features=1024, out_features=num_classes)
)
def forward(self,inputs):
x = self.features(inputs)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc(x)
return x
#生成网络模型实例
model = GoogLeNet()
params_info = paddle.summary(model, (1, 3, 224, 224))
print(params_info) #打印网络结构
model,callback=train_process(name='GoogLeNet', model=model)
model.fit(train_data=train_dataset, #训练数据集
eval_data=eval_dataset, #测试数据集
batch_size=16, #一个批次的样本数量
epochs=10, #迭代轮次
callbacks=callback,
save_dir="/home/aistudio/GoogLeNet", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=2, #设定每隔多少个epoch保存模型参数及优化器参数
log_freq=20 #打印日志的频率
)
4.5 ResNet
-
ResNet是2015年ImageNet比赛的冠军,将识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
-
通过前面几个经典模型学习,我们可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
-
Kaiming He等人提出了残差网络ResNet来解决上述问题。残差思想,这种设计方案也常称作瓶颈结构(BottleNeck)。11的卷积核可以非常方便的调整中间层的通道数,在进入33的卷积层之前减少通道数(256->64),经过该卷积层后再恢复通道数(64->256),可以显著减少网络的参数量。这个结构(256->64->256)像一个中间细,两头粗的瓶颈,所以被称为“BottleNeck”。

-
ResNet 50

#ResNet
class ConvBNLayer(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None):
"""
num_channels, 卷积层的输入通道数
num_filters, 卷积层的输出通道数
stride, 卷积层的步幅
groups, 分组卷积的组数,默认groups=1不使用分组卷积
"""
super(ConvBNLayer, self).__init__()
# 创建卷积层
self._conv = nn.Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
bias_attr=False)
# 创建BatchNorm层
self._batch_norm = paddle.nn.BatchNorm2D(num_filters)
self.act = act
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
if self.act == 'leaky':
y = F.leaky_relu(x=y, negative_slope=0.1)
elif self.act == 'relu':
y = F.relu(x=y)
return y
class BottleneckBlock(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True):
super(BottleneckBlock, self).__init__()
# 创建第一个卷积层 1x1
self.features = nn.Sequential(
# 创建第二个卷积层 3x3
ConvBNLayer(num_channels=num_channels,num_filters=num_filters,filter_size=1,act='relu'),
# 创建第二个卷积层 3x3
ConvBNLayer(num_channels=num_filters,num_filters=num_filters,filter_size=3,stride=stride,act='relu'),
# 创建第三个卷积 1x1,但输出通道数乘以4
ConvBNLayer(num_channels=num_filters,num_filters=num_filters * 4,filter_size=1,act=None)
)
# 如果conv2的输出跟此残差块的输入数据形状一致,则shortcut=True
# 否则shortcut = False,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self,inputs):
conv2 = self.features(inputs)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
class ResNet(paddle.nn.Layer):
def __init__(self,layers=50,class_dim=20):
super(ResNet,self).__init__()
"""
layers, 网络层数,可以是50, 101或者152
class_dim,分类标签的类别数
"""
super(ResNet, self).__init__()
self.layers = layers
supported_layers = [50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(supported_layers, layers)
if layers == 50:
#ResNet50包含多个模块,其中第2到第5个模块分别包含3、4、6、3个残差块
depth = [3, 4, 6, 3]
elif layers == 101:
#ResNet101包含多个模块,其中第2到第5个模块分别包含3、4、23、3个残差块
depth = [3, 4, 23, 3]
elif layers == 152:
#ResNet152包含多个模块,其中第2到第5个模块分别包含3、8、36、3个残差块
depth = [3, 8, 36, 3]
# 残差块中使用到的卷积的输出通道数
num_filters = [64, 128, 256, 512]
# ResNet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层
self.conv = ConvBNLayer(
num_channels=3,
num_filters=64,
filter_size=7,
stride=2,
act='relu')
self.pool2d_max = nn.MaxPool2D(
kernel_size=3,
stride=2,
padding=1)
# ResNet的第二到第五个模块c2、c3、c4、c5
self.bottleneck_block_list = []
num_channels = 64
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
num_channels=num_channels,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1, # c3、c4、c5将会在第一个残差块使用stride=2;其余所有残差块stride=1
shortcut=shortcut))
num_channels = bottleneck_block._num_channels_out
self.bottleneck_block_list.append(bottleneck_block)
shortcut = True
# 在c5的输出特征图上使用全局池化
self.pool2d_avg = paddle.nn.AdaptiveAvgPool2D(output_size=1)
# stdv用来作为全连接层随机初始化参数的方差
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
# 创建全连接层,输出大小为类别数目,经过残差网络的卷积和全局池化后,
# 卷积特征的维度是[B,2048,1,1],故最后一层全连接的输入维度是2048
self.out = nn.Linear(in_features=2048, out_features=class_dim,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(-stdv, stdv)))
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for bottleneck_block in self.bottleneck_block_list:
y = bottleneck_block(y)
y = self.pool2d_avg(y)
y = paddle.reshape(y, [y.shape[0], -1])
y = self.out(y)
return y
#生成网络模型实例
model = ResNet()
params_info = paddle.summary(model, (1, 3, 224, 224))
print(params_info) #打印网络结构
model,callback=train_process(name='ResNet', model=model)
model.fit(train_data=train_dataset, #训练数据集
eval_data=eval_dataset, #测试数据集
batch_size=16, #一个批次的样本数量
epochs=10, #迭代轮次
callbacks=callback,
save_dir="/home/aistudio/ResNet", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=2, #设定每隔多少个epoch保存模型参数及优化器参数
log_freq=20 #打印日志的频率
)
5、模型推理
class InferDataset(Dataset):
def __init__(self, img_path=None):
"""
数据读取Reader(推理)
:param img_path: 推理单张图片
"""
super().__init__()
if img_path:
self.img_paths = [img_path]
else:
raise Exception("请指定需要预测对应图片路径")
def __getitem__(self, index):
# 获取图像路径
img_path = self.img_paths[index]
# 使用Pillow来读取图像数据并转成Numpy格式
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
return img
def __len__(self):
return len(self.img_paths)
#实例化推理模型
model = paddle.Model(ResNet(),inputs=input_define)
#读取刚刚训练好的参数
model.load('/home/aistudio/ResNet/final')
#准备模型
model.prepare()
#得到待预测数据集中每个图像的读取路径
infer_list=[]
with open("/home/aistudio/data/testpath.txt") as file_pred:
for line in file_pred:
infer_list.append("/home/aistudio/data/"+line.strip())
#模型预测结果通常是个数,需要获得其对应的文字标签。这里需要建立一个字典。
def get_label_dict2():
label_list2=[]
with open("/home/aistudio/data/species.txt") as filess:
for line in filess:
a,b = line.strip("\n").split(" ")
label_list2.append([int(a)-1, b])
label_dic2 = dict(label_list2)
return label_dic2
label_dict2 = get_label_dict2()
#print(label_dict2)
#利用训练好的模型进行预测
results=[]
for infer_path in infer_list:
infer_data = InferDataset(infer_path)
result = model.predict(test_data=infer_data)[0] #关键代码,实现预测功能
result = paddle.to_tensor(result)
result = np.argmax(result.numpy()) #获得最大值所在的序号
results.append("{}".format(label_dict2[result])) #查找该序号所对应的标签名字
#把结果保存起来
with open("work/result.txt", "w") as f:
for r in results:
f.write("{}\n".format(r))