深度学习中评估指标:准确率Accuracy、召回率Recall、精确率Precision、特异度(真阴性率)和误报率、灵敏度(真阳性率)和漏报率、F1、PR、ROC、AUC、Dice系数、IOU
目录
准确率(Accuracy)
精确率(Precision,查准率)
召回率(Recall=TPR)
Precision-Recall曲线
F值(F-Measure,综合评价指标)
特异度TNR(真阴性率、specificity)
误报率(FPR、假阳性率)
灵敏度TPR(真阳性率、sensitivity)
漏报率(假阴性率、FNR)
ROC和AUC
Dice系数和IOU
| 预测 |
|||||
| 1 |
0 |
||||
| 实际情况 |
1 |
真阳性 (TP) |
假阴性 (FN) |
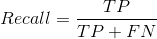 |
|
| 0 |
假阳性(FP) |
真阴性 (TN) |
|
|
|
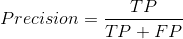 |
|
||||

True Positives, TP(真阳性):预测为正样本,实际为正样本
False Positives,FP(假阳性):预测为正样本,实际为负样本
True Negatives,TN(真阴性):预测为负样本,实际为负样本
False Negatives,FN(假阴性):预测为负样本,实际为正样本
准确率(Accuracy)
准确率是一个用于评估分类模型的指标。通俗来说,准确率是指我们的模型预测正确的结果(包括正例和负例)所占的比例。
精确率(Precision,查准率)
在预测为正类的样本中,实际上属于正类的样本所占的比例。 在信息检索领域,精确率又被称为查准率。
注意:精确率和准确率不是一个东西,请大家注意不要搞混了!
召回率(Recall=TPR)
在所有正类样本中,被正确识别为正类别的比例是多少,通俗讲,识别出来的正类(预测的)占实际正类中的比例。
在信息检索领域,召回率又被查全率。
精确率和召回率可以观察下图理解,他们的分子相同,但分母是不一样的。而且有时候是矛盾的,极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
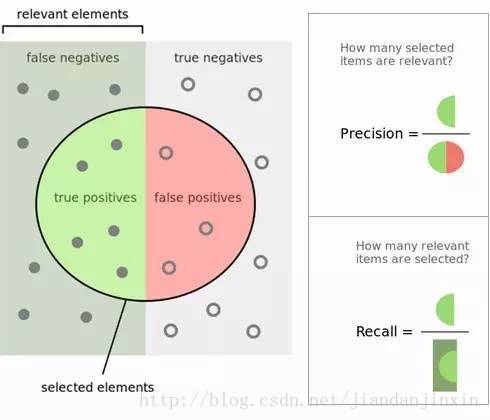
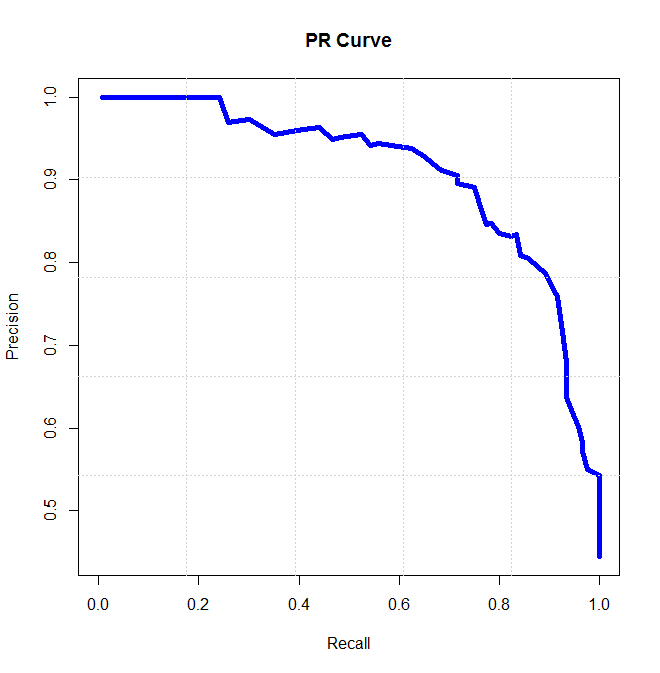
Precision-Recall曲线
在机器分类问题中,我们选用不同的阈值,因此,所得到的P(精确率)和R(召回率)也会有所不同,极端情况下,两个指标会自相矛盾,此时可以使用PR曲线来分析,以P(精确率)作y轴,R(召回率)作x轴,得到如下的PR曲线图。
F值(F-Measure,综合评价指标)
当Precision和Recall指标出现矛盾时,就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均
F =(a^2 +1)/(1/P + a^2/R) = (a^2+1)*P*R / (a^2*P +R)
当参数a=1时,就是最常见的F1:
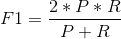
有时候我们对精确率和召回率并不是一视同仁,比如有时候我们更加重视精确率。我们用一个参数β来度量两者之间的关系。如果β>1, 召回率有更大影响,如果β<1,精确率有更大影响。自然,当β=1的时候,精确率和召回率影响力相同,和F1形式一样。含有度量参数β的F1我们记为Fβ, 严格的数学定义如下:
特异度TNR(真阴性率、specificity)
specificity(TNR):预测出来的负类占实际上负类的比例:
误报率(FPR、假阳性率)
预测出来的正类,但实际上是负类,占实际上负类的比例:
灵敏度TPR(真阳性率、sensitivity)
灵敏度:和召回率一样,预测出来是正类,实际上也是正类占所有正类的比例:
漏报率(假阴性率、FNR)
预测出来的负类,但实际上是正类,占实际上正类的比例:
ROC和AUC
ROC和AUC是评价分类器的指标,ROC的全名叫做Receiver Operating Characteristic。ROC关注两个指标TPR和FPR。
y轴:真阳性率(召回率)true positive rate ,TPR,称为灵敏度。所有实际正例中,正确识别的正例比例。
x轴:假阳性率(误报率)false positiverate, FPR,称为(1-特异度)。所有实际负例中,错误得识别为正例的负例比例。
Roc曲线用来评价分类器的性能。通过测试分类结果可以计算得到TPR和FPR的一个点对。再通过调整这个分类器分类的阈值(从0.1到0.9),阈值的设定将实例分类到正类或者负类(比如大于阈值划分为正类)。因此根据变化阈值会产生不同效果的分类,得到多个分类结果的点,可以画出一条曲线,经过(0, 0),(1, 1)。RoC曲线越靠近左上越好。从几何的角度讲,RoC曲线下方的面积越大,则模型越优。所以有时候我们用RoC曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。
注意:P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。

假设两个区域分别为X和Y
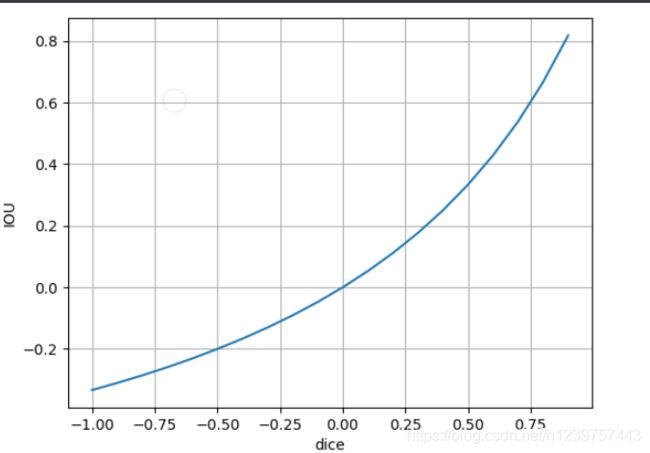
Dice系数和IOU
集合相似度度量的函数,通常用于计算两个样本的相似度,范围为【0,1】
将Dice看作自变量,IOU为因变量,那么函数图像如图: