MySQL:详细解读mysql的索引机制和分类,为何使用B+树?
索引
- 什么是mysql的索引
-
- 为什么要有索引,它的优缺点是什么?
- 为什么使用B+树作为索引,而不是二叉树,红黑树,B树?
-
- hash表
- 二叉树
- B树:改造二叉树
- B+树:改造B树
- 添加索引的原则
- 索引的分类和如何添加索引
-
- 聚簇索引和非聚簇索引
什么是mysql的索引
索引是帮助Mysql高效获取数据的数据结构。用大白话来说,就好比一本书的目录,帮助引擎更快的查询。
为什么要有索引,它的优缺点是什么?
为什么有索引? 因为在一些大型项目时,单表的数据量会过大,往往会超过百万条数据。 这 100 万条数据在硬盘上是存储在数据页上的,一页数据大小为16K,存储这大量的数据需要很多页。加入我们需要select * from 表名 where id = 100000 mysql会扫描全表来从数据1开始逐渐往后扫描。如果不添加索引,这样的效率是非常的低。
索引的优缺点?
优点:
- 提高查询效率,降低IO查询成本。(B+树排序,把索引数据加载到内存中,减小查询次数。)
- 使用B+数结构,是有序的,在排序是快捷方便,减少CPU消耗
缺点: 索引也是需要空间储存的,而且在执行增删改操作时,需要对索引的数据结构进行更新。
为什么使用B+树作为索引,而不是二叉树,红黑树,B树?
索引的存在是为了加快数据的查询效率。而数据存储在磁盘中,从磁盘读取数据会产生大量的IO操作,读取效率非常低。所以在读取效率的时候要减少IO操作来提高读取效率。 所以数据的存储格式就很重要。
hash表
首先,hash表的目的是尽可能的散列。因此在使用hash表的时候,要选择hash算法,避免hash碰撞和hash冲突。
其次是hash表的存储结构是无序的,当进行范围查询的时候,只能挨个遍历对比,效率非常低。
mysql中的memory存储引擎支持hash索引,innodb存储引擎支持自适应hash。
显然这种并不适合作为经常需要查找和范围查找的数据库索引使用。
二叉树
当二叉树为三层结构时,在存满的情况下,也只能存储7条数据。 当数据量继续增加时,树的层数也会增加,尤其是当数据量过大,树的长度会很高。相对应的IO操作也会变多,也就表示磁盘预读的操作也变多了。 而且磁盘预读在数据读取的操作一般都是层数的整数倍,那么当我们存储数据n层的空间不够时,哪怕多了一个数据在n+1行,它也会读完这一层,而且二叉树越往下,单层存储的数据就越多。这样极大的浪费了空间。所有二叉树不适合作为索引结构。
B树:改造二叉树
在上文中说道,优化查询效率的重点就是降低IO操作的次数。访问二叉树的每个节点就会发生一次IO,如果想要减少磁盘IO操作,就需要尽量降低树的高度。
二叉树的一次IO操作的有效数据量(读取的节点数量)是固定的,那么为了最大化的利用一次IO空间,就是在每个节点上存储尽可能多的元素。而如果每个节点可以存储1000个索引,通过增加树的叉树,就将树的形状从高瘦变为了矮胖。 那么IO操作的次数就会降低,查询的效率也会提升。这种树就成为B树。它是一种多叉平衡查找树。

主要的特点有;
- B树节点中存储多个元素,每个节点内有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值都是有序排列,从大到小。
- 父节点中的元素不会出现在子节点中。
- 所有的叶子节点都位于同一层。叶子节点具有相同的深度,叶子节点间没有指针连接。
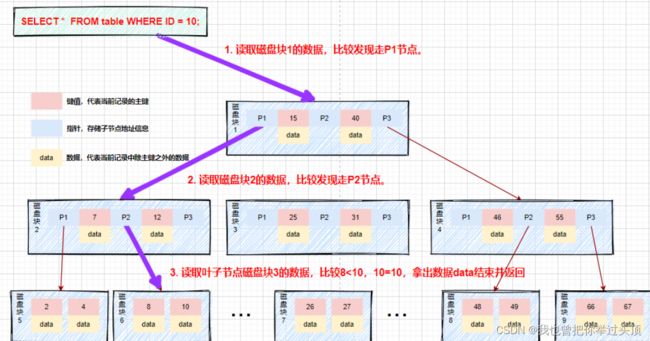
它的查询流程如图所示,虽然比较次数没有减少,但是在数据量增加的情况下,磁盘IO的次数会大大减少。同时比较是在内存中进行的,它的操作时间可以忽略不计,B树的高度一般2至3层就能满足大部分的应用场景,大大的增加了查询效率。
B树虽然很理想,但是别忽略它的一个缺点:叶子节点之间没有指针连接,所有他不支持范围查询,比如select * from 表名 where id > 10 and id < 30 ,查找到10后,又回到根节点查询遍历查找,需要从根节点进行多次遍历,查询效率不高。
B+树:改造B树
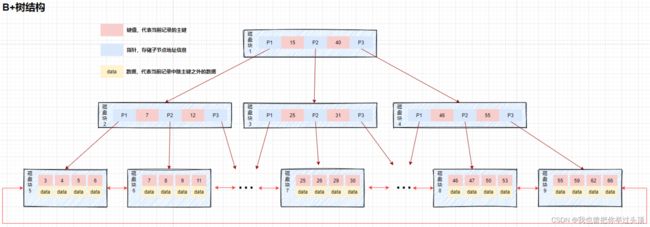
B+树,作为B树的升级版,在B树基础上,MySQL在B树的基础上继续改造,使用B+树构建索引。B+树和B树最主要的区别在于非叶子节点是否存储数据的问题
- B树的非叶子节点和节点都会存储数据。
- B+树只有叶子节点才会存储数据,非叶子节点存储键值。叶子节点之间使用双向指针连接,最底层的叶子节点形成一个双向有序链表。

可以看到B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构。
添加索引的原则
需要建立索引的情况
- 主键自动建立唯一索引
- 作为查询条件的列可以建立索引
- 作为外键关联的列可以建立索引
- 排序的列可以建立索引
- 分组的列可以建立索引
不需要建立索引的情况
- 表记录很少的列,比如系统参数的设置。
- 增、删、改频繁的表最好不建立索引。
- 数据重复率高的表,比如性别,年龄
索引的分类和如何添加索引
- 主键索引:设定主键后,数据库会自动建立索引
ALTER TABLE 表名 ADD PRIMARY KEY 表名(列名)
- 单值索引 / 单列索引: 一个索引对应一个列
CREATE INDEX index_user_account(这是索引名) ON USER(title)(表名和列名)
- 组合索引 / 符合索引:一个索引中包含多个列
CREATE INDEX 索引名 ON 表名(列名1,列名2,列名3,.....)
组合索引最左前缀原则: 列如表中有 a,b,c 3列,为 a,b 两列创建组合索引,那么在使用时需要满足最左侧索引原则.在使用组合索引的列作为条件时,必须要出现最左侧列为条件,否则组合索引不生效.
列如
select * from table where a=’’and b=’’索引生效
select * from table where b=’’and a=’’索引生效
select * from table where a=’’and c=’’索引生效
select * from table where b=’’and c=’’索引不生效
- 全文索引:需要模糊查询时,一般索引无效,这时候就需要全文索引了。
CREATE FULLTEXT INDEX 索引名 ON 表名(字段名) WITH PARSER ngram;
SELECT 结构 FROM 表名 WHERE MATCH(列名) AGAINST(搜索词')
- 查看索引:
SHOW INDEX FROM 表名;
聚簇索引和非聚簇索引
聚簇索引: 找到了索引就找到了数据。例如Innodb引擎,索引和数据在同一文件中,找到了索引就找到了数据。
非聚簇索引: 找到了索引,还要会表查询。例如myisam引擎,索引和数据在两个不同的文件,找到了索引还需要去另一个表找对应的数据,非聚簇索引也叫做辅助索引。
