CSAPP:PerfLab实验
目录
- 前言
- PartA优化一
- PartA优化二
- PartA优化三
- PartB优化一
- PartB优化二
- PartB优化三
前言
本实验是《深入理解计算机系统》一书中的附带实验。在本实验中,学生们必须优化应用程序的核心函数(如卷积积分或矩阵转置)的性能。这个实验非常清晰地表明了高速缓存地特性,并带给学生们低级程序优化的经验。
本文用于记录之前做实验的一些信息,可能思路有些凌乱,谨慎参考!
常用的几种代码优化的思路:
- 消除循环的低效率
- 减少过程调用
- 消除不必要的存储器引用
- 循环展开
- 提高并行性
PartA优化一
关于第一种优化,思路就是消除循环的低效率,减少在循环内的操作次数;
我们可以观察到原先的代码dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];中的j每变一次,dim-1-j就需要计算一次,共计算了 d i m 2 dim^2 dim2次,所以考虑将j换成外层循环变量i,将dim-1-i计算减少到dim次,直接写成dst[RIDX(i,j,dim)] = src[RIDX(j,dim-1-i,dim)];即可
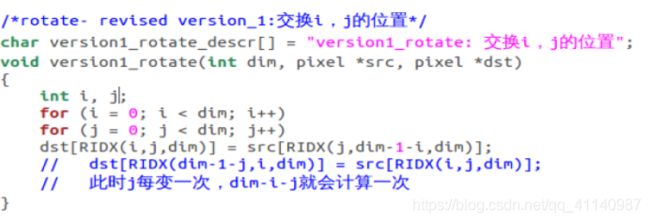
我们可以观察到原先的代码dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];中的j每变一次,dim-1-j就需要计算一次,共计算了 d i m 2 dim^2 dim2次,所以考虑将j换成外层循环变量i,将dim-1-i计算减少到dim次
PartA优化二

- 根据假设图像维度为32的倍数这一个条件可以试着将该图像划分成几个32*32的矩阵,分块进行操作
- 为了充分利用一级缓存(32kB),故采用分块策略,将每一小块分成32*32的矩阵
- 这里的分块是指一个应用级的数据组块,而不是高速缓存中的块,这样构造程序,能将一个片加载到L1高速缓存中去,并在这个片中进行所需要的所有读和写,然后丢掉这个片,加载下一个片,以此类推。
- 使用分块策略的时候需要注意分成的小块的规模要比规模小,且要被dim整除,否则出错
使用了分块技术,将矩阵分成相同规格的小矩阵,对这些小矩阵进行rotate操作,在这里我给出了将不同将矩阵分成不同规格(8x8、16x16、32x32、64x64)的矩阵的代码并比较性能
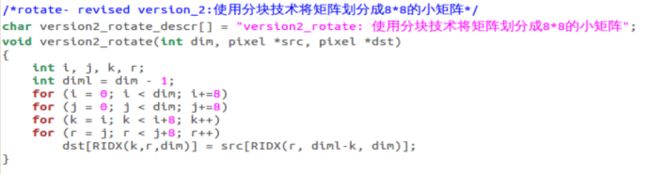


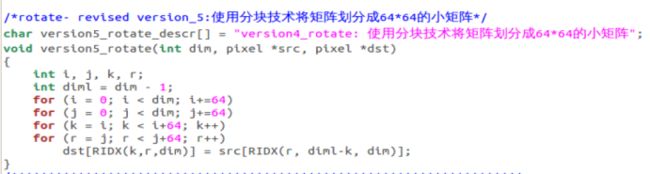
使用make命令之后输入./driver命令得到不同函数的性能参数

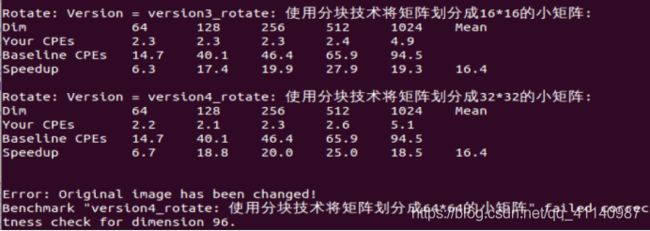
由此可以看出,将其分成64x64的矩阵时程序会出错(因为规模都是32的倍数);且发现程序在将矩阵划分成32x32的小矩阵的时候性能是最好的
PartA优化三
利用“循环展开”思想,从减少存储器写次数、用指针代替计算内存地址、写优先和读优先四个角度来实现


(使用32路循环展开,减少存储器的写次数)
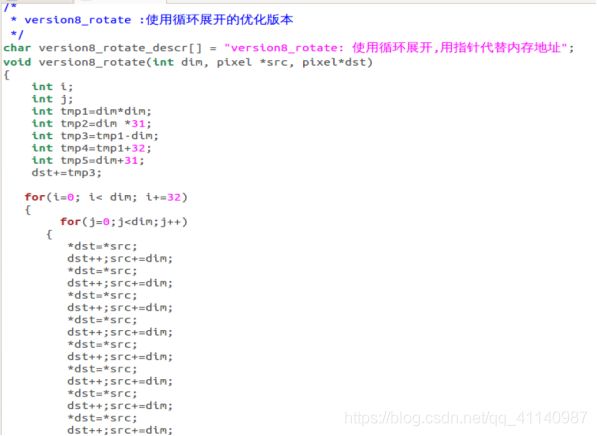


(使用循环展开,用指针代替计算内存地址)

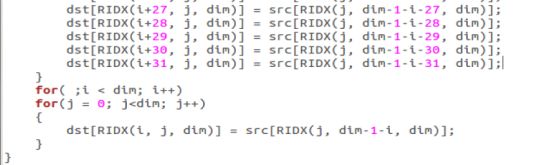
(循环展开,采取写优先)
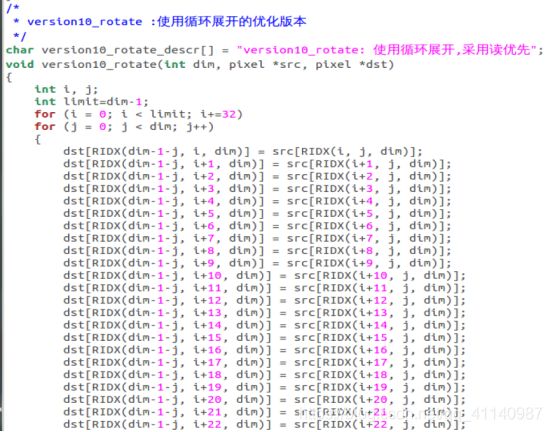
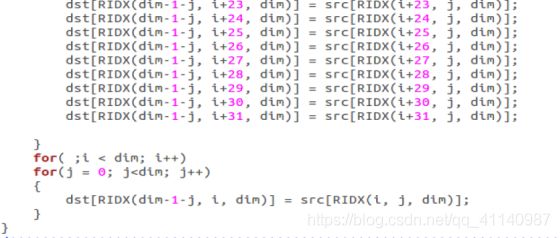
(使用循环展开,采取读优先)
使用make driver ./driver命令得到不同优化前后函数的性能参数



可以看出使用循环展开,用指针代替计算内存地址的操作能够使函数得到更大的优化;
- 循环展开,是一种程序变换,通过增加每次迭代计算的元素的数量,减少循环的迭代次数。Version8_rotate函数的代码实现了每次迭代增加了32行元素的计算,所以整个程序的迭代次数缩减为了原来的1/32次;
int tmp1=dim*dim;
int tmp2=dim *31;
int tmp3=tmp1-dim;
int tmp4=tmp1+32;
int tmp5=dim+31;
dst+=tmp3;
这一段代码中的dst就是小矩阵的第一个元素的首地址,将一个32*1的矩阵进行rotate的时候,在矩阵内部,每次执行完一行都只需要让scr+=dim,dst++,当执行完到最后一行的时候,src++,这时候实际上应该要到下一列的第一行,故src-=tmp2,而dst应该到上一行的第一列,故dst-=tmp5;根据二维数组在内存中的存储特征,下一列的第一行的地址为上一列第一行的地址+tmp2,所以src+=tmp2,该行的下一列地址为上一行的第一列+dim+32;故dst+=tmp4;
这就解释了代码中执行这一段的原因
src++;
src-=tmp2;
dst-=tmp5;
}
src+=tmp2;
dst+=tmp4;
PartB优化一

将initialize_pixel_sum函数、accumulate_sum函数、assign_sum_to_pixel函数、avg函数都放在smooth函数中实现,减少函数调用

可以看出本次优化效果不明显且存在不稳定性
- 包含函数调用的代码可以用一个称为内联函数替换的过程进行优化,此时将函数调用替换为函数体,这样既可以减少函数调用的开销,也允许对代码做进一步的优化,产生这个函数的另一个优化版本。根据这一思想,我将initialize_pixel_sum函数、accumulate_sum函数、assign_sum_to_pixel函数、avg函数的函数体都放在smooth函数中实现,减少函数调用
PartB优化二


使用make driver ./driver命令得到不同优化前后函数的性能参数

可以看到CPE几乎翻了一倍,程序得到较大程度上的优化
优化思路:
- 使用一个二维数组用于保存每次计算得到的中间值,需要用到的时候从数组中取值即可,不需要重复运算,因此可以很大程度上减少计算需要用的时间
- 实现过程:以rowsum[i][j].red为例,它存储的是第i行第j列的红色的像素值,根据平滑函数需要实现的功能,先从行开始循环,让rowsum[i][j].red等于当前行周围两列的红色像素值之和,边界条件为rowsum[i][0].red=rowsum[i][0].red+rowsum[i][1].red和rowsum[i][dim-1].red=rowsum[i][dim-1].red+rowsum[i][dim-2].red,此时参与运算的是两个方格,故rowsum[i][0].num=2,rowsum[i][dim-1].num=2;
- 当j在1~dim-2时,则让rowsum[i][j].red=rowsum[i][j-1].red+rowsum[i][j].red+rowsum[i][j+1].red; rowsum[i][j].num=3;
- 同理,之后从列开始,让rowsum[i][j].red等于当前列周围两行的红色像素值之和,边界条件为rowsum[0][j].red=rowsum[0][j].red+rowsum[1][j].red和rowsum[dim-1][j].red=rowsum[dim-1][j].red+rowsum[dim-2][j].red,此时参与运算的是两个方格,故rowsum[0][j].num=2,rowsum[dim-1][j].num=2;
- 当j在1~dim-2时,则让rowsum[i][j].red=rowsum[i-1][j].red+rowsum[i][j].red+rowsum[i-1][j].red; rowsum[i][j].num=3;
- Snum为紧邻当前方块的方块和,最终第i行第j列的颜色像素值=周围的该颜色像素值/snum;
PartB优化三





使用make driver ./driver命令得到不同优化前后函数的性能参数
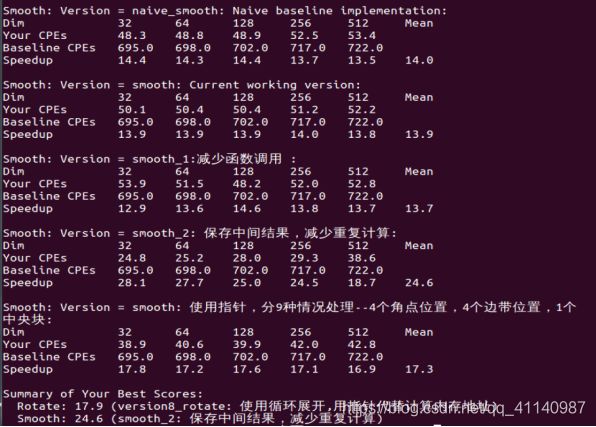
优化思路:
- 使用指针,分9种情况处理——4个角点位置,4个边带位置,1个中央块;
- 定义三个指针,第一个用于指向当前元素上一个元素的值,第二个指向当前元素,第三个指向当前元素下一个元素的值,先对左上角的像素点进行处理,接着是上边界、左边界、中央块、右边界、左下角、下边界和右下角,每处理完依次都要让三个指针值做出相应改变,计算出相应点的新的像素值。